2016年7月1日
MongoDBのクエリは必ずしもマッチするすべてのドキュメントを返すわけではない
本記事は、原著者の許諾のもとに翻訳・掲載しております。
データベースをクエリすると、一般的に、クエリにマッチするすべての結果を返すことが期待されます。最近、これがMongoDBには当てはまらないことを知り、驚きました。具体的には、クエリの実行中にドキュメントが更新された場合、更新前と更新後のドキュメントが共にクエリにマッチしたとしてもMongoDBのクエリが結果を返さないことがあるのです。MongoDBを使用する場合はこのようなことが起きることに注意し、クエリが犠牲にならないように気を付けましょう。
問題の発見
最近の私の主な仕事は、 Meteor Galaxyホストサービス のバックエンドの構築となっています。実行したすべてのコンテナの状態を含む多くのデータを MongoDB のデータベースで保存しています。コンテナは”起動中”、”正常”、”問題あり”、”停止”など、多くの状態を持っています。
我々のサービスのひとつが、データベースのポーリングを定期的に実行し、以下のクエリで実行中のコンテナの一覧を読み込んでいます。
containers.find({state: {$in: ['healthy', 'unhealthy']}})実行中のコンテナは”正常”状態と”問題あり”状態を行き来しますが、”停止”などの状態からは”正常”状態や”問題あり”状態に戻ることはありません。そのため、ある1回でのクエリで返されたコンテナがその後のクエリ結果に存在しなかった場合、2度と現れることはないはずです。
サービスのバグの調査中、1回目のクエリ結果に表示されたコンテナが2回目のクエリ実行では消え、3度目のクエリ実行では再度表示されていることが、たびたび(1日に何回か)ログを見て分かりました。これには驚きました。状態を書いた部分のコードにバグが存在したために正常な状態遷移に関する想定が外れたのだと思いました。
MongoDBのいいところは、 oplog にクエリをかけるとデータベースの履歴を見ることができることです。Oplogでコンテナドキュメントに変更がないか探してみました。反復したクエリから特定のコンテナが消えたのはいつだったのかおおよその時間をUNIXエポックタイムで計算してみました。
node> new Date("2016–03–011 07:22:53 GMT-0800").valueOf() / 1000
1457709773そして、MongoDBクラスタ内の”ローカル”データベースにログインし、1分前にoplogに対しクエリを実行しました(”addOption(8)”は”oplogコレクションで、クエリに’ts’が含まれているため、インデックスがなくても二分探索をする”ということを意味するマジックナンバーです。”batchSize(1)”が意味するのは、それぞれのエントリを見つけ次第クライアントにサーバから送られるということで、少ない結果を出力する遅いクエリを行う時には便利です)。
コンテナ状態の”起動中”から”正常”への遷移、そして、定期的な”正常”と”問題あり”の間での遷移のように、もっともな変化しか見られませんでした。この時点からクエリがマッチするドキュメントを返せば、この後もマッチするドキュメントを返すはずなのです。しかし、ログを見るとそうではなかったのです。特に、”問題あり”から”正常”に状態遷移した(1457709773)ころから、クエリに対してマッチする”{state: {$in: [‘healthy’, ‘unhealthy’]}”を返さなくなりました。
しかし、なぜ、更新前と更新後の両方でクエリにマッチしているのにMongoDBはこのドキュメントを返さなかったのでしょうか。
MongoDB:得体の知れないもの
MongoDBは、SQLデータベースのようなシステムやkey-value型データベース、GoogleのBigTableといったシステムの中間という興味深い位置にあるものなのです。
SQLデータベースは強力なトランザクション保証を提供し、クエリプランナによってユーザ定義のインデックスに対して、あらゆるクエリの実行が可能になります。しかし、スケーリングするためにデータがシャーディングされると、この保証は失われてしまいます。
スケーラビリティを追及するあまり、key-value型データベースやBigTableでは、1回の処理で任意のデータを変更することは許されていません。このため、ビルトインのインデックスやスクエリプランナがなく、作成すべきクエリを効率的に実行できるようにデータを構築するのは あなたの 仕事になります。
MongDBはこれらの中間に位置しています。一方では、基本的な原子性の単位はシングルドキュメントなので、1つのドキュメントに対してトランザクション処理を行うことは可能ですが、複数のドキュメントに対してはできません。もう一方では、MongDBはインデックスをサポートしており、クエリプランナもインデックスを使用することができます。
MongDBには、 その並行性の特性を記述した長いドキュメント があります。基本的な要点は、単一のドキュメントレベルでのみ一貫性を期待するべきであるとしています。そのため、 “ノンポイントインタイム(指定した時間に戻せない)読み込み処理” が提供されていても何ら不思議ではありません。ドキュメントコレクションに対し遅いクエリを実行している際にいくつかのドキュメントが更新された場合、更新前の状態のものもあれば、更新後の状態のものもあります。
さらに驚かされるのが、次の警告です。
マッチするドキュメントが読み込み処理中に更新された場合、読み込みがそれを見逃してしまうことがある。
まさに私が見た現象です。一体何が起きているのでしょうか。
実際MongoDB クエリはどのように動作するのか
MongoDBのクエリプランナは比較的簡単です(ここでは、地理空間やフルテキストインデックスのようなものを無視します)。ほとんどのクエリは、コレクション全体にわたって、あるいはインデックスのサブセット上で、単一のスキャンによって処理されます。スキャンをする際に特に大きなロックを行わないため、スキャン中にコレクションへの書き込みができてしまいます。しかし、単一のドキュメントを見ている間に書き込みを実行することはありません。
コレクション全体に対してスキャンをする場合、ドキュメントへの書き込みはスキャンがそのドキュメントに到達する前に起こるかもしれませんし、そうでもないかもしれません。しかし、コレクションのドキュメントを並び替えることは恐らくないでしょう(ドキュメントが大きくなりすぎ、移動しなければない場合のような時はありますが、WiredTigerより前のMMAPv1ストレージエンジン特有のものかもしれません)。
しかし、インデックスでのスキャンは少し違うのです。基本的にインデックスはドキュメントIDのリストで、まず、インデックスキーで分類され、その次にIDでソートされています。インデックスキーに影響を与えるような更新が生じた場合は、インデックス内で順番が変更します。これが、ポイントです。
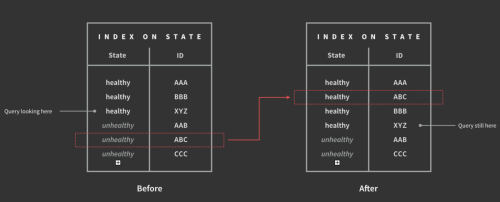
これを確かめましょう。コンテナテーブルに”状態”フィールドのインデックスがあります。これは、MongDBがすべてのコンテナのリストを管理していて、まず”状態”フィールドごとに分類され、次にコンテナIDごとに分類されていることを意味します。次のようにクエリを実行します。
containers.find({state: {$in: ['healthy', 'unhealthy']}})MongoDBでは、インデックスに対し二分探索で”正常”セクションの先頭を探し、それぞれの正常なコンテナIDに移り、メインコレクションストレージから完全なコンテナドキュメントを探し出します。”正常”セクションの最後まで行くと、次にインデックスの”問題あり”セクションの先頭から探し始めます。
しかし、このスキャンが実行されている間も書き込みは可能なのです。例えば、”正常”セクションの途中まで検索したとします。正常なコンテナでID”XYZ”を探しているとします。書き込みが行われ、コンテナ”ABC”が”問題あり”から”正常”へと遷移したとすると、このコンテナは書き込み前と書き込み後のクエリとマッチすることになります。しかし、この変更が書き込まれるとインデックスは”問題あり”セクションから”正常”セクションへと移動されます。しかも、すでにスキャンが終わったセクションに移動されることになるのです。
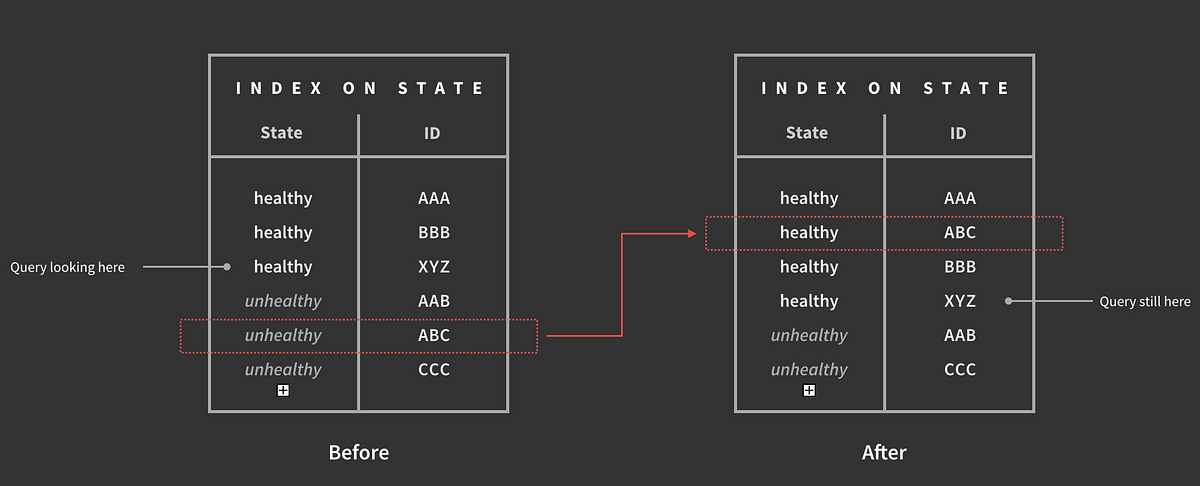
そのため、”問題あり”セクションをスキャンしても”ABC”は移動しているため見つかりませんが、スキャンの終わった場所に移動されているため”正常”セクション でも 見つかることはありません。
この特定のケースにおいては、簡単な対策があります。2つ目のインデックスとしてブーリアンフィールド”up”を追加し非正規化するのです。この”up”は、もし”状態”が”正常”や”問題あり”であればtrueに、そうでない場合はfalseにします。つまりクエリで”状態”を探す代わりに”up”を探します。書き込みはコンテナを”正常”や”問題あり”に遷移させますが、”up”に触れることはないため、この問題は起きません。
最終的には、インデックスを使用するクエリをすべて、システム全体をとおしてこの問題を起こすことはないか確認しました。幸いなことに、バックエンドサービスでは見られた問題はこれのみでした。
中間的位置の問題
この問題は、MongoDBがデータベースとして“中間的位置”を取っていることに起因していると思います。例えばインデックスやグローバルトランザクションのないBigTableを使用すると、最適化したいすべてのクエリに対して独自のインデックスを設定しなければなりません。書き込みによってコンテナがインデックステーブル間を移動している間にも別のクエリによるスキャンが実行されることはコード上で明確であり、データベースエンジンに隠されてしまうことはありません。SQLデータベースのようなもっと伝統的なトランザクショナルデータベースを使用すれば、このような問題に直面することはありません。 ACID が保証する”独立性”の部分で解決されます。
現在のMongDBモデルでも、インデックスでのスキャンとインデックスへの書き込みに依存性を持たせることで問題を解決することができます。ドキュメントがインデックス内を移動した場合に、実行中のスキャンに対してチェックを行い、関係があるかを確認することができます。つまり、クエリしてきたクライアントにいくつかのドキュメントをすでに返しており、そのインデックスがクライアントの指定するソート順序に持ちいられれている場合、移動したドキュメントの”新しい値”を返すことはできませんが、”古い値”でも問題はありません。
クエリがフィールドに複数の値を許さない場合でも、 インデックスが複数のフィールドを照会 すればこの問題は生じます。例えば、”people”コレクションに”(country, city)”の複合インデックスがあり(かつ、”country”単体に対してインデックスがない)、次を実行したとします。
people.find({country: "France"})すると、クエリが”country France, city Nice”をスキャンしている時に、ドキュメントが”country France, city Paris”から”country France, city Bordeaux”に書き込みによって変更されると、そのpersonは見逃されてしまうことになります。
まとめると
- この問題は、IDでドキュメントをクエリ検索する場合のように、インデックスを使用しないクエリには影響しません。
- この問題は、インデックスキーで使用される すべてのフィールド に対して、 単一の値の等値マッチ のを明示的に行うクエリには影響しません。
- この問題は、ドキュメントが最初に挿入された時から絶対に変更されないフィールドを持つインデックスを使用するクエリには影響しません。
- しかし、すべてのマッチするドキュメントを含め、その他のMongoDBのクエリでは問題が生じます。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事