2018年12月20日
大規模な決済システムを構築する際に学んだ分散型アーキテクチャの考え方 – 後編
(2018-4-16)by Gergely Orosz
本記事は、原著者の許諾のもとに翻訳��・掲載しております。
メッセージの耐久性と持続性
分散型システムのノードは演算し、データを保存し、互いにメッセージを送信し合います。メッセージ送信の重要な指標は、これらのメッセージがどれだけ確実に届くかです。基幹システムでは、消失メッセージがゼロでなくてはならない場合がしばしばあります。
分散型システムにおける通信は、RabbitMQ、Kafkaなどの分散型メッセージングサービスを用いることがほとんどです。こういったメッセージングサービスはメッセージ配信において様々なレベルの信頼性をサポートしています(または、サポートするように設定を変えられます)。
メッセージの永続性とは、メッセージを処理しているノードで何らかの問題が起こった時、その問題の解決後に処理されるよう、メッセージはそこに残ることを意味します。メッセージの持続性は多くの場合、 メッセージキュー レベルで用いられます。持続性のあるメッセージキューを実装すると、メッセージ送信時にキュー(またはノード)がオフライン状態だったとしても、オンライン状態に戻り次第メッセージを受信します。このトピックについては、 この記事 が参考になります。

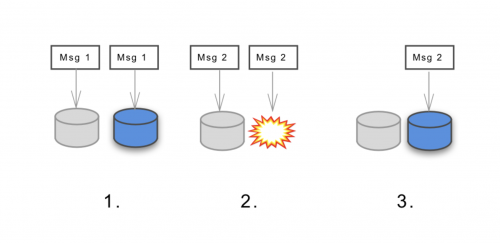
なぜ大規模決済システムを構築する際にメッセージの永続性と持続性が重要なのでしょうか? Uberでは消失しても許されるメッセージなどありません。例えば「ある人が乗車の決済を開始した」といった内容です。つまり、私たちが利用するメッセージングシステムはロスレスでなければなりません。全メッセージが必ず一度配信されなければならないということです。しかし、各メッセージを きっかり 1回配信するシステムを構築するのと、 最低 1回は配信するシステムを構築するのでは、複雑さの中身が違います。私たちは最低1回の配信を伴う持続性のあるメッセージングシステムを実装することにし、それを構築するメッセージングバスを選びました(最終的には、Kafkaに決め、このケース用にロスレスのクラスタを設定しました)。
冪等性
分散型システムでは、途中で接続が切れたり、リクエストがタイムアウトになったりして挙動がおかしくなることがあります。クライアント側はそのようなリクエストをよく再試行します。冪等性を備えたシステムでは、特定のリクエストが何度実行されたとしても、そのリクエストに対する実際の実行は必ず1度限りです。良い例は決済の実行です。クライアントが支払いをリクエストし、そのリクエストは成功したものの、クライアント側がタイムアウトになって同じリクエストを再試行したとしましょう。冪等性を備えたシステムなら、支払い者が2度請求されることはありません。冪等性のないシステムではその問題は起こり得ます。
冪等性を持たせる設計には、分散型システムにある種の分散型ロッキングの戦略が求められます。これは、先の分散型システムの概念のいくつかが関わってくるところです。楽観的なロックインの場所を設けて冪等性を実装し、同時更新を防ぐとします。楽観的なロックを備えるには、強い整合性を持つシステムが必須です。ヴァージョニングを使い、操作時に別の操作が開始されているかどうかをチェックできるようにするためです。
冪等性を持たせるには、システムの制限と操作のタイプによっていくつもの方法があります。冪等性のアプローチの設計は良いチャレンジです。 Ben Nadelが、分散型ロックやデータベース制限の両方を用いて自ら試した様々な戦略について書いています 。分散型システムを設計する際、冪等性は見過ごされやすい事柄のひとつです。私は、チームがいくつかの重要な操作に対して冪等性を正確に確保しなかったために苦労する、というシナリオに何度かぶつかりました。
なぜ大規模決済システムを構築する際に冪等性が重要なのでしょうか? 何よりも大事なのは、二重請求や二重返金を避けることです。メッセージングシステムが最低1回のロスレス配信なら、全てのメッセージが複数回送信される可能性があり、システムに冪等性の保証が必須になってくることを想定する必要があります。私たちは、ヴァージョニングと楽観的ロックを選ぶことにしました。冪等な振る舞いを実行するシステムが、データソースとして整合性の強いストアを用いるような形で実装したのです。
シャーディングとクォーラム
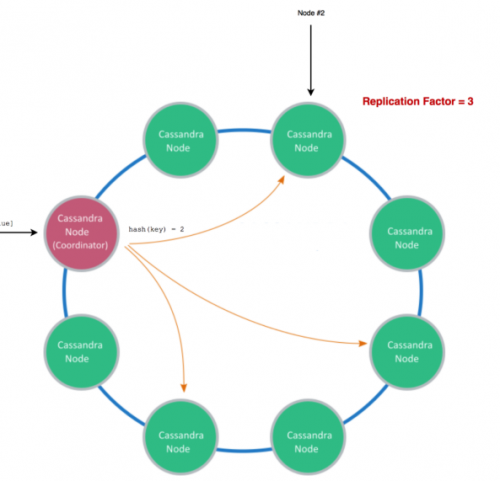
分散型システムでは、ノードひとつで格納できるデータより、ずっと多くのデータを格納しなくてはなりません。では、ある一定数のマシンに大量のデータを格納する場合、どうしたらよいでしょうか? もっとも一般的な方法は、 シャーディング を使うやり方です。データを、パーティション割り当てを決めるある種のハッシュを使って、水平に分割します。このシャーディングは、多くの分散型データベースが内部に実装しているものですが、特に 再シャーディング は詳しく学んでみると興味深いです。Foursquareでは2010年に17時間のダウンタイムがありました。これは、シャーディングのエッジケースに当たったことにより引き起こされたものでしたが、その際に行われた、根本的な原因についての 素晴らしい事後分析がシェア されています。
多くの分散型システムは、データや演算を複数のノードにコピーさせています。オペレーションが一貫した方法で実行されるようにするために、このうち一定数のノードで同じ結果が返されなければ操作が成功しない、という投票ベースのアプローチが定義されています。これをクォーラムと呼びます。
なぜUberで決済システムを構築する際にクォーラムとシャーディングが重要だったのでしょうか? これらはいずれもよく使われている基本的な概念なのです。私個人としては、Cassandraのコピーをどのようにセットアップするか検討していたときに、この概念に出会いました。Cassandra(その他の分散型システムも含め)は、 クォーラム とローカルクォーラムを使ってクラスタ間の一貫性を保証しています。笑えるのは、打ち合わせの度に、人が集まるなり上げられる第一声が、「始めていいですか? クォーラム、使ってますよね?」というぐらい定番になっていたことです。
アクターモデル
通常、プログラミングにおけるプラクティスを記述するために使っている、変数、インターフェース、メソッド呼び出しといった言葉は全て、単体のマシンシステムを前提としています。分散型システムを記述する際は、また別のアプローチを使う必要があります。一般的なのは、 アクターモデル です。この方法は、コミュニケーションという観点でコードを考えます。例えば、組織の中で人々がどのようにコミュニケーションしているかを表現する場合のように、私たちが意識的に何かを考えるときと同じように考えられるため、人気があります。もうひとつ、分散型システムを記述する一般的な方法と言えば、 CSP(Communicating Sequential Processes) もあります。
アクターモデルは、お互いにメッセージを送信し、それらに反応するアクターに基づいています。各アクターは限られたセットしか行うことはできません。他のアクターを作ったり、他のアクターにメッセージを送ったり、次のメッセージで何をすべきかを決めるといったことだけができるものです。これらにいくつかの簡単なルールを使うと、複雑な分散型システムでもうまく記述することができるのです。アクターがクラッシュした際にシステムを修復することもできます。アクターモデルの概要をつかむなら、 Brian Storti の書いた記事 「10分で分かるアクターモデル」 をおすすめします。多くの言語で アクターライブラリやフレームワーク が実装されています。例えば、Uberではいくつかのシステムに Akkaツールキット を使っています。
なぜ大規模決済システムを構築する際にアクターモデルが重要だったのでしょうか? 共にシステムを構築した多くのエンジニアのうち、大多数が分散型システムの経験が豊富なエンジニアでした。そのため、改めて分散の概念から考えること、つまり分かりきったことを一からやり直すようなことはスキップし、スタンダードな分散型モデルを採用することに決めたのです。
リアクティブアーキテクチャ
大規模分散型システムを構築する場合は通常、耐障害性、弾力性、拡張性のあるシステムにすることが目標となります。これが、決済システムでも何でも、高負荷なシステムでは、これを実現するときのパターンは似たものになります。この業界では、こうした場合にうまく機能するベストプラクティスが発見され、それが共有されています。リアクティブアーキテクチャもこの分野では一般的で、広く使われているパターンです。
リアクティブアーキテクチャを始めるなら、 Reactive Manifesto を読み、 「こちらの12分もかからない動画」 をご覧になってみてはいかがでしょうか。
なぜ大規模決済システムを構築する際にリアクティブアーキテクチャが重要だったのでしょうか? 新たな決済システムを構築するために多く使っていたツールキット、Akkaは、リアクティブアーキテクチャの影響を強く受けました。このシステムを構築しているエンジニアの多くは、リアクティブアーキテクチャのベストプラクティスにも精通していましたから、ごく自然な流れで、原則に従って応答性、耐障害性、弾力性のあるメッセージ駆動型システムを構築するということになりました。進めている方向に間違いがないか、モデルを基本にしながら進捗を確認していく進め方はやりやすいものでした。私は今後のシステムを構築する際にも、このモデルを使うと思います。
まとめ
Uberの核ともいえる決済機能、この大規模で分散型の基幹システムの再構築に参加できるなんて、私はラッキーでした。この環境で作業することで、これまで使う必要のなかった分散の概念を数多く獲得することができました。今回は、これから分散型システムに関する学習を始めようとする人や、これまでどおり継続していこうという人に役立つことを願い、以上をまとめてきました。
この記事は特に、これらのシステムのプランニングとアーキテクチャに重点を置いたものになっています。信頼性の高い運用が求められる高負荷システムにおける構築、導入、移行に関して話したいことはたくさんあるのですが、そうしたトピックについてはまた別の記事にしたいと思います。
追記: この記事は Hacker News と Reddit でも広く話題になりました。
Gergely Orosz
人々に愛され、日々使われる製品を作ることに情熱を注ぐ。エンジニア兼エンジニアリングリーダー。現在はUber、以前はSkyscannerならびにSkypeでも活動。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事