2022年7月27日
React Server Componentsの仕組み:詳細ガイド
本記事は、原著者の許諾のもとに翻訳・掲載しております。
React Server Components(RSC)は、ページの読み込みパフォーマンスやバンドルサイズのほか、Reactアプリケーションの書き方に近い将来大きな影響を与えることになる、素晴らしい新機能です。 Plasmicでは、Reactのビジュアルビルダーを開発しており、Reactのパフォーマンスには大きな関心を持もっています。 当社のクライアントの多くは、Plasmicを使用して高いパフォーマンスが求められるマーケティングサイトやECサイトを構築しています。 したがって、RSCはまだReact 18の初期実験機能ですが、Plasmicではその仕組みを詳しく調べています。 このブログ記事では、これまでに分かったことを紹介したいと思います。 Plasmicのメンバーによるツイートまとめもご覧ください。
- React Server Componentsとは何か
- サーバサイドレンダリングとの違いは?
- RSCを使うメリット
- RSCの全体像
- サーバコンポーネントとクライアントコンポーネントの分断
- RSCレンダリングの流れ
- RSCワイヤーフォーマット
- サーバコンポーネントがレンダリングしているコンテンツのアップデート
- RSCにメタフレームワークを使うべき理由
- RSCは実用化の準備ができているのか?
React Server Componentsとは何か
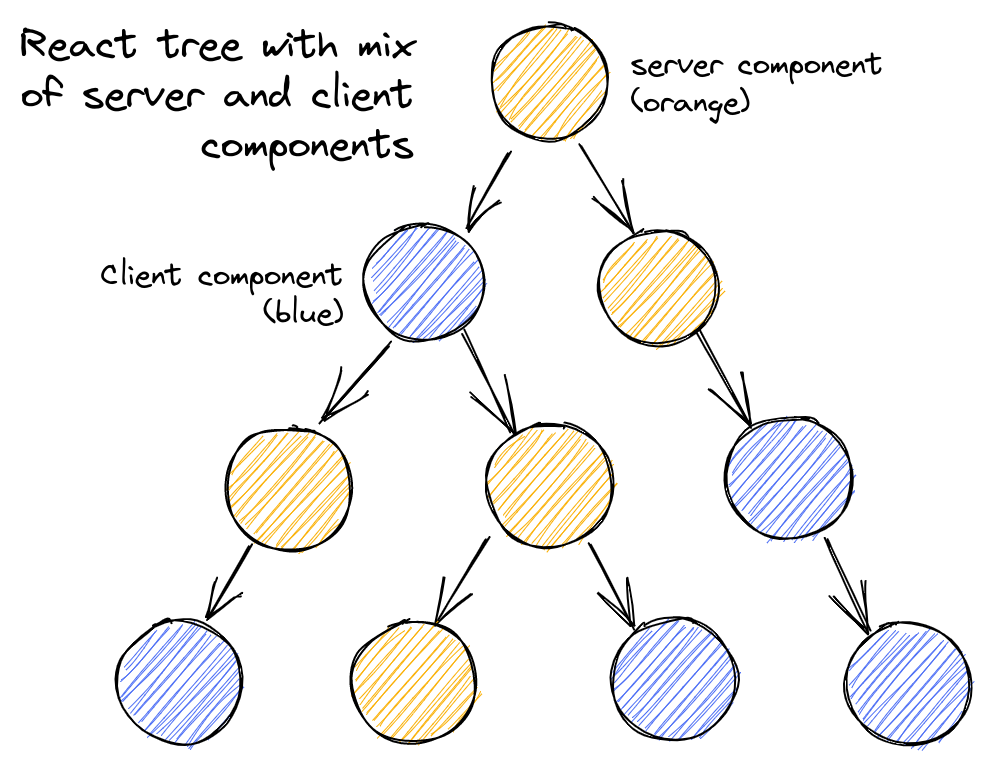
React Server Components(RSC)は、サーバとクライアント(ブラウザ)が連携してReactアプリケーションのレンダリングを行うことを可能にします。 Webページを表示する際にレンダリングされる一般的なReact要素ツリーは、通常異なるReactコンポーネントがさらに多くのReactコンポーネントをレンダリングする構成になっています。 RSCは、このツリーを構成する一部のコンポーネントがサーバによってレンダリングされ、他のコンポーネントがブラウザによってレンダリングされることを可能にします。🤯
これはReactチームによる概略図です。 最終的なゴールは、オレンジのコンポーネントはサーバ側でレンダリングされ、青のコンポーネントはクライアント側でレンダリングされるようなReactツリーです。
サーバサイドレンダリングとの違いは?
RSCはサーバサイドレンダリング(SSR)ではありません。 どちらも名前に「サーバ」が含まれ、どちらもサーバ上で動いているので少し混乱しますね。 しかし、両者はそれぞれ独立した直交する機能であると理解した方がずっと分かりやすいでしょう。 RSCはSSRを必要とせず、その逆もまたしかりです。 SSRは、Reactツリーを生HTMLにレンダリングするための環境をシミュレーションします。 サーバコンポーネントとクライアントコンポーネントを区別せず、どちらも同じようにレンダリングします。
SSRとRSCを組み合わせ、サーバコンポーネントでサーバサイドレンダリングを行い、ブラウザ上で適切にハイドレーションすることも可能です。 両者を併用する方法については、後日別の記事で詳しく話したいと思います。
SSRについてはひとまず無視し、RSCだけにフォーカスしましょう。
RSCを使うメリット
RSC以前のReactコンポーネントはすべてクライアントコンポーネントであり、ブラウザ上で実行されます。 Reactページにアクセスすると、ブラウザは必要なReactコンポーネントすべてのコードをダウンロードし、React要素ツリーを構築してDOMにレンダリングします(SSRを使用している場合は、DOMをハイドレーションします)。 これらの処理がブラウザ上で行われることで React アプリケーションはインタラクティブに(イベントハンドラをインストールし、ステートを追跡し、イベントに応じてReactツリーに変更を加え、DOMを効率的にアップデートできるように)なります。 では、サーバ上でレンダリングを行うメリットは何でしょうか。 ブラウザよりサーバ上でレンダリングを行った方がよい理由はいくつかあります。
- サーバは、データベース、GraphQLエンドポイント、ファイルシステムなどのデータソースにもっとダイレクトにアクセスできます。パブリックAPIエンドポイントを経由することなく、必要なデータを直接取得でき、通常データソースに近い場所に配置されているため、ブラウザよりも素早くデータを取得できます。
- サーバは、たとえばマークダウンをHTMLに変換してレンダリングするためのnpmパッケージなどの「重い」コードモジュールを手軽に利用できます。それは、これらの依存関係を使用するたびにダウンロードする必要がないからです。ブラウザの場合、使用するコードをすべてJavaScriptのバンドルとしてダウンロードする必要があります。
要するに、RSCはサーバとブラウザが互いに得意な処理を行えるようにするのです。 サーバコンポーネントはデータの取得とコンテンツのレンダリング、クライアントコンポーネントはステートフルなインタラクティビティに注力できるため、ページの読み込み速度が速くなるほか、JavaScriptのバンドルサイズが小さくなり、ユーザ体験が改善されます。
RSCの全体像
では、まずその仕組みについて直感的に理解することから始めましょう。
筆者の子供たちはカップケーキのデコレーションは大好きなのですが、焼くことに関してはさほど興味を示しません。 カップケーキを一から作らせ、デコレーションまでさせるのは、きっと(かわいらしい)悪夢のような経験になるでしょう。 小麦粉と砂糖、バターを用意し、オーブンの使用を許可し、さまざまな取扱説明書を延々と読んで聞かせなくてはいけません。 そんなことをしていては、丸一日かかってしまいます。 しかし筆者ならば、オーブンで焼く作業をずっと速く行えます。 一部の作業を事前に行っておけば(原材料をそのまま渡すのではなく、カップケーキを焼き、アイシングを作り、それらを渡す)、子供たちは楽しいデコレーションにもっと早く取り掛かれます。 さらに良いことに、子供たちがオーブンを使用することについて心配する必要がありません。 素晴らしい!

RSCの目的は、この役割分担を可能にすることです。 サーバが得意な作業は事前にサーバに行わせてから、残りの作業をブラウザに引き継ぐのです。 そうすることで、サーバがブラウザに渡すデータ量も減らすことができます。 袋いっぱいの小麦粉とオーブンに比べ、小さなカップケーキ12個の方がはるかに効率的に運べます。
一部のコンポーネントはサーバ側で、残りはクライアント側でレンダリングされるようなページのReactツリーを想像してみてください。
RSCのハイレベルな戦略を簡略化すると以下のような形になります。
サーバは、いつも通りサーバコンポーネントをレンダリングし、ReactコンポーネントをdivやpなどのネイティブHTML要素に変換します。
しかし、ブラウザ上でレンダリングされるクライアントコンポーネントに遭遇すると、代わりにプレースホルダを出力します。
サーバは、プレースホルダーに適切なクライアントコンポーネントとpropsを適用するように指示を加えます。
ブラウザはこの出力を受け取り、クライアントコンポーネントで穴埋めを行います。
これで完成です。
実際の仕組みはそんなに単純ではありません。 詳細については後ほど話しますが、まずは全体像を頭に入れておくと有益です。
サーバコンポーネントとクライアントコンポーネントの分断
ところで、サーバコンポーネントとは何でしょうか。 サーバ用とクライアント用のコンポーネントはどのようにして区別するのでしょうか。
Reactチームでは、コンポーネントが記述されたファイルの拡張子を基に定義しています。
.server.jsxで終わるファイルにはサーバコンポーネント、.client.jsxで終わるファイルにはクライアントコンポーネントが含まれています。
これらいずれの拡張子ももたないファイルには、サーバ用としてもクライアント用としても使用できるコンポーネントが含まれています。
これは実用的な定義であり、人間にとってもバンドラーにとっても区別が容易です。 特にバンドラーにとっては、ファイル名を調べることでクライアントコンポーネントを区別し、処理方法を変えられるようになりました。 後述しますが、バンドラーはRSCが適切に機能する上で重要な役割を果たします。
サーバコンポーネントはサーバ上で、クライアントコンポーネントはクライアント上で実行されるため、それぞれできることにさまざまな制限があります。 その中でも最も重要なのが、クライアントコンポーネントはサーバコンポーネントをインポートできないということです。 それは、サーバコンポーネントはブラウザ上で実行できず、ブラウザ上では機能しないコードが含まれる可能性があるためです。 クライアントコンポーネントがサーバコンポーネントに依存する場合、不正な依存関係がブラウザバンドルに入り込んでしまうことになります。 つまり、以下のようなクライアントコンポーネントは不正ということになってしまうため、この最後の点は難題になり得ます。
// ClientComponent.client.jsx
// 悪い例:
import ServerComponent from './ServerComponent.server'
export default function ClientComponent() {
return (
<div>
<ServerComponent />
</div>
)
}しかし、クライアントコンポーネントがサーバコンポーネントをインポートできず、サーバコンポーネントのインスタンスを生成できないのであれば、どうすれば以下のようにサーバコンポーネントとクライアントコンポーネントが交互に配置されたReactツリーができるのでしょうか。またどうすれば、クライアントコンポーネント(青い丸)の下にサーバコンポーネント(オレンジ色の丸)を配置できるのでしょうか。
クライアントコンポーネントからサーバコンポーネントをインポートしてレンダリングすることはできませんが、コンポジションは使用できます。
つまり、クライアントコンポーネントは単なる不透明なReactNodeであるpropsを取り込むことはでき、ReactNodeがサーバコンポーネントによってレンダリングされることも可能です。
以下に例を挙げます。
// ClientComponent.client.jsx
export default function ClientComponent({ children }) {
return (
<div>
<h1>Hello from client land</h1>
{children}
</div>
)
}
// ServerComponent.server.jsx
export default function ServerComponent() {
return <span>Hello from server land</span>
}
// OuterServerComponentはクライアントコンポーネントも
// サーバーコンポーネントもインスタンス化することができ、
// ClientComponentのchildrenとして<ServerComponent/>を渡します。
import ClientComponent from './ClientComponent.client'
import ServerComponent from './ServerComponent.server'
export default function OuterServerComponent() {
return (
<ClientComponent>
<ServerComponent />
</ClientComponent>
)
}この制限は、RSCを有効に活用するためのコンポーネントの配置を検討する上で大きな影響があります。
RSCレンダリングの流れ
それでは、Reactサーバコンポーネントをレンダリングするときに実際何が起こるのか、肝心な部分を詳しく見ていきましょう。 ここで説明することをすべて理解しなくてもサーバコンポーネントは使えますが、仕組みについて直感的な理解は得られると思います。
1. サーバがレンダリングリクエストを受け取る
レンダリングの一部はサーバが行わなくてはならないため、RSCを使用する場合、ページのレンダリングは必ずサーバで始まります。 その際、APIコールによってReactコンポーネントのレンダリングが開始します。 この「ルート」コンポーネントは必ずサーバコンポーネントであり、他のサーバコンポーネントまたはクライアントコンポーネントをレンダリングする場合もあります。 サーバは、リクエストに含まれる情報をもとに、使用するサーバコンポーネントとpropsを判断します。 このリクエストは、通常特定のURLでページリクエストの形で届きますが、Shopify Hydrogenはよりきめ細かい方法を使用しており、Reactチームの公式デモではraw実装を行っています。
2. サーバがルートコンポーネント要素をJSON形式にシリアライズ
ここでの最終目的は、最初のルートサーバコンポーネントをHTMLのタグとクライアントコンポーネントのプレースホルダで構成されるツリーとしてレンダリングすることです。 次に、そのツリーをシリアライズしてブラウザに送ります。 ブラウザ側では、受け取ったデータをデシリアライズし、プレースホルダを実際のクライアントコンポーネントに置き換え、最終結果をレンダリングします。
上の例に沿って見てみましょう。
<OuterServerComponent/>をレンダリングしたい場合、JSON.stringify(<OuterServerComponent />)を実行すればシリアライズされた要素ツリーが得られるでしょうか?
惜しいですが、少し違います。😅
React要素とは実際のところどういうものだったか、思い出してみてください。
typeというフィールドに文字列または関数をとるオブジェクトです。
type には、文字列なら"div"のようなhtmlのタグ名が、関数ならReactコンポーネントのインスタンスが入ります。
// <div>oh my</div> を返す場合
> React.createElement("div", { title: "oh my" })
{
$$typeof: Symbol(react.element),
type: "div",
props: { title: "oh my" },
...
}
// <MyComponent>oh my</MyComponent> を返す場合
> function MyComponent({children}) {
return <div>{children}</div>;
}
> React.createElement(MyComponent, { children: "oh my" });
{
$$typeof: Symbol(react.element),
type: MyComponent // MyComponent 関数への参照 function
props: { children: "oh my" },
...
}typeにHTMLタグではなくコンポーネントを指定した場合、typeフィールドはコンポーネントとして定義した関数(訳注: 原文ではcomponent function。本記事では、以降「コンポーネント関数」と訳します)を参照します。
しかし、関数はJSON 形式にシリアライズできません。
すべての要素をJSON文字列に適切に変換するために、Reactはこれらのコンポーネント関数の参照に適切に対処する特別な置換関数をJSON.stringify()に渡します。
そのa関数は、ReactFlightServer.jsにあるresolveModelToJSON()です。
具体的には、シリアライズ対象のReact要素に対して以下の処理を行います。
- HTMLのbaseタグ(
typeフィールドには、「div」のような文字列が入ります)の場合、すでにシリアライズ可能です。特別な処理は必要ありません。 - サーバコンポーネントの要素の場合、サーバコンポーネント関数(
typeフィールドに格納されている)とそのpropsを呼び出し、その結果をシリアライズします。これは実質的にサーバーコンポーネントのレンダリングに相当します。つまり、全てのサーバーコンポーネントをただのHTMLタグに変換するのです。 - クライアントコンポーネントの場合も、すでにシリアライズ可能です。
typeフィールドはすでにコンポーネント関数ではなく、モジュール参照オブジェクトを指し示しています。このモジュール参照オブジェクトとは一体何なのでしょう。
####「モジュール参照」オブジェクトとは何か
RSCでは、React要素のtypeフィールドに「モジュール参照」と呼ばれる新しい値を導入できます。
コンポーネント関数の代わりに、コンポーネント関数へのシリアライズ可能な「参照」を渡すのです。
例えば、ClientComponentという要素は以下のような形を取ることができます。
{
$$typeof: Symbol(react.element),
// type フィールドが、実際のコンポーネント関数の代わりに参照オブジェクトを持つようになりました
type: {
$$typeof: Symbol(react.module.reference),
// ClientComponent は以下のファイルから default export されます
name: "default",
// ClientComponent を default export しているファイルのパス
filename: "./src/ClientComponent.client.js"
},
props: { children: "oh my" },
}しかし、このマジックのような処理はどこで行われているのでしょうか。 クライアントコンポーネント関数への参照は、どこでシリアライズ可能な「モジュール参照」オブジェクトに変換されているのでしょうか。
なんと、この手品のような処理はバンドラーが行なっているのです。
Reactチームは、webpack向けの公式RSCサポートを、react-server-dom-webpackでwebpackローダまたはnode-registerとして公開しています。
サーバコンポーネントが*.client.jsxファイルから何かをインポートする際、実際のインポート対象を取得する代わりに、そのファイル名とエクスポート名が含まれたモジュール参照オブジェクトだけを取得しています。
クライアントコンポーネント関数が、サーバ上に構築されるReactツリーの一部に組み込まれることはありません。
このセクションの冒頭で<OuterServerComponent />をシリアライズしようとした例を思い出してください。
最終的には以下のようなJSONツリーになります。
{
//「モジュール参照」を持つ ClientComponent のプレースホルダー
$$typeof: Symbol(react.element),
type: {
$$typeof: Symbol(react.module.reference),
name: "default",
filename: "./src/ClientComponent.client.js"
},
props: {
// ClientComponent に渡される children(ここでは <ServerComponent />)
children: {
// ServerComponentは html タグに直でレンダリングされます。
// ServerComponent への参照が一切なく、直でspanをレンダリングしていることに注目してください。
$$typeof: Symbol(react.element),
type: "span",
props: {
children: "Hello from server land"
}
}
}
}シリアライズ可能なReactツリー
このプロセスの終わりには、サーバ上に以下のようなReactツリーができていることが望まれます。 これをブラウザに送信して「仕上げ」を行います。
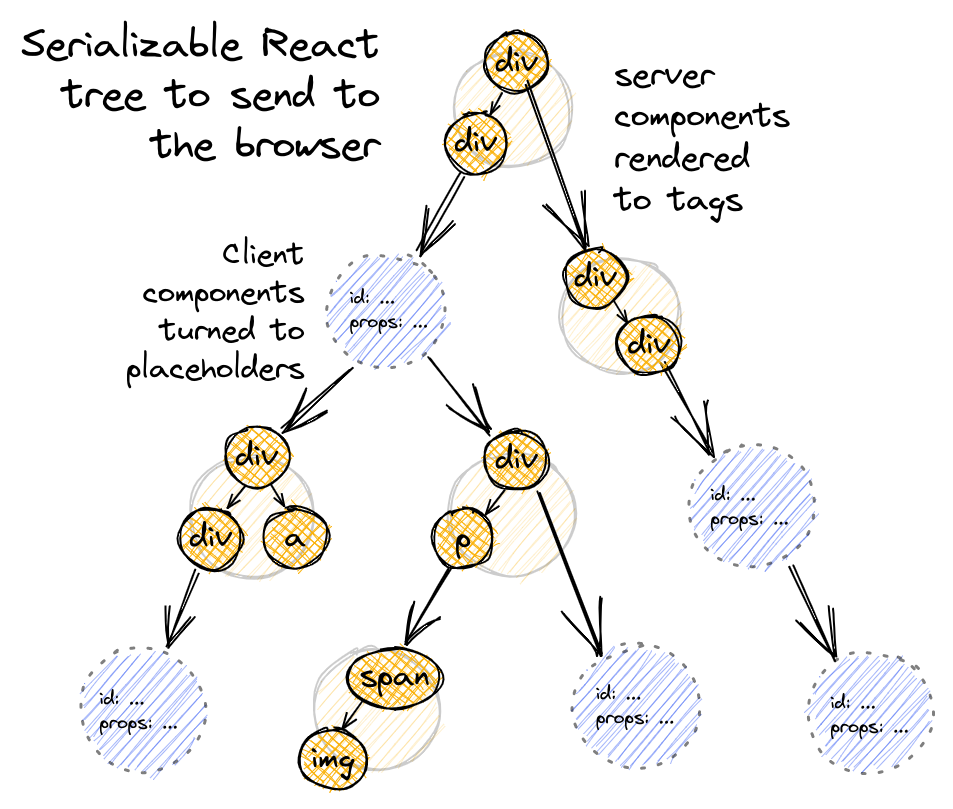
propsはすべてシリアライズ可能であること
Reactツリー全体をJSON形式にシリアライズするため、クライアントコンポーネントまたはHTMLのbaseタグに渡すpropsもすべてシリアライズ可能でなくてはなりません。 これはつまり、サーバコンポーネントからイベントハンドラをpropsとして渡すことはできないということです。
// 悪い例: サーバーコンポーネントは props として子孫コンポーネントに関数を渡すことができません。なぜなら関数はシリアライズできないからです。
function SomeServerComponent() {
return <button onClick={() => alert('OHHAI')}>Click me!</button>
}しかし、1つ留意すべき点として、RSCプロセスの際にクライアントコンポーネントに遭遇しても、決してクライアントコンポーネント関数を呼び出したり、クライアントコンポーネントに「降りて行く」ことはありません。 したがって、別のクライアントコンポーネントのインスタンスを生成するクライアントコンポーネントがある場合、以下のようになります。
function SomeServerComponent() {
return <ClientComponent1>Hello world!</ClientComponent1>;
}
function ClientComponent1({children}) {
// クライアントからクライアントコンポーネントに props として関数を渡すのは可
return <ClientComponent2 onChange={...}>{children}</ClientComponent2>;
}このRSC JSONツリーには、ClientComponent2は一切出てきません。
その代わり、ClientComponent1のモジュール参照とpropsをもつ要素だけがあります。
そのため、ClientComponent1がpropsとしてイベントハンドラをClientComponent2に渡すのは、全く正常なことです。
3. ブラウザがReactツリーを再構築
ブラウザは、サーバからJSON出力を受け取ったら、ブラウザ上でレンダリングするReactツリーの再構築を開始しなくてはいけません。
typeがモジュール参照である要素に遭遇した場合、実際のクライアントコンポーネント関数への参照に置き換える必要があります。
この作業には、再びバンドラーの助けが必要になります。
バンドラーを用いてサーバ上でクライアントコンポーネント関数をモジュール参照に置き換えたように、今度はバンドラーを用いてブラウザ上でモジュール参照を実際のクライアントコンポーネント関数に置き換えます。
再構築されたReactツリーは以下のようになります。異なる点は、ネイティブのタグとクライアントコンポーネントが置き換わっていることだけです。
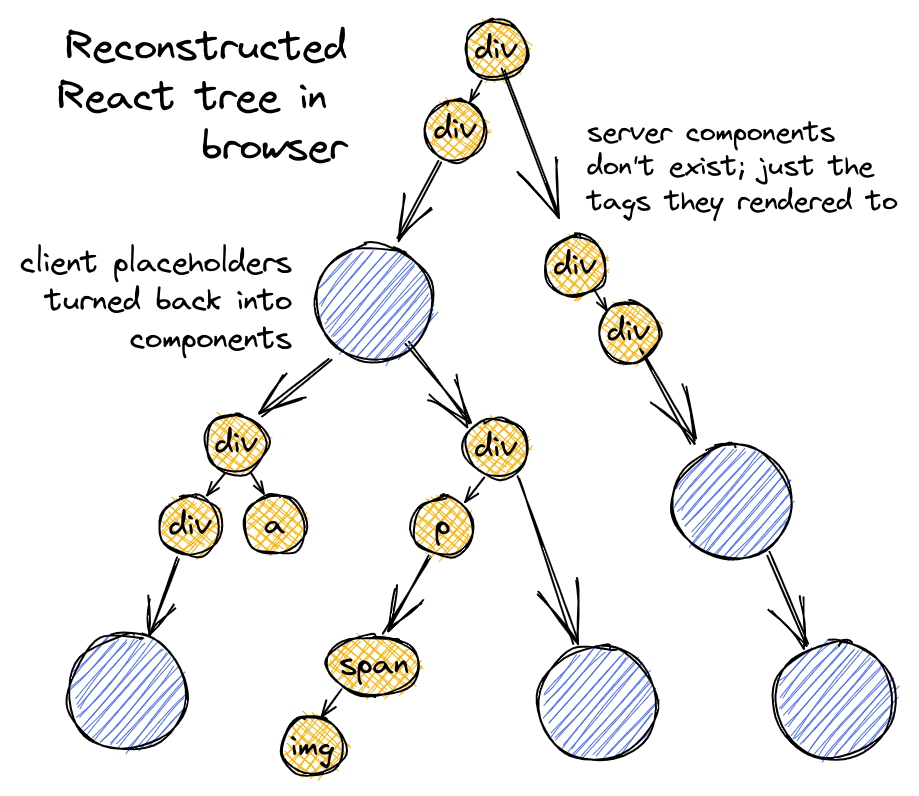
あとは、いつも通りこのツリーをレンダリングし、DOMにコミットするだけです。
Suspenseとの互換性は問題ないか?
問題ありません。 Suspenseは、上で述べたすべてのステップで欠かせない役割を果たします。
Suspenseはそれ自体が壮大なテーマであり、それ単体でブログ記事1本分に相当するものなので、この記事ではあえて軽く触れるだけに留めています。 ごく簡単に説明すると、Suspenseは何か準備ができていないもの(データのフェッチ、コンポーネントの遅延インポートなど)を必要とする際、ReactコンポーネントからPromiseをスローすることを可能にします。 それらのPromiseは、Suspenseの境界でキャッチされます。 Suspenseサブツリーのレンダリング時にPromiseがスローされると、ReactはPromiseが解決されるまでサブツリーのレンダリングを停止し、再度トライします。
RSC出力を生成するためにサーバ上でサーバコンポーネント関数を呼び出すと、それらの関数が必要なデータを取得する際にPromiseを返す場合があります。 スローされたPromiseに遭遇すると、プレースホルダを出力します。 Promiseが解決すると、再びサーバコンポーネント関数を呼び出し、成功すれば完成したチャンクを出力します。 RSC出力ストリームを作成しているのであり、Promiseがスローされると停止し、解決すると追加のチャンクをストリーミングします。
同様に、ブラウザ上では上のfetch()コールからRSC JSON出力ストリームを作成します。
このプロセスも、出力の中にSuspenseのプレースホルダがあり(サーバがスローされたPromiseに遭遇している)、ストリーム内にまだプレースホルダのコンテンツを見つけていない(詳細はこちら)場合、Promiseをスローすることになるかもしれません。
あるいは、クライアントコンポーネントのモジュール参照に遭遇したものの、まだブラウザ上にクライアントコンポーネント関数が読み込まれていない場合も、Promiseをスローする可能性があります。
その場合、バンドラーのランタイムが動的に必要なチャンクを取得する必要があります。
Suspenseのおかげで、サーバコンポーネントがデータを取得する間にサーバはRSC出力をストリーミングし、ブラウザは受け取ったデータから徐々にレンダリングし、必要になったクライアントコンポーネントバンドルを動的に取得します。
RSCワイヤーフォーマット
具体的にサーバは何を出力しているのでしょうか。 「JSON」と「ストリーム」の文字を見て疑念を抱いたのであれば、それは正しい反応です。 では、サーバはブラウザにどのようなデータをストリーミングしているのでしょうか。
IDがタグ付けされたJSONの塊が各行に一つ追加された、単純なフォーマットです。
以下は、<OuterServerComponent/>の例のRSC出力です。
M1:{"id":"./src/ClientComponent.client.js","chunks":["client1"],"name":""}
J0:["$","@1",null,{"children":["$","span",null,{"children":"Hello from server land"}]}]上のスニペットでは、Mで始まる行はクライアントコンポーネントのモジュール参照を定義しており、クライアントバンドルの中からコンポーネント関数を検索するのに必要な情報が含まれています。
Jで始まる行は、実際のReact要素ツリーを定義しており、M行で定義されたクライアントコンポーネントを参照する@1などが含まれます。
このフォーマットは非常にストリーミングしやすく、クライアントは1行読み終えるとすぐにJSONのスニペットを解析して処理を進めることができます。
サーバがレンダリング中にSuspense境界に遭遇した場合、各チャンクが解決される度たびにそれと一致する複数のJ行が出てきます。
もう少し興味深い例を見てみましょう。
// Tweets.server.js
import { fetch } from 'react-fetch' // React の Suspense 対応した fetch()
import Tweet from './Tweet.client'
export default function Tweets() {
const tweets = fetch(`/tweets`).json()
return (
<ul>
{tweets.slice(0, 2).map((tweet) => (
<li>
<Tweet tweet={tweet} />
</li>
))}
</ul>
)
}
// Tweet.client.js
export default function Tweet({ tweet }) {
return <div onClick={() => alert(`Written by ${tweet.username}`)}>{tweet.body}</div>
}
// OuterServerComponent.server.js
export default function OuterServerComponent() {
return (
<ClientComponent>
<ServerComponent />
<Suspense fallback={'Loading tweets...'}>
<Tweets />
</Suspense>
</ClientComponent>
)
}この場合、RSCストリームはどのように見えるでしょうか。
M1:{"id":"./src/ClientComponent.client.js","chunks":["client1"],"name":""}
S2:"react.suspense"
J0:["$","@1",null,{"children":[["$","span",null,{"children":"Hello from server land"}],["$","$2",null,{"fallback":"Loading tweets...","children":"@3"}]]}]
M4:{"id":"./src/Tweet.client.js","chunks":["client8"],"name":""}
J3:["$","ul",null,{"children":[["$","li",null,{"children":["$","@4",null,{"tweet":{...}}}]}],["$","li",null,{"children":["$","@4",null,{"tweet":{...}}}]}]]}]J0行には新たな子が追加されています。
childrenが参照@3を指している新しいSuspense境界です。
興味深いことに、この時点ではまだ@3は定義されていません。
サーバはツイートの読み込みを完了すると、M4とJ3の行を出力します。
前者はTweet.client.jsコンポーネントへのモジュール参照を定義し、後者は@3を置き換えるべき別のReact要素ツリーを定義します(ここでも、J3のchildrenはM4で定義されたTweetコンポーネントを参照しています)。
バンドラーがClientComponentとTweetを二つの異なるバンドルに自動的に入れており、それによってブラウザがTweetバンドルのダウンロードを遅らせることができる点も、ここで述べておくべきでしょう。
RSCフォーマットを使う
このRSCストリームをブラウザ上で実際のReact要素に変換するにはどうすればよいのでしょうか。
react-server-dom-webpackには、RSCレスポンスを用いてReact要素ツリーを再構築するエントリーポイントがあります。
以下はルートクライアントコンポーネントを簡略化した例です。
import { createFromFetch } from 'react-server-dom-webpack'
function ClientRootComponent() {
// RSC API のエンドポイントから fetch() を実行します。
// react-server-dom-webpack はフェッチした結果を受け取り、
// React の要素ツリーを再構築することができます。
const response = createFromFetch(fetch('/rsc?...'))
return <Suspense fallback={null}>{response.readRoot() /* Returns a React element! */}</Suspense>
}react-server-dom-webpackに、APIエンドポイントからのRSCレスポンスを読むよう指示します。
次に、response.readRoot()が、レスポンスストリームが処理されると更新されるReact要素を返します。
ストリームがまだ読まれる前に、直ちにPromiseがスローされます。
これは、まだコンテンツが用意できていないからです。
最初のJ0が処理されると、対応するReact要素ツリーが作成され、返されたPromiseが解決されます。
Reactはレンダリングを再開しますが、まだ準備ができていない@3の参照に遭遇すると、新たなPromiseがスローされます。
そのPromiseはJ3を読んだ時点で解決され、Reactは再びレンダリングを開始し、今回は完了します。
したがって、RSCレスポンスをストリーミングしながら、Suspense境界によって定義されたチャンク単位で要素ツリーの更新とレンダリングを完了するまで継続します。
単にプレーンHTMLを出力すればよいのでは?
なぜ全く新しいワイヤーフォーマットを発明する必要があるのでしょうか。 クライアント側における目的は、React要素ツリーを再構築することです。 HTMLは、解析しなければReact要素を作成できないため、この目的はHTMLよりもこのフォーマットから行う方がずっと簡単に果たせます。 React要素ツリーを再構築することで、DOMへのコミットを最小限に留めつつReactツリーへのその後の変更をマージできるようになるため、これは重要なプロセスです。
クライアントコンポーネントからデータを取得するだけよりもメリットがある?
このコンテンツを取得するために、どちらにしてもサーバにAPIリクエストを送信する必要があるのであれば、現在のようにリクエストを送信してデータだけを取得し、クライアント側ですべてのレンダリングを行うよりも、RSCを使った方が本当によいのでしょうか。
最終的には、何をレンダリングして画面上に表示するのかによります。 RSCでは、ユーザに向けて表示されるコンテンツに直接マッピングされる、非正規化された「処理済み」のデータを受け取ります。 したがって、取得するデータの一部だけをレンダリングしたい場合や、レンダリング自体に大量のJavaScriptが必要なため、ブラウザへのダウンロードを避けたい場合はメリットがあります。 さらに、レンダリングを行うために複数回データを取得する必要があり、ウォーターフォールにおいてそれぞれ互いに依存し合う場合、ブラウザよりもデータのレイテンシがはるかに低いサーバ上でデータを取得した方がよいでしょう。
サーバサイドレンダリングはどうなる?
SSRがどうなるのか気になる方が多いのはよく分かります。 React 18ではSSRとRSCの併用が可能なため、サーバ上でHTMLを生成し、ブラウザ上でRSCを用いてHTMLをハイドレーションすることが可能です。 このテーマについてはまた別の機会に詳しく話したいと思います。
サーバコンポーネントがレンダリングしているコンテンツのアップデート
ある製品のページから別の製品のページに切り替えたい場合など、サーバコンポーネントに新しいコンテンツをレンダリングさせる必要がある場合はどうすればよいでしょうか。
この場合も、レンダリングはサーバ側で行われるため、新しいコンテンツをRSCワイヤーフォーマットで取得するためにはサーバに新たなAPIコールを行う必要があります。 よいニュースは、ブラウザが新しいコンテンツを受け取ると、クライアントコンポーネントにステートハンドラとイベントハンドラを保持しつつ、新しいReact要素ツリーを構築し、前のReactツリーとの差分を取るための通常の差分検出処理を行い、DOMに対する必要最小限のアップデートを判断できるという点です。 クライアントコンポーネントにとっては、このアップデートはすべてブラウザ上で行われた場合と比べても何ら違いがありません。
現時点では、Reactツリー全体をルートサーバコンポーネントから再レンダリングする必要がありますが、将来的にはこれをサブツリーに対して行えるようになるかもしれません。
RSCにメタフレームワークを使うべき理由
Reactチームは、RSCは当初プレーンなReactプロジェクトで直接使用するのではなく、Next.jsやShopify Hydrogenのようにメタフレームワーク経由での導入を意図していると述べています。 これはなぜでしょうか。 メタフレームワークにはどのようなメリットがあるのでしょうか。
メタフレームワークの使用は必須ではありませんが、作業が楽になります。 メタフレームワークが提供するラッパーや抽象化は使いやすいため、サーバ上でRSCストリームを生成し、ブラウザ上で消費することを考える必要がありません。 また、メタフレームワークはサーバサイドレンダリングもサポートしており、サーバコンポーネントを使用している場合にサーバが生成したHTMLを適切にハイドレーションできるよう、必要な作業を実施しています。
上で説明したように、クライアントコンポーネントを適切に送信し、ブラウザ上で使用するためにはバンドラーの助けも必要です。 webpackインテグレーションはすでにあり、現在はShopifyがviteへのインテグレーションに取り組んでいます。 RSCに必要なプラグインの多くはパブリックnpmパッケージとして公開されていないため、これらのプラグインはReactリポジトリの一部でなくてはいけません。 しかし、一度開発されれば、メタフレームワークなしでこれらのプラグインを使用できるようになるはずです。
RSCは実用化の準備ができているのか?
RSCは、現在Next.jsの実験的な機能として提供されており、Shopify Hydrogenの現在の開発者プレビュー段階にありますが、どちらもまだ本番環境で使用できる状態ではありません。 今後のブログ記事では、これらのフレームワークがそれぞれRSCをどのように使用しているのか詳しく説明したいと思います。
しかし、RSCが今後のReactを大きく左右する存在であることは間違いありません。RSCは、ページの読み込み速度向上、JavaScriptバンドルの軽量化、Time To Interactive(TTI)の短縮という課題に対するReactの答えであり、Reactを使用して複数ページのアプリケーションを構築する方法に関するより包括的なテーゼです。未完成ではあるものの、注目すべき時が近づいています。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事









