2018年3月29日
PythonとKerasを使ってAlphaZero AIを自作する

本記事は、原著者の許諾のもとに翻訳・掲載してお��ります。
自己対戦と深層学習でマシンにコネクトフォー(Connect4:四目並べ)の戦略を学習させましょう。
この記事では次の3つの話をします。
- AlphaZeroが人工知能(AI)への大きなステップである2つの理由
- AlphaZeroの方法論のレプリカを 作って コネクト4のゲームをプレイさせる方法
- そのレプリカを改良して他のゲームをプラグインする方法
AlphaGo→AlphaGo Zero→AlphaZero
2016年3月、DeepmindのAlphaGo(アルファ碁)が、囲碁の18回の世界王者、李世乭(イー・セドル)との五番勝負で、2億人の見守る中、4-1で勝利しました。機械が超人的な囲碁の技を学習したのです。不可能だとか、少なくとも10年間は達成できないと思われていた偉業です。

AlphaGo 対 李世乭の第3局
このことだけでも驚くべき功績ですが、DeepMindは、2017年10月、さらに大きく進歩しました。
論文 『Mastering the Game of Go without Human Knowledge』 で、AlphaGoに100-0で圧勝した新バージョンAlphaGo Zeroを公開したのです。信じられないことに、このアルゴリズムは白紙状態から自己対戦のみによって学習し、過去の自分に打ち勝つための戦略を段階的に発見していきました。人間の能力を超えるAIを開発するために、プロ棋士による対局のデータベースは必要なくなったのです。
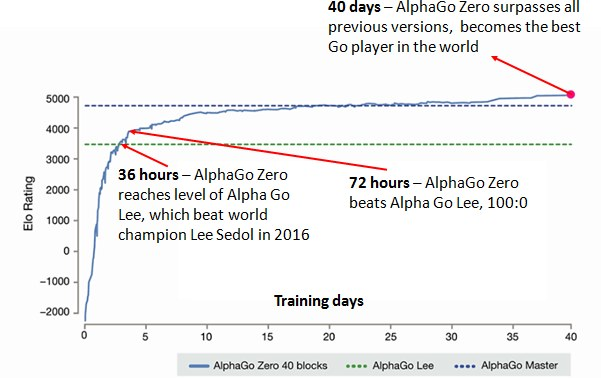
注釈:
40日:AlphaGo Zeroがそれ以前のバージョンのすべてに勝利して、世界最強の囲碁棋士になった
36時間:AlphaGo Zeroが、2016年に囲碁の世界王者、李世乭(イー・セドル)を破ったAlphaGo Leeのレベルに達した
72時間:AlphaGo ZeroがAlphaGo Leeを100:0で破った
イロレーティング
訓練日数
AlphaGo Zero 40ブロック
AlphaGo Lee
AlphaGo Master
『 Mastering the Game of Go without Human Knowledge 』より引用
DeepMindは、そのわずか48日後の2017年12月5日、別のレポート『Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm』(https://arxiv.org/pdf/1712.01815.pdf)で、AlphaGo Zeroを改造して、チェスと将棋の世界チャンピオンプログラム、StockFishとElmoを破る方法を公開しました。初めてそのゲームを経験してから世界最強のコンピュータプログラムになるまでの学習過程全体に要した時間は24時間未満でした。
ここからAlphaZeroが生まれました。人間の専門家の戦略についての予備知識なしに、素早く「あること」に熟達するための汎用アルゴリズムです。
AlphaZeroには、非常に優れた2つの点があります。
- AlphaZeroには、入力として人間の専門知識が全く必要ない
このことの重要性は、どれだけ言っても言い過ぎではありません。すなわち、ゲームのルール以上の専門知識は前もって必要ないので、AlphaGo Zeroの基本的方法論は、完全な情報を与えられていれば(ゲームの状態が、常に双方のプレイヤーに知られている)、 どんな ゲームにでも応用できるということです。
これこそが、元のAlphaGo Zeroの論文からわずか48日後にチェスと将棋の論文を発表できた理由なのです。文字どおり、必要だったのは、ゲームの仕組みを記述した入力ファイルを変更し、ニューラルネットワークとモンテカルロ木探索に関するハイパーパラメータを微調整することだけでした。
2.アルゴリズムがとんでもなくエレガント
AlphaZeroが世界中の一握りの人たちにしか理解できないような超難しいアルゴリズムを使っていたとしても、並々ならぬ功績には違いありません。しかし、さらに驚くべきことに、この論文に書かれた考え方の多くは、前のバージョンよりもずっと簡単なものでした。その中心にあるのは、見事にシンプルな学習のためのマントラです。
考えられる複数のシナリオに沿って頭の中で対局し、有望な経路を優先するが、その一方で、その他のシナリオが自分の打った手にどのように反応するか予想し、未知の部分について検討を続ける。
未経験の状況に至ったときは、どのような配置になれば自分にとって好都合なのか考えて、その配置から現在の配置に至るまでの経路を頭の中で逆にたどる。
将来の可能性について考え終わったら、最もよく検討した手を打つ。
対局が終わったら、見直して、配置の将来のバリューについてどこで判断を誤ったか評価を行い、それに応じて考え方を修正する。
人間がゲームを憶えるのにとても似ていると思いませんか? 悪い手を打つのは、その手を打った結果の配置の、将来のバリューを見誤ったか、対戦相手がある手を打つ可能性を見誤って、その可能性についてよく考えなかったかのどちらかが原因です。AlphaZeroが訓練によって学習するのは、ゲーム対局のこの2つの側面です。
AlphaZeroを自作する
まず、AlphaGo Zeroがどのように働くのか全体的に理解するために、 AlphaGo Zero cheat sheet を見てみましょう。コードの各部分を調べるとき、参照先として役に立ちます。さらに、 ここ には、AlphaZeroの働きを詳しく説明した素晴らしい記事があります。
コード
この Gitレポジトリを複製してください。この記事で参照するコードが入っています。
学習プロセスを開始するには、 run.ipynb というJupyter notebookの最初の2つのパネルを実行します。メモリがいっぱいになるまで対局の配置を貯め込んだら、ニューラルネットワークが訓練を開始します。さらに自己対局と訓練を重ねることにより、ゲームバリューの予測と、任意の配置から次の手への予測に徐々に熟達していき、意志決定と全体的な対局の腕が磨かれます。
では、これからコードを詳しく調べ、AIが時間の経過と共に強くなることを実証する結果を見ていきます。
おことわり: これは、上記の論文から得られる情報に基づく、AlphaZeroの働きについての私個人の見解です。間違った点がありましたら、お詫びし、訂正するように努力します。
コネクトフォー
私たちの自作アルゴリズムが学習するゲームは、コネクトフォーです。囲碁ほど複雑ではありませんが、それでも、ゲームの配置は全部で4,531,985,219,092通りもあります。

コネクトフォー
このゲームのルールは簡単です。プレイヤーは交互に、空いているマスに自分の色のコマを入れます。縦、横、斜めのいずれかの方向に先に4つのコマを一直線に並べた人の勝ちです。4つのコマが一直線に並ぶ前に全部のマスが埋まったら、ゲームは引き分けになります。
コードベースを構成する主要なファイルの概要を説明します。
game.py
このファイルには、コネクトフォーのゲームルールが入っています。
正方形のマスのそれぞれに、次のように、0から41までのアクション番号が割り当てられています。
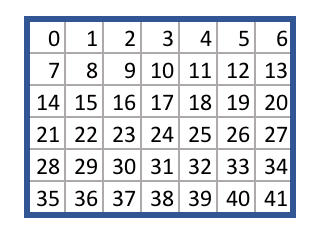
コネクトフォーのマスのアクション番号
ファイルgame.pyには、ある手(アクション)を打ったときの、あるゲーム状態から別の状態への移行の論理が記述されています。例えば、 takeAction メソッドは、空白のボード状態とアクション38を与えられると、中央の列の一番下に先攻プレイヤーのコマが置かれた新しいゲーム状態を返します。
同じAPIに従うゲームファイルなら、どんなファイルでもgame.pyに置き換えることができ、このアルゴリズムは、原理的には、与えられたルールに基づき、自己対戦によって戦略を学習します。
run.ipynb
このファイルには、学習プロセスを開始するコードが入っています。このコードはゲームのルールをロードしてから、アルゴリズムのメインループを繰り返します。メインループは次の3つのステップからなります。
- 自己対戦
- ニューラルネットワークの再訓練
- ニューラルネットワークの評価
このループには、2つのエージェント、 best_player と current_player が関与します。
best_player(ベストプレイヤー)は、最もパフォーマンスの高いニューラルネットワークをもっていて、自己対戦メモリを作るために使用されます。次にcurrent_player(現在のプレイヤー)がこのメモリを使って自分のニューラルネットワークを再訓練し、best_playerと対戦します。current_playerが勝てば、best_player内のニューラルネットワークがcurrent_player内のニューラルネットワークと入れ替わり、ループが繰り返されます。
agent.py
このファイルには、Agentクラス(ゲームのプレイヤー)が入っています。各プレイヤーはそれぞれのニューラルネットワークとモンテカルロ探索木で初期化されます。
simulate メソッドが、モンテカルロ木探索のプロセスを実行します。具体的には、エージェントが木のリーフノードに移動して、そのノードを自分のニューラルネットワークを使って評価してから、木を上方向にたどりながらノードにバリューを入れていきます。
actメソッドがシミュレーションを何回も繰り返して、現在の配置からどの手を打てば最も好都合か考えます。次に、その手を実行に移すために、選択したアクションをゲームに返します。
replay メソッドが、それ以前のゲームのメモリを使ってニューラルネットワークを再訓練します。
model.py
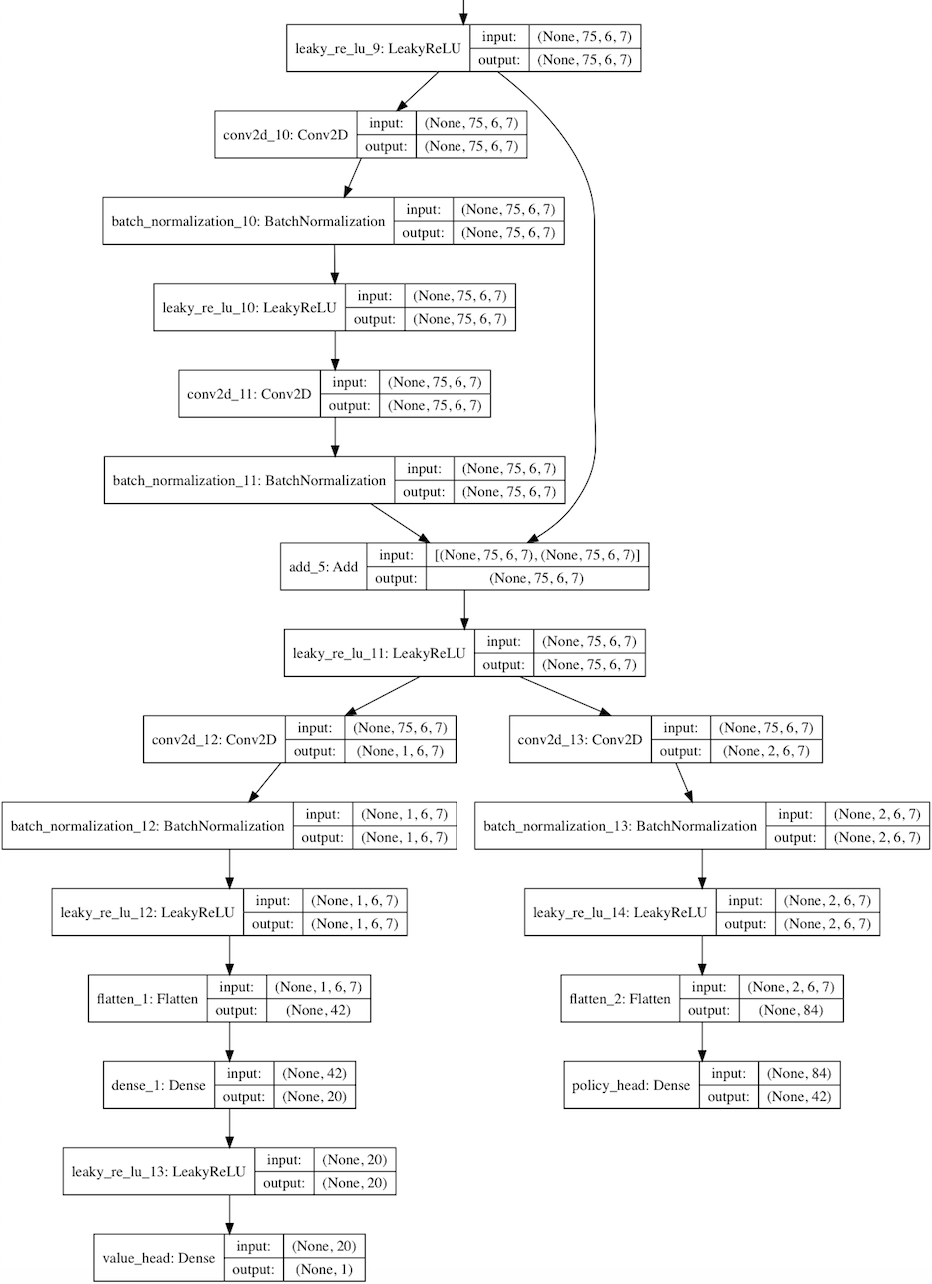
Kerasを使って構築したresidual convolutional networkの例
このファイルには、ニューラルネットワークのインスタンスを構築する方法を定めた、Residual_CNNクラスが入っています。
このクラスは、AlphaGoZeroの論文に書かれたニューラルネットワークのアーキテクチャの凝縮バージョン、つまり、1つの畳み込み(convolutional)レイヤに続く多数の残余(residual)レイヤを使い、次にバリューとポリシーのヘッドに別れます。
畳み込みフィルタの深さと数は、設定ファイルで設定することができます。
Kerasライブラリを使って、Tensorflowのバックエンドとのネットワークが構築されます。
個々の畳み込みフィルタとニューラルネットワーク内の緻密に結合したレイヤを見るには、run.ipynb notebookの中の次のコードを実行してください。
current_player.model.viewLayers()
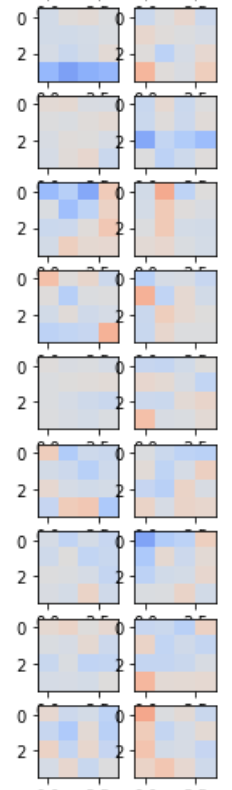
ニューラルネットワークの畳み込みフィルタ
MCTS.py
このファイルには、モンテカルロ探索木を構成するNode、Edge、MCTSのクラスが入っています。
MCTSクラスには、前述した moveToLeaf と backfill のメソッドが入っていて、Edgeクラスには考えられる手(動作)のそれぞれに関する統計が入っています。
config.py
このファイルには、アルゴリズムに影響する重要なパラメータを設定します。

これらの値を調節すると、実行時間、ニューラルネットワークの正確さ、アルゴリズムの全体的な成功に影響します。これらのパラメータによって、コネクトフォーの優秀なプレイヤーが育成されますが、それには長い時間がかかります。アルゴリズムを高速化するには、下記のパラメータを代わりに使ってみてください。

funcs.py
2つのエージェントを対戦させる、 playMatches 関数と playMatchesBetweenVersions 関数が入っています。
自分のプレイヤーと対戦させるには次のコードを実行してください(run.ipynb notebookにも入っています)。
from game import Game
from funcs import playMatchesBetweenVersions
import loggers as lg
env = Game()
playMatchesBetweenVersions(
env
, 1 # the run version number where the computer player is located
, -1 # the version number of the first player (-1 for human)
, 12 # the version number of the second player (-1 for human)
, 10 # how many games to play
, lg.logger_tourney # where to log the game to
, 0 # which player to go first - 0 for random
)注釈:(コメント部分)
コンピュータプレイヤーが位置する実行バージョン番号
第1のプレイヤーのバージョン番号(人間の場合は-1)
第2のプレイヤーのバージョン番号(人間の場合は-1)
ゲームの対戦回数
ゲームのログを記録する場所
先攻プレイヤー(ランダムの場合は0)
initialise.py
このアルゴリズムを実行させると、ルートディレクトリの run フォルダにすべてのモデルとメモリファイルが保存されます。
あとで、このチェックポイントからアルゴリズムを再開するには、runフォルダをrun_archiveフォルダに移し、フォルダ名に実行番号を追加します。次に、run_archiveフォルダ内の該当するファイルの位置に対応するinitialise.pyファイルに実行番号、モデルバージョン番号、メモリバージョン番号を入れます。通常のとおりにアルゴリズムを実行させると、このチェックポイントから開始します。
memory.py
Memoryクラスの、あるインスタンスが以前のゲームのメモリを記憶し、そのメモリをアルゴリズムが使用してcurrent_playerのニューラルネットワークを再訓練します。
loss.py
このファイルにはカスタムの損失関数が入っています。この関数は、交差エントロピー損失関数に移る前に、反則の手(動作)からの予測結果をマスクします。
settings.py
runフォルダとrun_archiveフォルダの場所です。
loggers.py
ログファイルは、runフォルダ内の log フォルダに保存されます。
ログ記録をオンにするには、このファイル内のlogger_disabled変数の値をFalseに設定します。
ログファイルを見れば、このアルゴリズムの働きと、その「心」の中を理解するために役立ちます。例えば、次はlogger.mctsファイルの一例です。

logger.mctsファイルからの出力
同様に、logger.tourneyファイルを見ると、評価段階でそれぞれの手(動作)に割り当てられた確率が分かります。
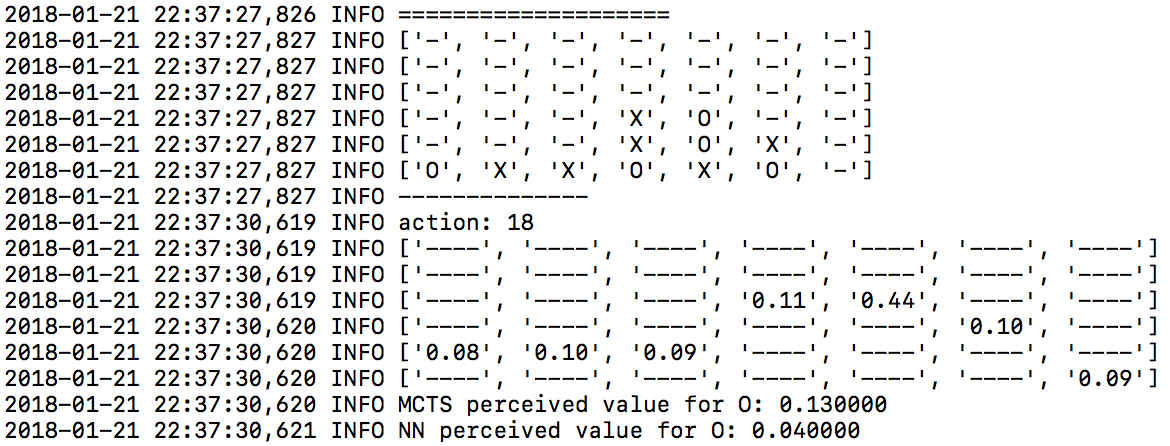
logger.tourneyファイルからの出力
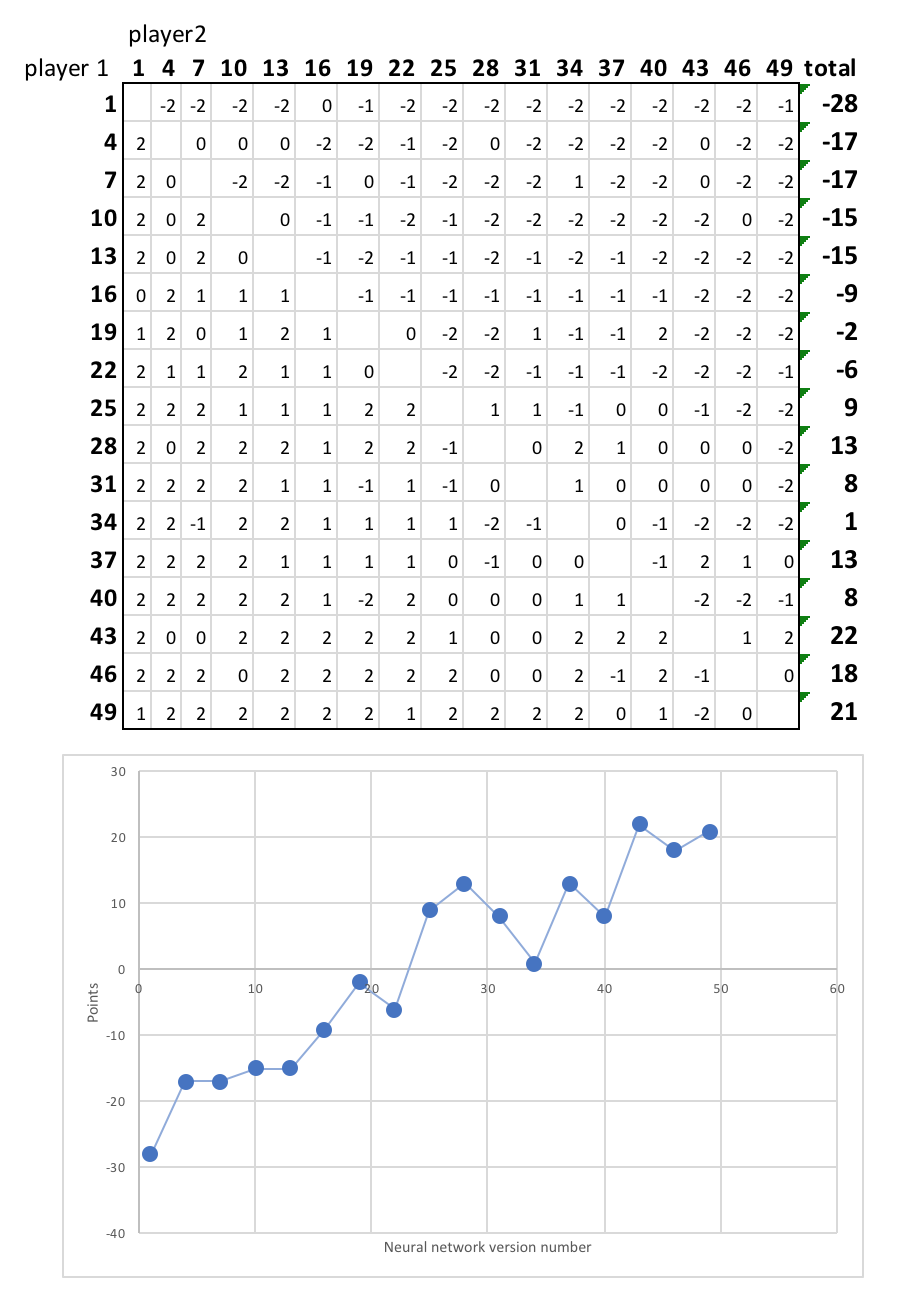
結果
数日間の訓練で、ミニバッチの繰り返し回数に対する損失について下記のグラフが得られまた。
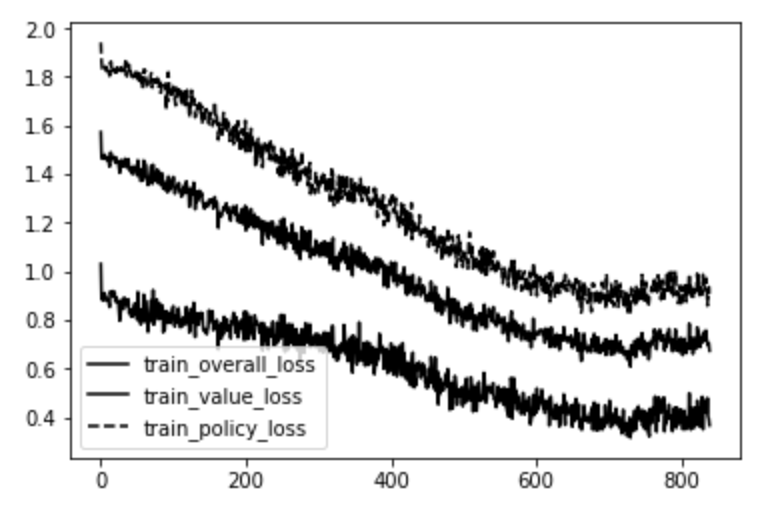
ミニバッチの繰り返し回数に対する損失
一番上のラインはポリシーヘッド内の誤差です(ニューラルネットワークからの出力に対するMCTS動作確率の交差エントロピー)。一番下のラインは、バリューヘッド内の誤差です(実際のゲームバリューとニューラルネットワーク予測バリューの間の平均二乗誤差)。真ん中のラインは、その2つの平均です。
明らかに、ニューラルネットワークは各ゲーム状態のバリューの予測に熟達しつつあり、次の手(動き)の予測についても同様です。その結果どんどん強くなっていくことを実証するために、ニューラルネットワークの繰り返し回数1回目から49回目までの17のプレイヤーの間でリーグ戦を行いました。各組は、各プレイヤーが1回ずつ先攻して2回対戦しました。
次の図は、最終順位表です。
注釈:
プレイヤー1
プレイヤー2
ニューラルネットワークのバージョン番号
明らかに後期のニューラルネットワークの方が早期のバージョンよりも優れていて、ほとんどの対戦で勝利しています。また、学習はまだ飽和状態ではないことは明らかで、さらに訓練を繰り返せば、プレイヤーはますます多くの複雑な戦略を学習して強化され続けます。
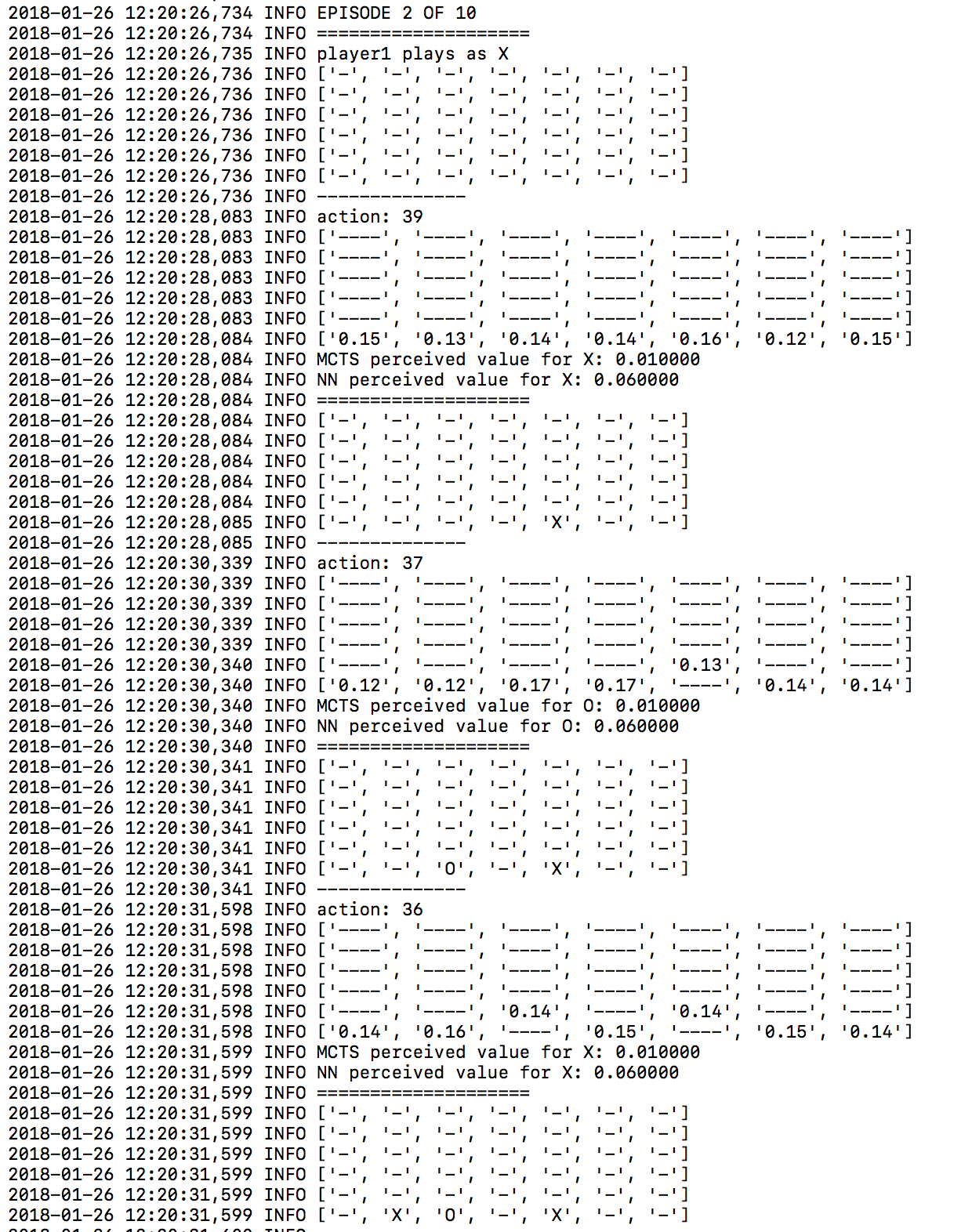
一例として、時間とともにニューラルネットワークが学んだ明らかな得意技は、早めに真ん中の列を押さえることです。アルゴリズムの最初のバージョンと、例えば30番目のバージョンの違いを比べてみましょう。
第1バージョンのニューラルネットワーク
第30バージョンのニューラルネットワーク
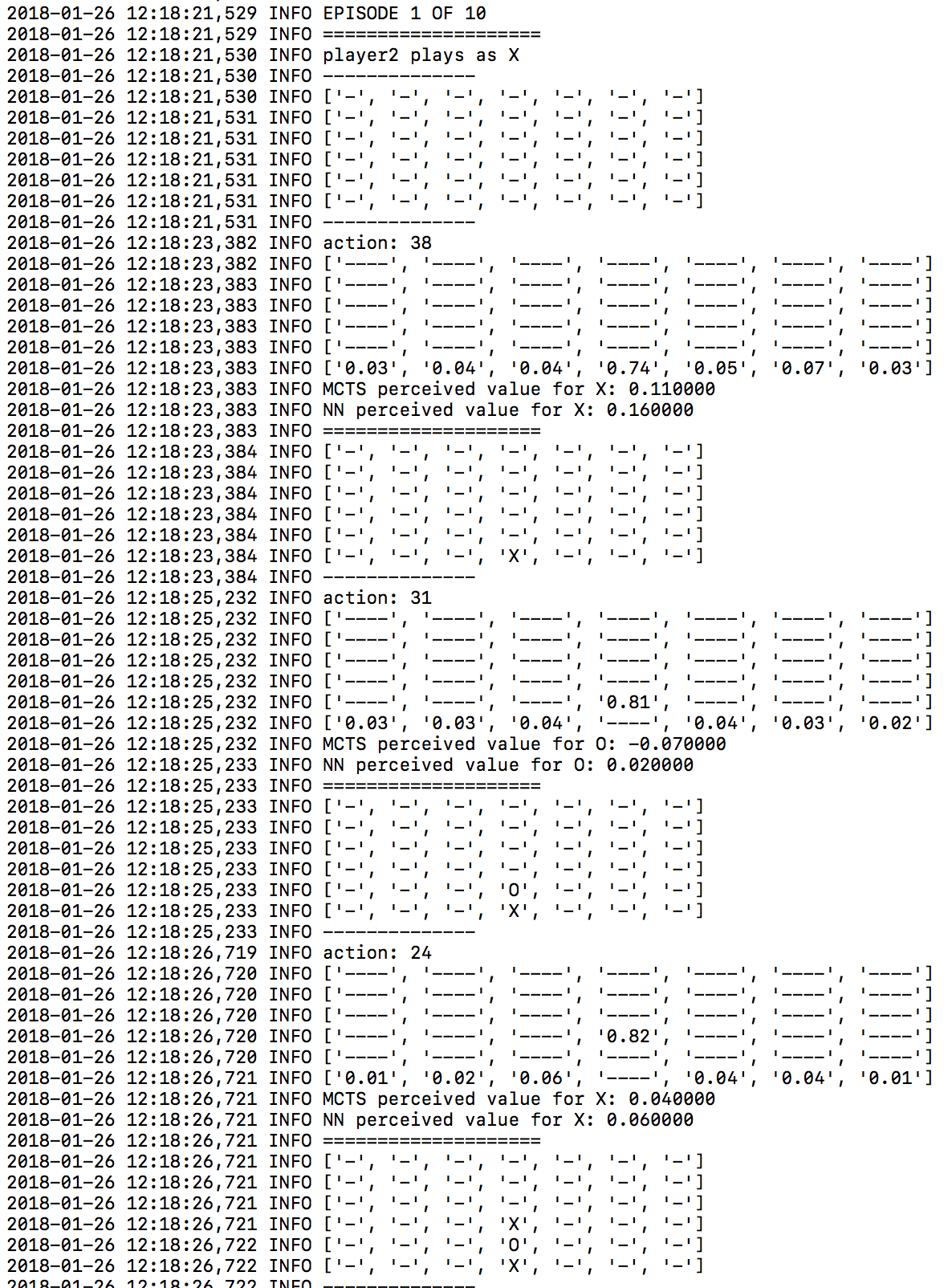
多くのラインが真ん中の列を要求しているので、これは良い戦略です。この列を早めにおさえておけば、対戦相手はこの列を利用することができなくなります。これは、ニューラルネットワークが人間の入力なしで学習した戦略です。
別のゲームを学習する
games フォルダには、「メタスクエア(Metasquares)」というゲームのgame.pyファイルがあります。これは、マル(O)とバツ(X)をマスに置いて、さまざまな大きさの正方形を作るゲームです。大きい正方形は小さい正方形より得点が高く、マスが埋め尽くされたときに、もっている得点の高い方のプレイヤーの勝ちです。
コネクトフォーのgame.pyファイルをメタスクエアのgame.py fileに置き換えると、同じアルゴリズムがメタスクエアの対戦方法を学習します。
まとめ
この記事がみなさんの役に立てば幸いです。この記事やコードベースにタイプミスを見つけた方や何か質問のある方は、コメントをいただければできる限り早急に対処します。

Applied Data Scienceではビジネス向けデータサイエンスのソリューションを開発しています。弊社のウェブサイトをご覧ください。LikedInからの直接のお問い合わせもお待ちしております。
そして、この記事を気に入って頂けたなら、拍手をお願いします。
Applied Data Scienceは、ロンドンを拠点とするコンサルタント会社です。エンドツーエンドの事業向けデータサイエンスソリューションを実現し、計測可能な価値をご提供します。さらなるデータの活用を目指すなら、ぜひご相談ください。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事