2018年7月19日
分散型システム徹底入門 – Part 2.
本記事は、原著者の許諾のもとに翻訳・掲載しております。
Cassandra
先ほど触れたCassandraは分散型のNoSQLデータベースで、CAP定理のAとP(可用性と分断耐性)の特性を基準に最終的な一貫性が確保されています。ただ、このように言ってしまうと少し誤解を招くかもしれません。というのも、実際のところCassandraの設定は非常に柔軟性が高く、可用性を犠牲にして強い一貫性を提供することもできるからです。ですが、そうした使用ケースは一般的ではありません。
Cassandraでは、 コンシステントハッシュ法 を使って、渡そうとするデータをクラスタのどのノードが管理するのかを決めています。そしてその際は、データを複製するノード数を示す レプリケーションファクタ を設定します。
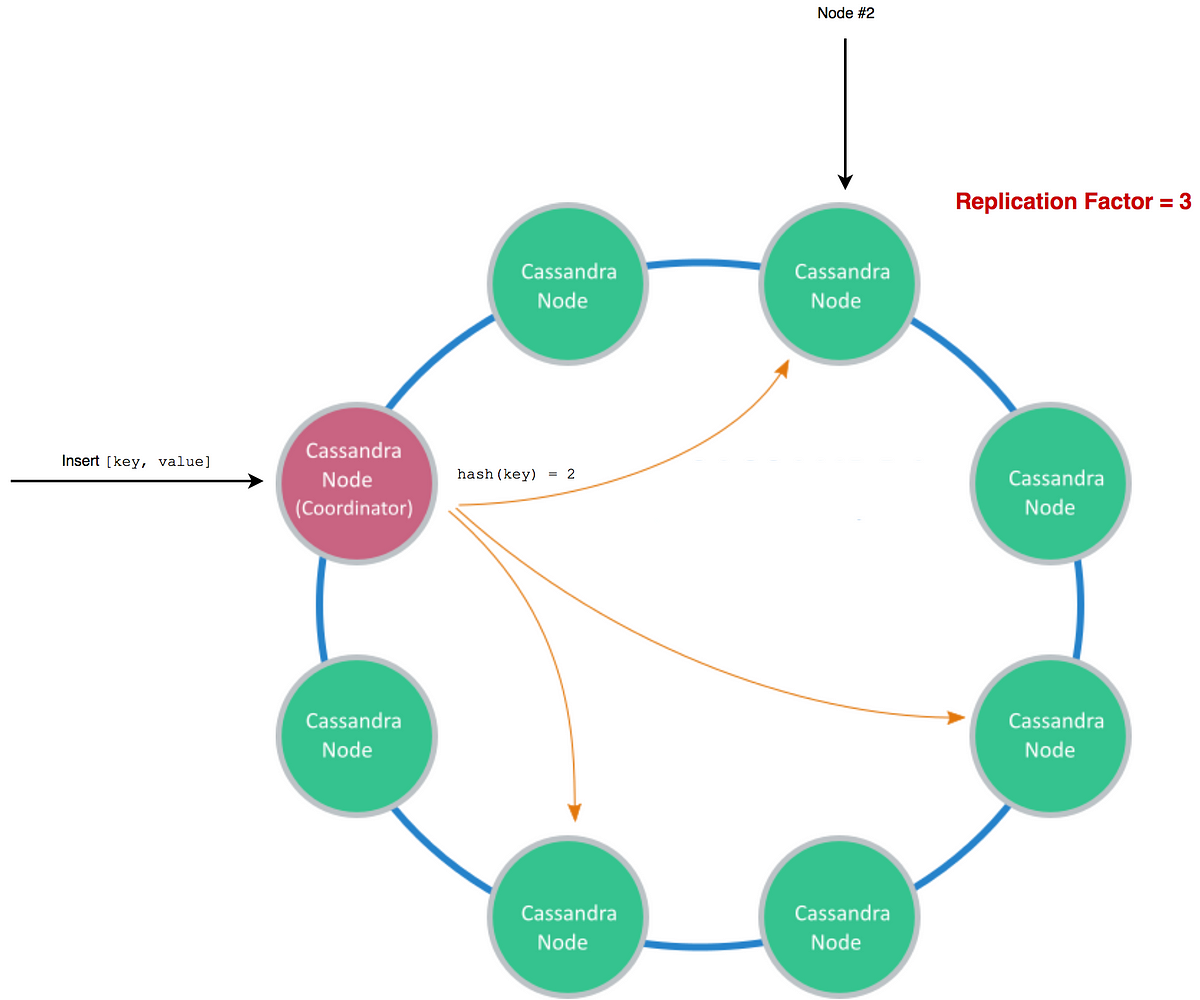
注釈:
レプリケーションファクタ=3
挿入(キー、値)
Cassandraのノード(コーディネータ)
Cassandraのノード
ハッシュ(キー)=2
ノード#2
書き込み例
読み込む際は、設定されたノードからのみ読み込みます。
Cassandraのスケーラビリティは非常に優秀で、驚異的な高さの書き込みスループットが提供されます。
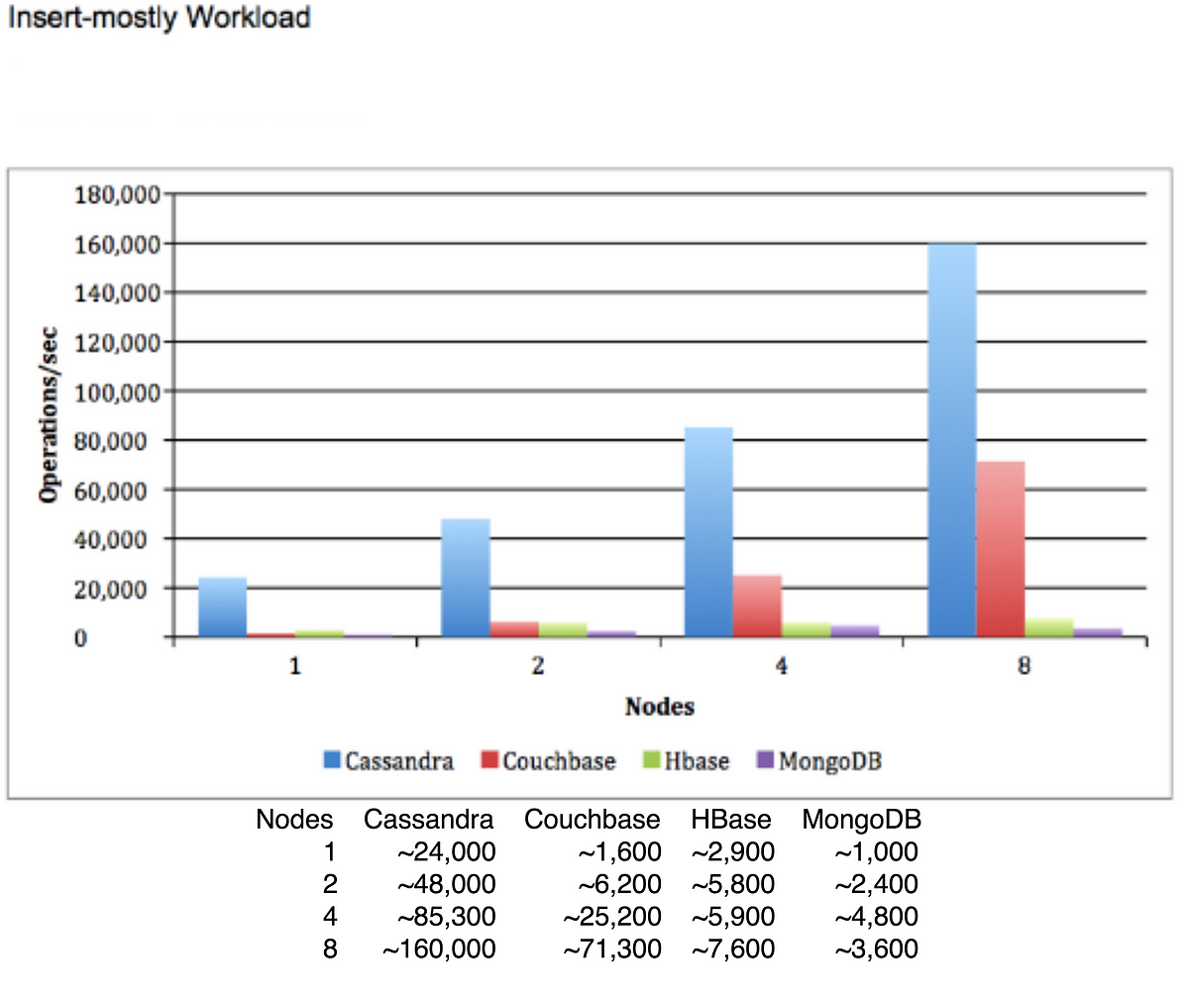
注釈:
挿入が大部分を占めるワークロード
オペレーション/秒
ノード
Cassandra
Couchbase
Hbase
MongoDB
多少偏りが見られる表ですが、これは1秒あたりの書き込みベンチマークを示しています。 参照先はこちらです 。
この表には多少の偏りはあるかもしれませんし、強い一貫性を提供するためのデータベースとCassandraを比較するための表にも見えますが(そうでなければ、4ノードから8ノードに上げた時にMongoDBでパフォーマンスが低下する理由が私には分かりません)、それでも、適切に設定されたCassandraのクラスタにどの程度の処理能力があるかというのは、この表から見てとれると思います。
ただし、こうした能力にもかかわらず、水平スケーリングと高いスループットを可能にする分散型システムのトレードオフとして、CassandraではACIDデータベースの基本的な機能、すなわちトランザクション機能がありません。
コンセンサス
分散型システムにデータベーストランザクションを実装するのは簡単ではなく、取るべき正しいアクション(アボートするのかコミットするのか)について各ノードに合意させる必要があります。 コンセンサス という言葉でご存じの方もいるかもしれませんが、これは分散型システムにおける基本的な課題の1つです。
仮に参加しているプロセスとネットワークが完全に信頼できるものであれば、”トランザクションのコミット”の課題に必要な種類の合意に達するのは難しくはないでしょう。しかし実際のシステムは、プロセスのクラッシュやネットワークのパーティション分割、メッセージの紛失や歪み、重複など、起こりうる数々の障害の影響下にあります。
問題となるのはここです。これまでは信頼性のないネットワーク上において、限られた時間枠内で正しいコンセンサスに達することを保証するのは 不可能だとされて きました。
しかし現実的には、信頼性の低いネットワーク上でも素早くコンセンサスに達することができるアルゴリズムはあります。実際Cassandraは、分散型コンセンサスに関して、 Paxos アルゴリズムを用いることで 軽量トランザクション を提供しています。
分散型演算
分散コンピューティング(分散型演算)は、近年盛んになってきたビッグデータの処理にとって鍵となるものです。これは、1台のコンピュータがそれ自体では実質的に処理できないような巨大なタスク(例えば、1000億レコードの集約)を、小さなタスクに分割して、一般的な商用コンピュータで処理できるようにするための技術と言えます。つまり、巨大なタスクを数多くの小さなタスクに分割し、多数のマシンで並列に実行させ、データを適切に集約するというわけです。これで巨大なタスクにおいて生じる問題は解決となります。このアプローチでも水平スケーリングの活用が可能で、ノードを追加することで、より大きなタスクに対応できるようになります。
> 既知の規模 – 2012年、約16万台のアクティブなマシン が Folding@Home で確認されています。
この分野の初期のイノベーターはGoogleです。彼らは増え続けるデータに対応するため、分散コンピューティングに関して新しいパラダイムを必要としており、それがMapReduceとなって実を結びました。 2004年にその論文 が発表され、その後、オープンソースコミュニティでは、MapReduceを元に Apache Hadoop が作成されています。
MapReduce
MapReduceは、簡単に言うと、データを マッピング(Map処理) し、それを何らかの意味あるものへと 束ねる(Reduce処理) という2つのステップから成ります。
例を挙げて、これを見てみましょう。
私たちがMediumサイトを運営しているとして、保管の目的で、分散型の補助データベースに巨大な情報を保存したとします。この中から、2017年4月(1年前)中のそれぞれの日に発行されたClaps(拍手)の数を表すデータを取得したいとしましょう。
この例自体はできるだけ短く、明確でシンプルにしたいと思っていますが、ここで扱うのは膨大なデータ(例:数十億のClapsの分析)です。この情報の全てを1台のマシンに保存するわけではなく、1台のマシンのみで全ての情報を分析することもありません。そして本番環境のデータベースにクエリを行うというよりは、優先度の低いオフラインジョブ専用に構築された”ウェアハウス(保管用)”データベースにクエリを行います。

注釈:
Mediumサイトの例
ID1-10,000,000のClaps
ID…のClaps
ID990,000,000-1,000,000,000のClaps
Mapジョブ#1
Mapジョブ#…
Mapジョブ#100
即時シャッフル、ソート、パーティションステップ
Mapジョブ#1 ローカルファイルシステム
Mapジョブ#… ローカルファイルシステム
Mapジョブ#100 ローカルファイルシステム
Reduceジョブ(4月1日)
Reduceジョブ(4月…日)
Reduceジョブ(4月12日)
Reduceジョブ(4月…日)
Reduceジョブ(4月30日)
出力
各Mapジョブは独立したノードで、できるだけ多くのデータを変換し、与えられたストレージノード内の全てのデータを辿って日付と1のシンプルなタプルにマッピングします。次に、シャッフル、ソート、パーティションの3つの中間ステップ(ほとんど言及されることはありません)が実行されます。この中間ステップによりデータはさらに整理され、Reduceジョブが適切に行われるよう束ねられます。この例ではデータが非常に大きいため、それぞれのReduceジョブにおいて、1日分のみが処理されるよう分離されます。
これは素晴らしい枠組みであり、驚くほど多くのことができるようになります。例えば、複数のMapReduceジョブをチェーンするといったことも可能です。
より優れた技術の登場
MapReduceは今では多少、過去の遺産と化したところがあり、いくつかの問題も抱えています。例えば、バッチ(ジョブ)で動作するため、ジョブが失敗した場合には全てを再起動しなければなりません。2時間のジョブの失敗は、データ処理パイプライン全体の処理速度に大きな影響を与え得るため、特にピーク時などにこうした問題が起こるのは、できれば避けたいでしょう。
結果を受け取るまでの時間も問題となります。(全てのシステムがビッグデータを保持し、分散コンピューティングを使用する)リアルタイムの分析システムでは、直近にクランチングされたデータの鮮度はできるだけ高くなくてはなりません。無論、数時間前のものなどは論外です。
こうした問題に対応すべく、他の アーキテクチャが紹介され始めました 。 ラムダアーキテクチャ (バッチ処理とストリーム処理のミックス)や カッパアーキテクチャ (ストリーム処理のみ)が、それに当たります。この進歩により、 Kafka Streams や Apache Spark 、 Apache Storm や Apache Samza といった新しいツールの登場が可能になりました。
分散型ファイルシステム
分散型ファイルシステムは、分散型データストアと同じものと考えてもいいかもしれません。1つのクラスタとして表示される複数のマシンを介して大量のデータの格納やアクセスを行うという点で共通の概念を有しており、基本的には分散コンピューティングと密接に関連して稼働します。
> 既知の規模 – 2011年、Yahooは600ペタバイトのデータを保存するために4万2000以上のノードでHDFSを稼動させました。
分散型ファイルシステムでは、Cassandra Query Language (CQL) のようなカスタムAPIではなく、ローカルファイルと同じインターフェースとセマンティクスを利用してファイルにアクセスすることが可能で、その点が両者の違いとしてWikipediaには挙げられています。
HDFS
Hadoop分散ファイルシステム(HDFS)は、Hadoopフレームワークによる分散コンピューティングに使用される分散型ファイルシステムです。(ギガバイトやテラバイトサイズなどの)大規模なファイルを多数のマシンに格納して複製するために使用されており、幅広い採用実績を誇っています。
アーキテクチャを構成する主なものは 名前ノード(Name Node) と データノード(Data Node) です。名前ノードは、クラスタに関するメタデータ(例えばどのノードにどのファイルブロックが含まれているかなど)を保持する役割を持ちます。ネットワークの調整役として機能し、システムの健全性を追跡しながら、ファイルの保存と複製に関して最適な場所を割り出します。一方、データノードの仕事は単純で、ファイルの保存や複製、新しいファイルの書き込みなどといったコマンドの実行を行います。
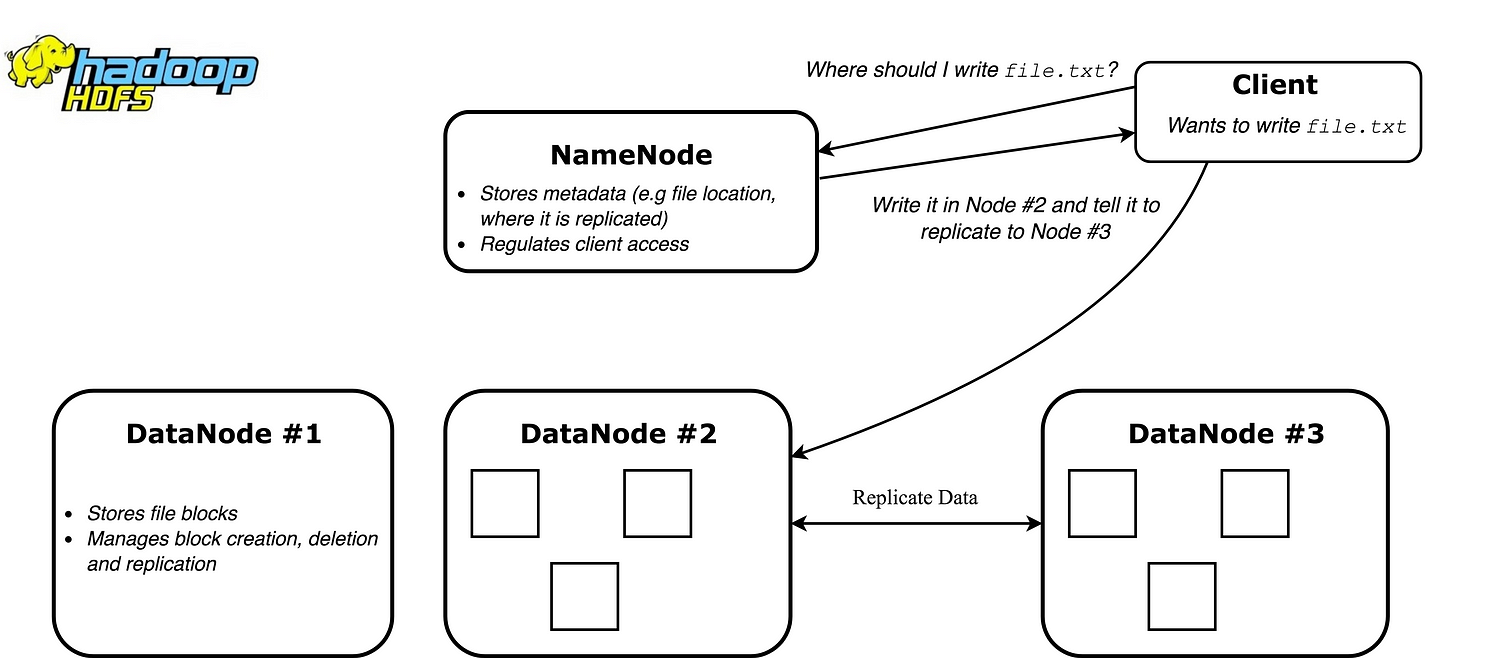
注釈:
クライアント
file.txtを書き込みたい
どこにfile.txtを書き込むべきか?
名前ノード
・メタデータを格納(例:ファイルの場所、複製される場所など)
・クライアントアクセスの制御
ノード#2に書き込んで、ノード#3に複製するよう指示
データノード#1
・ファイルブロックを格納
・ブロックの作成、消去、複製を管理
データノード#2
データの複製
データノード#3
HDFSは、計算ジョブにデータ指向(Data awareness)を提供するため、当然のことながらHadoopの計算処理で最もよく使用されます。それらのジョブは、次にデータを格納するノードで実行されます。この時、データローカリティが活用されることで計算の最適化が行われ、ネットワーク上のトラフィック量が削減されます。
IPFS
惑星間ファイルシステム(IPFS) は、分散型ファイルシステムにおける興味深い新たなピアツーピアのプロトコル/ネットワークです。ブロックチェーン技術の活用により、単一の所有者も単一障害点もない完全に分散化されたアーキテクチャを実現しています。
IPFSはIPNSと呼ばれる(DNSに類似した)ネーミングシステムを提供しており、これを通じてユーザは簡単に情報にアクセスできるようになっています。 Git のようなバージョン履歴管理方法によってファイルを格納することで、ファイルの以前の状態の全てにアクセス可能です。
現状はまだ開発の途上にありますが(本記事の時点ではバージョン0.4)、すでにそれを土台にしようとしているプロジェクトも散見されます( FileCoin )。
分散型メッセージング
メッセージングシステムは、システム全体において、メッセージ/イベントを格納し伝播するための中心となる場所を提供します。これを通じて、アプリケーションロジックと他のシステムとの直接的な対話を分離することができるようになります。
> 既知の規模 – LinkedInのKafkaクラスタは、1日に1兆件のメッセージ(ピーク時には1秒あたり4500万件のメッセージ)を処理しました。
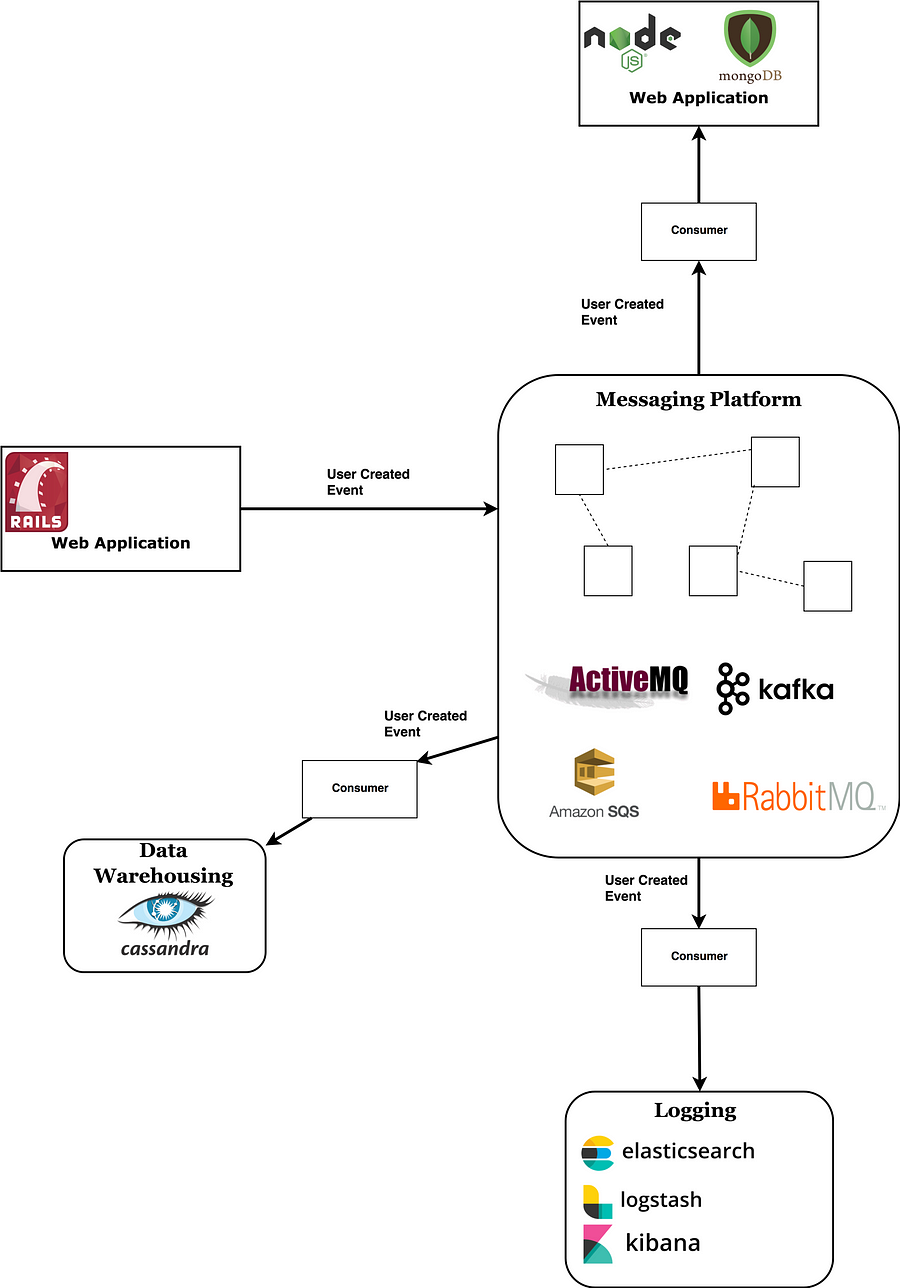
注釈:
RAILS Webアプリケーション
ユーザ作成イベント
コンシューマ
データウェアハウス Cassandra
メッセージングプラットフォーム
ロギング elasticsearch logstash kibana
簡単に言うと、メッセージングプラットフォームは次のように動作します。
まずはメッセージが、それを作成する側のアプリケーション( プロデューサ:送信元 )からブロードキャストされます。そして、作成されたメッセージはプラットフォームに入り、それに興味を示す複数のアプリケーション( コンシューマ:受信側 )によって読み取られます。
特定のイベントを複数の場所(例:ユーザが作成した場所からデータベースやウェアハウス、電子メール送信サービス、その他考えられる他の場所まで)に保存する必要がある時、メッセージングプラットフォームはそのメッセージを広める最もクリーンな方法と言えるでしょう。
情報の取得については、コンシューマがブローカから情報を引き出す場合(プルモデル)と、直接コンシューマに対してブローカに情報をプッシュさせる場合(プッシュモデル)があります。
以下に挙げるのは、人気の高い高性能メッセージングプラットフォームです。
RabbitMQ – ルーティングルールや簡単に構成できる他の設定を使用することで、メッセージの通り道を細かく制御できるメッセージブローカです。豊富なロジックを有し、通過するメッセージをしっかりと追跡することから、スマートブローカと呼ぶこともできます。 CAP定理 に関しては、 AP と CP の両方の設定が可能です。コンシューマへの通知にはプッシュモデルを使用しています。
Kafka – 既読メッセージの追跡や複雑なルーティングロジックがないため、多少、低い水準のメッセージブローカ(および全面的なプラットフォーム)と言えます。ただし、これは素晴らしいパフォーマンスの達成にとって足かせになるものではありません。オープンソースコミュニティでの積極的な開発と Confluentチーム からのサポートを背景に、この分野において今後、最も成長が見込まれるツールと言っても過言ではないでしょう。トップクラスのテック企業に間でも高い採用実績を誇っています。 以前、これについては徹底的に紹介した記事を書きました。その良さについて詳しく説明しているので、そちらもぜひご覧ください。
Apache ActiveMQ – 最古参のツールで登場したのは2004年です。JMS APIを使用していることから、Java EEアプリケーション向けと言えます。改変された ActiveMQ Artemis は、Kafkaと同等の素晴らしいパフォーマンスを提供します。
Amazon SQS – AWSが提供するメッセージングサービスです。既存のアプリケーションとの迅速な統合を可能にし、独自のインフラストラクチャを処理する必要性をなくします。セットアップが非常に面倒なKafkaのようなシステムと比べた場合、そのことは大きなメリットと言えるでしょう。Amazonは他にも2つの類似サービス、 SNS と MQ を提供しています。後者は、Amazonによって管理されていますが、基本的にはActiveMQと同じものです。
分散型アプリケーション
1台のロードバランサの背後で5台のRailsサーバをロールアップし(まとめ)、それら全てを1つのデータベースに接続した場合、それを分散型アプリケーションと呼ぶことはできるでしょうか。ここで前述した定義を振り返ってみましょう。
> 分散型システムは、エンドユーザには単一のコンピュータとして見えるように協働する複数のコンピュータの集まりと言えます。この複数のマシンは状態を共有し、並行して稼働しています。あるマシンに障害が発生した場合は、そのマシン単独の障害となるため、システム全体の稼働時間が影響を受けることはありません。
データベースが共有状態の時、それは分散型システムだと主張することはできなくはありませんが、定義の”協働する”がここでは抜け落ちているため、正しいとは言えません。
ノードが互いに連絡を取り合ってそれ自体のアクションを調整する場合にのみ、それを分散型システムと呼ぶことができます。
例えば、 ピアツーピアネットワーク 上でバックエンドコードを実行するアプリケーションのようなものは分散型アプリケーションとして分類してよさそうです。ただし、いずれにしてもこのような分類は無駄であり、物事をグループ化するのがいかに難しいかを示すだけで、それ以外には何の意味もありません。
> 既知の規模 – 2014年4月、BitTorrentのスウォームは、Game of Thrones(ゲーム・オブ・スローンズ)のエピソードにおいて19万3000ノードに達しました。
Erlang VM
Erlangは、並行性、分散性、フォールトトレランス性に優れたセマンティクスを持つ関数型言語です。Erlang Virtual Machine自体がErlangアプリケーションの分散を処理します。
このモデルは独立した多くの 軽量プロセス により機能し、その全てが組み込みのメッセージパッシングシステムを通じて相互に対話する能力を備えています。これは アクターモデル と呼ばれており、ErlangのOTPライブラリは、分散型のアクターフレームワーク(JVMの Akka と同じ系統)と考えることができます。
このモデルは優れた並行性をシンプルな形で実現するのに有効で、プロセスは、それらを実行しているシステムの利用可能なコアに分散されます。基本的に(メッセージを削除する機能を除き)ネットワーク設定とほとんど違いがないため、ErlangのVMは同じデータセンター内の他のErlang VMに(あるいは別の国にあるようなErlang VMにさえも)接続可能です。この仮想マシン群が1つのアプリケーションを実行し、テイクオーバーによってマシンの障害を処理します(別のノードに実行のスケジュールが割り振られます)。
フォールトトレランスについては、それを提供するために分散型の言語レイヤが追加されています。単一のマシン上で実行されるソフトウェアは、そのマシンが停止するとアプリケーションがオフラインになるというリスクが常にありますが、多数のノードで実行されているソフトウェアでは、アプリケーションがそれを念頭に置いて構築されてさえいれば、ハードウェアの障害時においてより簡単な対応で済むようになります。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事