2015年5月11日
Less is more:プログラミング言語設計の進歩史

(2015-4-13)by Mark Seemann
本記事は、原著者の許諾のもとに翻訳・掲載しております。
多くの言語は冗長性を有していますが、これらの機能を省いていくことも言語設計の進歩につながります。
巷には数多くのプログラミング言語があり、新しい言語も継続的に紹介されています。でも新しいものが古いものより優れているかというと、そうとは言えません。なぜなら、何が“優れているか”を判断する明確な尺度は存在しないからです。
それでも過去からの流れを見ていくと、優れた言語を作る1つの方向性は、言語にある冗長性を特定し、それらを持たない新たな言語をデザインすることにあるように思えます。
「完璧とは、それ以上足せない時ではなく、それ以上引けない時に達成される」 – Antoine de Saint Exupéry
この投稿では、現在までに知られている言語の冗長的機能を見ていくと共に、恐らく冗長性を有しているだろうと思われる機能についても触れていきます。
自ら墓穴を掘るあらゆる可能性
初めてコンピュータが作られた時代には、プログラムは機械語やアセンブリ言語で書いてやる必要がありました。機械語であれば、CPUの命令セットに従って記述されるので、CPUでできることの全てを表現することができます。ただ、機械語を使って正確にプログラミングできれば問題ありませんが、間違って運用してしまうこともあるわけで、そういった場合、クラッシュが多発したり、もっとひどい時には実行中にマシンを破壊したりすることだってあり得ます。
多分、皆さんが普段、使っている言語はもっと高水準な言語でしょう。それでも、これについての私の経験を共有していただければ、物事を正しくやり遂げるために多くのトライアルアンドエラーが必要だということが分かっていただけるはずです。どのプログラムにおいても、正しいものに対して間違ったバリエーションが数多く存在します。実際、その数は比較にならないほどです。
機械語を使っている場合、間違ったプログラミングをしてしまう可能性はいくらでもあります。確かにCPUで実行可能な全てを表現はできるしょう。でもその記述は正しくないことがほとんどです。そんなわけで、実際に有効なプログラムは、実行可能な全命令のうちのほんの一握りにしかなりません。
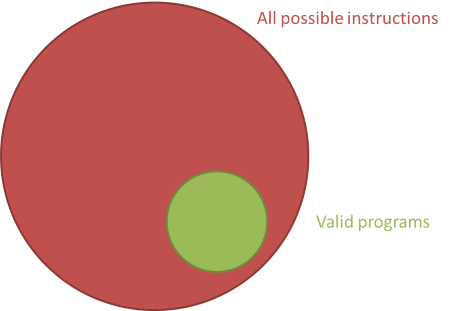
訳注:実行可能な命令群,有効なプログラム
初期の頃のコンピュータプログラマたちは、機械語でのプログラミングにエラーがつきまとうという事実をすぐに認識しました。また、プログラムが判読できないのもまた問題でした。そこでこれに対処すべくアセンブリ言語が導入されるようになります。ただし、根本的な問題の解決には至りません。アセンブリ言語というのは、詰まるところ機械語を”人間が読めるように”逐語訳したものでしかなく、機械語を使うことで生じるエラーの芽を摘めたわけではなかったからです。
高水準言語
機械語とアセンブリ言語による困難を経て、高水準言語によるプログラミングが考案されました。初期に開発された高水準言語は現在ではほとんど使われていませんが、その中で今も健在なCは“低水準な”高水準言語の最適な例と言えるでしょう。
訳注:実行可能な命令群,高水準言語,有効なプログラム
Cでは上述した有効なプログラムのほとんど全てを表現できます。間違った記述でプログラム(やコンピュータ)を壊してしまう恐れがなくなったわけではありませんが、機械語とは違って言語自体が抽象化されており、表現自体ができない命令というのもあります。それらはいずれにしろ無効な命令シーケンスなので、いい意味で表現できないと言ってもいいでしょう。
ここであることに気付きませんか? 機械語から高水準言語へと移行したことで、言語の機能の一部がそぎ落とされました。機械語では全てを表現できましたが、高水準言語ではそうではなくなっていますよね。しかし実害はありません。なくなった機能というのは、そもそも有用なものではなかったからです。
goto文
1968年、Edsger Dijkstraがその(悪)名高い論説、『 Go To Statement Considered Harmful(害悪と考えられるgoto文) 』を発表しました。その中で彼はgoto文の害悪について触れ、プログラム内でgoto文は”使わない方がいい”と論じています。彼のこの言葉はその後10年にも及ぶ論争を巻き起こしましたが、今では彼の正しさに異論を唱える人は少ないはずです。現時点で広範に使われている人気の高い言語(JavaやJavaScriptなど)に、goto文は使われていません。

訳注:実行可能な命令群,goto文なしの言語,有効なプログラム
実のところ、goto文というのは冗長表現以外の何物でもなかったため、この機能をカットしても、表現できる 有効な プログラムの範囲は変わりません。その上、 無効な プログラミングをしてしまうリスクを減らすことにもつながるのです。
あるパターンに気付きましたか?
何かを引くことが改善につながっていますよね。
これは別に新しい発想ではありません。 Robert C. Martinは数年前に同じことを語っています 。
ただ、好き勝手に 何でも 取り除いていいというわけではありませんよ。それによって有効なプログラムが書けなくなることだってあります。

訳注:実行可能な命令群,不適切な機能が取り除かれた言語,有効なプログラム
取り除くべき 適切な 機能は見極める必要があります。
例外
近年では、エラーが発生した際は例外メカニズムで処理すべきという認識を大方の人が持っているようです。少なくとも エラーコード を返す方法が 最適でない ことについては誰も異論はないでしょう(私もありません)。エラーコードを介した処理よりもっと豊かで、実用性と堅牢性を兼ね備えたものが必要ですよね。
例外の問題は、このメカニズムが実際は goto文をベースにしたもの だということです。先ほど、goto文は害悪であると学んだばかりですよね。
これに対しては、 直和型 を使って 構成可能な形で成功や失敗 の いずれか を示すのが良い方法だと思います。
ポインタ
Robert C. Martinが指摘したように、CやC++を含む古い言語ではポインタを操作できますが、いったんポリモーフィズムを導入してしまうと”生の”ポインタはもはや必要なくなってしまいます。JavaにもJavaScriptにもポインタはありません。C#では 一応 、使うことはできますが、私自身はWindows APIとの相互運用の目的以外で必要と思ったことはありません。
上記の言語の実証から、参照による値渡しのためにポインタにアクセスする必要はないことが分かると思います。ポインタは抽象化することができるのです。
数値
最も強く型付けされた言語では、様々な数値型を選択することができます。例えばバイト、16ビット整数、32ビット整数、32ビット 符号なし 整数、単精度浮動小数点数などです。選択できること自体は1950年代には実情に沿うものでしたが、現在ではほとんど意味を成しません。逆に数値型のことでマイクロチューニングに気を取られすぎると、大局を見失ってしまう可能性もあります。 Douglas Crockfordが説明したように、JavaScriptには 単一の 数値型しかありません。これはすばらしいアイデアだと思います。ただ、その単一の型が適切でないのは残念ですがね 。
訳注:実行可能な命令群,適切な単一数値型の言語,有効なプログラム
現代のコンピュータリソースであれば、数値型が混在したものよりも、適切な単一の型に制限されたプログラミング言語の方が優れていると言えると思います。
ヌルポインタ
ヌルは最も誤解されている言語構造の1つです。あってもなくてもいい値という概念自体には何の問題もありません。優れたプログラミング言語の多くにもこの概念は採用されています。例えばHaskellの Maybe 、F#の option 、Transact-SQLの NULL などがそうですね。これら全ての言語に共通しているのは、それが言語の オプトイン機能 であるということです。値をヌル(Null可能)として宣言することはできますが、デフォルトの状態では そう (Null可能) ではありません 。
一方で、 Tony Hoareは自らが認めるところの『The Billion Dollar Mistake(10億ドルの過ち)』 の中で、CやC++、Java、C#といった主流の言語にはヌルポインタがあることを指摘しつつ、「ヌル」そのものの 概念 が問題というよりも、全てをヌルに できる ことの方が問題だと言っています。つまり、ヌルが適切な期待値として使われている場合と単に不備の場合とで区別ができなくなってしまう状況が生じているというわけです。
ヌルポインタを持たない言語を設計すれば、ヌルポインタ例外の発生を取り除くことができますよね。
訳注:実行可能な命令群,ヌルポインタを持たない言語,有効なプログラム
Tony Hoareが言うように、ヌルポインタが過去数十年にわたり多大な損失を生んでいたとすれば、その欠陥の項目を取り除くだけで大幅に経費が節約できるはずです。T-SQLやHaskell、それにF#といったチューリング完全な言語を見れば分かるように、ヌルポインタという欠陥が取り除かれた状態でも、有効なプログラムの全てを表現するのに何の支障もありません。
変数の書き換え
手続き型言語、命令型言語、オブジェクト指向型言語の主要な概念は、プログラムの実行中に変数の値を変更できるということです。だから 変数 というのです。変数のイメージは直感的です。CPUにはレジスタが含まれていて、プログラムの実行中に値が出し入れされています。また、ほとんどのプログラムの目的が、データベースに記憶させること、メールを送信すること、スクリーンを再描画すること、文書をプリントアウトすることなど、現状を変化させることだと考えると、やはり直感的にイメージしやすいのではないでしょうか。
しかし、この書き換えのためにコードの整合性を維持するのが難しくなり、ソフトウェアの欠陥を作る大きな要因となっています。例えば以下に記したC#のコードを見てください。
var r = this.mapper.Map(rendition); Map メソッドが値を返す時に、引数 rendition の値も変更されているのでしょうか? 「 Command Query Separation(コマンド・クエリ分離の原則) 」に従うなら、変更されていないはずです。しかし、Mapメソッドを実装して確かめなければ、実際のところは分かりません。また、もしこのメソッドが、アプリケーションの状態を 変更する可能性のある 他のメソッド内に呼び出されていたら、その場合はどうなるのでしょう? このような状況を回避する方法はC#(もしくはJavaやJavaScriptなど)にはありません。
大きなコールスタックを持つ複雑なプログラムでは、 全て が変更されてしまうため、コードの整合性を維持することは不可能です。もし、数十~数百個の変数を扱う操作があったとしたら、もはや、その情報を追うことなどできません。 isDirty フラグは変更しましたか? また、そこはどこでしょう? customerStatus はどうなっているでしょう?
この変更機能を取り除いた場合を想像してください。

注釈:実行可能な命令群,変更機能なしの言語,有効なプログラム
ほとんどの言語に多かれ少なかれ変更機能が備わっています。しかしHaskell(チューリング完全な言語)が示すように、暗黙的な変更の宣言を行わずにプログラミングすることも可能です。
現時点では、多くの人がHaskellは難しくて直感的ではないと反論するでしょう。この議論はgoto文を排除することに抵抗があったことを思い出させます。もし、goto文を多用することに慣れてしまっていたら、goto文を使わずに同様の動作を形成するための代わりの方法を学ばなければなりません。同じく、もし変換の宣言を多用することに慣れてしまっていれば、その宣言を行わずに同じ動作を形成する他の方法を学ばなければなりません。
参照の等価性
C#やJavaのようなオブジェクト指向型言語では、デフォルトの等価比較は参照の等価性で行います。参照の等価性では、2つの変数が同じメモリアドレスを指す場合、この2つの変数は等価であると考えられます。しかし、2つの変数の構成要素が全て同一の値であっても、指し示すメモリアドレスが異なるならば、この2つの変数は等価であるとは認められません。これは直感的ではないため、ソフトウェアの欠陥の原因となることが多々あります。
参照の等価性を言語から取り除くとどうなるでしょうか?

変更:実行可能な命令群,参照の等価性なしの言語,有効なプログラム
また、参照の等価性の代わりに、全てのデータ構造に 構造的な等価性 を用いるとどうなるでしょう?
これについて、絶対的な確信はないのですが、私の経験では参照の等価性が必要になることはほとんどないでしょう。基本的な正当性を検証するために、参照の等価性が必要になることは決してありません。パフォーマンスの最適化を導入するために、参照の比較が必要になる機会があるかもしれません。しかし、もしそうであったとしても、構造的等価性がデフォルトになるように、デフォルトの設定を切り替えても問題はありませんし、2つの変数について参照の等価性を比較するための特別な機能もあるので大丈夫です。
継承
2015年になった現在でも、Gang of Fourが クラスの継承よりオブジェクトコンポジションを選ぶべき と提唱してから20年以上が経っているにも関わらず、至るところで継承は使用されています。クラスの継承で実現できることはコンポジションとインターフェースの組み合わせでも実現できます。しかしこの逆は単一継承の言語には当てはまりません。複数のインターフェースを実装することで実現できることは、単一継承で実現できない場合があるのです。また、コンポジションは継承の上位集約です。
単なる理論としてだけではなく、私自身の何年にも渡る経験からも、継承を使わない方法でプログラミングすることが可能です。コツさえつかめば難しくはありません。
インターフェース
強く型付けされた言語(JavaやC#など)では、インターフェースを用いてポリモーフィズムを実現します。この方法では1つのインターフェース上に、様々な操作をメソッドとして一緒にまとめることができます。 オブジェクト指向の設計原則”SOLID”で導き出された結論によると 、1つのインターフェース上で全てのpublicメソッドを宣言する ヘッダインターフェース よりも、複数のインターフェースを実装する ロールインターフェース を選択するべきで、先ほど説明したとおり、 全てのインターフェースが単一のメンバのみを保持しているべきだというのが論理的な結論となります 。
しかし、インターフェースにメンバーを一つだけ持たせるようにすると、インターフェースの宣言が煩雑になりがちです。ここで重要なのは(インターフェースが提供する)処理だけですから、(ただ一つの処理を提供する代替手段として) C#では代わりにデリゲートが使え 、Javaでも代わりになるラムダが登場しました。
新しいことは何もありません。関数型言語では基本的な構成ユニットとして何年にも渡り 関数 を使用してきました。
私の経験では、単一のメンバを持つインターフェースであらゆるものを形成することができ、同じように関数を用いて全てを形成することもできることを示しています。繰り返しになりますが、Haskellのような関数型言語はチューリング完全な言語でもあるので、そんなに驚くことではありません。
インターフェースは必ずしも必要ではありません。実は、 Robert C. Martinによるとインターフェースの使用には害があるということです 。
リフレクション
あなたが.NETやJavaで何らかのメタプログラミングをした経験があるなら、リフレクションが何か知っていると思います。リフレクションとは、言語やプラットフォームの機能とAPI群セットであり、コードの検査、照会、操作、生成を可能にするものです。
メタプログラミング は不可欠なプログラミング技法なので、それを失うのは嫌です。しかしリフレクションだけがメタプログラミングを可能にする唯一の方法ではありません。いくつかの言語は 同図像性を持っています 。”同図像性を持つ”とは、プログラムがデータとして構築されていて、プログラムが自分自身をその他のデータと同じように照会や操作できることを意味します。そのような言語はリフレクション機能を必要としません。言語の中にメタプログラミングが組み込まれていると言えるからです。
つまり、リフレクションはメタプログラミングを目的とする言語の1つの機能に過ぎません。もしリフレクションを使わずに同図像性を持つことでメタプログラミングが達成可能なら、リフレクションは不必要な機能と言えるでしょう。
循環依存
ヌルポインタは欠陥の原因です。一方、私の経験上、最も保守の困難なコードは、 相互依存しているコード です。中でもひどい相互依存の例で代表的なのは”循環依存”です。C#やJavaのような言語では循環依存はまず回避不可能です。
以下のコードは私がやってしまったミスの例なのですが、 AtomEventStoreライブラリ 内でもたまたま同じミスを見つけてしまいました。このミス以外は素晴らしく保守性のあるライブラリです。以下のコードは IXmlWritable というインタフェース宣言です。
public interface IXmlWritable
{
void WriteTo(XmlWriter xmlWriter, IContentSerializer serializer);
}ご覧の通り、WriteToメソッドが IContentSerializer を引数に取っています。
public interface IContentSerializer
{
void Serialize(XmlWriter xmlWriter, object value);
XmlAtomContent Deserialize(XmlReader xmlReader);
}Deserializeメソッドが XmlAtomContent の値を返しています。XmlAtomContentの定義はどうなっているでしょうか。次のコードを見てください。
public class XmlAtomContent : IXmlWritableXmlAtomContentクラスはIXmlWritableを実行しています。何ということでしょう。
私は 常に この種のミスに目を光らせていますが、このミスだけが私の監視の目をかいくぐってしまったようです。
F#(またはOCaml)ではこの種のミスはコンパイルエラーを起こします。
F#ではandキーワードやrecキーワードを使用する モジュール内に 小規模の循環を入れることができますが、偶発的な循環は絶対に起こりません。限定的にでも循環を可能にするためには、前述のキーワードを的確に用いる必要があります。モジュールまたはライブラリ間を行き来する循環は定義できません。
これは相互依存されたコードを回避できる素晴らしい防御システムですね。(安易に)循環依存を入れられる機能は排除して、より良い言語を手に入れましょう。

訳注:実行可能な命令群,循環を許可しない言語,有効なプログラム
これは実地で証明済みです。「 Scott WlaschinがC#とF#のプロジェクトで循環を検証した 」という記事では、F#のプロジェクトはC#のプロジェクトに比べて、より少量かつ小規模の循環しかないことが分かったと書かれています。この分析は後に Evelina Gabasovaによって精度が高められ、裏付けも取られています 。
まとめ
この記事では、現存する言語から特定の機能を排除すると、より良い言語が構築できることを例を挙げて説明しました。不必要な機能は潔く切り捨てましょう。それでも(ほぼ)何でもできるチューリング完全で、自ら墓穴を掘る可能性は断然少ない言語はあるのです。
完璧なプログラミング言語は以下の項目を含まないものだと考えます。
- goto文
- 例外
- ポインタ
- 数値
- ヌルポインタ
- 変換
- 参照の等価性
- 継承
- インターフェース
- リフレクション
- 循環依存
不必要だと思われる機能は全部網羅したと思います。まだありますか? 今なら言語設計者にとってより良い言語を定義できる絶好のチャンスです。排除できる機能がまだないか探してみましょう。
2015年05月21日: 翻訳フィードバックをいただき一部翻訳を修正しました

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事