2016年4月6日
画像処理入門講座 : OpenCVとPythonで始める画像処理

本記事は、原著者の許諾のもとに翻訳・掲載しております。
この記事を書くに至ったきっかけ
Recruse Centerでは、私は、画像処理の勉強に時間を費やしていました。独学をし始めた頃は、何をするものなのか全く理解しておらず、ただ、文字や輪郭、模様などを識別するのに役立ち、これらで面白いことができる、ということくらいの知識しかありませんでした。
私の情報源は、主にWikipediaや書籍、公開されている大学の講義ノートです。これらの資料に慣れ親しんでくるにつれ、画像処理の世界における基礎を伝えられる「入門向け画像処理」を望むようになりました。
これが、この記事を書こうと思ったきっかけです。
前提条件
この記事は、Pythonが扱えるということを前提に書いています。その他の事前知識は必要ありませんが、NumPyや行列計算に慣れていると理解しやすいでしょう。
初めに
使用するのは、Python版OpenCV、Python 2.7 ^(1) 、iPython Notebookです。MacOSでOpenCVをセットアップする方法は、 こちら を参照してください。
ここで使用した全てのコードや画像は、GitHub上に 実行可能なiPython notebook として掲載してあります。また、 iPython notebookオンライン でも確認することができます。
画像処理を学ぶ際は、画像をインラインで表示することができる、iPython notebookの環境下で行うことを強くお勧めます。そうすることで、コードが実際に何をしているのかのフィードバックを簡単に得ることができるのです。
画像処理とは?
画像処理とは、特定の効果(例えば、グレースケール画像)をもたらすために画像を加工したり、操作したりすることです。また、コンピュータを使って、画像から情報を取り出したりすること(画像内にある円を数えるといったようなこと)も、画像処理です。
画像処理は、コンピュータビジョンとも深く関係しており、これらの境界線はとても曖昧です。しかし、深刻に考える必要はありません。私たちがここで学ぼうとしているのは、画像を加工する方法や、これらの方法を使って、いかに画像情報を集めることができるかということです。
この記事では、画像処理の簡単な構成要素について話していきながら、いくつかのコードや、基本的な操作手順を紹介していきます。コードは全てPythonで書かれており、強力な画像処理・コンピュータビジョンのライブラリである、 OpenCV を使っていきます。
構成要素
まずは、インポートから行います。ここでは、 cv2 、 numpy 、そして(主に簡単に画像を表示するために)少しだけ matplotlib を使用します。
import cv2, matplotlib
import numpy as np
import matplotlib.pyplot as plt画像フォーマット
では、始めていきましょう! 最初に、現在表示されている画像のフォーマットを知るために、画像を読み込む必要があります。
OpenCVでは、画像は3次元のNumPy配列で表されています。1つ1つの画像は、ピクセルの行列で構成されており、各ピクセルはその色を表す値の配列によって表現されています。
この画像の場合の配列は、以下のようになります。
# read an image
img = cv2.imread('images/noguchi02.jpg')
# show image format (basically a 3-d array of pixel color info, in BGR format)
print(img)結果:
[
[[72 99 143] [76 103 147] [78 106 147] ..., [159 186 207] [160 187 213] [157 187 212]]
[[74 101 145] [77 104 148] [77 105 146] ..., [160 187 208] [158 186 210] [153 183 208]]
[[76 103 147] [77 104 148] [76 104 145] ..., [157 181 203] [160 188 212] [158 186 210]]
...,
[[39 78 130] [39 78 130] [40 79 131] ..., [193 210 223] [195 212 225] [197 214 227]]
[[32 71 123] [32 71 123] [32 71 123] ..., [198 215 228] [200 217 230] [200 217 230]]
[[39 78 130] [39 78 130] [39 78 130] ..., [199 216 229] [200 217 230] [201 218 231]]
] [72 99 143] といった数値は、それぞれ1つのピクセルにおける青、緑、赤(BGR)の3色の値を表しています。ちなみに、OpenCVでは、画像はBGRフォーマットで読み込まれる初期設定となっていますが、Matplotlibの場合はRGBで読み込まれます。Matplotlibで画像を表示させるために、BGRフォーマットをRGBに変換しなくてはなりません。Matplotlibに画像を渡す前にこの処理をしないとどうなるかは、ご自身で考えてみてください。
# convert image to RGB color for matplotlib
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# show image with matplotlib
plt.imshow(img)
色
ちょっと、待ってください。この問題に、なぜBGRとRGBが関係してくるのでしょう?
赤、緑、青(RGB)
デジタルの世界では、色は、 RBGカラーモデル を使って表現されるのが一般的です。このカラーモデルに従って、赤や緑、青の光が様々な形で合わさることで、可視スペクトル上に幅広い色を表現するのです。各色はチャンネルと呼ばれており、ペンキの色を混ぜて出来る色とは少し異なります。以下がRGBカラーモデルでの発色です。
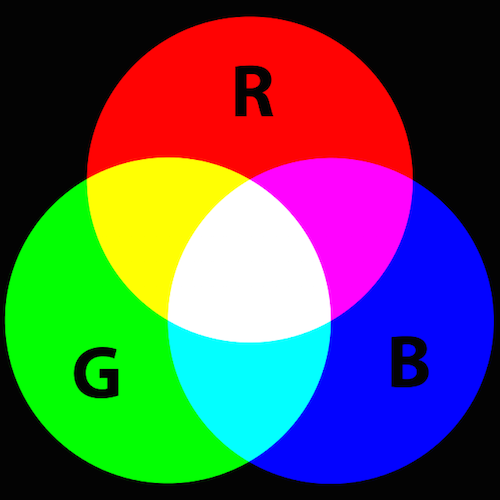
Wikipediaから引用 ^(2)
- 赤 + 緑 = 黄
- 青 + 緑 = 青緑(シアン)
- 赤 + 青 = 赤紫(マゼンタ)
- 赤 + 青 + 緑 = 白
細かい説明はこれくらいにしておきます。色の合成についての詳しい説明は、 Wikipediaの当該部分 をご覧ください。
ほとんどのシステムでは、RGB値は0から255の領域で表現されるようになっています。数値が高ければ高いほど、その色チャンネルの明度は高くなります。例えば、 [255, 51, 0] は赤みがかった色だと推測することができます。なぜなら、Rチャンネルの数値が最高値だからです。また [51, 102, 0] が、緑がかった色と推測できるのは、Gチャンネルの数値が最高値だからです。
色相、彩度、明度(HSV)
RGBの他に役立つカラーモデルが、 HSVカラーモデル です。赤や緑、青の色度で色を表現する代わりに、 色相 (虹色のカラーチャートのどの領域に位置するか)、 彩度 (色の「鮮やかさ」)、そして 明度 (明るさとも言い、どの程度の光が取り入れられているか)で表現されます。
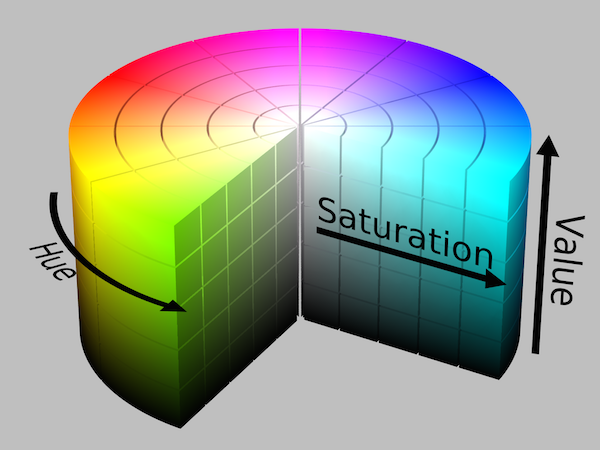
Wikipediaから引用 ^(3)
HSVカラーモデルは、いずれかの色チャンネルの1つで、画像の色を考える際に役立ちます。例えば画像の中で、青い色相の領域に同調する部分を探すのに適しています。
HSVの変化形がHSLカラーモデルで、色相、彩度、輝度から成り立っています。HSVによく似ていますが、彩度と3つ目のチャンネル(明度 対 輝度)の定義が異なります ^(4) 。
グレースケール
グレースケール画像についても話していきましょう。最も暗い色(黒)を表す0、最も明るい色(白)を表す255といった、ピクセルの明るさを表現する256階調のスケールで、1つの色チャンネルしか持っていないのが、グレースケール画像です。
画像をグレースケールに変換すると、以下のような2次元の配列になります。
# convert image to grayscale
gray_img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
# grayscale image represented as a 2-d array
print(gray_img)結果:
[[109 113 115 ..., 189 192 191]
[111 114 114 ..., 190 190 187]
[113 114 113 ..., 185 192 190]
...,
[ 89 89 90 ..., 212 214 216]
[ 82 82 82 ..., 217 219 219]
[ 89 89 89 ..., 218 219 220]]階調を変更することで、どのように色が変化するのか、 カラーピッカー を使って遊んでみるとよいでしょう。特に、HSVチャンネルの1つを変更した時のRGB値の変化を見るのは、面白いと思います。
演習:
ここで学んだことから、画像の平均色を割り出すことができます! 赤、緑、青の各チャンネルの平均値を割り出せば、ピクセルの色の平均値であるRGB値が求められます。では、 np.average() を使ってこのRGB値を割り出した例を見ていきましょう。
# find average per row, assuming image is already in the RGB format.
# np.average() takes in an axis argument which finds the average across that axis.
average_color_per_row = np.average(img, axis=0)
# find average across average per row
average_color = np.average(average_color_per_row, axis=0)
# convert back to uint8
average_color = np.uint8(average_color)
print(average_color)結果:
[179 146 123]Matpotlbに色を表示するために、このRGB値が追加された100 x 100ピクセルの小さな画像を作成する必要があります。
# create 100 x 100 pixel image with average color value
average_color_img = np.array([[average_color]*100]*100, np.uint8)
plt.imshow(average_color_img)画像の平均色は何色でしょう?
セグメンテーション
画像情報を集める際、まず、興味のある特徴ごとに分割する必要があります。これを セグメンテーション と呼びます。画像セグメンテーションは、分析を容易にすることを目的に、意味を持たせるために画像を部分ごとに表示する処理のことです ^(2) 。
閾値処理
画像セグメンテーションの一番簡単な方法は、 閾値処理 です。閾値処理の基本的な考え方は、ピクセルのチャンネル値がある閾値を超えた場合は、画像の各ピクセルを白いピクセルに、超えなかった場合は、黒いピクセルに置き換えるという考えです。通常は、画像を 2値画像、 つまりシングルチャンネル画像に変換します。グレースケール画像は、シングルチャンネル画像の一例です。
# threshold for image, with threshold 60
_, threshold_img = cv2.threshold(gray_img, 60, 255, cv2.THRESH_BINARY)
# show image
threshold_img = cv2.cvtColor(threshold_img, cv2.COLOR_GRAY2RGB)
plt.imshow(threshold_img)結果:
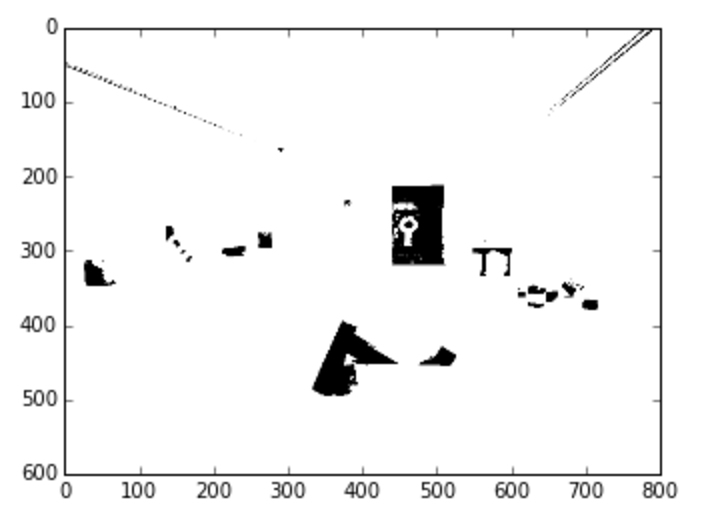
こうすると、明度の異なる部分を選ぶのが簡単になります。また、グレースケールではない画像にも利用できます。更に、色チャンネルを使って画像をセグメント分けすることも可能です。色の閾値処理はHSVで最も効果的です。HSVの色相チャンネルについて先ほど説明しましたが、赤から緑、緑から青、青から赤紫と移っていくスケールのどこにピクセルの色はあるのでしょうか?
閾値より低い値を探さなくても、 cv2.inRange() を使えば、一定の色相の領域内に納まる部分を画像から見つけることができます。
# open new Mondrian Piet painting photo
piet = cv2.imread('images/piet.png')
piet_hsv = cv2.cvtColor(piet, cv2.COLOR_BGR2HSV)
# threshold for hue channel in blue range
blue_min = np.array([100, 100, 100], np.uint8)
blue_max = np.array([140, 255, 255], np.uint8)
threshold_blue_img = cv2.inRange(piet_hsv, blue_min, blue_max)
threshold_blue_img = cv2.cvtColor(threshold_blue_img, cv2.COLOR_GRAY2RGB)
plt.imshow(threshold_blue_img)結果:
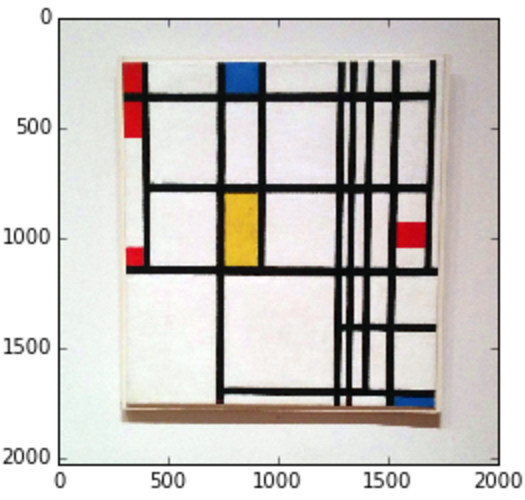
元の画像
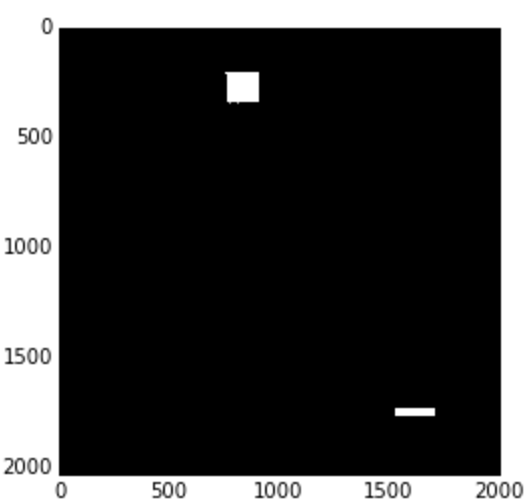
青い色相の閾値処理
演習: どうやったら、この絵から赤、または黄の部分を取り出せるでしょうか。また、もし色の全色相を0から255で表すことができるとしたら、赤、または黄にどの範囲を使えばいいでしょうか。
2値化閾値を使ったマスキング
色を区別できるようになったので、面白いことができます。例えば2値画像をマスクとして使ってみましょう。マスクとは、ビット演算で使われるゼロとゼロ以外の値の行列のことです。マスクを使うと、画像を切ったり、画像のある部分を”マスク”で隠したりできます。マスクは通常、ゼロの行列(消したい部分)と、ゼロ以外の行列(残したい部分)です。
それでは、屋外で撮った景色の画像から空を消したバージョンが欲しいとしましょう。その場合は、最初に、青い色相の領域に含まれるピクセルを見つけます。そうすると、1枚の画像の中から青い空の部分を区別できるようになるのです。空以外の部分の画像を取り出すには、 bitwise_not を使って値が逆になるようにします。そうすると青以外の部分を残すマスクができます。マスク上で bitwise_and を使うと、画像の青以外の部分だけが残ります。
upstate = cv2.imread('images/upstate-ny.jpg')
upstate_hsv = cv2.cvtColor(upstate, cv2.COLOR_BGR2HSV)
plt.imshow(cv2.cvtColor(upstate_hsv, cv2.COLOR_HSV2RGB))
# get mask of pixels that are in blue range
mask_inverse = cv2.inRange(upstate_hsv, blue_min, blue_max)
# inverse mask to get parts that are not blue
mask = cv2.bitwise_not(mask_inverse)
plt.imshow(cv2.cvtColor(mask, cv2.COLOR_GRAY2RGB))
# convert single channel mask back into 3 channels
mask_rgb = cv2.cvtColor(mask, cv2.COLOR_GRAY2RGB)
# perform bitwise and on mask to obtain cut-out image that is not blue
masked_upstate = cv2.bitwise_and(upstate, mask_rgb)
# replace the cut-out parts with white
masked_replace_white = cv2.addWeighted(masked_upstate, 1, \
cv2.cvtColor(mask_inverse, cv2.COLOR_GRAY2RGB), 1, 0)
plt.imshow(cv2.cvtColor(masked_replace_white, cv2.COLOR_BGR2RGB))結果:
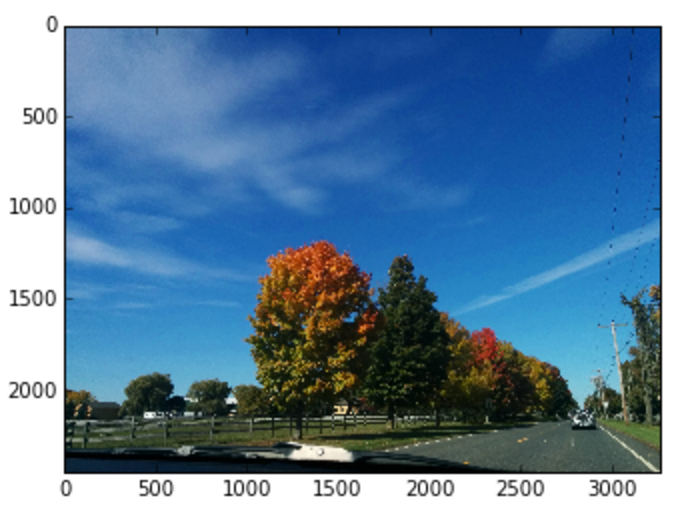
元の画像
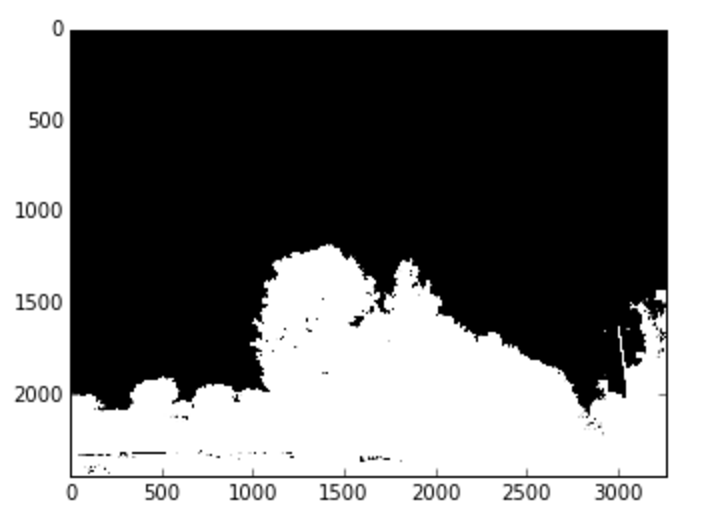
閾値を適用(マスク)
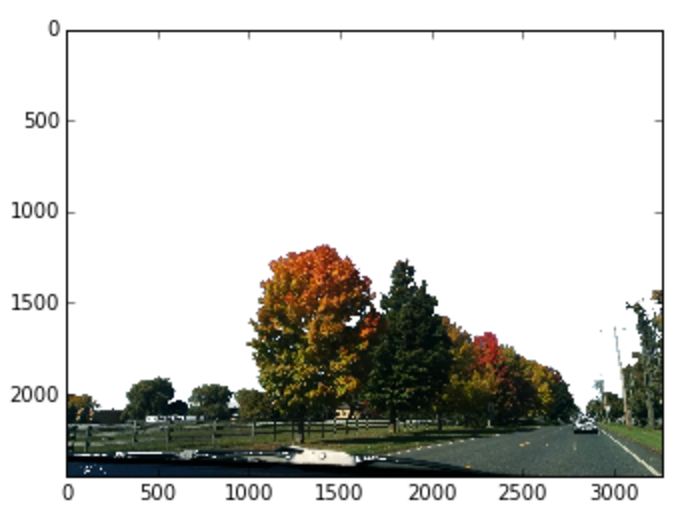
マスクを適用した画像
参考資料
- 異なるタイプのさらに強力な閾値処理についての情報や、その働きについては、 OpenCV3ドキュメンテーション をご覧ください。
ぼかし
写真にノイズが多い場合があります。どういう意味かというと、セグメント分けの邪魔になる、小さい変則的な要素が画像に含まれている場合があるということです。この小さいノイズを取り除くためには、 ガウスぼかし を使って画像の前処理をする方法がよく使われます。ぼかしは、明度差の大きい場合や、ピクセル間で激しい変化がある場合に、それらをスムーズにするものだと思ってください。
ガウスぼかしは、画像内の各ピクセルを変換することで効果を出します。これは、画像を正方形(n×n)の カーネル で 畳み込む ことで行われます。畳み込みは、周りにあるn×nのピクセルの値に応じて、あるピクセルに操作を適用することだと思ってください。操作はカーネルによって決められます。つまり、5×5のカーネルでガウスぼかしを適用すると、全てのピクセルに対し周りの5×5のピクセルが考慮され、平均値を出す計算が行われます。そうして、新しくぼかされた色がピクセルに与えられるのです。ガウシアンカーネルサイズが大きいほど、画像のぼかしは強くなります。
img = cv2.imread('images/oy.jpg')
# gaussian blurring with a 5x5 kernel
img_blur_small = cv2.GaussianBlur(img, (5,5), 0)
元の画像(600px×450px)

5×5のカーネルでぼかしを適用

15×15のカーネルでぼかしを適用
ガウスぼかしは、画像にノイズが多く、閾値を適用する前に全ての変則的な要素をスムーズにしたい場合、特に有効です。
結果:

元の画像に閾値を適用

5×5のカーネルでぼかした画像に閾値を適用
上は、ぼかしていない画像に閾値を適用した場合と、5×5のカーネルでぼかした画像に閾値を適用した場合を比較した例です。ぼかした方が、閾値の適用される塊のラインが明確になり、使いやすくなります。
参考資料
輪郭と外接矩形
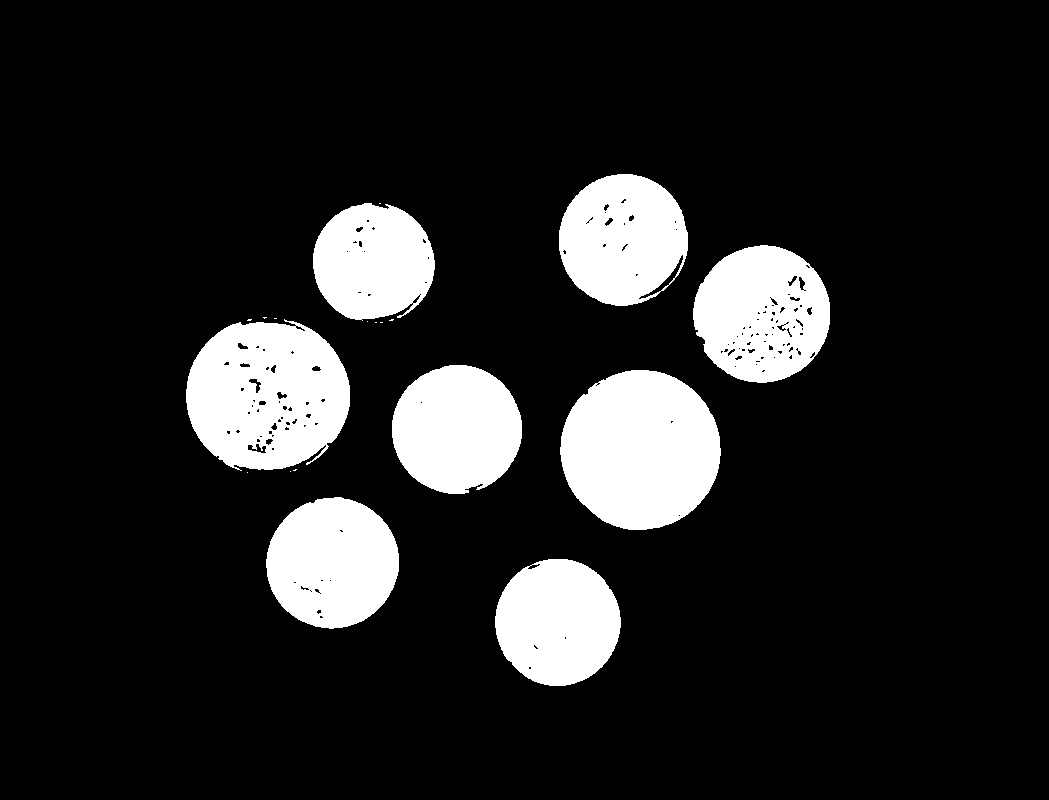
単純化して2値化したバージョンの画像を作れるようになったので、関心のある特徴だけを区別することができます。例えば、下の画像から個々のコインを区別するにはどうしたらいいでしょうか。
このセクションでは、特徴でセグメント分けするために、 輪郭 と 外接矩形 を使う方法を説明します。

元の画像
画像の前処理
最初に、画像をグレースケールに変換し、そこにガウスぼかしを適用して単純化とノイズの除去を行います。これは前処理の一般的な形式で、画像を扱う際は、大抵の場合、これを最初に行います。
それから、前処理を行った画像に2値化閾値処理を適用します。コインが明るい場所に置かれているため、閾値は明るい背景部分を関心のある特徴として取り出します。ですから、コインを取り出すために2値画像を反転させます。
# get binary image and apply Gaussian blur
coins = cv2.imread('images/coins.jpg')
coins_gray = cv2.cvtColor(coins, cv2.COLOR_BGR2GRAY)
coins_preprocessed = cv2.GaussianBlur(coins_gray, (5, 5), 0)
# get binary image
_, coins_binary = cv2.threshold(coins_preprocessed, 130, 255, cv2.THRESH_BINARY)
# invert image to get coins
coins_binary = cv2.bitwise_not(coins_binary)結果:
前処理を行った2値画像
輪郭の検出
輪郭とは、境界線上で同じ色や明度を持つ全ての連続する点をつないだ曲線のことです。これは、形状の分析 ^(3) だけでなく、物体や特徴の検出をする際にも便利です。 cv2.findContours() を使うと、それぞれのコインの輪郭を検出できます。これを cv2.RETR_EXTERNAL フラグの中で関数に渡すと、外郭だけが返されます。つまり、コイン表面の細かいディテールの輪郭までは取り出しません。
この外郭によって、それぞれのエリアを検出できるので、コインより小さなものをフィルタで取り除くことができます。実際に撮影される写真が完璧ということは、なかなかありません。ですから、ノイズや異物を取り除くために、このようなチェックが必要となることがよくあります。輪郭エリアを得るためには、 cv2.contourArea() を使います。
# find contours
coins_contours, _ = cv2.findContours(coins_binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# make copy of image
coins_and_contours = np.copy(coins)
# find contours of large enough area
min_coin_area = 60
large_contours = [cnt for cnt in coins_contours if cv2.contourArea(cnt) > min_coin_area]
# draw contours
cv2.drawContours(coins_and_contours, large_contours, -1, (255,0,0))
# print number of contours
print('number of coins: %d' % len(large_contours)) number of coins: 8
結果:

2値画像から得られたコインの輪郭
外接矩形の検出
外接矩形とは、輪郭を含むことができる最も小さな長方形のことです。画像から個々のコインをセグメント分けするのに使うことができます。 cv2.boundingRect() メソッドでは、長方形の左上の角のx座標とy座標、及びに幅と高さの値を外接矩形として返すことを覚えておいてください。また、8枚のコインを個別に取り出すために、外接矩形を使うこともできます。
# create copy of image to draw bounding boxes
bounding_img = np.copy(coins)
# for each contour find bounding box and draw rectangle
for contour in large_contours:
x, y, w, h = cv2.boundingRect(contour)
cv2.rectangle(bounding_img, (x, y), (x + w, y + h), (0, 255, 0), 3)結果:

輪郭の外接ボックス
参考資料
エッジ検出
私たちが行った閾値による2値化のように、色や明度によるセグメンテーションでは十分ではない場合があります。多色使いの物体をセグメンテーションする必要がある場合はどうすればよいでしょうか。不均一な照明の下にある、青と黄のストライプのボウルについて考えてみましょう。ちなみに、その色は全体的に均一ではありません。
このような画像に使えるのが 境界 を見つけ出す方法である エッジ検出 です。エッジは画像において輝度や明度が変化している部分の、点の集まりであると定義されます。通常これは、異なる物体間の境界を意味します。エッジ検出は画像処理の基本的な要素であり、特徴検出や特徴処理をする際に、まずここから始めることがよくあります ^(5) 。
エッジ検出にはちょっとした計算が必要ですが、そこにはあまり触れないでおきましょう。エッジ検出の背景にある基本的な考え方は、画像内の輝度の変化は測定可能であるということです。この変化を 勾配 と言います。勾配の 大きさ (変化がどのくらい急激に起きているか)と 方向 を測定することができます。点が集まっている箇所の、変化の大きさが所定の閾値を超えた場合、それが境界であると考えられます。
キャニー法のアルゴリズム は一般的なエッジ検出アルゴリズムであり、正確で鮮明なエッジを検出できます。以下のサンプルは、キャニー法のOpenCVの実装例で、同じ画像を閾値で2値化した画像と比較したものです。不均一な照明の下にある画像であるため、単純な閾値処理でボウルとカップの両方を捉えることはできないことに留意してください。

元の画像
閾値処理による2値化
標準的な技法として、画像を閾値処理する前にグレースケールとガウスぼかしで処理します。画像上部のティーカップを単純な閾値処理では捉えられないことに留意してください。ティーカップを捉えられるように閾値を調整して高い値にしたとしても、ボウルを捉えられなくなってしまいます。
cups = cv2.imread('images/cups.jpg')
# preprocess by blurring and grayscale
cups_preprocessed = cv2.cvtColor(cv2.GaussianBlur(cups, (7,7), 0), cv2.COLOR_BGR2GRAY)
# find binary image with thresholding
_, cups_thresh = cv2.threshold(cups_preprocessed, 80, 255, cv2.THRESH_BINARY)
plt.imshow(cv2.cvtColor(cups_thresh, cv2.COLOR_GRAY2RGB))結果:

閾値を80に設定した2値画像。ティーカップを捉えられない。

閾値を200に設定した2値画像。ティーカップは捉えられるが、ボウルを捉えられない。
キャニー法
閾値処理ではなく、キャニー法で処理してみましょう。 cv2.Canny() 関数が2つの閾値をとることに留意してください。このアルゴリズムは、 二重の閾値 と呼ばれるものです。勾配の大きさが threshold2 よりも大きい場合は、強い境界と判断されます。 threshold2 よりも小さく threshold1 よりも大きい場合も、他の強い境界に接していれば、弱い境界であっても境界と考えられます。
# find binary image with edges
cups_edges = cv2.Canny(cups_preprocessed, threshold1=90, threshold2=110)
plt.imshow(cv2.cvtColor(cups_edges, cv2.COLOR_GRAY2RGB))
cv2.imwrite('cups-edges.jpg', cups_edges)結果:

キャニー法
キャニー法を使うと、単純な閾値処理では検出できないような画像の特徴を抽出する際に、より良い結果が得られます。
境界は非常に鮮明であり、面白い効果を生んでいますが、これによってどんなことができるでしょうか。
線検出と輪郭検出
対象となる物体が線や円などの標準的な形態であれば、ハフ変換を利用して検出できます。
直線検出
直線を検出するハフ変換 は、複数の点を通る、直線の可能性のある線の候補を挙げることによって処理を行います。各線は r と theta の極座標の観点から、 r = x * cos (theta) + y * sin (theta) と定義されます。もし直線の可能性があるものが、他にも十分な数の点を通っていれば、それは直線だと考えられます。
以下に、直線を検出するハフ変換の実例を挙げます。
# copy of image to draw lines
cups_lines = np.copy(cups)
# find hough lines
num_pix_threshold = 110 # minimum number of pixels that must be on a line
lines = cv2.HoughLines(cups_edges, 1, np.pi/180, num_pix_threshold)
for rho, theta in lines[0]:
# convert line equation into start and end points of line
a = np.cos(theta)
b = np.sin(theta)
x0 = a * rho
y0 = b * rho
x1 = int(x0 + 1000*(-b))
y1 = int(y0 + 1000*(a))
x2 = int(x0 - 1000*(-b))
y2 = int(y0 - 1000*(a))
cv2.line(cups_lines, (x1,y1), (x2,y2), (0,0,255), 1)結果:
エッジ

エッジから直線が検出される。
円検出
円を検出するハフ変換 でも同じような処理を行います。ただし、 ( x - a ) ^ 2 + ( y - b ) ^ 2 = r ^ 2 で定義される円の候補の要素となる a 、 b 、 r の全ての値を求めます。検索範囲が非常に広いので、範囲を限定するために理想的な境界を設定する必要があります(例えば、最小または最大の半径値を設定します)。
以下に円を検出するハフ変換の実例を挙げます。
# find hough circles
circles = cv2.HoughCircles(cups_edges, cv2.cv.CV_HOUGH_GRADIENT, dp=1.5, minDist=50, minRadius=20, maxRadius=130)
cups_circles = np.copy(cups)
# if circles are detected, draw them
if circles is not None and len(circles) > 0:
# note: cv2.HoughCircles returns circles nested in an array.
# the OpenCV documentation does not explain this return value format
circles = circles[0]
for (x, y, r) in circles:
x, y, r = int(x), int(y), int(r)
cv2.circle(cups_circles, (x, y), r, (255, 255, 0), 4)
plt.imshow(cv2.cvtColor(cups_circles, cv2.COLOR_BGR2RGB))
print('number of circles detected: %d' % len(circles[0]))
number of circles detected: 3結果:
エッジ

エッジから検出された円
ボウルから検出された円が1つだけであることに留意してください。これは円と円の距離 minDist を最短に指定したからです。この距離は最低でも50ピクセル必要です。
参考資料
- ハフ変換が OpenCVのドキュメンテーション で説明されており、デモンストレーションが見られます。
次は?
実に素晴らしいですね。これで基本が分かったと思います。自分の画像処理のプロジェクトを考え始める上で、絶好のスタート地点に立てたのではないかと思います。まだプロジェクトを考えていないとしても、多様なパラメータを使って様々なOpenCVの機能を試してみるだけで、もっと使い方に慣れることができます。
こうした機能の処理について、より深く掘り下げたい方は(例えば、エッジ検出の実際の仕組みなど)、自分が選んだ言語で実装することで多くのことが学べます。例えば私は、 JavaScriptインプリメンテーション を使ってみるまで、エッジ検出について十分に理解していませんでした。どうか数学を怖がらないでください。疑似コードを読めば大抵の場合、アルゴリズムの背景にある理論をよく理解できるでしょう。
参考資料
-
HIPR2 画像処理の学習のためのリソース集 は、様々なアルゴリズムの入門となる内容であるとともに、その処理について説明しています。
-
画像処理の概念に関する Wikipedia には、理解しやすい疑似コードが掲載されていることがよくあります。実際にどのように処理が行われるのか、背景にある数学的な考え方とともに詳細に説明されています。役に立つと思われるものについて、投稿の中でいくつかリンクを貼っていますが、他にもたくさんあります。
-
Samarth Brahmbhatt著『Practical OpenCV』 には、OpenCVによる画像処理への異なるアプローチの例が記載されています。
-
OpenCVとPythonを使った自動カードゲーム は、カード検出のような処理にOpenCVをどのように利用するかを説明しており、内容が上手に要約されています。
謝辞
Recurse CenterのファシリテーターであるJohn Workmanに感謝します。彼のおかげで画像処理について興味を持つようになりました。また、 Set Solver では画像処理に関する多くの技術を学びましたが、そこで一緒に仕事をしたJesse GonzalezとMiriam Shiffmanに感謝します。
投稿で使用した写真は、但し書きがあるものを除いて私が所有するものです。
Sher Minn Chong は、昼はフロントエンドを手掛けるWebデザイナーで、夜は画像処理とPythonに熱心に取り組んでいます。 Recurse Center の2015年秋の第1期に参加しました。
編集: Timnit Gebru
-
Python3のOpenCVのサポートは、この投稿を執筆している時点ではまだベータ版です。 ↩
-
定義は 画像のセグメンテーション についてのWikipediaを参照しました。 ↩ ↩
-
定義は輪郭についての OpenCVドキュメンテーション を参照しました。 ↩ ↩
-
HSLカラーモデルとHSVカラーモデル に関するWikipediaの記事では、HSVとHSLの違いを説明しています。 ↩

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事