2014年7月17日
機械学習とは何か? – 機械学習の定義と使える言い回し
(2013-11-17)by Jason Brownlee
本記事は、原著者の許諾のもとに翻訳・掲載して�おります。
この記事で、取り上げたいのは 「機械学習って何?」 ということです。
機械学習に興味がある人なら、少しはその内容について、かじったことがあるでしょう。ですが友人や同僚に機械学習の話をふると、誰かに「機械学習って何?」と質問されるリスクがあることを覚えておいてください。
この記事の目指すところは、機械学習について考えるための定義、それも覚えやすい気の利いた言い回しをいくつか提案することです。
まずは、この分野で信頼のおける教本から機械学習のスタンダードな定義について触れるところから始めましょう。それから機械学習についてのプログラマ的な定義をはっきりさせ、最終的には、「機械学習って何?」と聞かれても、いつでも答えられるようになるのが目標です。
信頼できる定義
それでは最初に、一般的に大学の講義レベルで、よく使われている機械学習の教本4冊から見ていきましょう。信頼できる定義であり、この問題を熟考するための基礎となります。分かりやすくかつ変化に富んだ観点が際立っているものを選びました。終わりまで読めば、いかに雑多なメソッドがあることに気づき、同時にどの観点を選ぶかが、答えに近づく鍵となっているかが分かるでしょう。
ミッチェルの機械学習
トム・ミッチェルは著書 『Machine Learning』 (原著者アフィリエイトリンク)の冒頭で次のように書いています。
機械学習の分野では、コンピュータプログラムが経験によって自動的に改善していくにはどうしたらいいかというテーマを掲げています。
私はこの端的でステキな定義を気に入っています。プログラマ的な定義こそが、私たちがこの記事の最後にたどり着きたい答えなのです。”コンピュータプログラム”と”自動的な改善”という表現に注目してください。「自ら改善していくプログラムを書く」とは、何て興味をそそられることでしょう!
彼は序文で形式主義的な見解を書いています。この見解はこの後、何度も登場します。
コンピュータプログラムはタスクTとパフォーマンス測定Pに関連する経験Eから学習すると言われています。タスクTでパフォーマンスをした場合、パフォーマンス測定Pによって達成度が測定され、経験Eによって改善されていきます。
尻込みは厳禁ですよ。これはとても役に立つ形式です。この形式をテンプレートとして用い、E、T、Pをテーブル内の列の最上位に置きます。そしてより厳格に、複雑な問題を扱うことなく、リスト化することができます。
デザインツールとして利用することで、どのデータを集め(E)、ソフトウェアはどんな決定をする必要があるか(T)、どう結果を評価するか(P)を、明確に考える助けになります。この働きこそが、基礎となる定義として何度も登場する理由です。覚えておいてください。
統計的学習の要素
『統計的学習の基礎 ―データマイニング・推論・予測―』 (原著者アフィリエイトリンク)はスタンフォードの統計学者3人の共著です。
統計学の分野を構造化するための統計学的なフレームワークとして定義が書かれていて、序文には、こうあります。
膨大な量のデータが多くの分野で生成されているが、統計学者は、いかにこのデータに意味を持たせるかを生業としている。重要なパターンや傾向を抽出し、”このデータは何を言わんとしているのか”を解析することが目的である。我々は、これをデータからの学習と呼んでいる。
統計学者の領域では、統計学的ツールを用い、ドメインのコンテキストにおけるデータを解明するということは分かっています。この研究者たちは、機械学習を網羅した分野における研究の補助メソッドとして機械学習を捉えているようです。興味深いのは、彼らが本の副題に”データマイニング”をつけたことです。
統計学者はデータから事実を突きとめていきますが、ソフトウェアも同じように、ソフトウェアが学習したことから学んでいきます。すなわち、さまざまな機械学習によって実行された決定と結果からです。
パターン認識
ビショップは彼の著書 『パターン認識と機械学習』 (原著者アフィリエイトリンク)で、こうコメントしています。
パターン認識はエンジニアリングに起源を持ち、機械学習はコンピュータサイエンスの領域で発達してきましたが、同じ分野の2つの側面ともみなせるのです…
これを読めば、ビショップは、まずエンジニアリングの観点から、この分野にたどりつき、同じメソッドを持つコンピュータサイエンスを学び、活用したという印象を受けるはずです。これは、なかなか賢いやり方であり、私たちも見習うべきメソッドです。さらに広い意味でいえば、メソッドの権限を主張する分野に関わらず、”データからの学習”による洞察や結果に近づくことで、私たちの求めるものに一致するならば、機械学習と呼ぶことができるのです。
アルゴリズム的観点
マースランドは、自身の著書 『Machine Learning: An Algorithmic Perspective』 (原著者アフィリエイトリンク)で、機械学習に関するミッチェルの定義を採用しています。前書きで、その本を書いた動機について説得力のある理由を述べています。
機械学習の最も面白い特徴の1つは、主にコンピュータサイエンスや統計学、数学、エンジニアリングといったさまざまな学問分野の境界線上にあるということです。…機械学習は通常、人工知能の一部として研究され、コンピュータサイエンスにしっかりと分類されています。…これらのアルゴリズムがなぜ機能するのかを理解するには、統計的で数学的な洗練さがある程度必要です。コンピュータサイエンスの学部生にはよくそれが欠けています。
この文章は洞察に満ちていて、ためになりますね。まず、マースランドはこの分野の学際的な性質を強調しています。上記の定義からそのことを感じていましたが、彼は私たちのために特に強調してくれています。機械学習は、ありとあらゆる情報科学から引き出します。次に、既定の観点に固執しすぎる危険性を強調しています。特に、メソッドの数学的な内部構造を避けるアルゴリズミストの場合です。恐らく、実装と展開の実際的な懸念を避ける統計学者とは逆のケースで、同じくらい限定的です。
ベン図
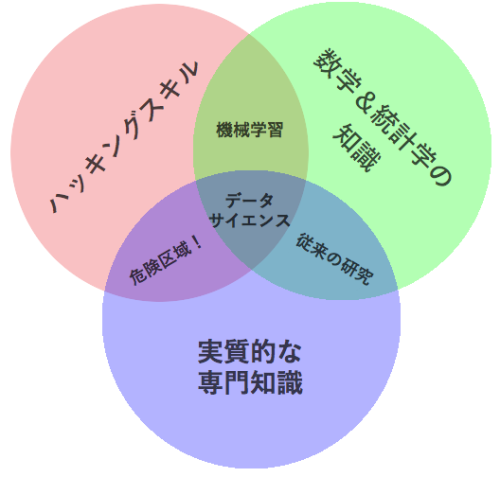
ドルー・コンウェイは、2010年9月に、役に立ちそうな すばらしいベン図を作成しました 。彼は説明の中で、機械学習は「 ハッキング 」+「 数学&統計学 」だと述べています。
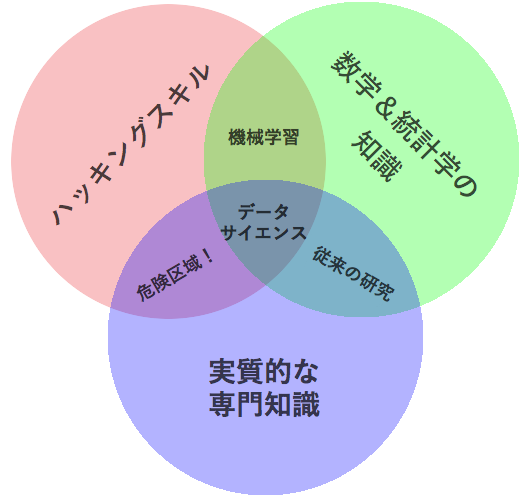
ドルー・コンウェイによるデータサイエンス・ベン図(翻訳)
クリエイティブ・コモンズ・ライセンス”表示—非営利”の下で公開
また、「 危険区域 」を「 ハッキングスキル 」+「 専門知識 」と表現しています。ここで、彼は危険であることを十分に分かっている人々について触れています。その人々はデータにアクセスして構造化でき、ドメインを知っていて、メソッドを実行して結果を提示できますが、その結果が何を意味するのかを理解していません。これはマースランドが示唆していたことかもしれません。
プログラマ的な定義
私たちは現在、自分たちプログラマのためにすべてを基本的なものに分解する必要性について考えています。まず分解と手続き型ソリューションを妨げる複雑な問題に目を向けています。これは機械学習の力を形づくっています。それから、他のプログラマから「 機械学習って何? 」と聞かれた時にいつも使えるように、私たちプログラマが納得できる定義を考え出しています。
複雑な問題
いつかはプログラマとして、論理的な手続き型ソリューションに頑固に抵抗するような問題と遭遇するでしょう。私が言いたいのは、実行できなかったり、座って解決に必要なif文をすべて書き出しても費用対効果の高くなかったりするような問題があるということです。
「 冒とくだ! 」と、皆さんのプログラマ脳が叫ぶのが聞こえます。
確かにそうです。スパムメールとノンスパムメールを区別する決定問題のありふれた例を取り上げてみましょう。これは、機械学習を紹介する際にいつも使われる例です。メールがメールアカウントに入ってきた時にメールをフィルタにかけ、スパムフォルダに入れるか受信フォルダに入れるかを決定するプログラムを皆さんはどのように書きますか?
恐らく、サンプルをいくつか集め、そのサンプルを見て、それについて深く考えることから始めるでしょう。スパムメールとノンスパムメールのパターンを探し、今後、新たな事例が出てきてもヒューリスティックスが対応できるように、それらのパターンを取り出すことを考えます。変なメールは二度と見られないように無視するでしょう。楽に精査できるように、精度を上げて、エッジケースのために特別なものを作ります。やがて頻繁にメールを見直し、意思決定を改善するために新しいパターンを取り出すことを考えるでしょう。
コンピュータではなくプログラマによって実行されたものを除くすべての中に、機械学習アルゴリズムがあります。手動で引き出されてハードコードされたシステムの出来栄えは、データからルールを抽出してプログラムに実装するプログラマの能力によって決まるでしょう。
この方法でできるでしょうが、多くのリソースを使いますし、悪夢のようなメンテナンスに苦しめられるでしょう。
機械学習
上記の例にあるように、あなたの脳内にも徹底的に自動化を働きかけようとする部分があるはずです。プログラマ脳は、サンプルのパターンを抽出するメタプロセスを自動化・最適化しようとするチャンスをうかがっているのかもしれません。機械学習の手法こそが、そのような自動化されたプロセスなのです。
スパム/ノンスパムメールを例に挙げると、サンプル(E)は、今までに集めたメールのことを指します。タスク(T)はメールがスパムかノンスパム、どちらなのか判別して、適切なフォルダに振り分ける決定問題(分類と呼ばれる)となります。パフォーマンスの測定は、0%(最低)から100%(最高)までのパーセンテージ(適正な決定の数÷すべて含めた決定の総数×100)と同じくらい正確性があるでしょう。
このような意思決定プログラムの事前準備は一般的に”トレーニング”、集められたサンプルは”トレーニング用データセット”などと呼ばれています。プログラム自体は、メールをスパムまたはノンスパムに分類するといったモデルケースにあるように、”モデル”と言われています。プログラマが好きな言い方をすれば「モデルの状態が維持されている必要があります。トレーニングとは、一度実行され、必要に応じて再び実行されるというプロセス。分類とは、実行されたタスク」。これなら理にかなっていますね。
プログラマの立場から、先述の定義に使われている用語の中にしっくりこないものもあるかもしれません。技術的に言えば、私たちが書くプログラムはすべて処理の自動化になるので、「機械学習は自動的に学ぶ」という説明は意味がないとも言えます。
気の利いた言い回し
それではこれらの用語を使って、プログラマ的な機械学習の定義を考えてみましょう。例えば、
機械学習とは、パフォーマンスの測定に対する決定を一般化するため、データにあるモデルをトレーニングさせること。
モデルのトレーニングとはサンプルをトレーニングさせることで、モデルは経験によって得られる状態を意味します。決定の一般化はインプットを基に判断する能力であり、いずれ決定が必要になる時に、まだ見ぬインプットをあらかじめ予測することができます。最後にパフォーマンスの測定に対しては、的をしぼった要求と用意されているモデルに向けられた性質を示唆します。
私は詩人ではないので、もっと正確で簡潔な機械学習の定義を思いついた方がいたら、コメントをお寄せください。
リソース(情報源)
記事に色々なリソースのリンクを貼りましたが、特に役立ちそうなものをリストアップしたので、まだ読み足りないという方は、ぜひリストをご覧ください。
書籍
今回ご紹介した定義は、以下の書籍4冊から引用しました。どれもAmazonのアフィリエイトリンクなので、あなたが購入を決めた場合、私に何セントか支払われることになります。
- 『Machine Learning』 トム・ミッチェル(著)
- 『統計的学習の基礎 ―データマイニング・推論・予測―』 トレヴァー・ヘイスティ(著) ロバート・チブシラニ(著) ジェローム・フリードマン(著)
- 『パターン認識と機械学習 上 – ベイズ理論による統計的予測』 C. M. ビショップ(著)
- 『Machine Learning: An Algorithmic Perspective』 ステファン・マースランド(著)
また、ドルー・コンウェイとジョン・マイルズの共著書 『入門 機械学習』 も実用的で楽しめる内容となっています。
Q&Aサイト
Q&Aサイト上では、機械学習とは何なのかといった面白い議論が交わされているので、こちらもいくつかピックアップしました。
- Quora は、ハイレベルな質問にも対応しているサイトです。例えば 「機械学習を素人にも分かる言葉で説明するには?」 「データサイエンスとは?」 といった質問があるのでザッと読んでみてください。
- Cross Validated は、より専門的な質問を基にすばらしい議論が展開されています。 2つの文化:統計学 vs 機械学習 をご覧ください。この議論に使われている情報は、ブログ記事の 『統計学 vs 機械学習、いざ対決!』 とテキストの 『統計学上のモデリング:2つの文化』 です。
- Stack Overflow でも議論が行われています。 「機械学習とは?」 などチェックしてみてはどうでしょうか。
私は機械学習について思いめぐらせ、過去に読んだ本や今までの経験を反映させながら自分なりの定義を見つけました。この記事は参考になったでしょうか。
あなたの感想や機械学習の理解が深まったかどうか教えてください。あなたにとって機械学習とは? 他にも何かリソースをご存じですか? コメントをお待ちしています。
次のステップへ進む

機械学習は実に多くのアルゴリズムや問題が絡み合っていて、複雑な分野でもあります。たくさんの専門用語が飛び交っている中で、覚えておいた方がいい用語があります。
この世界に飛び込む前に、まずは現状を知っておかないといけません。
28ページにわたるPDF版ガイド: 『機械学習の基礎』 はこちらからどうぞ。
このガイドを手引に機械学習の本質や、最初に知っておくべきハイレベルな概念を発見できることでしょう。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事