2015年10月5日
マルチモデルデータベースを用いたデータモデリング
(2015-07-07)by Max Neunhöffer
本記事は、原著者の許諾のもとに翻訳・掲載しております。
同じデータストア内に異なるデータモデルを適合させるためのケーススタディ。
最近になって、”多言語パーシステンス”という考えが新たに登場し、ポピュラーになってきました。参考として、 Martin Fowlerが自身のブログに投稿した素晴らしい記事 をご覧ください。Flowerの基本的な考えを解釈すれば、大規模なソフトウェアアーキテクチャにおけるパーシステンス層の異なる部分に対して、適切なデータモデルを色々と使うことは有益である、ということになります。このことから、例えば、永続的に構造化されるリレーショナルデータベースには表形式のデータ、非構造化データ向けのドキュメントストアにはオブジェクトライクなデータ、ハッシュテーブル向けのキー/バリューストアには高度に関連付けられた参照データ向けのグラフデータベースを使うこともできるということです。従来の考え方では、これは同一のプロジェクト内で複数のデータベースを使用しなければならないことになるため、操作上の摩擦(より複雑なデプロイメントになり、より頻繁な更新が必要になる)、データの整合性や重複といった点での問題が起きると考えられてきました。
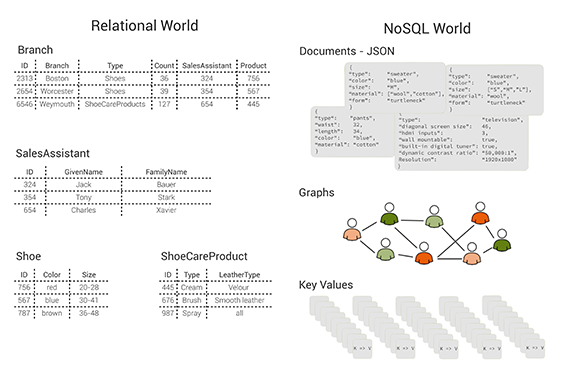
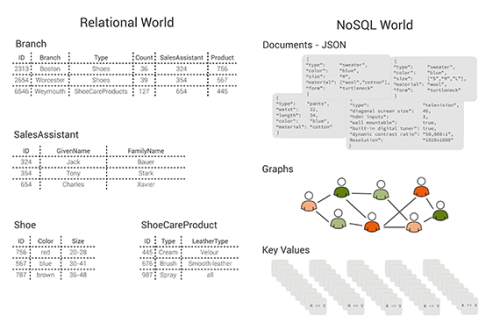
注釈:Relational World:リレーショナルの場合
Branch:部門
Sales Assistant:店員
Shoe:靴
Shoe Care Product:靴用ケア商品
NoSQL World:NoSQLの場合
Documents – JSON:JSONドキュメント
Graphs:グラフ
Key Value:キーバリュー
図1:表、ドキュメント、グラフ、およびキーバリューペア:異なるデータモデル。(イメージ提供:Max Neunhöffer)
このように考えられていることが、マルチモデルデータベースの問題点なのです。この問題は次のような方法で解決することができます。ドキュメントストア(JSONドキュメント)、キー/バリューストア、およびグラフデータベースで構成されるマルチモデルデータベース、一体型のデータベースエンジン、統一的なクエリ言語、そしてこれら3つのデータモデル全てを1つのクエリに適合させることもできるAPIを使用するのです。技術的に詳しく踏み込んだ話をせずとも、特にこれら3つのデータモデルを使うことが妥当と言えるでしょう。その理由は、このようなアーキテクチャでは、クエリのパフォーマンスやメモリの使用量といった観点で、特殊ソリューションよりも勝っているからです。例えば、カラム(列)指向データモデルは意図的に排除されています。しかし、この組み合わせにより、ある程度ではありますが、複数のデータストアを必要とせずに多言語パーシステンスでのアプローチができるようになります。
見ただけでは、マルチモデルデータベースのコンセプトは分かりにくいので、簡単にこの考え方を説明しましょう。ドキュメントコレクション内のドキュメントには通常、ドキュメントの識別を解読する固有の主キーがあります。これによって、ドキュメントストアは、キーがストリング、バリューがJSONドキュメントとなるキー/バリューストアに自然となります。セカンダリインデックスがない場合、バリューがJSONであることにより、パフォーマンス上のペナルティを課せられることはなく、ある程度の柔軟性を持たせてくれます。グラフデータモデルは、各頂点のJSONドキュメントと各エッジのJSONドキュメントを保存することにより実装されます。エッジは特別なエッジコレクションに保持されており、これは、全てのエッジが各エッジの始点と終点の頂点を参照する”from”と”to”属性を持っていることを保証します。3つのデータモデルに対してこのようにして統合したデータを持つことは、ユーザがドキュメントクエリ、キー/バリュー検索、”グラフィクエリ”、そしてこれらの組み合わせを可能にする共通のクエリ言語を考案し、実装するという部分がまだ残っています。なお、”グラフィクエリ”に関してですが、ここでは例えば”最短パス”や”グラフトラバーサル”、”近傍点”といったエッジに関連する特定のコネクションの特徴を持つクエリを指しています。
航空会社の管理する機体のメンテナンス:ケーススタディ
マルチモデルデータベースの持つ柔軟性が極めて効果を発揮するケースの一つが、航空会社の所有する機体のメンテナンスというような大規模な階層型データの管理をする場合です。航空会社は航空機を何機も所有していますが、典型的な機体は副部品から大小の部品まで数百万のパーツで構成されています。これらは、階層全体の”アイテム”を構成する情報として必要になるものです。このように何機もの機体を対象に行うメンテナンスを体系化するためには、こうした階層の異なるレベルで多数のデータを保存しなければなりません。パーツや部品の名前、シリアル番号、製造元の情報、メンテナンスの間隔、メンテナンスの実施日、下請業者、マニュアルやドキュメントへのリンク、担当者、保証およびサービス契約情報などがありますが、これでもほんの数例でしかありません。通常、データの一つ一つは、上の階層にある特定のアイテムにぶら下がっています。
情報を提供し、問い合わせに答えるために、こうしたデータで追跡するのです。問い合わせというのは以下の例を含みますが、これらに限定されるということではありません。
- 指定された部品に必要な全てのパーツとは何か?
- ある(故障した)パーツを前提としたとき、そのパーツを含む機体の最小の部品は何か? また、それに対してメンテナンスの手順書はあるか?
- 次の週にメンテナンスを必要としているのは、特定の機体のどのパーツか?
航空会社の管理する機体のデータモデル
では、自由に使えるマルチモデルデータベースがある場合、どのように航空会社の管理する機体のデータを形成すればいいのでしょうか?
やり方はいくつかあると思いますが、ここでは次の方法がいいでしょう(なぜなら、この方法だと要求されるクエリを全て迅速に実行できるからです)。階層内の各アイテムにはJSONドキュメントがあります。JSONには柔軟で再帰的な性質があるため、各アイテムについて、ほぼ任意の情報を保存することができます。また、ドキュメントストアはスキーマレスなため、航空機のデータが、エンジンや小ネジのデータと全く違う形式でも問題ありません。更に、包含関係については、グラフ構造として保存します。このグラフ構造では、機体群の頂点に各航空機の頂点へのエッジがあり、航空機の頂点には航空機を構成する主要部品へのエッジがあり、主要部品の頂点には部品を作る副部品へのエッジがあるというように、最後に小部品が含む個々の単一パーツのエッジに繋がるまで続きます。このように形成されたグラフは、正真正銘の有向木となります。
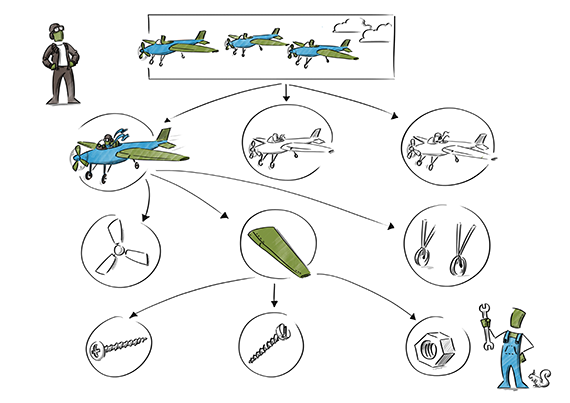
図2:アイテムの木。(イメージ提供: Max Neunhöffer)
この方法では、全てのアイテムを、ある単一の(頂点の)コレクションの中に置く、または異なるコレクションに分類することが可能です。例えば、航空機、部品、個々のパーツというようにグループ分けすることができます。グラフでは、どちらでも問題ありませんが、セカンダリインデックスを定義する場合はコレクションが複数ある方がいいでしょう。データベースに本当に必要なセカンダリインデックスを要求することができるので、私たちのアプリケーション特有のクエリが効果的に行えます。
航空会社の管理する機体のメンテナンスのクエリ
さて、それではデータに要求する可能性のある典型的な質問に戻り、どんな種類のクエリが必要になるのかを検討しましょう。また、 ArangoDB Query Language (AQL) を使うクエリの具体的なコードの例も見ていきます。
- 指定された部品に必要な全てのパーツとは何か?
このクエリには、グラフ内のある頂点を始点とし、その”下”にある全ての頂点が含まれます。つまり、末尾に向かってエッジを追っていき、到達できる全ての頂点を探さなければいけません。これはグラフトラバーサルといい、典型的なグラフのクエリです。
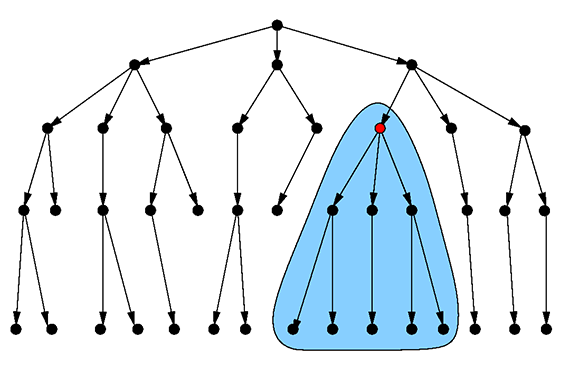
図3:指定された部品に必要な全てのパーツを探す。(イメージ提供 : Max Neunhöffer)
このタイプのクエリは以下のようになります。このコードで、” components/Engine765 “を始点にしてグラフトラバーサルを行い、それによって到達できる全ての頂点を見つけることができます。
RETURN GRAPH_TRAVERSAL("FleetGraph",
"components/Engine765",
"outbound")ArangoDBでは、名前を与え、どのドキュメントコレクションが頂点を含み、どのエッジコレクションがエッジを含むかを指定することでグラフを定義できます。頂点であるか、エッジであるかには関わらず、ドキュメントは _id 属性によって一意的に識別されます。これにはコレクション名で構成される文字列で、スラッシュ(/)と主キーが含まれます。そのため GRAPH_TRAVERSAL の呼び出しには、グラフ名の” FleetGraph “と始点となる頂点、そして追うエッジの方向を示す” outbound “の記述のみが必要となります。更に、オプションを指定することも可能ですが、ここでの説明とは関連しません。AQLは、このタイプのグラフィクエリを直接サポートします。
- ある(故障した)パーツを前提としたとき、そのパーツを含む機体の最小の部品は何か? また、それに対してメンテナンスの手順書はあるか?
これを見つけるためには、ある葉となる頂点を始点とし、メンテナンスの手順書がある部品に到達するまで木をさかのぼっていきます。これについては、関連するJSONドキュメントで確認することもできるでしょう。これもアプリオリではステップ数が分からないため、典型的なグラフィクエリといえます。ただし、今回の場合に限っては、上方に常に1つのエッジしかないため、比較的簡単な方法となります。
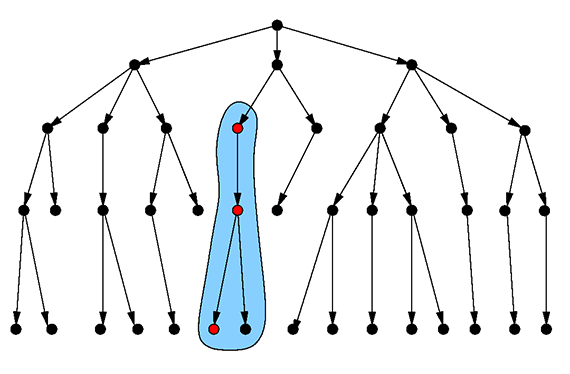
図4:メンテナンスできる最も小さい部品を探す。(イメージ提供: Max Neunhöffer)
以下は” parts/Screw56744 “から、ある頂点の isMaintainable 属性までの最短距離を見つけるAQLクエリの例で、ブール値はtrue、追うエッジの方向は” inbound “となっています。
RETURN GRAPH_SHORTEST_PATH("FleetGraph",
"parts/Screw56744",
{isMaintainable: true},
{direction: "inbound",
stopAtFirstMatch: true})ここで大切なのは、グラフ名、始点となる頂点の _id 、目標となる頂点のパターンを指定するということです。具体的な _id を代わりに与えたり、最後の引数が示す進行方向に別のオプションを加えたりすることもできるかもしれませんが、やはりAQLがグラフィクエリ を直接サポートする様子を見ることとなります。
- 次の週にメンテナンスを必要としているのは、特定の機体のどのパーツか?
これはグラフ構造に全く関係のないクエリとなります。むしろ、グラフ構造を直交するような結果となる傾向にあります。それでも、このクエリには正しいセカンダリインデックスを含むドキュメントデータモデルがぴったりです。
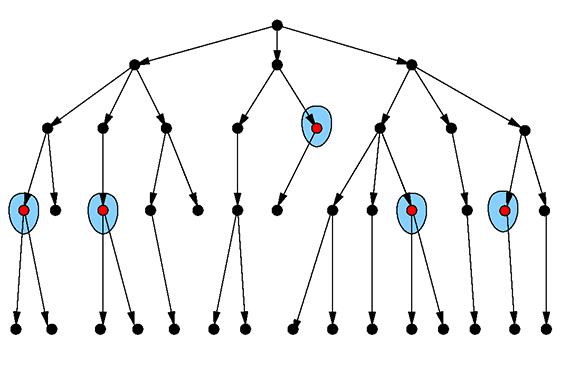
図5:結果がグラフ構造に直交するクエリ。(イメージ提供: Max Neunhöffer)
純粋なデータベースでは、このようなクエリが迅速に行われることはなく、むしろ問題が発生します。なぜならグラフ構造を理論的に使えず、セカンダリインデックスに頼らなければいけないからです。例を挙げると、次にメンテナンスするデータが記録されているのは属性上となります。グラフデータベースが頂点のデータ上にセカンダリインデックスを実装できるのは明らかですが、マルチモデルデータベースとなることが必要不可欠になります。
質問の回答を得るためには、グラフ構造を考慮しないドキュメントクエリを行います。メンテナンス予定の部品を見つけるクエリは以下となります。
FOR c IN components
FILTER c.nextMaintenance <= "2015-05-15"
RETURN {id: c._id,
nextMaintenance: c.nextMaintenance}このループは、AQLが components コレクション上での反復を記述する方法に似ています。クエリオプティマイザは nextMaintenance のセカンダリインデックスが存在していることを認識するため、 FILTER の条件を満たすために実行エンジンが全てのコレクションをスキャンする必要はありません。既知のデータから RETURN ステートメント内に新しいJSONドキュメントを形成するだけで、AQLは射影を指定できることを覚えておきましょう。まさに同じ言語が、通常のドキュメントストアで使われるクエリをサポートするのを確認できます。
マルチモデルのクエリを使う
マルチモデルアプローチの可能性を解説するために、3つのデータモデルを合わせたAQLクエリをここに示します。以下のクエリは、パーツのメンテナンス期限を見つけるところから始まります。各パーツに対して、上の最短経路の計算を実行し、結果に具体的な連絡先情報を追加するために、 contacts コレクションでJOIN演算を実行します。
FOR p IN parts
FILTER p.nextMaintenance <= "2015-05-15"
LET path = GRAPH_SHORTEST_PATH("FleetGraph", p._id,
{isMaintainable: true},
{direction: "inbound",
stopAtFirstMatch: true})
LET pathverts = path[0].vertices
LET c = DOCUMENT(pathverts[LENGTH(pathverts)-1])
FOR person IN contacts
FILTER person._key == c.contact
RETURN {part: p._id, component: c, contact: person}AQLでは、 document 関数の呼び出しが、提供された _id 属性を経由して、キー/バリュールックアップを実行します。これは、最短経路の計算のターゲットとして見つかった各頂点に対して行われます。最終的に、JOINのAQL公式を見ることができます。2つ目の FOR ステートメントは、 contacts コレクションを振る舞いにもたらします。そして、クエリオプティマイザは、JOINをすることによって、 FILTER ステートメントが最適とみなされることを認識します。これは、速いハッシュのルックアップに対して contacts コレクションのプライマリインデックスとして使うことができるので、とても効果的です。
これは、マルチモデルアプローチの可能性を示す典型的な例です。このクエリには、セカンダリインデックスのドキュメント、グラフィクエリ、そして素早いキー/バリュールックアップを備えたJOINの3つのデータモデル全てが必要です。3つのデータモデルが同じデータベースエンジンに存在して いなかったり 、同じクエリに適合させることができなかったりした場合、どんな困難が待っているか想像してみてください。
更に重要なことは、このケーススタディでは、3つの異なるデータモデルは、アプリケーションから生じた全てのクエリに対して、素晴らしいパフォーマンスをもたらす必然性があったことを示しています。グラフデータベースがないと、 アプリオリ ではないと知られている、パスの長さと併せたグラフィ特質のクエリは扱いにくく、効果を期待できない複数のJOIN演算になってしまうことで有名です。しかしながら、純粋なグラフデータベースは、正しいセカンダリインデックスを使うことによって効果的に得られるドキュメントクエリに対してニーズを満たすことはできません。効果的なキー/バリュールックアップは、データモデリングに更なる柔軟性を与える興味深いJOIN演算子を許可することによって、状態を補完します。例えば、上の状況では、各パスと一緒に全ての連絡先情報を組み込む必要はありません。なぜなら、最後のクエリでJOIN演算を実行することができるからです。
データモデリングから学んだこと
航空会社が管理する機体のメンテナンスのケーススタディでは、データモデリングそしてマルチモデルデータベースに関する重要なポイントがいくつか明らかになりました。
- JSONは、非構造化また構造化データのどちらにでも融通の利くフォーマットである。 JSONの再帰的な本質は、サブドキュメントの組み込みと可変長のリストを可能にします。加えて、JSONドキュメントとしてテーブルの行を保存することさえもできます。そして、最近のデータストアは、リレーショナルデータベースと比べると、基本的にメモリのオーバーヘッドがなく、データを圧縮するのに長けています。構造化データでは、必要に応じて拡張可能なHTTP APIを使って、スキーマ解析が実装されます。
- グラフは、リレーションにおける良いデータモデルである。 多くの実際のケースでは、グラフは非常に自然なデータモデルで、リレーションを取り、各エッジと各頂点と共にラベルの情報を持つことができます。JSONドキュメントは、このタイプの頂点やエッジデータを保存するために自然に適合します。
- グラフデータベースは、とりわけグラフィクエリに適している。 ここで重要なのは、クエリ言語は、”最短パス”や”グラフトラバーサル”といったように、決められた動作を実装しなければなりません。これらの基本的な能力は、頂点の送受信するエッジ全てのリストに素早くアクセスする点です。
- マルチモデルデータベースは、特殊ソリューションに勝る。 ドキュメント、キー/バリューそしてグラフといった3つのデータモデルの選択では、これらをコヒーレントなエンジンに組み合わせることを可能にします。組み合わせに妥協はありません。ドキュメントストアとしては、特殊ソリューションと同様に効果的ですし、グラフデータベースとしても、同様です(いくつかのベンチマークが こちらのブログに投稿 されています)。
- マルチモデルデータベースは、オペレーショナルオーバーヘッドを少なくして、異なるデータモデルを選択することを可能にする。 シングルデータベースエンジンで入手可能なマルチデータモデルを持つことで、同時に異なるデータモデルを使うときに直面するいくつかの問題を軽減します。なぜなら、オペレーショナルオーバーヘッドやデータの同期が少ないので、データモデリングの柔軟性が大幅に飛躍するからです。異なるデータモデルが必要だったとしても、同じデータストアに関連データを一緒に保持することができるという選択肢が生まれます。単独のクエリ内で異なるデータモデルを適合できるということは、アプリケーションデザインとパフォーマンスオプティマイザの選択肢が増えることになります。いくつかの異なるデータベースインスタンスにパーシステンス層を分ける選択をしたとしても(同じデータモデルを使う場合でも)、単一テクノロジーをデプロイするだけという利点があります。その上、データモデルのロックインを防ぐことができます。
- マルチモデルは、リレーショナルデータベースよりも大きなソリューションスペースを持っている。 普段なら続いて起こる摩擦を受けることなく、データモデリングの追加的柔軟性と多言語パーシステンスの利点という、クエリのこれら全ての可能性を考慮すると、マルチモデルアプローチは、リレーションデータベースのスペースよりも更に大きなソリューションスペースに対応していることになります。長年、リレーショナルモデルが、データベース市場そしてデータベースリサーチを独占していることを考えると、これはいっそう、驚くべきことです。
マルチモデルデータベースの活用
マルチモデルが活用できる、または必要とされるいつかの例を挙げます。
- ワークフロー管理ソフトウェア は、グラフと共にタスク間の依存性をしばしばモデル化し、いくつかのクエリはこれらの依存性を必要とし、その他は、これらを無視し残っているデータだけを見ます。
- ナレッジグラフ は、巨大なデータコレクションで、エキスパートシステムからのほとんどのクエリは、エッジとグラフィクエリのみを使っています。しかし、頂点のデータだけと考えるのであれば”直交”のクエリが必要となります。
- Eコマースシステム は、顧客のデータとプロダクトデータ(JSON)を保存する必要があり、ショッピングカート(キー/バリュー)、オーダー/セールス(JSONまたはグラフ)、そして推奨データ(グラフ)をサポートし、これらのデータアイテム全てを特徴付ける多くのクエリが必要となります。
- 企業の階層 は、グラフに適合しており、通常、グラフィとドキュメントクエリが適合された 権利管理 が必要となります。
- ソーシャルネットワーク は、巨大で、つながりの強いグラフの代表的な例です。通常のクエリはグラフィであるにも関わらず、実際のアプリケーションは追加のクエリを必要とします。このクエリはソーシャルリレーションを無視するので、セカンダリインデックスと恐らく、keyルックアップと一緒にJOINが必要となります。
- バージョン管理アプリケーション は、普通、有向非巡回グラフで機能します。しかし、グラフィクエリとその他のものも必要です。
- 複雑で、ユーザ定義のデータ構造である アプリケーションは、ドキュメントストアの柔軟性から劇的な利点を得ています。またこれは、グラフデータにとっても良いアプリケーションと言えます。
マルチモデルデータベースの将来
JSON、キー/バリュー、グラフの利用を必要としていているマルチモデルで製品化されているのは、現在2つだけです。 ArangoDB と OrientDB です。その他、”マルチモデル”の名前で市場に出回っている製品はいくつかありますが(概要は、 DB-enginesのランキング をご覧ください)、どれもグラフを持たず、オペレーションドメインをターゲットとしています。
また、従来のシングルデータモデルに特化した MongoDB や Datastax は、スコープの広がりの兆しを見せています。純粋なドキュメントストアであるMongoDBは、2015年3月に取り外しが可能なストレージエンジン、3.0をリリースしました。カラムベースストアのApache Cassandraを基盤とした市販用の製品を生産する企業、Datastaxは最近、分散型のグラフデータベースTitanDBを支える企業、Aureliusを買収しました。Appleは、上部にレイヤーを載せた異なるデータモデルのための複数の”パーソナリティ”で、分散型のキー/バリューストアを提供する FoundationDB を買収しています。
新しいデータベースの到来や、より実証されたデータベースは、マルチデータモデルに対するサポートをするというのが最近の流れになっています。同時に、多くのNoSQLソリューションが出始めていて、ACIDトランザクションやJOIN、比較的強い一貫性の保証など、リレーショナルデータベースの従来の長所が、再発見されています。
これらは、データモデラーやソフトウェアアーキテクチャにとって黄金期と言えます。引き続き、データベース市場におけるワクワクするような新しい開発に注目し、そして、かつてない種類の選択肢から得られる利点を楽しんでください。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事