2024年9月27日
React Compilerについて理解する

(2024-1-19)by Tony Alicea
本記事は、原著者の許諾のもとに翻訳・掲載しております。
Reactのコアアーキテクチャは、与えられた関数(すなわちコンポーネント)を繰り返し呼び出します。この仕組みはReactのメンタルモデルを単純化し、その人気に一役を買いましたが、同時にパフォーマンスの問題が生じる原因にもなりました。関数のパフォーマンスコストが高いと、アプリの動作は総じて遅くなります。
開発者はReactにどの関数をいつ再実行するか手動で指示しなくてはならなかったため、パフォーマンスチューニングが悩みの種になっていました。Reactチームが最近リリースしたReact Compilerというツールは、コードを書き直すことにより、開発者が手動で行っていたパフォーマンスチューニングの作業を自動化します。
React Compilerはコードに何をするのでしょうか?裏ではどのような処理が行われるのでしょうか?使った方がいいのでしょうか?こうした疑問について詳しく見ていきたいと思います。
none
Reactの内部実装について詳しく学び、完全で正確なメンタルモデルを得たい方は、Understanding Reactという筆者の新しいコースでReactのソースコードを掘り下げて説明していますので、ぜひチェックしてみてください。Reactの使用経験が豊富な開発者でも、内部実装の理解を深めることは大いに役立ちます。
コンパイラ、トランスパイラ、オプティマイザ
モダンJavaScriptのエコシステムでは、コンパイラ、トランスパイラ、オプティマイザという用語がよく聞かれます。これらは何でしょうか?
トランスパイル
トランスパイラとは、コードを解析し、同等の機能を持つコードを別のプログラミング言語で出力するか、調整を加えたコードを同じプログラミング言語で出力するプログラムです。
React開発者は何年も前からトランスパイラを使用し、JSXをJavaScriptエンジンが実際に実行するコードに変換してきました。JSXは、基本的にはネストされた関数のツリー(これらはネストされたオブジェクトツリーを構築)を作成するための省略記法です。
ネストされた関数を記述するのは面倒でミスが生じやすいため、JSXは開発者を大いに助けます。トランスパイラはJSXを解析し、関数に変換するために必要です。
例えば、JSXを使用して次のReactコードを記述したとします。
none
読みやすさに配慮し、このブログ記事ではコードはすべて大幅に簡略化しています。
function App() {
return <Item item={item} />;
}
function Item({ item }) {
return (
<ul>
<li>{ item.desc }</li>
</ul>
)
}これをトランスパイルすると、次のようになります。
function App() {
return _jsx(Item, {
item: item
});
}
function Item({ item }) {
return _jsx("ul", {
children: _jsx("li", {
children: item.desc
})
});
}こちらが実際にブラウザに送られるコードです。HTMLのような構文ではなく、Reactでは「props」と呼ばれるプレーンなJavaScriptオブジェクトを渡す、ネストされた関数です。
none
トランスパイルの結果は、JSX内でif文を簡単に使用できない理由を示しています。関数内ではif文を使用できません。
Babelを使用すればJSXを素早くトランスパイルし、出力結果を確認できます。
コンパイルと最適化
では、トランスパイラとコンパイラの違いは何でしょうか? その答えは、回答者のバックグラウンドや経験によって異なるでしょう。コンピューターサイエンス分野を歩んできた人であれば、大抵はコンパイラと言えば記述したコードを機械語(プロセッサが理解できるバイナリコード)に変換するプログラムという認識だと思います。
しかし、トランスパイラは「source-to-source compilers」とも呼ばれます。オプティマイザは「最適化コンパイラ」とも呼ばれます。つまり、トランスパイラとオプティマイザもコンパイラの一種なのです。
物事に名前を付けるのは簡単ではありません。したがって、何をもってトランスパイラ、コンパイラ、あるいはオプティマイザと呼ぶのかについては意見の相違があるでしょう。理解すべき重要な点は、トランスパイラも、コンパイラも、オプティマイザも、コードが記述されたテキストファイルを解析し、同等の機能を持つ別のコードを新しいテキストファイルに出力するプログラムだということです。コードを改良する場合もあれば、別の人が書いたコードを呼び出すコールで自分のコードの一部をラップすることで、新しい機能を追加する場合もあります。
none
トランスパイラ、コンパイラ、オプティマイザは、コードが記述されたテキストファイルを解析し、同等の機能を持つ別のコードを出力するプログラムです。
React Compilerが行うのは後者です。あなたが書いたコードと同等の機能を持つコードを作成しますが、他のReact開発者が書いたコードを呼び出すコールであなたのコードの一部をラップします。そうすることで、あなたが意図したことに加え、プラスアルファの機能を備えたコードに書き換えます。その「プラスアルファ」が何かについては後ほど説明します。
抽象構文木(Abstract Syntax Trees)
ここで言うコードの「解析」とは、コードを1文字ずつ構文解析し、アルゴリズムを実行することで、コードをどう調整し、書き換えるか、どのようにして機能を追加するかなどを明らかにすることを言います。通常、構文解析の結果は抽象構文木(AST)として出力されます。
そう言うと仰々しく聞こえますが、要はコードを分析しやすいようツリー構造で表したものです。
例えば、次の1行がコードに含まれていたとします。
const item = { id: 0, desc: 'Hi' };これを抽象構文木で表すと、次のようになります。
{
type: VariableDeclarator,
id: {
type: Identifier,
name: Item
},
init: {
type: ObjectExpression,
properties: [
{
type: ObjectProperty,
key: id,
value: 0
},
{
type: ObjectProperty,
key: desc,
value: 'Hi'
}
]
}
}生成されたデータ構造は、あなたが書いたコードを定義付けされた要素ごとに分解して説明します。各要素には、それがどういったものかを表す情報や、ひも付けされている値があればその値が含まれます。例えば、desc: 'Hi'はObjectPropertyであり、'desc'という keyと'Hi'というvalueがひも付けされています。
これが、トランスパイラやコンパイラなどがコードに対して行う処理について考える上でのメンタルモデルです。いずれも、あなたが書いたコード(テキストそのもの)をデータ構造に変換し、解析し、調整するために作成されたプログラムです。
最終的に生成されるコードはこのASTがもとになり、おそらくその他にもいくつかの中間言語が関与します。このデータ構造を繰り返し使用し、テキストを出力します(同じ言語で書かれた新しいコード、違う言語で書かれたコード、あるいは何らかの調整が加えられたコード)。
React Compilerは、ASTと中間言語の両方を使用し、あなたが書いたコードをもとに新しいReactコードを生成します。React自体がそうですが、React Compilerも「誰かが書いたコード」だということを忘れないでください。
コンパイラやトランスパイラ、オプティマイザなどのツールを謎めいたブラックボックスだとは考えないでください。時間さえあれば、自分にも作れるものだと考えましょう。
Reactのコアアーキテクチャ
React Compilerについて話す前に、明確にしておくべき概念があといくつかあります。
Reactのコアアーキテクチャがその人気の源泉であると同時に、パフォーマンスの問題の原因にもなり得ることはお話したかと思います。JSXを書く際、実際にはネストされた関数を記述しているのだということは説明した通りです。しかし、関数はReactに渡され、それをいつ呼び出すかはReactが判断します。
多数のアイテムを扱うReactアプリの最初の部分を例に見てみましょう。App関数はいくつかのアイテムを取得し、List関数はそれらを処理して表示すると仮定します。
function App() {
// TODO: fetch some items here
return <List items={items} />;
}
function List({ items }) {
const pItems = processItems(items);
const listItems = pItems.map((item) => <li>{ item }</li>);
return (
<ul>{ listItems }</ul>
)
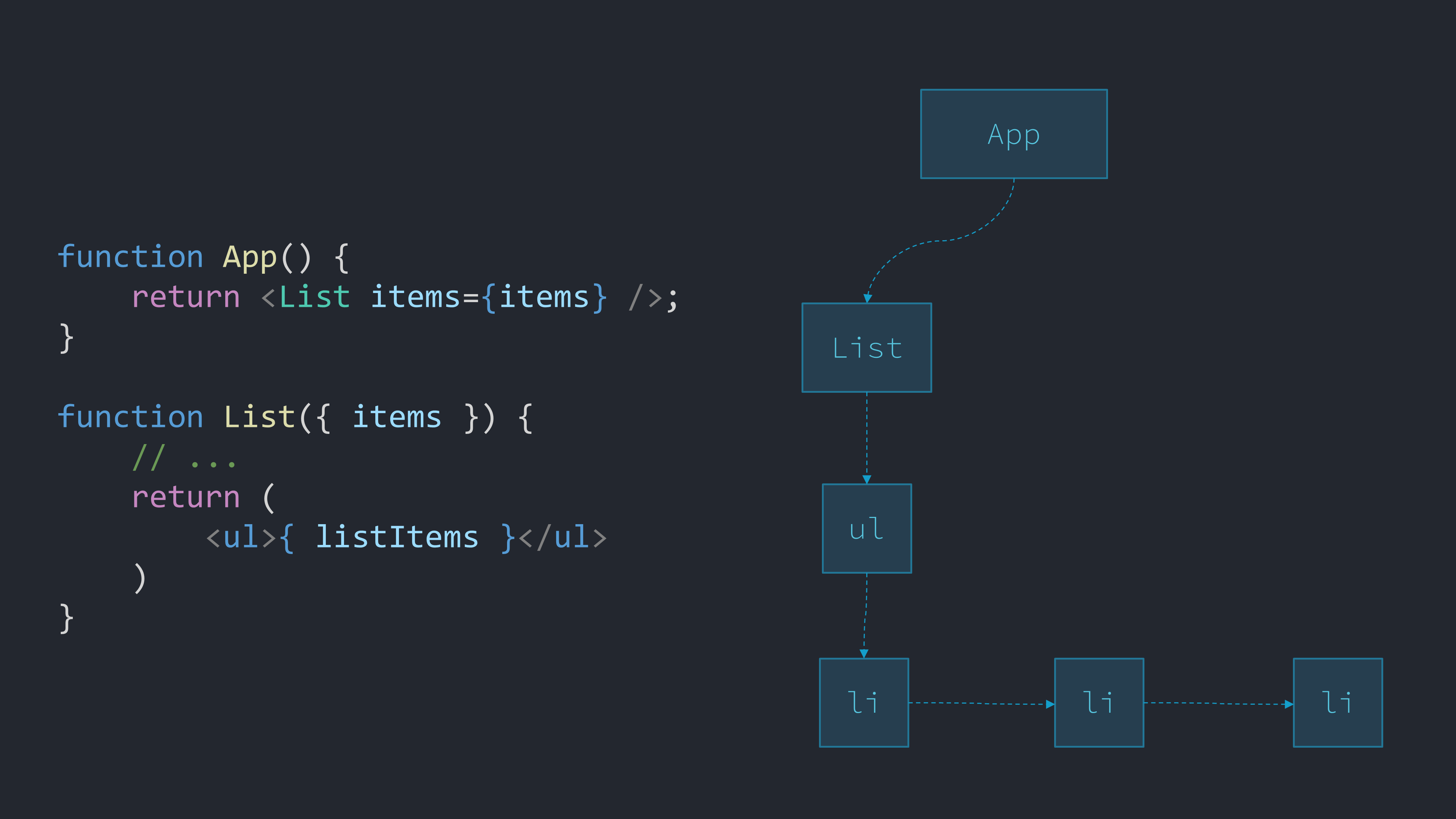
}これらの関数は、子(ここでは最終的に複数のliオブジェクトになる)を含むulオブジェクトのようなプレーンなJavaScriptオブジェクトを返します。ulやliなどの一部のオブジェクトはReactに組み込まれています。Listなど、それ以外のオブジェクトは自分で作成します。
最終的に、Reactはこれらすべてのオブジェクトを使ってFiberツリーと呼ばれるものを構築します。ツリーの各ノードはFiber、またはFiberノードと呼ばれます。UIを説明するためにJavaScriptオブジェクトからなる独自のノードツリーを作成することを、「仮想DOM」を作成すると言います。
Reactでは、ツリーの各ノードから枝分かれする2本の枝があります。1つは"current"(DOMと一致)、もう1つは"work-in-progress"(関数を再実行した際に返された内容をもとに構築したツリーと一致)の枝(ツリー)です。
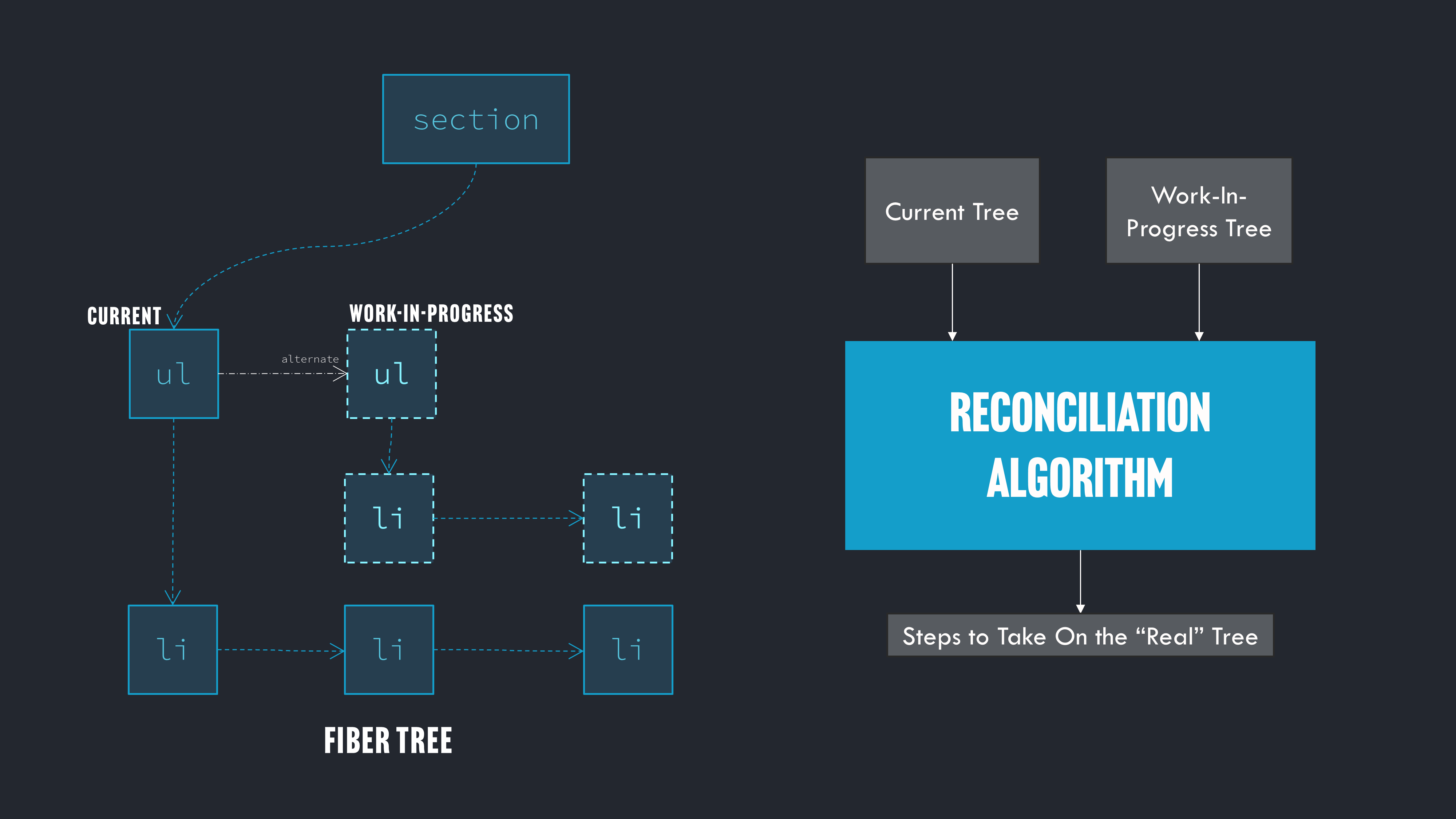
Reactはこれら2つのツリーを比較した上で、DOMがwork-in-progress側のツリーと一致するように実際のDOMに対して行う変更を判断します。このプロセスを「差分検出処理(reconciliation)」と呼びます。
したがって、他にどのような機能をアプリに追加するかによっては、ReactはUIの更新が必要だと判断するたびにList関数を繰り返し呼び出すかもしれません。そうするとメンタルモデルはかなり分かりやすくなります。UIの更新が必要な場合(例えば、ユーザーがボタンをクリックした場合など)、UIを定義する関数が再び呼び出され、Reactは関数が定義するUIの外観と一致するように、ブラウザ上で実際のDOMをどう更新するかを判断します。
しかし、processItems関数が遅いと、Listを呼び出すコールも遅くなり、アプリ全体の反応が遅くなってしまいます。
メモ化
パフォーマンスコストの高い関数を繰り返し呼び出す必要がある場合、プログラミングによる解決策として、関数の結果をキャッシュします。このプロセスを「メモ化」と呼びます。
メモ化が機能するためには、関数が「純粋」でなくてはなりません。つまり、関数に同じ入力値を渡した場合、毎回同じ出力が得られなくてはならないということです。出力が毎回同じであれば、入力値と関連付けた形で出力を保存することができます。
次にそのパフォーマンスコストの高い関数を呼び出した際には、入力値を見て、同じ入力値の関数をすでに実行済みかをキャッシュで確認します。すでに実行していれば、再度その関数を呼び出すのではなく、キャッシュに保存された出力を取得します。前回その入力値が使用されたときと出力が同じであることが分かっているので、再度関数を呼び出す必要はありません。
前述のコード例で使用したprocessItems関数がメモ化を実装した場合、次のようになります。
function processItems(items) {
const memOutput = getItemsOutput(items);
if (memOutput) {
return memOutput;
} else {
// ...run expensive processing
saveItemsOutput(items, output);
return output;
}
}saveItemsOutput関数は、アイテムと、この関数と関連する出力の両方を保存するオブジェクトを格納するものだと考えてください。getItemsOutputは、itemがすでに保存されているかを確認し、保存されていればそれ以上の作業は行わず、キャッシュに保存された関連する出力を返します。
関数を繰り返し呼び出すReactのアーキテクチャにとって、メモ化はアプリの動作が遅くならないようにするための重要な技術です。
Hooksの保存
React Compilerを理解するために理解する必要のあるReactのアーキテクチャがもう1つあります。
アプリの「state」(UIの作成に必要なデータ)が変わると、Reactは再度関数を呼び出す必要があるか判断します。例えば、値がtrueかfalseである"showButton"というデータの場合、このデータの値に応じて、UIはボタンを表示するか、非表示にする必要があります。
Reactはクライアントのデバイス上にstateを保存します。どうやって保存するのでしょうか。いくつかのアイテムをレンダリングし、操作するReactアプリを例に見てみましょう。最終的に選択されたアイテムを保存し、アイテムをクライアント側でレンダリングし、イベントを処理し、リストをソートすると仮定します。アプリは次のようになります。
function App() {
// TODO: fetch some items here
return <List items={items} />;
}
function List({ items }) {
const [selItem, setSelItem] = useState(null);
const [itemEvent, dispatcher] = useReducer(reducer, {});
const [sort, setSort] = useState(0);
const pItems = processItems(items);
const listItems = pItems.map((item) => <li>{ item }</li>);
return (
<ul>{ listItems }</ul>
)
}JavaScriptエンジンがuseStateとuseReducerの行を実行した際、何が起きるでしょうか。Listコンポーネントをもとに作成したFiberツリーのノードには、データを保存するためのJavaScriptオブジェクトがいくつか追加されています。各オブジェクトは互いに連結し、連結リストと呼ばれるデータ構造になっています。
none
多くの開発者は、useStateがReactにおけるstate管理の肝だと考えていますが、そうではありません。これは単に、useReducerを呼び出すコールのラッパーです。
useStateとuseReducerを呼び出すと、ReactはstateをFiberツリーに付け加え、アプリが実行されている間、これらは保持されます。したがって、関数が繰り返し再実行される間、stateはいつでも利用できる状態にあります。
none
Hooksの保存方法は、Hooksをループまたはif文の中で呼び出せないという「Hooksのルール」の説明にもなります。Hooksを呼び出すたびに、Reactは連結リストの次のアイテムに移動します。したがって、Hooksを呼び出す回数は一貫している必要があります。一貫していないと、Reactは連結リストの中の間違ったアイテムを指す場合があります。
結局、Hooksはユーザーデバイスのメモリ上にデータ(および関数)を保存するオブジェクトに過ぎないのです。これは、React Compilerが実際に行う処理を理解する上で重要です。ただし、それだけではありません。
Reactにおけるメモ化
Reactは、メモ化の概念とHooksの保存の概念を組み合わせています。Fiberツリーの一部であり、Reactに渡すすべての関数(Listなど)の結果をメモ化することも、それらの中で呼び出す個別の関数(processItemsなど)をメモ化することもできます。
キャッシュは、stateと同じようにFiberツリー上に保存されます。例えば、useMemoはuseMemoを呼び出すノード上に入力値と出力を保存します。
つまり、Reactにはパフォーマンスコストの高い関数の結果を、Fiberツリーの一部であるJavaScriptオブジェクトの連結リストに保存するという概念がすでに備わっているということです。これは素晴らしいことですが、1つ問題があります。メンテナンスです。
Reactにおけるメモ化は、メモ化が依存する入力値を明示的にReactに伝える必要があるため、面倒です。processItemsを呼び出すコールは次のようになります。
const pItems = useMemo(processItems(items), [items]);最後の配列は「依存関係」のリスト、すなわち変更されたらReactに再度関数を呼び出すよう指示する入力値です。これらの入力値が正しくないと、メモ化は正しく機能しません。事務的な雑務として維持し続ける必要があります。
React Compiler
ここでReact Compilerの登場です。React Compilerは、Reactコードのテキストを解析し、JSXのトランスパイルを行うための準備ができた新しいコードを生成するプログラムです。ただし、その新しいコードには追加された要素があります。
この場合、React Compilerがアプリに対してどのような処理を行うのか見てみましょう。以下はコンパイル前の状態です。
function App() {
// TODO: fetch some items here
return <List items={items} />;
}
function List({ items }) {
const [selItem, setSelItem] = useState(null);
const [itemEvent, dispatcher] = useReducer(reducer, {});
const [sort, setSort] = useState(0);
const pItems = processItems(items);
const listItems = pItems.map((item) => <li>{ item }</li>);
return (
<ul>{ listItems }</ul>
)
}コンパイル後は次のようになります。
function App() {
const $ = _c(1);
let t0;
if ($[0] === Symbol.for("react.memo_cache_sentinel")) {
t0 = <List items={items} />;
$[0] = t0;
} else {
t0 = $[0];
}
return t0;
}
function List(t0) {
const $ = _c(6);
const { items } = t0;
useState(null);
let t1;
if ($[0] === Symbol.for("react.memo_cache_sentinel")) {
t1 = {};
$[0] = t1;
} else {
t1 = $[0];
}
useReducer(reducer, t1);
useState(0);
let t2;
if ($[1] !== items) {
const pItems = processItems(items);
let t3;
if ($[3] === Symbol.for("react.memo_cache_sentinel")) {
t3 = (item) => <li>{item}</li>;
$[3] = t3;
} else {
t3 = $[3];
}
t2 = pItems.map(t3);
$[1] = items;
$[2] = t2;
} else {
t2 = $[2];
}
const listItems = t2;
let t3;
if ($[4] !== listItems) {
t3 = <ul>{listItems}</ul>;
$[4] = listItems;
$[5] = t3;
} else {
t3 = $[5];
}
return t3;
}これが新しく書き直されたList関数です。かなりの情報量なので、少し分解して説明します。
冒頭に次の行があります。
const $ = _c(6);この_c関数("c"は「キャッシュ」を表します)は、Hooksを使用して保存される配列を作成します。React CompilerはLink関数を解析し、パフォーマンスを最大限に高めるには6つのものを保存する必要があると判断したのです。最初に関数が呼び出されたとき、その6つのものの結果を配列に保存します。
次に関数が呼び出されたときにはキャッシュが使われます。例として、processItemsを呼び出す部分を見てみましょう。
if ($[1] !== items) {
const pItems = processItems(items);
let t3;
if ($[3] === Symbol.for("react.memo_cache_sentinel")) {
t3 = (item) => <li>{item}</li>;
$[3] = t3;
} else {
t3 = $[3];
}
t2 = pItems.map(t3);
$[1] = items;
$[2] = t2;
} else {
t2 = $[2];
}関数の呼び出しとliの生成の両方を含む、processItemsに関するすべての処理がラップされた状態で、配列で2番目のキャッシュ($[1])が、前回関数が呼び出されたときと同じ入力値かどうかを確認します(Listに渡されるitemsの値)。
同じであれば、キャッシュ配列で3番目の位置($[2])が使われます。itemsのマッピングが完了すると、生成されたすべてのliのリストが保存されます。React Compilerのコードはこう言っているのです。「前回この関数を呼び出したときと同じアイテムのリストを渡してくれたら、前回キャッシュに保存したliのリストをあげます。」
前回と違うitemsを渡すと、processItemsを呼び出します。その場合でも、リストの中の個々のアイテムについての情報をキャッシュに保存します。
if ($[3] === Symbol.for("react.memo_cache_sentinel")) {
t3 = (item) => <li>{item}</li>;
$[3] = t3;
} else {
t3 = $[3];
}t3 = の行をご覧ください。liを返すアロー関数を再度作成するのではなく、キャッシュ配列で4番目の位置($[3])に関数自体を保存しています。これにより、JavaScriptエンジンは次にListが読み出されたときにこの関数を作成する必要がなくなります。この関数は決して変わることがないため、最初のif文は基本的にこう言っています。「キャッシュ配列のこの場所が空いているならキャッシュしてください。空いていなければキャッシュから取得してください。」
このようにして、Reactは自動的に値をキャッシュし、関数の結果をメモ化します。Reactが出力するコードは我々が書いたコードと機能は同じですが、これらの値をキャッシュするためのコードを含んでおり、Reactが繰り返し関数を呼び出すことでパフォーマンスが損なわれないようにしています。
ただし、React Compilerのキャッシュは開発者が一般的にメモ化で行うキャッシュよりも詳細であり、しかも自動的にこれを行っています。つまり、開発者は手動で依存関係やメモ化を管理する必要がないのです。コードさえ書けば、React Compilerがそれをもとに新しいコードを生成し、キャッシュを利用することで高速化も実現してくれます。
React CompilerがまだJSXを生成していることも言っておくべきでしょう。実際に実行されるコードは、JSXのトランスパイルを行った上でReact Compilerが生成したものです。
JavaScriptエンジンで実際に実行される(ブラウザに送られるか、サーバー上で実行される)List関数は、次のようなものです。
function List(t0) {
const $ = _c(6);
const {
items
} = t0;
useState(null);
let t1;
if ($[0] === Symbol.for("react.memo_cache_sentinel")) {
t1 = {};
$[0] = t1;
} else {
t1 = $[0];
}
useReducer(reducer, t1);
useState(0);
let t2;
if ($[1] !== items) {
const pItems = processItems(items);
let t3;
if ($[3] === Symbol.for("react.memo_cache_sentinel")) {
t3 = item => _jsx("li", {
children: item
});
$[3] = t3;
} else {
t3 = $[3];
}
t2 = pItems.map(t3);
$[1] = items;
$[2] = t2;
} else {
t2 = $[2];
}
const listItems = t2;
let t3;
if ($[4] !== listItems) {
t3 = _jsx("ul", {
children: listItems
});
$[4] = listItems;
$[5] = t3;
} else {
t3 = $[5];
}
return t3;
}React Compilerは、値をキャッシュするための配列と、そのために必要なすべてのif文を追加しました。JSXトランスパイラはJSXをネストされた関数に変換しました。あなたが書いたコードとJavaScriptエンジンが実行するコードの間には大きな違いがあります。つまり、他人が書いたコードが、自分が当初意図したとおりのものを生成してくれることを信用する必要があります。
CPUの命令サイクルとデバイスメモリのトレードオフ
メモ化とキャッシュは、大まかに言うとメモリを犠牲にしてCPUへの負荷を軽減することを意味します。CPUがパフォーマンスコストの高い演算を行わなくて済む代わりに、メモリ容量を消費してデータを保存しているのです。
React Compilerを使用するということは、デバイスのメモリ上にできるだけデータを保存するということです。ユーザーデバイスのブラウザ上でコードを実行する場合、この点はアーキテクチャの面で意識する必要があります。
多くのReactアプリでは大きな問題にならないでしょう。しかし、アプリ上で大量のデータを扱う場合、実験ステージを経たReact Compilerを使うのであれば、少なくともデバイスメモリが使用されることを意識し、メモリの使用状況を注視する必要があるでしょう。
抽象化とデバッグ
形式を問わず、コンパイルはすべて自分が書いたコードと実際に実行されるコードの間の抽象化レイヤーに相当します。
この記事で説明したように、React Compilerの場合、実際にブラウザに送られるコードの内容を理解するためには、自分のコードをReact Compilerにかけて、生成されたコードをJSXトランスパイラにかけてみる必要があります。
コードに抽象化レイヤーを加えることにはデメリットもあります。デバッグが難しくなる場合があるのです。だからと言って使用を避けた方がいいというわけではありませんが、デバッグ対象のコードは自分が書いたものだけではなく、ツールが生成したものだということは頭に入れておく必要があります。
抽象化レイヤーから生成されたコードをデバッグする上では、抽象化について正確なメンタルモデルを持っておくことが成果を大きく左右します。React Compilerの仕組みを完全に理解することで、生成されたコードをデバッグできるようになり、ストレスなく開発作業を行えるようになるでしょう。
さらに深く掘り下げる
このブログ記事が有益だと感じていただけたなら、筆者が提供しているUnderstanding Reactというコースもぜひご検討ください。計16.5時間にわたり、Reactのあらゆる機能について同様に深く掘り下げています。生涯にわたるアクセス権とすべてのソースコード、修了証が得られます。
筆者はReactのソースコードも、React Compilerのソースコードも、すべて読みました。なぜかと言うと、Reactの仕組みを内部実装レベルから説明できるようにするためです。
React自体は、Webを基礎とし、その上に構築された大きな抽象化レイヤーです。抽象化ではよくあることですが、Reactを使用する開発者のほとんどは、その仕組みについて正確なメンタルモデルを持っていません。それが、Reactベースのアプリケーションをビルドし、デバッグする上で大きな影響を及ぼしています。しかし、Reactについて深く理解することは可能です。
React 19の機能とReact Compilerに関する新しい内容を近々コースに追加する予定です。すでに受講されている方は無料でご利用いただけます。コースの方もぜひチェックしてみてください。最初の6時間分の内容は、筆者のYouTubeチャンネルで無料公開しています。以下がその動画です。
単に誰かが書いたコードをまねするだけではなく、自分の仕事を本当の意味で理解する旅に、一緒に出かけてみませんか? -- トニー

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事