2018年7月12日
分散型システム徹底入門 – Part 1.

本記事は、原著者の許諾のもとに翻訳・掲載しております。
分散型システムとは何でしょうか? なぜそんなに複雑なのでしょう?

分散型システムについて熟考中のクマ
目次
はじめに
- 分散型システムとは何か?
- なぜシステムを分散させるのか?
- データベースのスケーリングの例
分散型システムのカテゴリ
- 分散型データストア
- 分散型演算
- 分散型ファイルシステム
- 分散型メッセージング
- 分散型アプリケーション
- 分散型台帳
まとめ
はじめに
目覚ましい進歩を遂げているテクノロジが世界中に拡大する中、分散型システムは広く知れ渡ってきました。コンピュータサイエンスにおいては、複雑かつ果てしない研究分野と言えます。
本記事は、基本的な方法を使って、この分散型システムを紹介しています。詳細まで深く掘り下げていくのではなく、こうしたシステムの様々なカテゴリを垣間見ていくことを目的としています。
分散型システムとは何か?
分散型システムを最もシンプルに定義するとしたら、エンドユーザには単一のコンピュータとして見えるように協働する複数のコンピュータの集まりと言えます。
この複数のマシンは状態を共有し、並行して稼働しています。あるマシンに障害が発生した場合は、そのマシン単独の障害となるため、システム全体の稼働時間が影響を受けることはありません。
それでは、まずはシステムの全体像をよりよく理解できるよう、システムを分散した例を1つずつ見ていくことにしましょう。
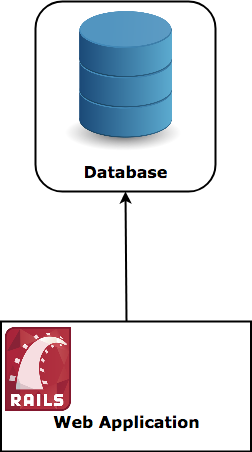
注釈:従来のスタック
では、データベースから始めましょう! 従来型のデータベースは、1つのマシンのファイルシステムに格納されていて、情報を取り出したり挿入したりしたいときには、そのマシンと直接対話をする、というものです。
このようなデータベースシステムを分散するには、このデータベースが複数のマシンで同時に稼働している必要があります。つまり、ユーザは、自分が選択したマシンがどれであっても、そのマシンと対話ができなくてはなりません。さらに、自分が対話をしていないと言えるマシンが1つでもあってはいけません。ユーザがノード#1にレコードを挿入したのなら、ノード#3がそのレコードを返すことができなければいけないのです。
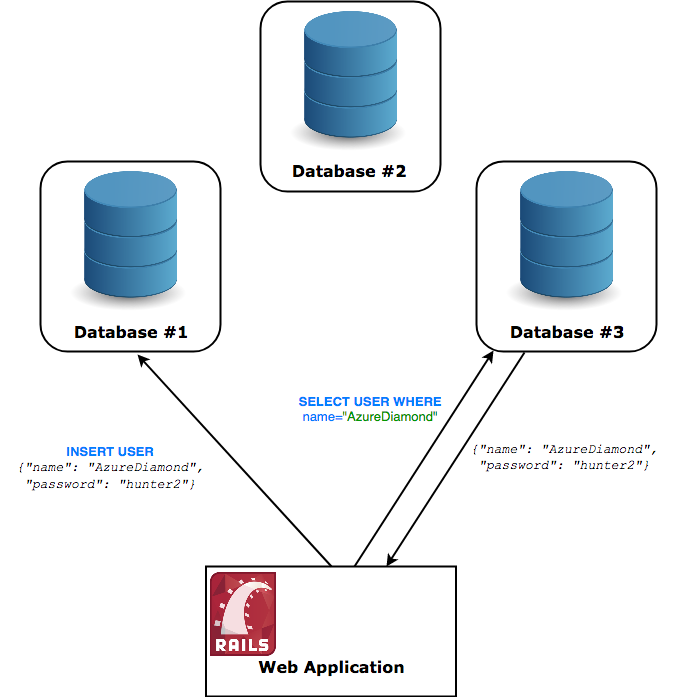
注釈:分散型と考えられるアーキテクチャ
なぜシステムを分散させるのか?
システムは常に必要に迫られて分散されます。実のところ、分散型システムを管理するならば、いくつもの落とし穴と地雷が潜む複雑な課題に直面することになります。分散型システムをデプロイし、デバッグをするときは、頭が痛くなります。それなのに、一体なぜやらなくてはいけないのでしょうか?
分散型システムにすることにより、 水平スケール が使えるようになります。先に例を挙げた単一のデータベースサーバの話に戻りますと、この場合、より多くのトラフィックを処理する唯一の方法は、データベースが稼働しているハードウェアをアップグレードすることでした。これはいわゆる 垂直スケール です。
垂直スケールは、対応できる間は良いのですが、ある一定のポイントを過ぎたところで、最適なハードウェアになったというのに十分なトラフィックが得られないという事態に陥ることが分かります。当然、それはホストにとっても実用的なものではなくなります。
水平スケール とは、単一のハードウェアをアップグレードするのではなく、単に、別のコンピュータを追加することを意味します。
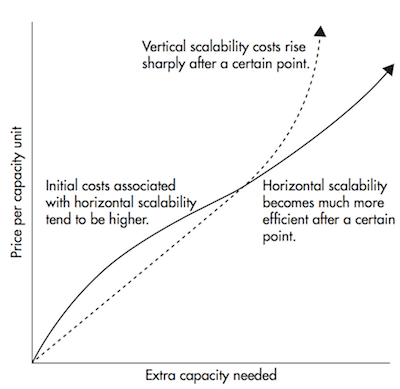
注釈:(横軸)余分に必要となる容量
(縦軸)容量を確保するユニットごとの価格
(上)垂直スケーラビリティだと、あるポイントを超えてからコストが急に上がり始める
(左下)水平スケーラビリティだと、イニシャルコストが高くなりがち
(右下)水平スケーラビリティだと、あるポイントを超えてから非常に効率的になる
水平スケールはある閾値を境に コストがずっと低く なります
水平スケールは、ある閾値を超えれば、垂直スケールよりもずっとコストを抑えられます。ただ、このことが水平スケールを好ましいと考える主な理由というわけではありません。
垂直スケールは、パフォーマンスを最新のハードウェアのレベルまで上げることしかできません。このような性能では、中規模から大規模な業務を担う技術的な企業にとっては 不十分 であることが分かっています。
水平スケールの最も優れた点は、スケーリングできる数に制限がないことです。パフォーマンスが低下したら、単に新たなマシンを追加すればいいのです。追加なら無限に行える可能性があります。
さらに、分散型システムによって得られる恩恵は、このようにスケーリングが簡単ということだけではありません。 耐障害性 と 低遅延 も同じく注目すべき点です。
耐障害性 – 2つのデータセンターにまたがる10台のマシンの集まりは、実質的に1台のマシンよりも耐障害性に優れています。1つのデータセンターが火災に見舞われても、アプリケーションは引き続き機能します。
低遅延 - ネットワークパケットが世界中を移動する時間は、物理的には光の速度までという限界があります。例えば、ニューヨークからシドニーの間での光ファイバケーブルでリクエストが ラウンドトリップタイム (つまり、リクエストが行って帰ってくる時間)の最短時間は 160ms です。分散型システムなら、両方の都市にノードを持つことができるので、より近い方のノードにヒットするようなトラフィックが選択されます。
しかし、分散型システムを稼働させるには、複数のコンピュータ上で同時に実行され、これに伴う問題にも対応できるように特別に設計されたソフトをこうしたマシン上で実行する必要があります。これを実現するのは容易なことではありません。
データベースのスケーリング
私たちのWebアプリケーションがとてつもなく人気を博していると想像してみましょう。それに伴い、クエリが、データベースが1秒あたりに処理できる量の2倍になったとします。あなたのアプリケーションのパフォーマンスはすぐに低下し始め、ユーザもそのことに気付くことになります。
では、こうした高い要求を満たすため、力を合わせてデータベースのスケールを変えることにしましょう。
一般的なWebアプリケーションでは通常、新しい情報を挿入したり、古い情報を変更したりするよりもずっと頻繁に行っているのは、情報の読み込みです。
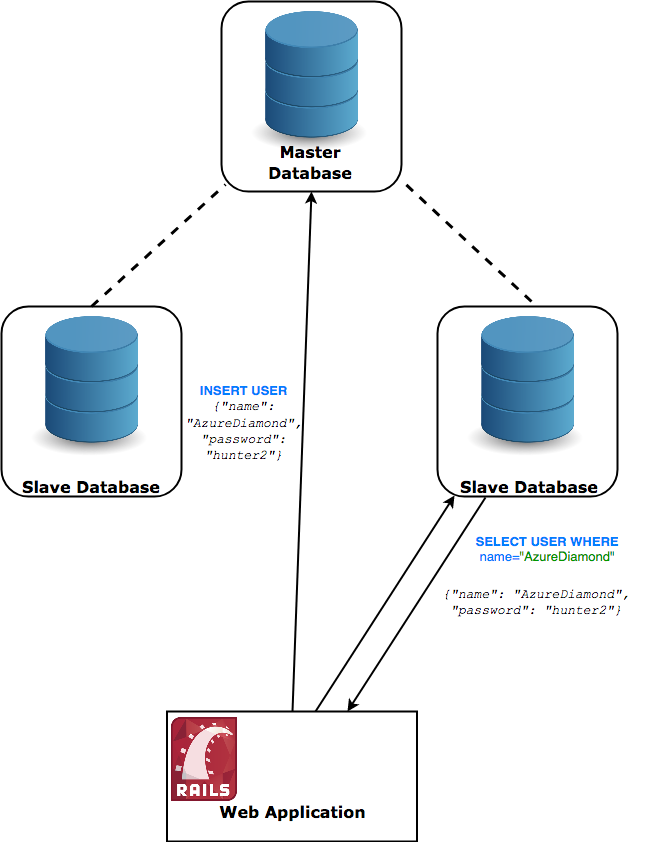
この読み込みのパフォーマンスを向上させる方法があります。それは、いわゆる マスタースレーブ型のレプリケーション 戦略です。ここでは、メインサーバと同期する2つの新しいデータベースサーバを作成します。この新たに作成されたサーバからは、 読み込みしか できない、という難点があります。
あなたが情報を挿入または変更するときは、マスターデータベースと対話することになります。次に、マスターデータベースは非同期的にスレーブへとその変更を通知し、スレーブはその通知のとおりに変更を保存します。
おめでとうございます! これで、3倍の読み込みのクエリを実行できるようになりました。これは素晴らしいですよね?
落とし穴
はまりました! これであっという間にリレーショナルデータベースの ACID 保証の C 、つまり一貫性(ConsistencyのC)が欠落したものになってしまいました。
見ていただいたとおり、新しいレコードをデータベースに挿入した直後は、そのレコードの読み取りのクエリが発行されても何も返してこない可能性があります。まるで何も存在しないかのように!
マスターからスレーブへの新しい情報の伝搬は即座には行われません。実際は、古い情報を取得する可能性のある時間枠があるのです。情報が伝搬されていない場合は、伝播されるデータの同期を待たなくてはならないため、書き込みパフォーマンスが低下します。
分散型システムにはいくつかのトレードオフがあります。適切にスケーリングをしたいなら、この特定の問題をうまく扱っていかなければならないのです。
スケーリングを続ける
スレーブデータベースという方法を用いることで、ある程度までは読み取りのトラフィックを水平方向にスケーリングすることができました。それは素晴らしいことですが、書き込みトラフィックという観点では、まだ壁があると言えます。書き込みに関しては全て、1つのサーバでやっているという点です!
これには、たくさんのオプションがあるわけではありません。1つのサーバで処理しきれないのなら、シンプルに、書き込みトラフィックを複数のサーバに分割するのです。
その方法は、 マルチマスターレプリケーション戦略 です。読み込みだけのスレーブではなく、読み込みと書き込みをサポートする複数のマスターノードにするものです。残念ながら、今度は コンフリクトも作成 できるようになるため(例えば、同じIDを持つ2つのレコードを挿入するなど)、これであっという間に複雑になります。
それでは シャーディング と呼ばれる別の技術を試してみましょう( パーティショニング とも呼ばれています)。
シャーディングでは、サーバを シャード という、より小規模な複数台のサーバに分割します。これらのシャードはすべて異なるレコードを保持します。どのシャードにどのようなレコードを格納するのかといったルールを作成します。 均一に データを分散させるというルールを作成することはとても重要です。
これを実現するための方法としては、レコードのある情報によって範囲を定義することが考えられます(例えば名前がA~Dで始まるユーザ)。
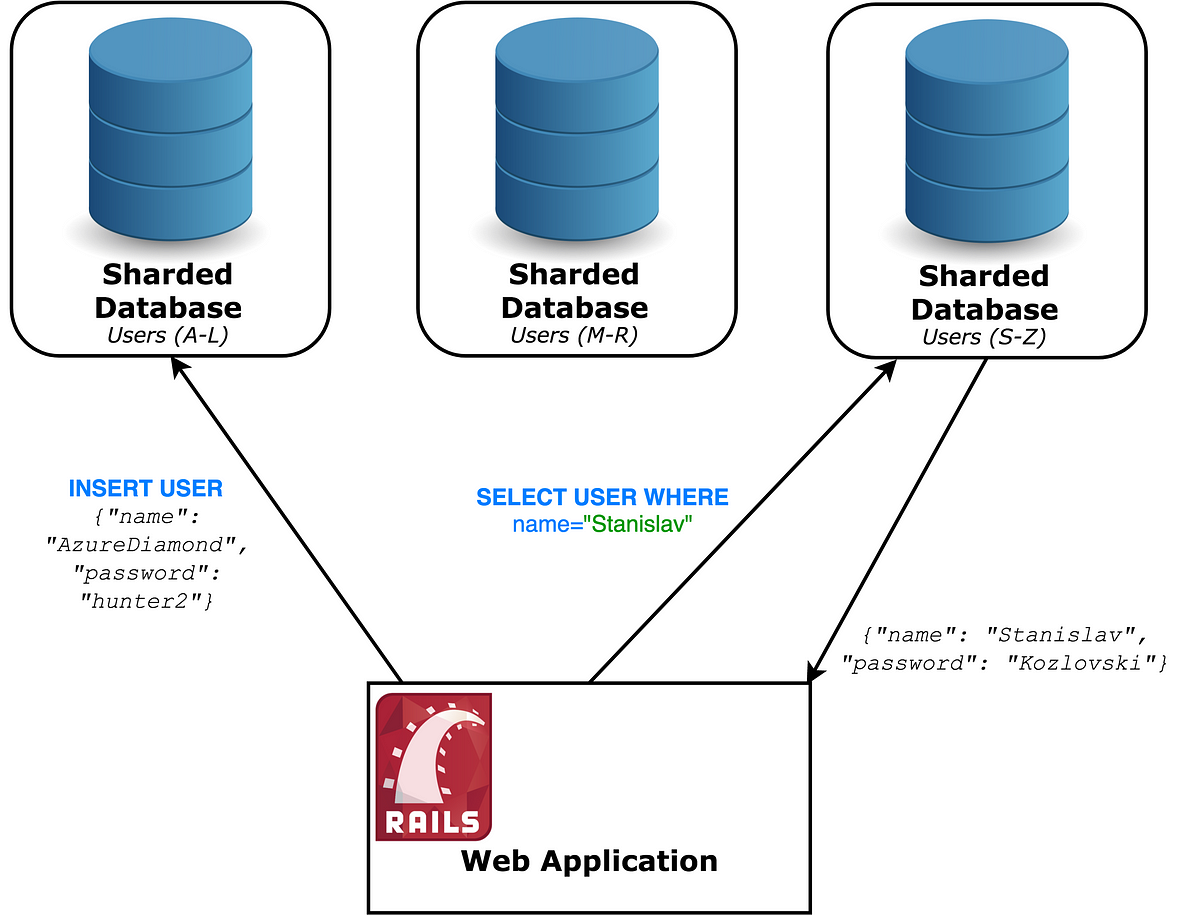
このシャードキーはかなり慎重に選ばなければなりません。というのも任意の列に基づく負荷が常に一定であるとは限らないからです(例えばZで始まる名前の人より、 C で始まる名前の人の方が多い)。他のシャードよりも多くのリクエストを受け付ける単一のシャードは ホット・スポット と呼ばれ、回避しなければいけません。 Foursquareの不名誉な11時間にも及ぶ機能停止
と同様、
分割した時点で、再シャーディングされたデータは非常にコストの高いものとなり、大幅なダウンタイムを発生させる可能性があります。
例を簡単にするため、クライアント(Railsのアプリ)は各レコードに対してどのデータベースを使うのか分かっているものと仮定します。シャーディングには多くの方策があり、今回は概念を説明するための簡単な例であるということを忘れてはいけません。
現時点では多くの目的を達成しています。つまり、書き込みのトラフィックを N 倍に増加させることが可能です。ここで N はシャードの数です。これで実質的に、ほぼ無制限にできるということです。このパーティショニングで、どれぐらいきめ細かくできるか想像してみてください。
落とし穴
ソフトウェアエンジリアニングのすべては多かれ少なかれトレードオフであり、これも例外ではありません。シャーディングは、決して簡単な技法ではなく、 本当に必要になるまで 避けた方がよいでしょう。
今、途方もなく効率の悪い パーティション・キー以外の キーを用いてクエリを作っています。SQLのJOINクエリでさえ状態が悪くなり、複雑なものは実際に使用不能に陥ります。
自律分散型と分散型の対比
先に進む前に、2つの用語の区別をしたいと思います。
この2つの語は同じように聞こえ、論理的には同じ意味を含んでいるかもしれませんが、この差異は技術的にも政策的にもかなり大きな影響をもたらします。
自律分散型 とは、技術的意味において静的 分散型 ですが、自律分散型システム全体が1つの主体に保有されているわけではありません。どの企業も自律分散型システムを所有することはできません。そうでないと、それはもう自律分散型ではありません。
現在利用されているシステムのほとんどは、 分散型の集中管理システム と考えられるということです。そうあるべきものとして、存在しているのです。
考えてみると、参加者の一部に悪意があるケースを処理する必要が生じるので、分散化されたシステムを作るのはより難しいことです。お分かりのようにすべてのノードを自分で所有しているので、これは通常の分散型システムには該当しません。
注記:この定義は何度も 議論 されており、他のもの(ピアツーピアやFEDERATED)と混同されている可能性があります。 初期の文献でも、同様に異なるものとして定義されています 。にもかかわらず、定義として私が示したのは、ブロックチェーン仮想通貨が用語を普及させたので、もっとも広く使用されていると感じるからです。
分散型システムのカテゴリ
今から、数個の分散型システムのカテゴリを調べて、公に知られている最大規模のプロダクト使用法をリストアップしましょう。この記事を読む時点では、示されているこうした数値のほとんどは時代遅れになっており、ほぼ確実により大規模なものが登場しているということを考慮してください。
分散型データストア
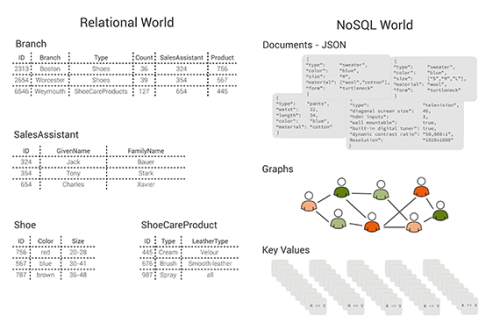
分散型データストアは、分散型データベースとして最も広く使用され、認識されています。分散型データベースのほとんどは、 NoSQL のノンリレーショナルデータベースで、key-value型のセマンティックに限定されています。これは、一貫性や可用性を犠牲にして、驚異的なパフォーマンスやスケーラビリティを実現します。
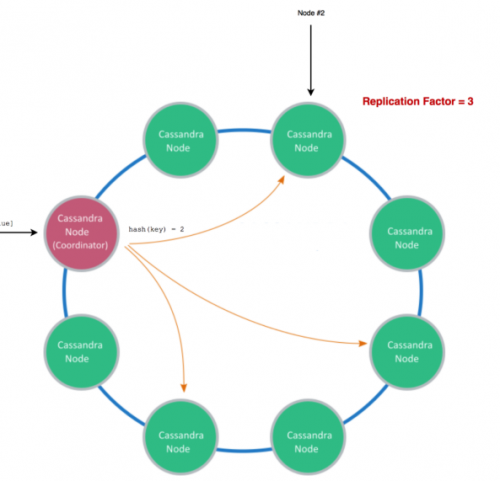
既知の規模 – 去る2015年、 Appleは10ペタバイトを上回るデータを保存する75,000個のApache Cassandraのノードを使っていたことが知られています
CAP定理 の紹介をせずに、分散データストアの議論は始められません。
CAP定理
2002年に実証済みの方法 で、 CAP定理では分散型データストアは、一貫性、可用性、分断耐性を同時に成立させることはできないと述べられている。
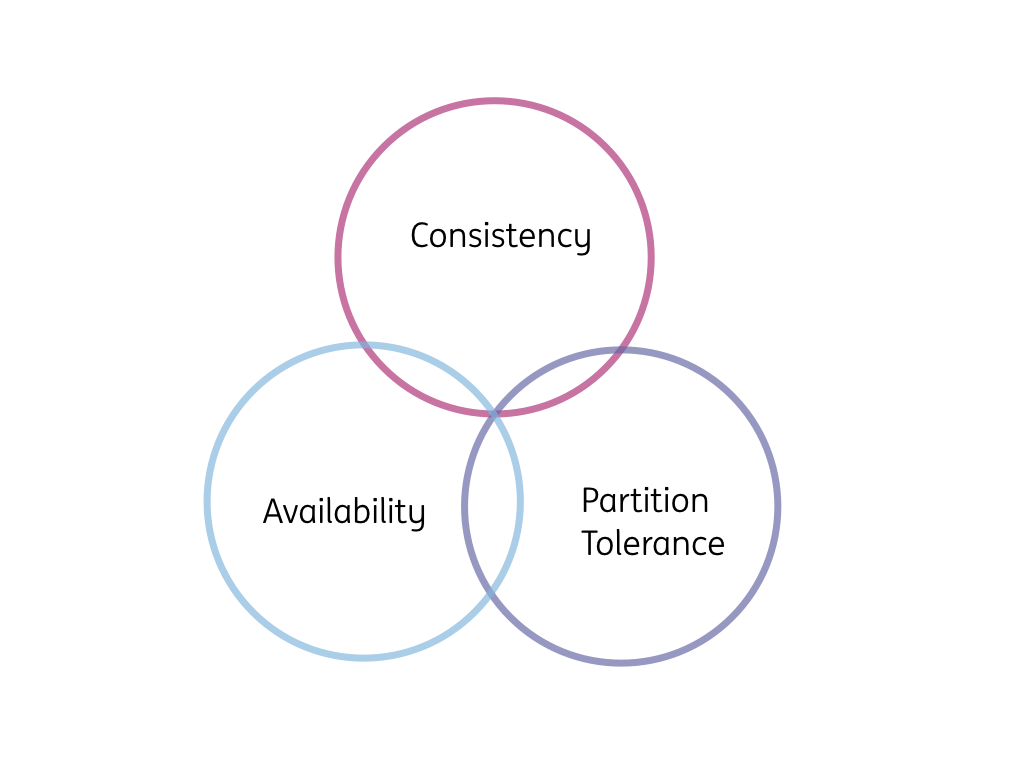
注釈:
Consistency:一貫性
Availability:可用性
Partition Tolerance:分断耐性
3つのうち2つを選択する(ただし一貫性と可用性の組み合わせではない)
簡単な定義:
- 一貫性 – 連続して読み込みや書き込みをすると、期待どおりに行われる。
(数段落前のデータベースのレプリケーションで”はまった”ことを覚えていますか?) - 可用性 – システム全体は停止しない。正常なノードは常にレスポンスを返す。
- 分断耐性 – ネットワークが分断 しても、システムは機能し、一貫性と可用性の保証を維持し続ける。
実際には、分断耐性はあらゆる分散型データストアに付与されなければなりません。多くの場所で述べられているように、分断耐性が無ければ、一貫性も可用性も保つことができません。 その記事のうちのひとつがこちらです 。
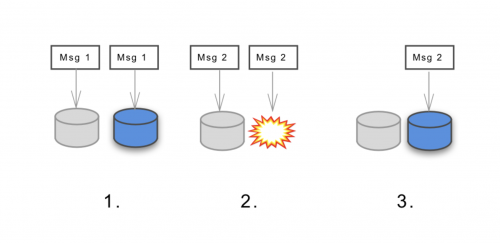
考えてみてください。情報を受け付けるノードを2つ有していて、そのコネクションが分断されてしまったら、どうすれば両方を使えるようになるのでしょう。またどうすれば同時に一貫性を保てるのでしょうか。互いに、一方のノードが何をしているのかを知るすべもなく、そういうものとして、オフライン( 利用不可 )になったり、古い情報で動作( 非一貫性 )したりするかもしれません。
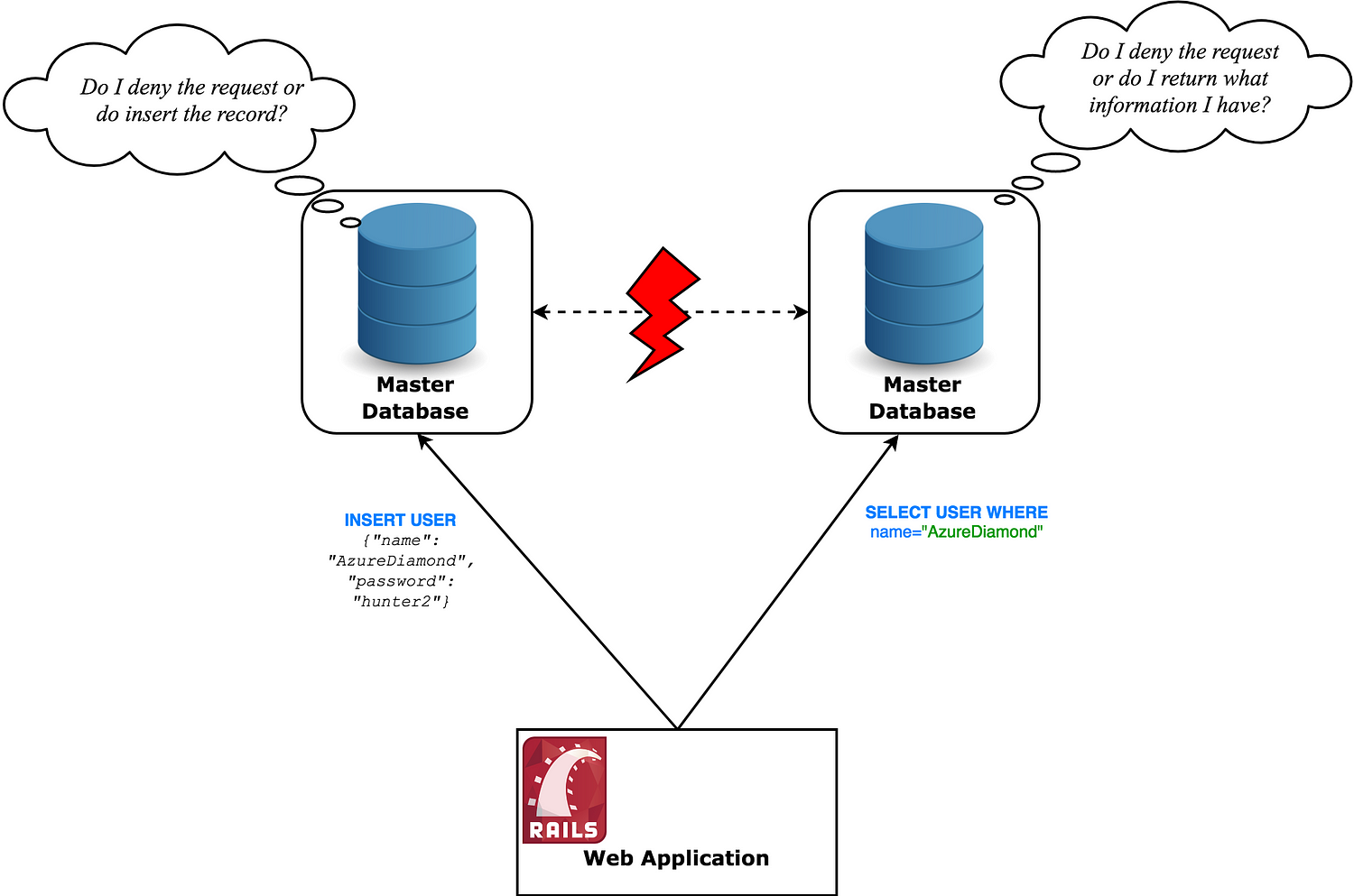
注釈:
(左)リクエストを拒否するか、レコードを挿入するか?
(右)リクエストを拒否するか、どのような情報をもっているのか返すのか?
どうするのでしょう?
最終的には、 ネットワークパーティション下 でシステムに強固な一貫性を持たせるのか、高い信頼性を実現するのかの選択を迫られます。
経験上、ほとんどのアプリケーションでは可用性に重きを置いています。強一貫性はいつも必ずしも必要とされているわけではありません。それでも、100%の可用性の確保が必要だからといって、必ずしもトレードオフが行われるということではなく、強一貫性を持たせるために、マシンを同期させなければならない場合に、ネットワークのレイテンシが問題になることがあります。これらも含めさまざまな要因のためにアプリケーションは高い可用性を要求するソリューションを選択するのです。
このようなデータベースは最弱の一貫性モデルである 結果整合性 ( 強一貫性と結果整合性の説明 ) に落ち着きます。このモデルは与えられたアイテムに対して新しいアップデートが実行されないなら、 最終的 にそのアイテムへのすべてのアクセスが最新のアップデート値を返すことを保証します。
これらのシステムは(昔ながらのデータベースのACIDとは対照的に) BASE プロパティを提供します。
- B asically A vailable(可用性が基本) – システムは常にレスポンスを返す
- S oft-state(厳密でない状態遷移) – システムはインプットが無い場合でも時間と共に変化する(結果整合性のため)
- E ventual consistency – インプットが無い場合には、データは遅かれ早かれすべてのノードに伝搬する
このような利用可能な分散型データベースの例は次のとおりです。 Cassandra 、 Riak 、 Voldemort
もちろん、強一貫性を優先した他のデータストアもあります。 HBase 、 Couchbase 、 Redis 、 Zookeeper
CAP定理はそれだけで複数の記事が書けるほどの価値があります。どうやって システムのCAPプロパティを調整 するのかや、 正しく理解されないわけ などがあります。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事