2016年8月2日
動的配列について – JavaのLinkedListとArrayListを分析・比較する
本記事は、原著者の許諾のもとに翻訳・掲載しております。
私はSkienaの『Algorithm Design Manual』 (訳注:『アルゴリズム設計マニュアル』 上巻 ・ 下巻 ) を読んでいました。ところでこの本は素晴らしい本で、連結リストと配列についてこんな比較をしていました(chapter 3.1.3)。
連結リストが静的配列に勝る相対的な長所には以下のものがあります。:
• メモリが本当にいっぱいにならない限り、連結構造にオーバーフローが生じない。
• 連続的な(配列)リストに比べて、挿入と削除が単純である。
• 大きなレコードを扱う場合、要素自体を動かすよりもポインタを動かすほうが容易かつ高速である。
一方で、配列の相対的な長所には以下のものがあります。
• 連結構造には、ポインタのフィールドを格納するための余計な領域が必要となる。
• 連結リストでは、要素に対する効率的なランダムアクセスができない。
• 配列は、ランダムなポインタのジャンプに比べてメモリ局所性やキャッシュパフォーマンスが優れている。Skiena氏は包括的な比較をしてくれているのですが、残念ながら最後のポイントについての重きの置き方が十分ではありません。私はシステムプログラマとして、「メモリアクセスパターンや効率的なキャッシュ、効率的なCPUパイプラインの利用が大きな影響力を持ち得る・ 持つ 」ということを知っており、ここではそれを示したいと思っています。
簡単なテストをしてみて、連結リストと動的配列のデータ構造での基本的な操作(挿入や検索など)のパフォーマンスを比較してみましょう。
コンピュータ・サイエンスの場における完璧なツールとして、私はJavaを使うことにします。Javaには LinkedList と ArrayList の両方があります。これらはそれぞれ連結リストと動的配列を実装しており、両方が同じ List インターフェイスを実装しています。
テストには以下のものを含みます。
- 100万個のランダムな要素の挿入によるメモリ割り当て。
- ランダムな箇所への10000個の要素挿入。
- 先頭への10000個の要素挿入。
- 末尾への10000個の要素挿入。
- 10000個のランダムな要素の検索。
- 全ての要素の削除。
ソースは私のCS playgoundリポジトリの ds/list-perf ディレクトリ
Sources are at my CS playground in ds/list-perf ディレクトリ にあります。これはMavenプロジェクトなので、 mvn package するだけでjarを入手可能です。テストは極めてシンプルで、例えば以下がランダム挿入のテストです。
package com.dzyoba.alex;
import java.util.List;
import java.util.Random;
public class TestInsert implements Runnable {
private List<Integer> list;
private int listSize;
private int randomOps;
public TestInsert(List<Integer> list, int randomOps) {
this.list = list;
this.randomOps = randomOps;
}
public void run() {
int index, element;
int listSize = list.size();
Random randGen = new Random();
for (int i = 0; i < randomOps; i++) {
index = randGen.nextInt(listSize);
element = randGen.nextInt(listSize);
list.add(index, element);
}
}
}これは List インターフェイスを利用して動作しており(そうです、ポリモーフィズムです!)、何も変更せずとも LinkedList と ArrayList の両方を渡すことができます。テストは先ほど書いた通りの順番(割り当て→挿入→検索→削除)で複数回実行され、全ての結果の最小値/中央値/最大値を計算します。
さあ、説明はこれで十分でしょうから、実行してみましょう!
$ time java -cp target/TestList-1.0-SNAPSHOT.jar com.dzyoba.alex.TestList
Testing LinkedList
Allocation: 7/22/442 ms
Insert: 9428/11125/23574 ms
InsertHead: 0/1/3 ms
InsertTail: 0/1/2 ms
Search: 25069/27087/50759 ms
Delete: 6/7/13 ms
------------------
Testing ArrayList
Allocation: 6/8/29 ms
Insert: 1676/1761/2254 ms
InsertHead: 4333/4615/5855 ms
InsertTail: 0/0/2 ms
Search: 9321/9579/11140 ms
Delete: 0/1/5 ms
real 10m31.750s
user 10m36.737s
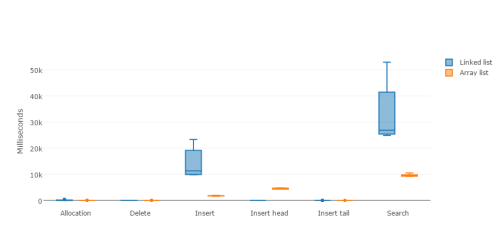
sys 0m1.011sぱっと見て分かる通り、 LinkedList が劣っています。しかし、素晴らしい箱ひげ図をご覧になって下さい。

LinkedListとArrayListでの割り当てと削除

LinkedListとArrayListでの挿入

LinkedListとArrayListでの検索
そして、 全てのテストをまとめた リンクもあります。
全ての操作において、 LinkedList が恐ろしく劣っています。唯一の例外が先頭への挿入ですが、それでも動的配列の最悪のケースと勝負しているだけです。このケースにおいて、動的配列は配列全体を毎回コピーしなければならないからです。
これを説明するために、実装について少し深く見ていきます。Java 8のOpenJDKのソースを使います。
ArrayList と LinkedList のソースは src/share/classes/java/util にあります。
Javaの LinkedList は、 Node 内部クラス を通じた双方向リストとして実装されています。
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}では、シンプルな割り当てテストの状況下で何が起こっているのかを見てみましょう。
for (int i = 0; i < listSize; i++) {
list.add(i);
}これは、 add メソッドを
呼び出し、さらに add メソッドはJDKの linkLast メソッドを呼び出します。
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}基本的に、 LinkedList での割り当ては 定数時間の操作 となります。 LinkedList クラスは末尾のポインタを保持しているため、挿入のために必要なのは「新しいオブジェクトの割り当て」「2つのポインタの更新」のみとなります。これが そんなに遅くなるはずがないのです ! では、なぜ実際は遅くなっているのでしょう? ArrayList と比較してみましょう。
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}Javaの ArrayList は実のところ、「初期設定として10個までの容量を持ち、容量を増やす際には毎回1.5倍に増やす」という動作をする動的配列なのです。 //overflow-conscious code という記述も実におかしです。なぜこのようになっているのかという理由は、 こちら で読むことができます。
自身のリサイズは Arrays.copyOf を通じて行われており、これはJavaの ネイティブ メソッドである System.arraycopy を呼び出します。ネイティブメソッドの実装はJDKの一部ではないため、これはJVM固有の機能となります。HotSpotのソースを探し出し、見てみましょう。
簡潔にまとめると以下の通りです―この機能は TypeArrayKlass:copy_array メソッド内にあり、これは Copy:conjoint_memory_atomic を呼び出します。このメソッドはアラインメントを探しますが、見ての通りメソッド内にはコピーメソッドのlong、int、short、bytes(アラインメントがない場合)向けのバリエーションがあります。int向けのメソッドである conjoint_jints_atomic を見てみますが、これは pd_conjoint_jints_atomic のラッパであり、OSとCPUに固有のものとなります。Linux用のバリエーションを探してみると、 _Copy_conjoint_jints_atomic への呼び出しが見つかります。最後に待ち受けているのはアセンブリの獣です!
# Support for void Copy::conjoint_jints_atomic(void* from,
# void* to,
# size_t count)
# Equivalent to
# arrayof_conjoint_jints
.p2align 4,,15
.type _Copy_conjoint_jints_atomic,@function
.type _Copy_arrayof_conjoint_jints,@function
_Copy_conjoint_jints_atomic:
_Copy_arrayof_conjoint_jints:
pushl %esi
movl 4+12(%esp),%ecx # count
pushl %edi
movl 8+ 4(%esp),%esi # from
movl 8+ 8(%esp),%edi # to
cmpl %esi,%edi
leal -4(%esi,%ecx,4),%eax # from + count*4 - 4
jbe ci_CopyRight
cmpl %eax,%edi
jbe ci_CopyLeft
ci_CopyRight:
cmpl $32,%ecx
jbe 2f # <= 32 dwords
rep; smovl
popl %edi
popl %esi
ret
.space 10
2: subl %esi,%edi
jmp 4f
.p2align 4,,15
3: movl (%esi),%edx
movl %edx,(%edi,%esi,1)
addl $4,%esi
4: subl $1,%ecx
jge 3b
popl %edi
popl %esi
ret
ci_CopyLeft:
std
leal -4(%edi,%ecx,4),%edi # to + count*4 - 4
cmpl $32,%ecx
ja 4f # > 32 dwords
subl %eax,%edi # eax == from + count*4 - 4
jmp 3f
.p2align 4,,15
2: movl (%eax),%edx
movl %edx,(%edi,%eax,1)
subl $4,%eax
3: subl $1,%ecx
jge 2b
cld
popl %edi
popl %esi
ret
4: movl %eax,%esi # from + count*4 - 4
rep; smovl
cld
popl %edi
popl %esi
retポイントは、VM言語が遅いことにあるの ではなく 、ランダムメモリアクセスがパフォーマンスを低下させていることにありました。 conjoint_jints_atomic の肝は rep; smovl ^(1) です。そして、CPUが本当に好むのものがあるとすれば、それは rep 命令です。これに対して、CPUはパイプラインやプリフェッチ、キャッシュなど、この命令のために構築された全ての物―ストリーミング計算と予測的メモリアクセスを利用することができます。 «Modern Microprocessors. A 90 Minute Guide!» をお読みください。
これの意味するところは、アプリケーションに対して rep smovl は実際には線形時間の操作ではなく、やや定数時間寄りの操作である、ということです。最後のポイントを見ていきましょう。100万個の要素のリストについて、先頭に100、1000、10000個の要素を挿入してみましょう。私のマシンでは、以下のサンプルが得られました。
- 100 TestInsertHead: [41, 42, 42, 43, 46]
- 1000 TestInsertHead: [409, 409, 411, 411, 412]
- 10000 TestInsertHead: [4163, 4166, 4175, 4198, 4204]
10倍にするごとに、計算も10倍になっていますね。これは10 * O(1)だからです。
熟練の開発者はエンジニアであり、そういった人々は コンピュータサイエンスはソフトウェアエンジニアリングではない というのを御存じでしょう。理論上は良いものが、全てのファクターを考慮しないことにより実践では悪くなるということもあります。実世界で成功するためには、下部を支えるシステムとその動作に関する理解がとても重要になり、影響力を持ちます。
そしてこれは私だけの意見ではなく、数年前 ^(2) からRedditにこんなリンクがありました―「 Bjarne Stroustrup: Why you should avoid LinkedLists 」というものです。私は彼の論旨に同意しています。しかし、勿論、気を確かに持って、誰かや何かを盲目的に信じることのないようにしましょう。計測、計測、計測です。
私の今までで一番のお気に入りである James Mickensの『The Night Watch』 を添えてお別れしたいと思います。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事