2017年8月15日
Kotlinの隠れたコストについてのベンチマーク
(2017/6/25)by Renato Athaydes
本記事は、原著者の許諾のもとに翻訳・掲載しております。
@BladeCoder が書いた Kotlinの隠れたコストの調査 という一連のブログ記事は、ある Kotlin 構文にどのように隠れたコストがあるのかを説明しました。
実際の隠れたコストは、普通、不可視オブジェクトのインスタンス化やプリミティブ値のボクシング/アンボクシングに起因します。これらのコストは、Kotlinコンパイラがどのように上記の構文をJVMのバイトコードに変換するのかを理解していない開発者には特に見えづらいのです。
しかし、何らかの数字を示さずに隠れたコストの話をするだけでは、実際にどのくらいコストのことを心配すべきなのかという疑問が湧いてきます。コードベースのいたるところで、これらのコストを考慮すべきでしょうか?あるKotlin構文は単に全面的に禁止されるべきでしょうか?あるいは、最も範囲の狭い内部ループの中でだけ考慮されるべきでしょうか?
さらに挑発的な言い方をすれば、これらのいわゆるコストが実際、パフォーマンスにペナルティをもたらすのでしょうか(JVMが実行時にどうやって積極的にコードを最適化するのかを見る限り、それを利用実態に基づき効率的なマシン語に変換するなら、この問いへの答えは、見かけほど明確ではないかもしれません)。
隠れたコストに数字を入れて示さなければ、答えることは不可能です。
このような理由から、 JMHベンチマーク を書いて、これまでに公開された一連のブログ記事の3つ全てにおいて触れられた各Kotlin構文の実際のコストを数値化することにしました。
方法とシステム
ブログ記事の中で取り上げられたKotlin構文のコストの一部は、Java構文のコストと直接比較することができます。例えば、Kotlinラムダのコストは、Javaラムダのコストと直接比較することができます。しかし、多くのKotlin構文はJavaに同等のものがありません。このような場合、Kotlin構文とそれと同等のJavaのバージョンとを比較する代わりに、コストのかかる構文を改善しようと著者が提案したものとを比較します。
コードはGitHub にあるので、誰もが自身のシステム上で実行し、さまざまなシステムで数値が一致しているかを確認することができます( Redditのコメント にいくつかの結果を集めるのは興味深いことでしょう)。
コードを実行する場合、フルベンチマークには数時間かかることに注意してください。
全ての結果は、下に示すシステムを用いて集められました。
Macbook Pro (2,5 GHz Intel Core i7, 16GB of RAM)
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)Kotlinのバージョン(1.1.3)とJMH(0.5.6)は記述時点での最新版です( pom.xml をご覧ください)。
更新:Android ARTベンチマークは、WillowTreeApps.comの ブログ記事 から入手できます。
パート1
https://medium.com/@BladeCoder/exploring-kotlins-hidden-costs-part-1-fbb9935d9b62
高階関数とラムダ式
この最初の例では、著者が何のコストについて話をしているのかがあまり明確ではありませんでした。初期設定でKotlinがラムダを持たないJava 6 VMを対象にしていることを考えると、著者は単に、Kotlinラムダを使うコストを参照しようとしているように思えます。
しかし、記事の後半で述べられたアドバイスは、単なるラムダ、厳密にいえば下の例で示されたラムダだけではなく、 ラムダをキャプチャすること に特化したものです。
fun transaction(db: Database, body: (Database) -> Int): Int {
db.beginTransaction()
try {
val result = body(db)
db.setTransactionSuccessful()
return result
} finally {
db.endTransaction()
}
}これは、次のようなシンタックスで使用されます。
val deletedRows = transaction(db) {
it.delete("Customers", null, null)
}ここでの、隠れたコストは、 transaction 関数が上で呼び出された時に、 Function オブジェクトが作られる かもしれない という事実だけのように思われます。しかし、著者自身が気付いているように、この例はラムダのキャプチャではないので、この特定の関数に対する事例ということではありません。ですから、シングルトンの Function インスタンスが作成され、起動の度に使用されます。
記事で触れられているコストで唯一残っているのは ランタイムコストではありません 。つまり3~4個の余分なメソッドが、Kotlinコンパイラによって生成された関数のクラスにより作成されます。
とにかく、Java 8のラムダと比較した場合、Kotlinラムダに関係する実際のランタイムコストが存在するかどうか確認することにしました。というのも、問題の説明から、このようなコストが存在するはずだという印象を私は持ち続けていたのです( ラムダのキャプチャは記事のこの部分に寄せられたアドバイスの中で避けることを勧められていますが、これを使うコストは、パート2でベンチマークを行う予定ですので、どうぞお読みください )。
同等の関数を、Java 8を用いて次のように実装してみました。
public static int transaction( Database db, ToIntFunction<Database> body ) {
db.beginTransaction();
try {
int result = body.applyAsInt( db );
db.setTransactionSuccessful();
return result;
} finally {
db.endTransaction();
}
}Java 8で、この関数を呼び出すシンタックスは、Kotlinのものとは若干ですが異なっています。
int deletedRows = transaction( db, ( database ) ->
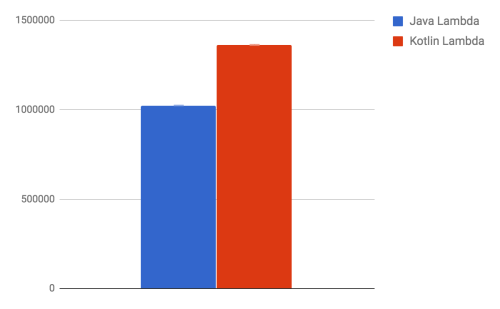
database.delete( "Customer", null, null ) );Javaのバージョン 8とKotlinのバージョンを比較したベンチマークの結果は以下のとおりです。
| ベンチマーク | モード | 標本 | 平均 | 平均誤差 | 単位 |
| c.a.k.part1.KotlinBenchmarkPart1.javaLambda | thrpt | 200 | 1024302.409 | 1851.789 | ops/ms |
| c.a.k.part1.KotlinBenchmarkPart1.kotlinLambda | thrpt | 200 | 1362991.121 | 2824.862 | ops/ms |

上のグラフは、高いほどよいことを示しています(ops/msが高い)。
この例では、Kotlinラムダを使うオーバーヘッドも表していることに注意してください。このラムダはJava 8の例で使用されている特殊なバージョンの( ToIntFunction )に対して整数を返します。
しかし、KotlinラムダはJavaラムダよりも、かなり速いように思います。やはり、実際にKotlinの方がJavaよりも30%程度も処理が速かったので、ここでのコストは問題にならないと思われます。平均誤差は、KotlinのほうがJavaよりも若干大きいですが、上のグラフでは、エラーバーを示そうとしているのに、その影も形もありません。(小さ過ぎて見えないだけです)。
さて、いずれにせよ、Kotlinラムダのコストを下げるために(たとえそのことを心配する必要がないように思えたとしても)、著者が提案している解決策は、関数をインライン化することです。これにより、 inline キーワードを用いて transaction 関数を単純に宣言することにより、実行できるようになります。
これにより、以下の結果が得られます。
結果
| ベンチマーク | モード | 標本 | 平均 | 平均誤差 | 単位 |
| c.a.k.part1.KotlinBenchmarkPart1.kotlinInlinedFunction | thrpt | 200 | 1344885.445 | 2632.587 | ops/ms |

見て分かるように、この例では、インライン関数を使用しても、Kotlinのラムダ式のパフォーマンスは全く改善されません。どちらかというと、パフォーマンスが若干悪化しただけです。
正直なところ、著者と私が期待したものと正反対の結果が出た理由は全く分かりません。ベンチマークコードを見ても、明らかに間違っている点は見当たりません。ですから、慎重にではありますが、これらの数値が現実のものであると確信しています。
更新:驚くべき結果について、考えられる理由に関する こちらの議論 をご覧ください。
コンパニオンオブジェクト
著者が提示しているように、コンパニオンオブジェクトは、クラスプロパティにアクセスするために生成された合成ゲッターとセッターを原因とする、オーバーヘッドを示しているように思われます。最悪の場合、単純な定数値を取得するために、最初のゲッターがコンパニオンオブジェクトのインスタンスメソッドである2番目のゲッターを呼び出さなくてはならない可能性もあります。
最悪の場合のコストを測定するために、以下のKotlinクラスを使って、ブログ記事で提示されたコンパニオンオブジェクトの例を結合することにしました。
class MyClass private constructor() {
companion object {
private val TAG = "TAG"
fun newInstance() = MyClass()
}
fun helloWorld() = TAG
}以下が、ベンチマークされたKotlinの関数です。
fun runCompanionObjectCallToPrivateConstructor(): String {
val myClass = MyClass.newInstance()
return myClass.helloWorld()
}上記のKotlinのコードのコストは、それと同等の単純なJavaの実装との比較で測定します。この実装は、クラス自体の中でシンプルなstatic finalの Stringを使用したものです。
class MyJavaClass {
private static final String TAG = "TAG";
private MyJavaClass() {
}
public static String helloWorld() {
return TAG;
}
public static MyJavaClass newInstance() {
return new MyJavaClass();
}
}使用したJavaのメソッドはこちらです。
public static String runPrivateConstructorFromStaticMethod() {
MyJavaClass myJavaClass = newInstance();
return myJavaClass.helloWorld();
}結果
| ベンチマーク | モード | 標本 | 平均 | 平均誤差 | 単位 |
| c.a.k.part1.KotlinBenchmarkPart1.javaPrivateConstructorCallFromStaticMethod | thrpt | 200 | 398709.154 | 800.190 | ops/ms |
| c.a.k.part1.KotlinBenchmarkPart1.kotlinPrivateConstructorCallFromCompanionObject | thrpt | 200 | 404746.375 | 621.591 | ops/ms |

僅差ですが、これも同様に、KotlinのパフォーマンスがJavaよりも優れています。
パート2
ローカル関数
ブログ記事のこのパートでは、著者がKotlinのローカル関数に関する隠れたコストを理論化しています。唯一のコストと思われるのは、コンテクストから何もキャプチャしない関数ではなく、キャプチャするための Function オブジェクトです。
このテストは、Javaのローカル関数、またはラムダから始めます。これは、ボクシングを避けるものですが、コンテクストから1つの変数をキャプチャします。
public static int someMath( int a ) {
IntUnaryOperator sumSquare = ( int b ) -> ( a + b ) * ( a + b );
return sumSquare.applyAsInt( 1 ) + sumSquare.applyAsInt( 2 );
}ブログ記事内で、例として全く同じ関数がKotlinに実装されています。
fun someMath(a: Int): Int {
fun sumSquare(b: Int) = (a + b) * (a + b)
return sumSquare(1) + sumSquare(2)
}コンテクストからのキャプチャを回避するKotlinの2つ目のバージョンも、同様に試してみました。
fun someMath2(a: Int): Int {
fun sumSquare(a: Int, b: Int) = (a + b) * (a + b)
return sumSquare(a, 1) + sumSquare(a, 2)
}結果
| ベンチマーク | モード | 標本 | 平均 | 平均誤差 | 単位 |
| c.a.k.part2.KotlinBenchmarkPart2.javaLocalFunction | thrpt | 200 | 897015.956 | 1951.104 | ops/ms |
| c.a.k.part2.KotlinBenchmarkPart2.kotlinLocalFunctionCapturingLocalVariable | thrpt | 200 | 909087.356 | 1690.368 | ops/ms |
| c.a.k.part2.KotlinBenchmarkPart2.kotlinLocalFunctionWithoutCapturingLocalVariable | thrpt | 200 | 908852.870 | 1822.557 | ops/ms |

これまでのところ、特に驚きはありません。この場合もKotlinがJavaより若干優れているようです。つまり、Kotlinにコストがあるとしても、ささいなものであるということです。
Null安全
Kotlinのコンパイラでは、各パブリック関数の非nullパラメータにnullチェックが追加されました。ただし、どの程度のコストがかかるのでしょうか。
見てみましょう。
以下に、テストに使われたKotlinの関数を示します。
fun sayHello(who: String, blackHole: BlackHole) = blackHole.consume("Hello $who")Blackholeは、ベンチマーク中に値を消費するために使えるJMHクラスです。コンパイラが必ず値を計算するようにし、ベンチマークを無意味にするものです。
Javaのベースラインは以下のとおりです。
public static void sayHello( String who, BlackHole blackHole ) {
blackHole.consume( "Hello " + who );
}結果
| ベンチマーク | モード | 標本 | 平均 | 平均誤差 | 単位 |
| c.a.k.part2.KotlinBenchmarkPart2.javaSayHello | thrpt | 200 | 73353.725 | 155.551 | ops/ms |
| c.a.k.part2.KotlinBenchmarkPart2.kotlinSayHello | thrpt | 200 | 75637.556 | 162.963 | ops/ms |

この場合も、Kotlinを用いるコストはわずかです。言い換えると、バイトコードの違いに基づく私たちの予想に反して、Javaを使うよりもKotlinを使ったほうがパフォーマンスの向上に役立つように思われます。
注意:Null許容型プリミティブ型 をベンチマークするパートをスキップしました。私が思うに、Javaに比べてKotlinの隠れたコストではないからです。JavaのNull許容型プリミティブはKotlinにおけるボクシングと全く同等のコストがかかるからです。
可変引数
著者が指摘しているように、メソッドパラメータに可変引数を使用するコストは、メソッドの引数として既存の配列を使うために、スプレッド演算子を使う必要がある時にだけ発生します。これは、Javaでは必要ない類のものです。
ですので、オーバーヘッドをテストするために、以下のJavaメソッドの呼び出しを比較します。
public static void runPrintDouble( BlackHole blackHole, int[] values ) {
printDouble( blackHole, values );
}
public static void printDouble( BlackHole blackHole, int... values ) {
for (int value : values) {
blackHole.consume( value );
}
}比較対象は、Kotlinの同等の実装です。
fun runPrintDouble(blackHole: BlackHole, values: IntArray) {
printDouble(blackHole, *values)
}
fun printDouble(blackHole: BlackHole, vararg values: Int) {
for (value in values) {
blackHole.consume(value)
}
}結果
| ベンチマーク | モード | 標本 | 平均 | 平均誤差 | 単位 |
| c.a.k.part2.KotlinBenchmarkPart2.javaIntVarargs | thrpt | 200 | 173265.270 | 260.837 | ops/ms |
| c.a.k.part2.KotlinBenchmarkPart2.kotlinIntVarargs | thrpt | 200 | 83621.509 | 990.854 | ops/ms |

ついに、絶対に回避するべきKotlinの隠れたコストが発生しました。Kotlinのスプレッド演算子は、メソッドの呼び出し前に生成される配列の全体コピーを引き起こすもので、これを使うと、パフォーマンスにおいて非常に高いコストがかかります(さらに配列のサイズが増える恐れもあります)。この場合は、Javaのバージョンが、同等のKotlinバージョンに比べて実行速度は200%速かったようです。
注意: 比較すべき同等の対象がJavaにないので、 配列と引数の混在の受け渡し のパートも、スキップしました。
パート3
デリゲートプロパティ
Kotlinでデリゲートプロパティを使う場合の実際のコストを測定するために、ベースラインとして、最も効果的と思われるJavaの同等の実装を使用することにしました。この2つは同じものではないので、Kotlinには完全に公正ではないかもしれません。さらに、デリゲートプロパティではJavaでは不可能なパターンが使えます。
しかし、こうしたことに留意すれば、たとえこのケースのために特別に記述されたJavaバージョンと比較したとしても、実際にどんなコストが発生するのかを知るには有効だと思われます。
Javaのベースラインは、以下のような小さなクラスを使用します。
class DelegatePropertyTest {
public static String stringValue = "hello";
public static String someOperation() {
return stringValue;
}
}
class Example2 {
public String p;
public void initialize() {
p = DelegatePropertyTest.someOperation();
}
}見てお分かりのように、呼び出し側は、 p プロパティを初期化するために、 Example2 で initialize を忘れずに呼び出さなければなりません。
public static void runStringDelegateExample( BlackHole blackHole ) {
Example2 example2 = new Example2();
example2.initialize();
blackHole.consume( example2.p );
blackHole.consume( example2.p );
}Kotlinのコードは、pプロパティを初期化するためにデリゲートクラスを使用しています。
class StringDelegate {
private var cache: String? = null
operator fun getValue(thisRef: Any?, property: KProperty<*>): String {
var result = cache
if (result == null) {
result = someOperation()
cache = result
}
return result!!
}
operator fun setValue(thisRef: Any?, property: KProperty<*>, value: String) {
cache = value
}
}class Example {
var p: String by StringDelegate()
}Kotlinのテスト関数はJavaのテスト関数とほぼ同じ働きをしますが、 Example クラスのプロパティを明示的に初期化する必要はありません。
fun runStringDelegateExample(blackHole: BlackHole) {
val example = Example()
blackHole.consume(example.p)
blackHole.consume(example.p)
}結果
| ベンチマーク | モード | 標本 | 平均 | 平均誤差 | 単位 |
| c.a.k.part3.KotlinBenchmarkPart3.javaSimplyInitializedProperty | thrpt | 200 | 274394.088 | 554.171 | ops/ms |
| c.a.k.part3.KotlinBenchmarkPart3.kotlinDelegateProperty | thrpt | 200 | 255899.824 | 910.112 | ops/ms |

Javaプロパティを手動で初期化することに比べると、Kotlinのデリゲートプロパティを使うことで、ここでは10%程度のわずかなコストが発生しているのが分かります。
注意: 汎用デリゲート についてはスキップします。繰り返しになりますが、発生するかもしれないコストはボクシング/アンボクシングされたプリミティブ型に関係するもので、それ自身の機能によるものではありません。
遅延デリゲート のパートも隠れたコストではないのでスキップします。これは、遅延デリゲートの同期プロパティを正確に特定する方法について記述された情報セクションです。
範囲(間接参照)
現在Javaには同等の概念がないので、範囲の使用によるコストを見つけ出すには、多くの例で示されているパフォーマンスの問題について提案された解決策のパフォーマンスを比較します。
まずは、必要に応じて最低でも、間接参照で範囲を使うコストと、直接参照で範囲を使うコストを比較します。
間接的な方法を使用しているコードは、ゲッターの呼び出しによる範囲の取得を含んでいます。
private val myRange get() = 1..10
fun isInOneToTenWithIndirectRange(i: Int) = i in myRange直接的な範囲の使用とは対照的です。
fun isInOneToTenWithLocalRange(i: Int) = i in 1..10結果
| ベンチマーク | モード | 標本 | 平均 | 平均誤差 | 単位 |
| c.a.k.part3.KotlinBenchmarkPart3.kotlinIndirectRange | thrpt | 200 | 1214464.562 | 2071.128 | ops/ms |
| c.a.k.part3.KotlinBenchmarkPart3.kotlinLocallyDeclaredRange | thrpt | 200 | 1214883.411 | 1797.921 | ops/ms |

範囲の間接参照の使用に伴うわずかなコストがあったとしても、顕著なものではありません。
範囲(非プリミティブ型)
著者によると、範囲に関するその他コストとして挙げられるのは、たとえローカルに宣言された範囲であっても、範囲が非プリミティブ型で使われた時に新たな ClosedRange インスタンスが生成されることです。以下に例を挙げます。
fun isBetweenNamesWithLocalRange(name: String): Boolean {
return name in "Alfred".."Alicia"
}上記のコードは以下のコードよりコストがかかります。
private val NAMES = "Alfred".."Alicia"
fun isBetweenNamesWithConstantRange(name: String): Boolean {
return name in NAMES
}結果
| ベンチマーク | モード | 標本 | 平均 | 平均誤差 | 単位 |
| c.a.k.part3.KotlinBenchmarkPart3.kotlinStringRangeInclusionWithLocalRange | thrpt | 200 | 211468.439 | 483.879 | ops/ms |
| c.a.k.part3.KotlinBenchmarkPart3.kotlinStringRangeInclusionWithConstantRange | thrpt | 200 | 218073.886 | 412.408 | ops/ms |

できる限り最高のパフォーマンスが必要な場合は、確かに、ローカルに宣言された範囲よりも、コンスタントで非プリミティブな範囲を使用するほうがよいことが分かります。
コンスタントな範囲の代わりにローカルな範囲を使うことに伴うコストは3%程度ですので、心配するほどのことはありません。
範囲(イテレーション)
範囲に関してもう1つ起こり得る問題があります。それはイテレートする場合です。
プリミティブな範囲に対してイテレートすると、オーバーヘッドがゼロになるはずです。
fun rangeForEachLoop(blackHole: BlackHole) {
for (it in 1..10) {
blackHole.consume(it)
}しかし、ブログ記事によると、forEachメソッドを使うイテレートでは、オーバーヘッドが発生します。
fun rangeForEachMethod(blackHole: BlackHole) {
(1..10).forEach {
blackHole.consume(it)
}
}範囲に対するイテレートはstepを使って作成するべきです。
fun rangeForEachLoopWithStep1(blackHole: BlackHole) {
for (it in 1..10 step 1) {
blackHole.consume(it)
}
}結果
| ベンチマーク | モード | 標本 | 平均 | 平均誤差 | 単位 |
| c.a.k.part3.KotlinBenchmarkPart3.kotlinRangeForEachFunction | thrpt | 200 | 108382.188 | 561.632 | ops/ms |
| c.a.k.part3.KotlinBenchmarkPart3.kotlinRangeForEachLoop | thrpt | 200 | 331558.172 | 494.281 | ops/ms |
| c.a.k.part3.KotlinBenchmarkPart3.kotlinRangeForEachLoopWithStep1 | thrpt | 200 | 331250.339 | 545.200 | ops/ms |

上のグラフを見ると、範囲に ForEach 関数を使うことは、著者が予測したように絶対に避けた方がよいことが分かります。使用すると forループ に比べてパフォーマンスは300%遅くなってしまいます。
一方、ブログ記事のアドバイスに反して、明示的な step の使用がforループのrangeのパフォーマンスに影響を与えることはないようです。
イテレーション:インデックスのコレクション
最後に、コンパイラで最適化されていないカスタムクラス上でインデックスを使用するコストを測定してみましょう。
この例では、 SparseArray のモックバージョンを作成します。
class SparseArray<out T>(val collection: List<T>) {
fun size() = collection.size
fun valueAt(index: Int) = collection[index]
}著者が提案しているように、カスタムな indices プロパティを使ってこれを展開します。
inline val SparseArray<*>.indices: IntRange
get() = 0..size() – 1それでは、インデックスに対してイテレートします。
fun printValuesUsingIndices(map: SparseArray<String>, blackHole: BlackHole) {
for (i in map.indices) {
blackHole.consume(map.valueAt(i))
}
}著者によると、この代わりに lastIndex を使うほうが良い解決策だということです。
inline val SparseArray<*>.lastIndex: Int
get() = size() – 1fun printValuesUsingLastIndexRange(map: SparseArray<String>, blackHole: BlackHole) {
for (i in 0..map.lastIndex) {
blackHole.consume(map.valueAt(i))
}
}結果
| ベンチマーク | モード | 標本 | 平均 | 平均誤差 | 単位 |
| c.a.k.part3.KotlinBenchmarkPart3.kotlinCustomIndicesIteration | thrpt | 200 | 79096.631 | 134.813 | ops/ms |
| c.a.k.part3.KotlinBenchmarkPart3.kotlinIterationUsingLastIndexRange | thrpt | 200 | 80811.554 | 122.462 | ops/ms |

カスタムコレクションに対してイテレートするには、0から lastIndex までの範囲を使うほうが、少しは安全かもしれませんが、 indices を使用する影響はかなり小さく、2%程度遅くなるだけのようです。
まとめ
さて、注意する必要のない機能、使用を避けるべき機能が分かりましたか?
このベンチマークの結果から、以下に挙げた機能のうち、緑のチェックマークのものは、注意せずに使えます(コストは5%以下)。
赤いマークの機能は、パフォーマンスは二の次である場合を除いて、できれば避けたほうがよいものです。
いずれにせよ、パフォーマンスに関しては、測定してみなければ分からないということが、この分析からお分かりいただければ幸いです。
 高階関数とラムダ式
高階関数とラムダ式
Kotlinのラムダと高階関数は避けるべきだとする根拠は何も見当たりません。むしろ、Java 8のラムダよりも、実行速度は速いようです。
コンパニオンオブジェクト
コンパニオンオブジェクトについては、パフォーマンスにおける顕著なコストは測定されませんでした。ですので、パフォーマンスの観点から、使用を避けるべきという理由はありません。
ローカル関数
ローカル関数は、キャプチャする、しないにかかわらず、Kotlinのコードに影響はないようです。
Null安全
KotlinのNull安全チェックは、無視しても問題ないくらい、パフォーマンスにわずかな影響しか与えません。
 可変引数+スプレッド演算子
可変引数+スプレッド演算子
Kotlinの可変引数は、スプレッド演算子と併用する場合、余分で不必要な配列コピーのために高いパフォーマンスのコストがかかります。パフォーマンスに配慮が必要ならば避けるべきでしょう。
デリゲートプロパティ
パフォーマンスが重要なコードにおいてデリゲートプロパティを使用するのは避けたほうがよいでしょう。たとえオーバーヘッドがわずか10%程度でも、特定の環境では受容できないかもしれません。
範囲の間接参照
範囲の間接参照によるパフォーマンスへの影響は測定されませんでした。
範囲(ローカル、非プリミティブ型)
非プリミティブ型のローカルな範囲を使うコストはほとんどありません(測定値は3%程度でした)。ですので、パフォーマンスが重要であるような極端な環境においてのみ避けるべきでしょう。
範囲(forEach関数)
範囲においてforEachを呼び出すことは絶対に避けるべきです。300%程度の非常に高いコストがかかります。Kotlinのチームには、いつかこの問題に取り組んでほしいところですが、今のところ使用するのは名案とは言えません。
範囲(明示的stepを用いたイテレーション)
明示的なstepの使用による範囲に対するイテレーションの、速度への影響はないようです。
カスタムコレクションにおけるインデックスの使用
カスタムコレクションにおける indices プロパティの使用に関しては、 lastIndex への範囲を使用するのに比べて顕著なコストはありませんでした。2%程度のコストはあるため、パフォーマンスが重要なアプリケーションでは lastIndex を使うことはお勧めできるでしょう。
全結果
| ベンチマーク | モード | 標本 | 平均 | 平均誤差 | 単位 |
| c.a.k.part1.KotlinBenchmarkPart1.empty | thrpt | 200 | 3540527.759 | 23025.839 | ops/ms |
| c.a.k.part1.KotlinBenchmarkPart1.javaLambda | thrpt | 200 | 1024302.409 | 1851.789 | ops/ms |
| c.a.k.part1.KotlinBenchmarkPart1.javaPrivateConstructorCallFromStaticMethod | thrpt | 200 | 398709.154 | 800.190 | ops/ms |
| c.a.k.part1.KotlinBenchmarkPart1.kotlinInlinedFunction | thrpt | 200 | 1344885.445 | 2632.587 | ops/ms |
| c.a.k.part1.KotlinBenchmarkPart1.kotlinLambda | thrpt | 200 | 1362991.121 | 2824.862 | ops/ms |
| c.a.k.part1.KotlinBenchmarkPart1.kotlinPrivateConstructorCallFromCompanionObject | thrpt | 200 | 404746.375 | 621.591 | ops/ms |
| c.a.k.part2.KotlinBenchmarkPart2.javaIntVarargs | thrpt | 200 | 173265.270 | 260.837 | ops/ms |
| c.a.k.part2.KotlinBenchmarkPart2.javaLocalFunction | thrpt | 200 | 897015.956 | 1951.104 | ops/ms |
| c.a.k.part2.KotlinBenchmarkPart2.javaSayHello | thrpt | 200 | 73353.725 | 155.551 | ops/ms |
| c.a.k.part2.KotlinBenchmarkPart2.kotlinIntVarargs | thrpt | 200 | 83621.509 | 990.854 | ops/ms |
| c.a.k.part2.KotlinBenchmarkPart2.kotlinLocalFunctionCapturingLocalVariable | thrpt | 200 | 909087.356 | 1690.368 | ops/ms |
| c.a.k.part2.KotlinBenchmarkPart2.kotlinLocalFunctionWithoutCapturingLocalVariable | thrpt | 200 | 908852.870 | 1822.557 | ops/ms |
| c.a.k.part2.KotlinBenchmarkPart2.kotlinSayHello | thrpt | 200 | 75637.556 | 162.963 | ops/ms |
| c.a.k.part3.KotlinBenchmarkPart3.javaSimplyInitializedProperty | thrpt | 200 | 274394.088 | 554.171 | ops/ms |
| c.a.k.part3.KotlinBenchmarkPart3.kotlinCustomIndicesIteration | thrpt | 200 | 79096.631 | 134.813 | ops/ms |
| c.a.k.part3.KotlinBenchmarkPart3.kotlinDelegateProperty | thrpt | 200 | 255899.824 | 910.112 | ops/ms |
| c.a.k.part3.KotlinBenchmarkPart3.kotlinIndirectRange | thrpt | 200 | 1214464.562 | 2071.128 | ops/ms |
| c.a.k.part3.KotlinBenchmarkPart3.kotlinIterationUsingLastIndexRange | thrpt | 200 | 80811.554 | 122.462 | ops/ms |
| c.a.k.part3.KotlinBenchmarkPart3.kotlinLocallyDeclaredRange | thrpt | 200 | 1214883.411 | 1797.921 | ops/ms |
| c.a.k.part3.KotlinBenchmarkPart3.kotlinRangeForEachFunction | thrpt | 200 | 108382.188 | 561.632 | ops/ms |
| c.a.k.part3.KotlinBenchmarkPart3.kotlinRangeForEachLoop | thrpt | 200 | 331558.172 | 494.281 | ops/ms |
| c.a.k.part3.KotlinBenchmarkPart3.kotlinRangeForEachLoopWithStep1 | thrpt | 200 | 331250.339 | 545.200 | ops/ms |
| c.a.k.part3.KotlinBenchmarkPart3.javaStringComparisons | thrpt | 200 | 211488.726 | 450.531 | ops/ms |
| c.a.k.part3.KotlinBenchmarkPart3.kotlinStringRangeInclusionWithConstantRange | thrpt | 200 | 218073.886 | 412.408 | ops/ms |
| c.a.k.part3.KotlinBenchmarkPart3.kotlinStringRangeInclusionWithLocalRange | thrpt | 200 | 211468.439 | 483.879 | ops/ms |

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事