2014年11月11日
Optimizelyを使ってクビになりかけたワケ ~統計学が苦手なマーケターへの薦め~
本記事は、原著者の許諾のもとに翻訳・掲載しております。
(訳者注: 検定手法について、この記事には一部内容が古い部分があります。Optimizelyは現在、両側検定を採用し、独自開発したより精度の高い統計手法(Stats Engine)でテスト結果を表示しています。Stats Engineに関する記事: 日本語 ・ 英語 )
私たちがSumAllでA/Bテストを一斉にスタートさせて6ヶ月が経ち、あまりよくない結末を迎えました。それは勝算があるとした結果のほとんどが新規ユーザーの獲得改善にはつながらなかったことです。それどころか、私たちは失敗したのです。そして私の一番の責任はユーザー獲得の増加であるということを考えると、本当に最悪の状況でした。私にとっても、私のキャリアにとっても、そしてSumAllにとっても。
過去に A/BテストとWebサイト・パーソナライゼーションの会社 に勤めていた経験から(はっきり言うとMonetateはOptimizelyのライバル会社です)、私はいつもA/Bテストのメリットを信じていました。それで、SumAllに勤めて最初に始めた事の1つもテストプログラムの立ち上げでした。テストは順調に進み(少なくともそう見えました)私たちは、ただそのテストのパフォーマンスの良さに驚いていたのです。
Optimizelyは私たちのテスト結果から”リフト”と呼ばれる巨額の利益を予測していました。リフトはこちらに60%、あちらに15%という具合で、驚くことにどこにもマイナス要因は見られません。プラスばかりでした。本当は中身のない朗報が毎週の電子メールで届き、チームはすっかりA/Bテストの哲学を信じていました。
つまずき始めの原因は、まずSumAllが典型的な一般の会社ではなかったということでした。私たちは高度な技術集団で、多くのデータアナリストや統計の専門家がスタッフにいます。ビジネスデータの集計と分析を専門としている会社なので当然です。一見どんなに素晴らしい数字であっても、そのリフトが本物であることを、重要なビジネス成果測定基準のもとで厳しく精査して確かめなければ、私たちは納得しません。
残念なことに、少なくともOptimizelyが私たちを確信させたほどには、その数字は本物ではありませんでした。
もう少し詳しく調べた結果、私たちが得た数字は予測されたリフトの10~15%にすぎませんでした。そこで少し実験をしてみることにしたのですが、それが完全に墓穴を掘ることになります。
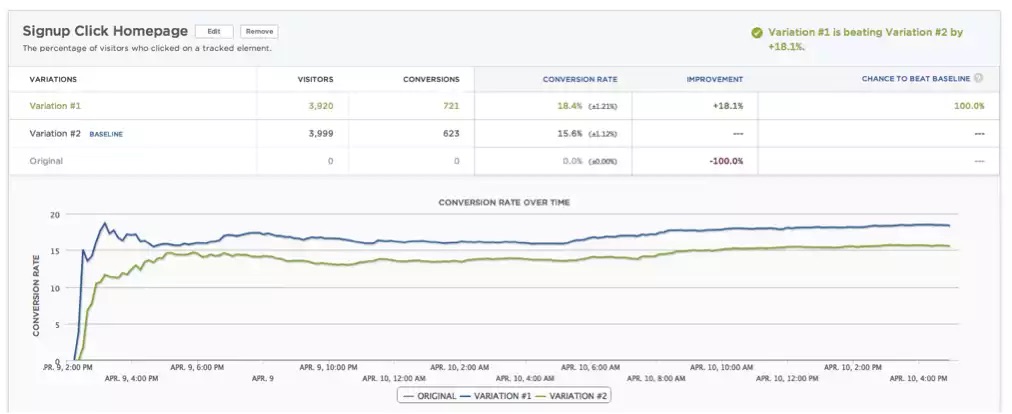
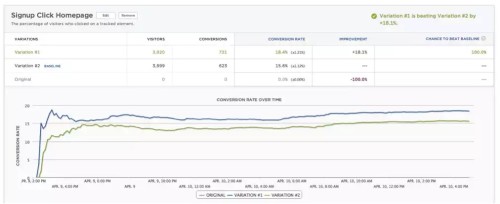
私たちは2つのまったく同じホームページの比較テストしました。この2つの結果は同じになり、ほぼ同じコンバージョン率が得られると思われるでしょう。ところが結果は驚くべきものでした。上のスクリーンショットからわかるように、最初のものと同じはずのホームページが、18.1%の改善を示したのです。さらに悪いことに、この結果が正確である確率は100%と出ました。控え目に言っても、問題と言わざるを得ないでしょう。
片側検定vs.両側検定
ほとんどのマーケターは統計の専門家ではありません。そのため、結果が統計学的に妥当であることを検証するために2つの方法、いわゆる”片側検定”と”両側検定”があるということを知らないのです。
さらにややこしいことに、テスティングベンダには片側検定を使う会社( Visual Website Optimizer 、 Optimizely )と両側検定を使う会社( Adobe Test&Target 、 Monetate )があります。どちらの陣営も、どのタイプの検定を使用しているかということを明らかにしたり、それぞれの検定の利点や欠点についてユーザに知識を与えることは得意としていません。
(訳者注: Optimizelyは現在、両側検定を採用し、独自開発したより精度の高い統計手法(Stats Engine)でテスト結果を表示しています。Stats Engineに関する記事: 日本語 ・ 英語 )
では、片側検定と両側検定の違いは何でしょう?
簡単に言えば、両側検定は効果についてポジティブとネガティブの両方向の可能性をテストします。一方、片側検定では逆方向のインパクトを考慮に入れることなく、一方向について効果の可能性だけをテストします。
UCLAのフレンドリーな統計学者 がこう説明しています。
片側検定は1つの効果について検出することに、より力を発揮します。もし既に仮説に方向性がある場合は片側検定を使おうとするでしょう。しかし片側検定を使う前に、別の方向への効果が考慮されないまま導かれる結果について考えてください。例えば、新薬を開発し、それが既存の薬よりも改善されていると信じているとします。どれほど改善されたかを最大限の能力で測りたいので、片側検定を選びます。そうしてしまうと、新薬が既存薬よりも効果がないかもしれないという可能性はテストされません。これは極端な例ですが、片側検定を適切に使っていない場合の危険性を明確に伝えているでしょう。
では、どういう場合に片側検定が適しているのでしょうか? テストしない方向への効果が欠けている影響を考慮して、それが無視してよいものであり、そうすることが無責任でも非倫理的でもないと考えられれば、片側検定で進めていいでしょう。もう一度、新薬を開発した例で考えます。それは既存薬よりも安価で、既存薬と同等の薬効があるとあなたが信じているとします。つまり既存薬よりはるかに優れていることは期待しておらず、ただ既存薬に劣っていないということを示したいのです。そういう場合は片側検定が適切です。
片側検定の落とし穴は、先ほどの例で続けると、測定の対象が”新薬は既存薬よりも優れているかどうか”だけであることです。片側検定では新薬が既存薬と同じかどうか、あるいは既存薬のほうが優れているかどうかは測定しません。新薬がより優れていると示すデータだけを探し、その結果、有意性が2倍になるような結果となります。片側検定には本質的に偏りがあるのです。
世の中(ソフトウェアベンダも含む)にとっては、片側検定は便利です。両側検定よりも少ないアクセス量で済むからです。(統計的に正確ではないにしろ)結果が素早く出るので、事情をよく分かっていないユーザは好んで使います。片側検定を使えば簡単に結果が得られますし(上司にも評価されます)、ハッキリした結果が見られるのでA/Bテストのバグを簡単に見つけられます。何だかんだ言っても、いつも勝てるのであれば、カジノに行きたくない人なんかいないと思いませんか?
ところで、実際にチームメンバーが数字を徹底的に調べて、自分が予測したものよりも結果が悪いと分かったら、どうなるでしょう? 良い結末にはなりませんね。まるで、仕事で稼いだと思っていたお金が偽物だったとか、想定していた価値の10~15%ほどの価値しかなかったとかいうようなものです。
統計的検出力
大幅な変更についての簡単な見積もりを実施するというのであれば、片側検定で十分でしょう。しかし、データの正確な解釈によって会社のボトムラインが決まるというような場合は、片側検定では不十分です。
統計的検出力とは、単に実験中に検出した差が、実際に現実世界での差を反映するという尤度のことです。
統計的検出力がP90や90%といった形で表されているのをよく目にするでしょう。つまり、AがBよりも良いという可能性が90%あるとしたら、BがAよりも良くて実際に見積もったものよりも悪い結果になる可能性が10%あるということです。
このことについては、 なぜ多くのA/Bテストで出る結果は信用ならないのか について書かれた必読のホワイトペーパーでMartin Goodsonが説明しています。
“例えば男性と女性の身長に違いがあるのかどうかを調べるとしましょう。その時に男性と女性1人ずつしか測定しなかったとしたら、男性が女性より身長が高いという事実を検出できないというリスクを冒すことになります。なぜかって? それは、身長が特に高い女性または身長が特に低い男性を、偶然に選んでしまうかもしれないという不規則変動があり得るからです。
しかし、測定対象の人数を多くすれば、最終的には男性と女性の身長の平均は一定の値に落ち着き、男性と女性の間に存在する身長差を検出することができるでしょう。それは、統計的検出力が「サンプル」(統計学者が使う用語で「測定対象にされた人数」の意味)の数によって高まったからです”。
片側検定は一方向からしか結果を測定しないので、統計的検出力は増幅されます。そのため結果の精度に関しては懐疑的になるべきなのです。
魔法の粉、短期バイアス、平均値への回帰
たとえ短期バイアスによって有意性が出ることがよくあるとしても、大抵のA/Bテストツールは有意性が見えたらすぐに、テストを終了することを推奨しています。Optimizelyでは、小さな緑色の表示がポップアップすると、マーケターはテストを終了します。
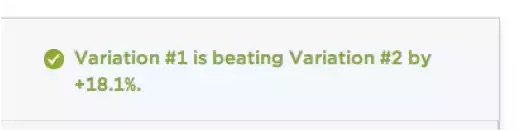
こうして終わる大抵のテストは、もっと長い時間をかけて行われるべきですが、もし長い時間行われたら、多くの場合、期待ほどの結果が出なくなる可能性があります。つまりこれは、このようなプラットフォームにおいて、デフォルト設定でユーザの期待している結果が出やすくなっていることで、ユーザがもっとツールを使いたくなるということの好例です。
結果に注意を払えば、多くのA/Bテストの結果が、平均値へ回帰するか、有意性を失うか、何らかの形で徐々に悪化していくことに気づくでしょう。実際、Goodsonは”少なくとも、80%の有意性なんてものは全く価値がない”と断言しています。
なぜでしょうか?
それは、”新奇性効果”が出ることがあるからです。Webサイトに対して加えた変更は既存ユーザの注目を集めます。サイト上で「行動を誘引する大きなボタン」を緑色からオレンジ色に変更することは、単に以前と見た目が違うというだけでも、サイトを再訪したユーザの目にとまります。一時的な効果ではありますが、変更を加えることはユーザの行動におけるバナーブラインドネスの防止に効果があるのです。
最初の結果がそもそも誤検出になる可能性もあります。こういったことは、大抵、偏った結果が出る片側検定を行ったことで起こってしまうのです。結局、最小限の有意性を確保したところでテストツールはグリーンフラグを出します。大きな緑色のボタンが現れ”結果が出ました”と知らせてくるわけです。そしてマーケターは、その結果が偽りのものだと気づくことなくテストを終えてしまいます。
世界は一様に分布していない
少なくとも、Webサイトを訪れる人々に関して言えば、世界は必ずしもきちんと整えられた場所ではありません。実際、Webサイトを訪れる人々は”塊”になる傾向があります。それは、アクセス量を左右する様々な広告、電子メールで送られたニュースレター、既存そして新規ユーザ、時差、そして様々な国や地域などといったものです。実際に釣鐘曲線を描けるような十分なアクセス量があるWebサイトはほとんどありません。1ヶ月に訪れるユーザ数が100万人に満たないとすればサイトのユーザが一様に分布しているとは言えませんし、その場合は釣鐘曲線を描けません。
これが重要になるのは、例えば、テストの開始時にリストに載っているユーザに電子メールの配信を行ったことで、AがBよりも大きな上昇を見せたような時です。同様に、発注量のようにWebサイトにおいて重要視されるものは、大抵、正規分布しません。特定の方向に異常値やロングテールが現れます。このようなことは、結果が平均に回帰したり、一時的なものになったり、偽りのものになってしまったりすることにつながるのです。
テストをしているのではなくて仮説を確認しているだけだということを認める
ほとんどのA/Bテスティングベンダが、一方向の結果だけを測定して早めに実験を止めるようにグリーンフラグで勧める片側検定でうまくやり過ごしている理由は簡単です。ユーザがそれを許しているからです。
悲しい現実ですが、ほとんどのユーザはA/Bテストに厳しくありません。実際、彼らはA/Bテストをしているのではなく、自分の仮説を確かめているだけだと言えるでしょう。
ほとんどの組織では、Webサイトに変化を起こしたいと考えた場合、その変化を裏付けるデータを欲しがるでしょう。予期せぬ結果、悪い結果、意外な結果を示している実験を詳細に調べる代わりに、変化を示したものがあればそれを熱烈に支持するでしょう。錯覚にすぎない結果でも次回の上司との会議のネタになるならば、詳細は問題になりません。ほとんどの組織は最終結果に反して良い傾向を示しているA/Bテストの結果を深く追及しませんから、誰も気づかないのです。
高度な知識の欠如
長年に渡り、私はA/Bテストやコンバージョン最適化について多くのマーケターと会話してきました。1つ明らかになったことは、ほとんどのマーケターが統計学に無関心であることです。驚いたことに、統計や標本サイズなど有効なA/Bテストを行うのに必要なことを理解しているマーケターはほとんどいませんでした。
コンバージョンテストを提供している会社側はこのことを知っています。そういうベンダの多くはテストが良かったのか悪かったのかを告げ、ある数値がどれくらいと示す簡単な仕組みを持ったインターフェースを提供するだけでそれ以上の見返りを得ています。これは公平な実験とは言えません。それはPowerPointのプレゼンテーションに理想的な見栄えがよい結果を迅速なレポート用に提供する手段です。ほとんどのコンバージョンテストは基本的にマーケティングの玩具にすぎません。
ですから、たとえこの業界が決して正確とは言えないこうしたサービスの本質に気づいていないとしても、私はA/Bテスティングベンダが自らのユーザにひどい仕打ちをしていると考えています。盲目的に信じているユーザを教育するのではなくて、ユーザにマーケティングごっこをさせているのです。彼らは低トラフィックサイトのユーザを拒否しません。バーを低くして結果的に”成功”させるシステムを作ります。故意に片側検定を使います。なぜなら、そうした検定結果のほとんどは問題があるにもかかわらず人を興奮させるからです。
私の考えでは(少し偏向していますが)、両側検定を行う知識と能力が加われば喜ばれると思います。今の状態はカジノへ行って、列を成した高齢の常連客が酸素ボンベを従え貯金をスロットマシンに使っているのを見ているのに似ています。人々が最新のテストが良かったことに興奮しているのを見ると残念で胸が痛みます。結局彼らはそうした好結果が実世界には何の影響も与えないことを理解することになります。
できることは何か
最悪の事態に出会う前に、どうすればいいかをお話ししましょう。
1. ターゲットを絞ったテストの実行
ユーザを別々のグループに分けてテストすることを考えましょう。携帯機器のユーザはデスクトップ機器のユーザとは別に実行するのです。新たな訪問者と再訪者は別に、電子メールのトラフィックとサイトのアクセス量は別に考えましょう。”セグメント第1″に考えましょう。
2. 最新知識で武装する
マーケターにとって測定基準と統計学はますます重要になっています。実際、最近の私が知っている成功したマーケティングチームの多くはスタッフにデータアナリストを加えています。ですから高度な知識を持ったアナリストを敬遠しないでください。深く探求するのです。
3. テストは2回
A/Bテストを2回実施することが賢明です。結果を得たら同じテストをもう一度やりましょう。そうすれば錯覚にすぎなかった結果を除外するのに役立つでしょう。最初のテスト結果が頑強なものでない場合は、2回目のテストでそれが目に見えて崩れていくのが分かるでしょう。しかし好結果が本物ならば、2回目もそうなるでしょう。この手法は絶対確実というわけではありませんが、十分役立つでしょう。
4. テストは長く
疑問がある時は、テストプラットフォームがストップサインを出すポイントを越えて、テストを長くやってください。何千というコンバージョンイベントを追跡するまで実験を続けるように勧める専門家もいます。しかし実際に重要なのはコンバージョンの数ではありません。問題はテスト時間の長さが対象サイトの変化をとらえるのに十分かどうかということです。週末や夜間に多くの訪問者や様々なコンバージョンパターンがありますか? データを標準化するためにはいくつかの変動サイクルを考慮すべきでしょう。
もう1つ考えるべきことは、統計的有意性は十分ではないということです。例えばThreadlessのような大きなサイトは1時間に数千のコンバージョンを得ています。また少しテストをすればすぐに有意性を確認することができるでしょう。しかしこのことは、ただ単にテストを数時間走らせるべきだということを意味しているのではありません。正確に言うと、そのユーザの代表標本をとらえられるように十分長くテストをするべきだということです。重要なのは変動サイクルです。コンバージョンの数はそれほど重要ではありません。
さて結局、私はクビにはなりませんでしたが、統計学者やデータアナリストへの新たな認識を胸にして会社を去ろうと思っています。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事