2015年10月9日
深層畳み込みニューラルネットワークを用いた画像スケーリング

本記事は、原著者の許諾のもとに翻訳・掲載しております。
この夏、私はカリフォルニア州パロアルトにあるFlipboardでインターンとして仕事をしました。私はそこで機械学習関係の問題に取り組んだのですが、その一つが画像のアップスケーリングでした。この記事では予備的結果を紹介し、また私たちのモデルとFlipboard製品への応用の仕方について議論していきたいと思います。
Flipboardのデザイン言語では、上質で印刷物のような仕上がりにすることが重要とされています。コンテンツ全体を通して、ユーザには安定感と美しさを楽しんでほしいと思っています。まるで自分専用に印刷された雑誌を手に持っているかのような体験を提供したいのです。このような体験を一貫して提供するというのは難しいことです。画像の質などといった様々な要素が、表示するコンテンツ全体の品質に大きく影響するのです。画像の質は、その画像のソースによって大きく変化します。フルブリード形式の、ページ全体に画像を載せる雑誌などでは、この画像の品質のばらつきが特に明確になります。
Webや携帯デバイスに画像を表示する場合、きちんと表示するには画像の品質が一定のラインを越えていなければなりません。私たちのWebプロダクト上の大きな画像を使えば、息をのむようなフルブリードのページを作成できます。

注釈:フルブリードの高品質な画像
解像度が低い画像は、100%を超えて拡大するとピクセレーションや過平滑化、アーティファクトを引き起こします。下の画像をご覧いただくと分かるように、これはフルブリードで表示する場合に最も顕著に表れます。この画像は私たちの製品における表示品質を大幅に低下させます。

注釈:フルブリードの低品質な画像
原因は何でしょうか。一般的に、サイズXの画像をサイズYにしたい場合はスケーリングアルゴリズムを通さなければなりません。このアルゴリズムは、画像のピクセルを任意のサイズYにスケーリングするために数学的な演算を行うものです。用いられるアルゴリズムとしては、バイキュービック法、バイリニア法、ニアレストネイバー法などの補間法があります。上記に挙げたアルゴリズムの多くは、ピクセル値間の補間を行ってトランジションを作成します。これらのアルゴリズムは、周辺のピクセルを用いて新たな画像の中に何の値が入るべきかを推測します。画像をより大きなサイズにスケーリングする際に問題となるのは、画像中に埋めなくてはならない“新たな”値が多すぎる場合です。これらのアルゴリズムは、新たな値が何になるべきかを“推測”しなければならないのですが、そのせいで処理プロセスにノイズやハロー、アーティファクトといった誤差が生じる可能性が出てくるのです。
さらに先に進む前に、伝統的かつ畳み込みを取り入れたニューラルネットワークの概略をご紹介しておきたいと思います。これについてよくご存じの方は次の章に進んで頂いて結構です。ニューラルネットワークをご紹介したあとは、予備的結果、モデルアーキテクチャについての議論、デザインの決定、応用と続きます。
注意:今回の紹介の中では、ニューラルネットワークの種類ごとの微妙な違いについては説明していません。
ニューラルネットワーク
ニューラルネットワークとは、与えられたデータから学習することが可能な素晴らしい型のモデルです。広範囲にわたって応用が可能で、コンピュータビジョンや音声認識、自然言語処理といった多くの分野で近年再び盛り上がりを見せています。最近では、 画像のキャプション付け や Atariのゲーム に使われ、 自動運転車の技術の一端を担い 、また 言語の翻訳 などにも用いられています。
ニューラルネットワークは 畳み込み や 再帰型 など様々な形で存在し、それぞれが違った類いのタスクを得意としています。“モデル”の学習も存在します。教師あり学習と教師なし学習がありますが、ここでは教師あり学習のみに焦点を当てていきたいと思います。
教師あり学習 は、入力と出力の両方について学習を行うネットワークと説明できます。この“モード”は、入力値を与えられた時に新たな出力値を予測するのに用いられます。例えば、何千枚もの猫と犬の写真に人間がラベル付けをし、それをネットワークに学習させて、新たな写真を提示しそれが猫なのか犬なのかを問う、というような学習法です。
構造レベルの話をすると、ニューラルネットワークはフィードフォワードの図式であり、ユニットとして知られる各ノードが入ってきた入力値について非線形演算を行うものです。各入力値がウエイトを持っており、ネットワークはバックプロパゲーションと呼ばれるアルゴリズムを通してこのウエイトを学習することができます。
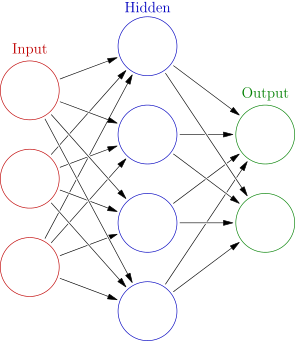
注釈:基本のニューラルネットワーク
引用元: Wikipedia
ニューラルネットワークの構造は柔軟で、目下のタスクを基にした構造をとります。属性を選択することで、簡単にネットワークをカスタマイズすることができるのです。属性の例としては、隠れ層(上の図では青のノード)の数、1層あたりのユニットの数、1ユニットあたりの結合の数などがあります。ハイパーパラメータと呼ばれるこれらの属性が、モデルの構造と振る舞いを描写します。高いパフォーマンスを得るためには、これらのパラメータを正しく選択することが非常に重要です。ハイパーパラメータは通常、無作為の グリッドサーチ や最適化アルゴリズム( ベイズ や 勾配型 )、または単なる試行錯誤を通して選択されます。
先に述べたように、ネットワークの中のユニットは入力値について数学的演算を行います。ここでは、数個の入力値を持つ1つのユニットを例に取り、簡単な数字を入れて計算を行い、さらに理解を深めていきたいと思います。
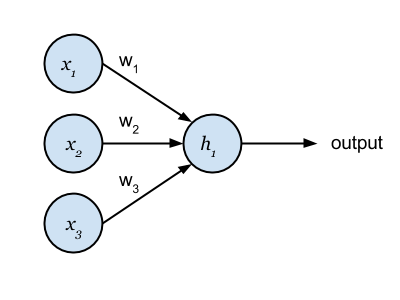
注釈:簡単なモデル
上記のユニットは、 x₁, x₂, x₃ という3つの入力値と、スカラのバイアス項 b (表示されていません)をとります。この入力値のそれぞれが、 w₁, w₂, w₃ と呼ばれる重み付けを持ちます。このウエイトは、入ってくる入力値の重要度を表します。この例では、ユニットの数学演算としてRectified Linear(ReL)関数を用います。もっと正式に言うと、活性化関数として知られるもので、下記のように表記されます。
f ( x ) = { x 0 if x > 0 if o t h e r w i s e
この活性化関数で大事なのは、ゼロ未満の入力値は全てゼロとし、ゼロより大きいものはそのままの数であるということです。出力値の範囲は [ 0 , ∞ ] となります。 シグモイド 、 双曲線正接 、 maxout など、他の活性化関数を使うこともできます。
では出力値はどのように計算するのでしょうか。これには f ( W T x + b ) という計算をする必要があります。まず初めに W T x と定義される転置 W と x 間のベクトル積を計算します。続いてこの結果にバイアス値を加算し、最後に活性化関数を通します。
この例をもう少し具体的に考えるために、ランダムな値を使ってみましょう。以下のように、ウエイト、入力値、そしてスカラのバイアス値に対応したベクトルがあるとしましょう。
W = [ 1 , 0.2 , 0.1 ] x = [ 0.74 , 5 , 8 ] b = 1.0
順に値を代入していくことで、 W T x の値を算出します。
1.0 ( 0.74 ) + 0.2 ( 5.0 ) + 0.1 ( 8.0 ) = 2.54
次にバイアス値を加えて、 W T x + b をします。
2.54 + 1.0 = 3.54
さらに、この計算結果を活性化関数である f ( x ) に適用します。
f ( 3.54 ) = 3.54
定義した関数によると、xが0より大きい場合は関数の値がxとなりますので、今回の場合は3.54が得られます。
この関数に心躍らされる理由は何でしょう。とは言っても、例に挙げた1ユニットのみを見ただけでは、それほど心躍る内容ではありませんね。今のところ、関数における最も基礎的な部分のみをモデル化するために、ウエイトとバイアス値を微調整しています。先ほどまで見てきた例は、“表現力”が欠けています。では、“表現力”を高めるために、ユニット同士をつないで関連づけ、以下に示すような、より大きなネットワークを考えてみましょう。
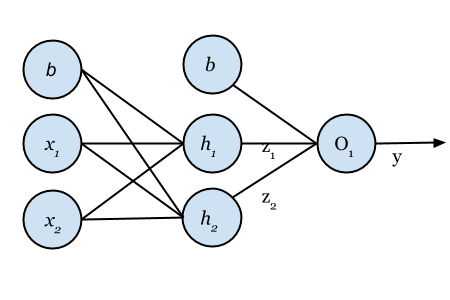
注釈:より大きなネットワーク
W f r o m , t o は1つのユニットから他のユニットへ移っていくウエイトの値を示しており、上記におけるネットワークの方程式は以下のように表記できます。
z 1 = f ( W T l 1 , h 1 x + b ) z 2 = f ( W T l 1 , h 2 x + b ) y = f ( W T h 12 , o 1 z + b )
z 1 は先ほど計算した方程式と同じものです。複雑なネットワークを作るために、どのようにユニット同士をつなげたか分かりますか? ここでは同じ計算を何度も繰り返し適用していきます。前の層で計算した結果の出力値を、その次の層に適用していくのです。最終層に到達するまで、ネットワークを値が伝播していきます。このプロセスがフォワードプロパゲーションです。しかし、このプロセスはウエイトやバイアスに何の補正も加えないので、ネットワークの出力値を変える必要がある場合は、ほとんど役立ちません。
ネットワークのウエイトやバイアスを変更するには、バックプロパゲーションとして知られているアルゴリズムを使います。では、入力値であるxと、期待される出力値yというデータセットをネットワークに与えた場合の、教師あり学習に焦点を当ててみましょう。教師あり学習でバックプロパゲーションを使う場合は、ネットワークのパフォーマンスを定量化する必要があります。ネットワークを通ってきたフォワードプロパゲーションの結果である y ^ (推定値)と期待値である y の値を比較する誤差を定義しなければならないのです。
この値同士の比較は、正式にはコスト関数として知られています。他の方法で定義することもできますが、この記事では以下の通り平均二乗誤差の関数を使いましょう。
E M S E ( x , y ) = 1 n | y ^ ( x ) − y | 2
この関数を使えば、誤差の大きさを算出できます。ランダムに初期化されたウエイトやバイアスがネットワークに与えられた場合、出力値は期待値であるyの値からかけ離れたものになり、 E M S E からの出力値は大きくなるでしょう。
バックプロパゲーション では、この誤差の大きさを使い、ネットワークの後方から前方までウエイトとバイアスを補正しながら値を伝播させていきます。各ウエイトとバイアスについて補正した量は、誤差への寄与として扱われ、 最急降下法 で計算されます。このアルゴリズムで、ウエイトとバイアスの値を変更することにより、誤差関数の値を最小化しようとしているのです。
入力値としてベクトルxが与えられ、出力値の期待値がyの場合、ニューラルネットワークを開発する一般的なプロセスは以下の通りです。
-
ベクトルxを入力したネットワークにて、フォワードプロパゲーションを行う。 y ^ が計算される。
-
誤差関数で誤差を計算する。 E M S E ( x , y ) = 1 n | y ^ ( x ) − y | 2 を使う。
-
ウエイトとバイアスを更新しながら、ネットワークにて、バックプロパゲーションを行う。
上記の手順は、ネットワークのウエイトとバイアスの誤差が可能な限り最小になるまで、異なるxとyの組み合わせを使って、何度も繰り返し行われます。 E M S E 関数を最小化するのです。
畳み込みニューラルネットワーク
あなたが最近の技術的な記事に注意を払っているとすれば、ニューラルネットワークが複数の領域において最先端の技術を発展させているという話題を耳にしたことがあるでしょう。畳み込みニューラルネットワークのほんの小さな一部分が、これらのブレイクスルーをもたらしています。
畳み込みニュートラルネットワーク(ConvNets)は、典型的な順伝播型ニュートラルネットワークとは少しばかり特徴が異なります。ConvNetsは視覚野から生物学的なインスピレーションを得ます。視覚野には、視野の小区域に対し敏感な小さな細胞の集まりも含まれており、これは受容野と呼ばれます。この受容野の挙動は、行列の形で重み付けを学習することで模倣できます。この行列は”カーネル”と呼ばれ、生物学的に受容野が果たす役割と同様に、ある画像の類似した小区域に対して敏感になります。今度は、カーネルと小区域との間の類似性を表す方法が必要になります。畳み込み演算が2つの信号の間で、適切な“類似性”を効果的に返してくるので、私たちは画像の小区域とともに覚えたカーネルを首尾よく通すことができます。この演算を通して、私たちは適切な類似性を返すことができるのです。
以下はカーネルを表したアニメーションです。黄色は画像上に畳み込まれたもの、緑は、右側に赤で書かれた演算の結果と一緒です。
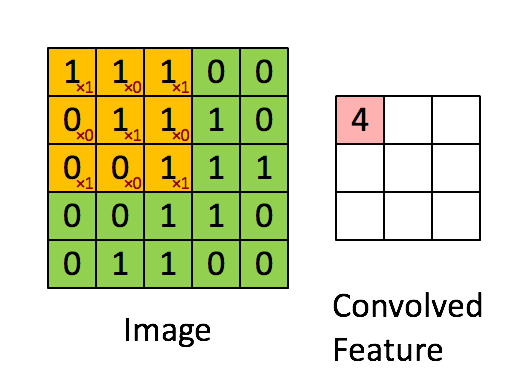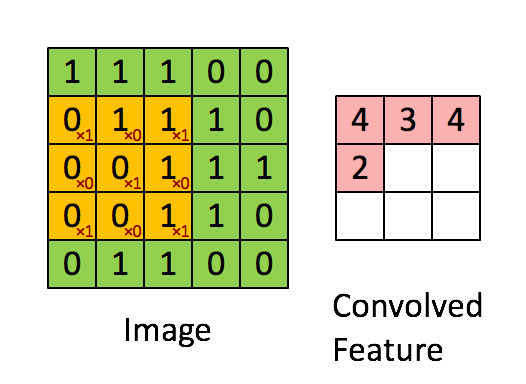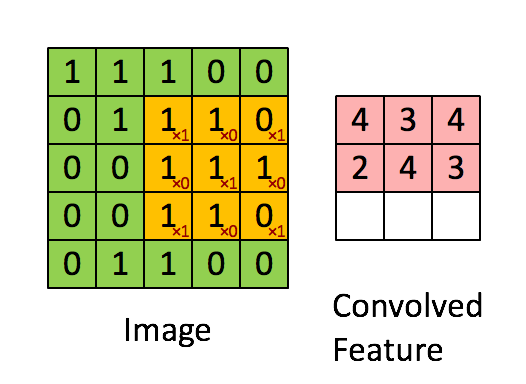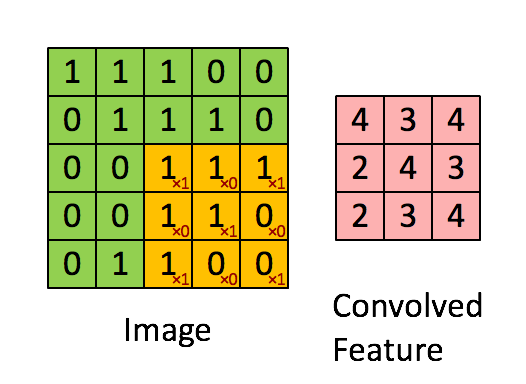
注釈:畳み込み演算を表したアニメーション
引用元:スタンフォード大学ディープランニングから Feature extraction using convolution
これを説明するために、画像上のエッジ方向を検出するとてもシンプルな正方形のカーネルを実行しましょう。カーネルのウエイトは以下で表されます。
⎛ ⎝ ⎜ − 5 0 0 0 0 0 0 0 5 ⎞ ⎠ ⎟
カーネルを使用している畳み込み演算を左の画像について何度か実行すると、右の画像が得られます。

注釈:畳み込み演算についてのアニメーション。
引用元: Edge Detection with Matrix Convolution
どうしてこれが有効なのでしょうか? ニューラルネットワークのコンテキストでは、いくつかの理由があります。
まず、右の画像上から情報を引き出すことが可能になります。カーネルはエッジ方向の存在と位置の情報を私たちに教えてくれます。ニュートラルネットワークで使用することで、画僧の基本的な特徴(エッジや勾配、ぼかし具合など)を抽出するための、カーネルの適切な重み付けを学習することができます。ネットワークが十分な深さの畳み込み層を持っていれば、前の層における特徴の組み合わせを学習し始めます。前述のエッジ・勾配・ぼかし具合といった基本的な構成要素が、後ろの層では目や鼻、髪に変わるのです。

注釈:高水準の表現を初期の層から作り上げているカーネル。
引用元: Yann LecunによるディープラニングのICML 2013チュートリアル
慣習的に言えることは、画像や音声を扱う分野で仕事をしたいならば、使用可能な形にデータを前処理するために、別のアルゴリズムを利用して特徴を生成しなければならないことです。これによって、機械学習アルゴリズムは、入って来るデータを理解するために選択できるようになります。このプロセスは冗長的で、もろいものです。畳み込みフロントエンドをネットワークに適用することによって、アルゴリズムに、私たちの持っている側のデータを最小限に前処理するだけで、その特定の領域と状況のために最も効果的に働く特徴を作らせることができます。ネットワークは、単独で特徴を抽出します。ネットワークで学習された特徴は、アルゴリズムや手動で設計された特徴より、よく機能するものがほとんどです。
畳み込みニュートラルネットワークを使った画像スケーリング
以下はモデルから作られた予備的結果です。左の画像は、オリジナルの“高い”解像度です。グランドトルースであり、私たちが望む完璧な復元の画像です。1/2でオリジナルを縮小し、バイキュービック法とニューラルネットワークモデルを通して復元しました。結果は、それぞれ中央と右側に出ます。
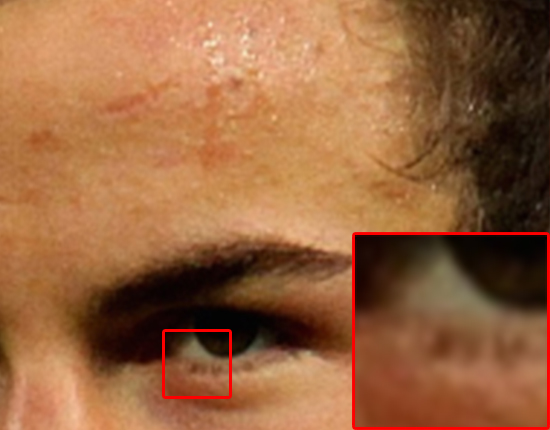
注釈:オリジナル
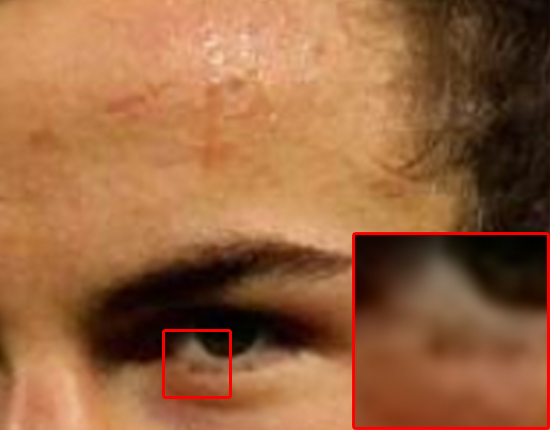
注釈:バイキュービック法
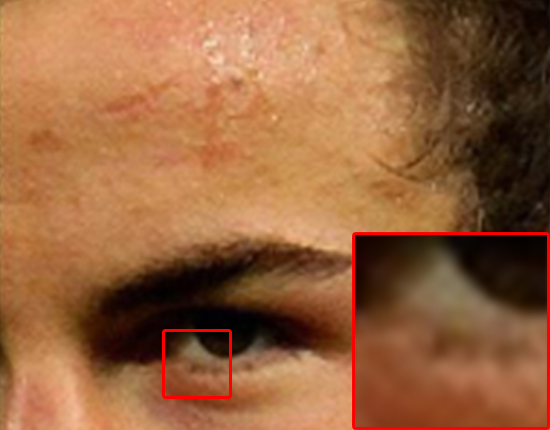
注釈:ニューラルネットワークモデル
主な違いは髪の生え際、眉毛、ほほと額の肌の部分に見られます。

注釈:オリジナル

注釈:バイキュービック法

*注釈:ニューラルネットワークモデル
ニューラルネットワークモデルはバルコニーや前景の日焼け用ベッドのハードエッジに沿って、うまく機能しています。

注釈:オリジナル

注釈:バイキュービック法

注釈:ニューラルネットワークモデル
初見では分かりづらい例でしょう。耳側の毛の流れや耳の中の毛といった細部がモデルでは見て取れます。

注釈:オリジナル

注釈:バイキュービック法

注釈:ニューラルネットワークモデル
Lennaの画像を処理対象に含めずして、画像に関連する仕事を終えるわけにはいきません。羽、鼻、唇と目の鋭さをよく見てください。帽子のパターンも、モデルの出力でよく表されています。

注釈:オリジナル

注釈:バイキュービック法

注釈:ニューラルネットワークモデル
主な違いは、葉っぱや影の形、木目などに現れています。
構造
以下の図は、私たちが使用したアーキテクチャの一つで、主な目的は、画像から取り入れられたピクセル数を倍にすることです。この構造は8層のニューラルネットワークになっていて、ピンク色がかったブロックの積み重ねで表示されている3つの畳み込み層と、青色をした4つの全結合層で構成されています。各層は、ReL活性化関数を使用しており、図には表示されていませんが、最後に線形ガウスユニットである緻密層があります。
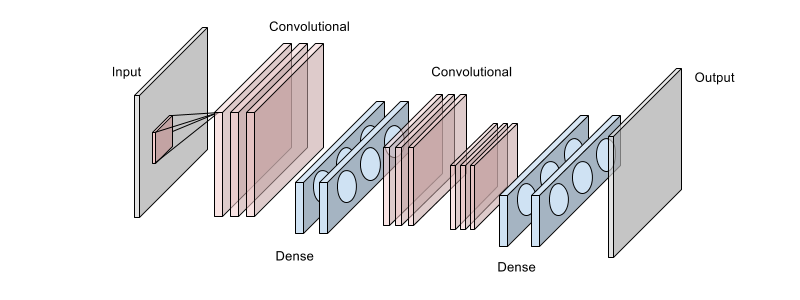
入力画像の小部分は、最初の畳み込み層を通って取り込まれています。この画像は、正方形のスライディングウィンドウを使ってより大きな画像から取り入れられたものです。そして、最初の畳み込み層には最大数のフィルタマップが含まれています。最初の2つの全結合層を通って高次元として”再出力”された出力画像は、更に次の2つの畳み込み層によって処理が行われます。この畳み込み層で抽出された特徴は、一連の全結合層に送り込まれます。そして、最終的な出力画像は、線形ガウスの層によって算出されます。
ここでは、畳み込み層の後に、プーリング演算は行っていません。プーリング演算は入力に対する不変性が重要な分類タスクには有用なのですが、このタスクで重要なのは各カーネルで検知される特徴の位置だからです。また、プーリングはこのユースケースで必要となる有益な情報を必要以上に削除してしまうので、そういった意味でも採用しませんでした。
ウエイトは、 Glorot & Benigoによって推奨されているXavier initialization で全て初期化され、ハイパーパラメータの最適化を行っている間、微調整されています。これは、 2 n i n + n o u t と定義され、正規分布からサンプリングされます。また、バイアスは全てゼロに初期化されています。
データセット
ネットワークは、約300万ものサンプルによる巨大なデータセットで学習されています。データセットの画像は、動物やアウトドアの場面といったような自然の画像を使用しました。いくつかの画像については、動物のイラストやテキストが含まれていたため、このデータセットから削除しています。また、各画像のサイズや画質はまちまちだったので、合計ピクセル数が、64万ピクセル以上である画像に絞ることにしました。
データセット内のサンプルは、それぞれ低解像度と高解像度の画像の組み合わせになっています。入力値”x”で表す低解像度の画像は、高解像度の画像をある倍率でダウンスケールしたもので、求められる出力値”y”は、元々の高解像度の画像となります。入力データには、多少のノイズと歪みを加えておきました。データに対しては、ゼロ平均(データセット全体の平均値を利用)・同一の分散(データセットでの標準偏差で割り算)となるように標準化を行いました。
データセットは、トレーニング、テスト、バリデーションのサブセットに分かれており、それぞれ、80%、10%、10%の割合です。
規則
最大ノルム
最大ノルム制約は、そのレイヤー上の全ユニットの重みベクトルに対し、大きさの絶対的な上限を設ける制約です。この制約により、勾配の更新が大きすぎた場合にネットワークの重みが”爆発”してしまうのを防ぐことができます。最大ノルム制約は、最後の線形ガウス層以外のどの層でも使われます。ノルムの大きな重みベクトルは全ての畳み込み層で用いられますが、他の層ではノルムはそれほど大きくなりません。
L2
L2規則とは、大きい重みベクトル W を使うネットワークにペナルティを与えることです。これは規則の強さとしてパラメータ λ で設定されます。 1 2 λ W 2 項としてコスト関数に加えられます。最適化アルゴリズムは、コスト関数が従来通り最小化している間、ウエイトを小さくしようします。畳み込み層と最初の全結合層には、軽度の規則が適用され、その他の全結合層には、強い値を使います。
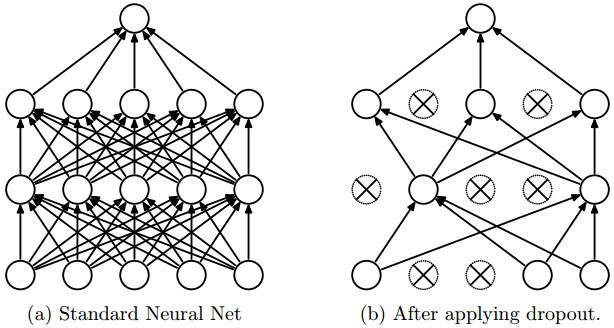
ドロップアウト
ドロップアウト は、各トレーニングステップで、ユニットを層からランダムに”ドロップ”し、モデル内に”サブ構造”を作り上げます。大きなネットワークの中の小さなネットワークに対する一種のサンプリングとして見ることができます。そこに含まれるユニットのウエイトだけが更新され、ネットワークが少数のユニットに依存しないようにします。ユニットの削除のプロセスは、実行中、繰り返し行われ、残っているユニットだけが変更されていきます。全ての畳み込み層は、1.0に近い高い包含確率を持っていますが、最後の2つの全結合層では、その半分のユニット数となっています。
学習
モデルは、学習セット全体で250回のエポックに対して、1回のバッチサイズが250である確率的勾配降下法で学習されました。バッチサイズが小さいとパータベーションが起こって、それが有益に働く場合もありますが、バッチサイズが大きければ更新がスムーズになり、GPUを効果的に使えるようになります。
ネットワークは平均二乗誤差関数を最小化するために学習されます。学習率のスケールは全てのウエイトとバイアスで使われていました。ウエイト(各層)は、 1 − 1 2 n i n t o t a l 2 という式で表され、 n i は現在の層の位置、 n t o t a l は全層の数を示しています。これで前半層の収束を補助する学習率をスケーリングしました。また、全てのバイアスには2.0の学習率乗数がありました。Nesterov momentumは、最初の値は0.15で使われていましたが、45のエポックで0.7まで増加されました。
ネットワークの学習にはAmazon EC2のg2.2xlargeというインスタンスを利用し、スピードアップのために NVIDIAのcuDNN というライブラリを加えました。最終モデルの学習にかかった時間は、およそ19時間です。
ハイパーパラメータ
大部分のハイパーパラメータを選択するために、Amazonのg2.2xlargeインスタンスのクラスタ上で動作する、社内のハイパーパラメータ最適化ライブラリを使いました。学習のデータセットとバリデーションのデータセットの一部を使うことで、これを実行します。このプロセスには4週間ほどかけて、500種類くらいの異なる構成を評価しました。
バリエーション
この問題を対処する上で、うまくいかなかった例を挙げます。
- 1,000より大きいバッチサイズを使うと、うまく機能しましたが、極小値にすぐぶつかってしまいました。この極小値から抜け出すために、これより小さいバッチで生じるジッターが役に立ちました。
- 小さな畳み込みネットワークを使っても問題はありませんでしたが、大きな畳み込みネットワークと同じ程度まで一般化することはできませんでした。
- He氏らが提唱する、ウエイトを初期化する 2 n という式を試しましたが、残念ながらネットワークがパチパチと飛び散ったような状態になり、学習ができなくなりました。これを使って多くの人が成功していますが、おそらく、これは上手く行かない特定の構成だったのでしょう。
- 全ての層で同じ量のL2規則を使うと、どの層で飽和状態が始まったのか、または最大ノルム制約にかかったかなどの条件によって、層のL2規則をうまく変化させることができました。
- 層にプーリングを使うと、層の間で失う情報が多くなりすぎてしまい、画像のきめが粗く、見た目が劣化しました。
私が学んだ、より大きなネットワークを扱うために最も重要な事は、ウエイトの初期化を正しく行うことの大切さでした。これがモデルの学習の出来に最も影響を与えると感じたのは、いくつか他のハイパーパラメータを選択した後でした。初期化がモデルにどのような影響を与えるかを理解するため、時間を割いて異なる初期化の技術を調べるのはいい考えです。異なる初期化スキームを扱っている論文や機械学習ライブラリが沢山あるので、そこから簡単に学ぶことができます。
アプリケーション
私たちの目標は、バイキュービック法など、他の画像拡大アルゴリズムの必要性を排除したり、置き換えたりすることではなく、異なる技術や方法を駆使して質を向上させようと試みることでした。使用した主なユースケースは、高解像度の画像が使用できない状況で、低解像度の画像を拡大するというものでした。私たちが使っていたプラットフォーム上では、時折この状況が見られました。
静止画像の主要なユースケースのみならず、この技術はGIFなど異なるメディアフォーマットに適用できます。GIFは切り離されたフレームに分割し、拡大して、リパッケージすることができました。
私たちが思いつく最終的なユースケースは、帯域幅を抑えることでした。小さい画像をクライアントに送り、クライアントサイド版のこのモデルを実行して大きな画像を得ることができます。これは、カスタムソリューション、または ConvNetJS など、利用可能なニューラルネットワークのjavascript実装を用いて達成できるはずです。
更なるステップ
この問題の領域には多くの可能性が秘められていて、以下のような突拍子もない案も含めて、試してみるべきことが沢山あると感じました。
- 畳み込み層内のフィルタサイズを大きくする。
- もっと多くの層とデータで試してみる。
- RGB以外のカラーチャネルフォーマットを試してみる。
- 最初の畳み込み層内で数百のフィルタを試し、そこから、包含確率が非常に小さいドロップアウトのサンプルを取り、層の学習率を微調整する。
- 全結合層は見限り、畳み込み層を全て使ってみる。
- この問題で 抽出 が有効か調べてみる。クライアントデバイス上で簡単に実行できる軽いバージョンを作る際に役立つかもしれません。
- 質が下がらない範囲で、どれくらい小さい、または大きいネットワークを作ることができるか調べてみる。
結論
原物と同じ見た目を追及することは困難です。どんなに努力をしても、最後の数パーセントの質を絞り出すことができません。私たちは定期的に製品を見直し、最初は明確でなかったり、可能には思えなかったりしても、この数パーセントの違いは何かを再考します。これは製品全体に関係する問題ではないかもしれません。しかし、質を向上させるためには、大まかですが良い方法だと思っています。
読者の皆さんが、この投稿を楽しみ、内容に興味を持っていただけたら嬉しく思います。また、非常に有意義なインターンシップの経験をさせてもらったFlipboard社の皆さんには感謝を伝えたいと思います。今回のインターンシップの中では、多くを学び、傑出した方々に出会い、かけがえのない経験をすることができました。
機械学習、大規模データセット、素晴らしい人々と共に面白いプロジェクトに従事することに興味があれば、ぜひ求人に応募してください。 ただいま、人員募集中です !
また、私のTwitter( @normantasfi )も、どんどんフォローしてくださいね。
この記事を執筆するにあたり、提案や編集をしてくれた Charles 、 Emil 、 Anh 、 Mike Klaas 、 Michael Johnston に、感謝の意を示したいと思います。また、サーバのセットアップや質問のために、いつも時間を割いて助けてくれた Greg には、特に大きな感謝を捧げます。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事









{kind=link}