2015年12月1日
Word2Vecを用いた研究 : ベクトル空間での操作で、単語から「ジェンダーの2元性」を排除する
本記事は、原著者の許諾のもとに翻訳・掲載しております。
前回の投稿では、言語のword embeddingモデル(WEM)という新しいモデルの概要を説明し、基本的なWEM操作が簡単に実行できるR言語のパッケージを紹介しました。 この記事はほとんど、デジタルヒューマニティーズのコミュニティの皆さん向けに書きました。本稿では、ratemyprofessors.comの教職員メンバーによる約1,400万のレビューを使ってトレーニングした1つのword2vecモデルについて、詳しく説明します。 ^(1) このモデルの注目点は、ジェンダー(性別)を示す言葉について分析する際に、こうした機械学習のモデルがどこまで役立つのかについて、具体的な研究ができるということです。この記事で、機械学習のモデルのトレーニングには興味のない方の関心も引くことができればうれしいと、私は思っています。コードを多少提示しますが、読み飛ばしてくださって構いません。
では前回の投稿を軽くおさらいしましょう。私はこれまで、WEMは言語学の分野で単語同士の 関係 を探るための強力かつ柔軟な手段であると主張してきました。単語はベクトルとしてエンコードされますが、それだけではなく、単語同士の 関係 にも意味があると考えるのが妥当です。機械学習の世界で最も印象深いWEMの利用方法は、ただ1種類だけの関係を使うもの、すなわち類推のタスクです。といってもWEMが実行する処理は「good(良い):better(より良い)::bad(悪い):? 」や「fish(魚):school(学校)::crow(カラス):? 」のような、SAT(米国の大学入学適性試験)スタイルの設問に正しく回答するという従来の方法よりもずっと高度なものです。前回の投稿で書いた通り、私が作成したコーパス「Rate My Professor」を使ってこのモデルにタスクを処理させたところ、かなり良好な結果が得られました。事前に設定した「学術分野と著者」のペアに関する情報に基づいて、新しい学術分野の中で最も多く読まれる教科書を類推するというタスクに対して、エラーも少しはありましたが、概ね的確な結果を返しました。
また、WEMの動作を見ていて、私はこのモデルが、単純にSAT形式の設問に回答を返す以上の、とても興味深い処理ができることに気づきました。そこで、この記事のタイトルを「ジェンダー二元語の排除」としました。このタイトルは一般的に、 性別二元論の性質を批判する表現として使われることが多い 言い回しです。しかしWEMが実際に返してくるのは、「rejection」(排除)と「the gender binary」(二元的なジェンダー)という2つの用語について、正確に形式化された定量的な定義です。控えめに表現すると、少し腹立たしい結果です。「gender」にしても「rejection」にしても、WEMの捉え方は、もちろん現実とは異なります。しかしだからといって、ここから知見が得られないというわけではありません。
逆に言うと、WEMのおかげで私たちは、「性別に関してマッピングのパターンが 存在しない とすれば、言語における意味のネットワークとはどんなものなのか」という反事実的な問いについて考えることができます。
library(wordVectors)
library(dplyr)
teaching_vectors =read.vectors("~/rmp2vec/vectors.txt") 二元的なジェンダー
そもそも、二元的なジェンダーとはどんなものでしょうか。word2Vecの世界で「二元的ジェンダー変換」とは、空間内で男性語から女性語へと繋がる経路の追跡を試みることを意味します。私は、モデルの中で、あるベクトルが学術分野からテキストの著者へと向かっていることに気付きました。従って私は、女性語から男性語へのベクトルも同様に作成できます。(繰り返しますが、ここに示したコードでは、 私が自作のR言語パッケージのために設計したシンタックスを使っています 。)
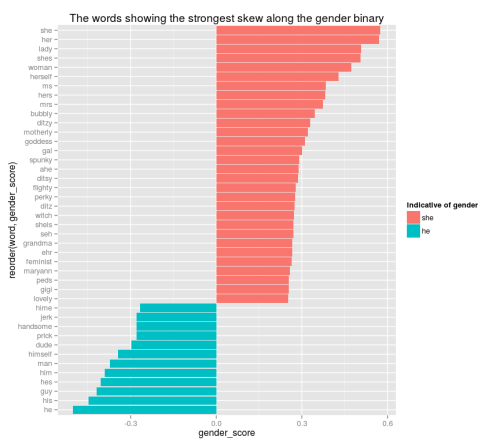
gender_vector =RMP[["she"]] -RMP[["he"]] コサイン類似度を使って、関連するベクトルとの高い類似度を示す語を全て抽出します。性別ベクトルに対するコサイン類似度または非類似度が0.25を超える、全単語のリストを以下に示します。言い換えるとこれらの語は、男性または女性のどちらかへの偏向をはっきりと示しているということになります。
library(ggplot2)
word_scores =data.frame(word=rownames(RMP))
word_scores$gender_score =RMP %>%cosineSimilarity(gender_vector) %>%as.vector
ggplot(word_scores %>%filter((gender_score)>.))+geom_bar((gender_score,reorder(word,gender_score),fill=gender_score<),stat="identity") +coord_flip()+scale_fill_discrete("Indicative of gender",labels=("she",)) +(title="The words showing the strongest skew along the gender binary")
## Warning in loop_apply(n, do.ply):Stacking not well defined when ymin != 0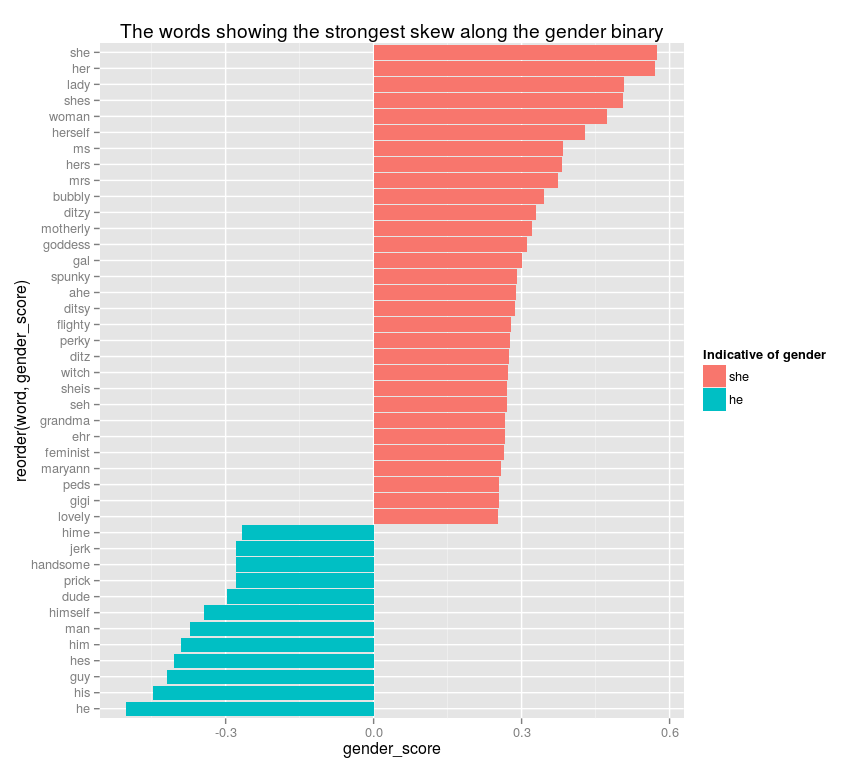
注釈:
The words showing the strongest skew along the gender binary:二元的なジェンダーへの顕著な偏向を表している語
Indicative of gender: ジェンダーの指標
この単純なベクトルは明らかに、ジェンダーのある言葉についての有意な何かを示しています。リストには、性別を示す代名詞が多数含まれていますが、性別を明確に限定する形容詞もたくさん含まれています。例えば男性教師を示す語として「prick」(嫌な奴)と「jerk」(間抜け)、女性を示す語には「spunky」(魅力的な)「ditzy」(頭の弱い)「flighty」(気まぐれな)「feminist」(フェミニスト)「goddess」(女神)が挙げられています。(人名も幾つか含まれています。アルゴリズムで極力排除したのですが、フィルタで捕捉しきれませんでした。)
この結果から、女性社会学的な表現や男性の身体的特徴を表す語を取り出し、いろいろと面白いことができそうです。語の排除の話題に早く移りたいので、例を1つだけ挙げますが、男女両方向に関して、様々な語の性別表現の強さをグリッド上に一覧表にして示すこともできます。これで私はすぐに、学生たちの言葉使いを思い出しました。(何か例題を使って、私の rate my professors language explorer の処理を試し、実際にはどんな動作をするのかを調べてくださっても構いません。)
goodness_vector =teaching_vectors[[("good","best")]]-teaching_vectors[[("bad","worst")]]
gender_vector =RMP[[("woman","she","her","hers",,"herself")]] -RMP[[("man",,"his","him",,"himself","herself")]]
word_scores$gender_score =RMP %>%cosineSimilarity(gender_vector) %>%as.vector
word_scores$goodness_score =cosineSimilarity(RMP,goodness_vector) %>%as.vector
groups =("gender_score","goodness_score")
word_scores %>%mutate( genderedness=ifelse(gender_score>,"female","male"),goodness=ifelse(goodness_score>,"positive","negative")) %>%group_by(goodness,genderedness) %>%filter((-((gender_score*goodness_score)))<=) %>%mutate(eval=-+((goodness_score)/(gender_score))) %>%ggplot() +geom_text((eval %/%,eval%%,label=word,fontface=ifelse(genderedness=="female",,),color=goodness),hjust=) +facet_grid(goodness~genderedness) +theme_minimal() +scale_x_continuous(,(,)) +scale_y_continuous() +(title="The top negative (red) and positive(blue)used to describe men (italics) and women(bold)") +theme(legend.position="none") 
注釈:
男性(斜体)と女性(太字)を表す際に使う表現の中で、最も否定的なもの(赤)と最も肯定的なもの(青)
ベクトル排除を取り入れる
このように、ジェンダーベクトルはジェンダーのある単語を抽出することができます。これまでのところ、この方法は、単語のリストを生成する際に任意の単語の関連語を拾い出すのがずっと高速なので、他の方法よりも効率的です。
ベクトル排除 をこの図式に持ち込むと、とても興味深いことになります。
(訳注:「ベクトル排除」とは、リンク先のwikipediaの図におけるa ₂ ベクトルのこと。
aベクトルのbベクトルに対する正射影(Vector projection)をa ₁ とした時、a ₂ =a-a ₁ となり、bベクトルと直行する。a2ベクトルはaベクトルからbベクトルを排除したもの、ということになる)
前回の投稿で述べたように、ベクトル排除ではword embeddingでのある単語の経路について、他の任意のベクトルとの類似性を取り除くことができます。
ですから例えば、銀行業務に関連するいくつかの語を「bank」(岸、銀行)という単語から除外し、最も「river」(川)の近くにあるベクトルを得ることができるのです。
chronam_vectors =read.vectors(("gunzip -c ~/Dropbox/rmp2vec/shorter_chronam.txt.gz"),nrow=50000,vectors = )
not_that_kind_of_bank =chronam_vectors[["bank"]] %>%reject(chronam_vectors[["cashier"]]) %>%reject(chronam_vectors[["depositors"]]) %>%reject(chronam_vectors[["check"]])
chronam_vectors %>%nearest_to(not_that_kind_of_bank) %>%names
## [1] "bank" "river" "banks" "side" "road" "live"
## [7] "lies" "still" "district" "tha"このような直接的な排除をすると、単語の思いがけない別の意味に遭遇することがあります。大学院生が作ったこうしたモデルの1つを見てみましょう。このモデルには、「colony」/「colonial」/「colonist」といったベクトルの様々な組み合わせがあります。私は、19世紀後期の新聞で、「colony」という単語が「colonist」という単語とは、ある意味無関係に使われていたことに興味がありました。恐らくこの単語はインドやフィリピンを指していたのでしょう。単語のリストでは、実際にどのような文脈で単語が最もよく使われたのかが明らかになります。それは、裕福な人々向けの郊外や静養所という文脈でした。(ただ、その他にも様々な島に関連した単語があることから、1898年以降のアメリカ帝国主義の姿が垣間見えます。)
chronam_vectors %>%nearest_to(chronam_vectors[["colony"]] %>%reject(chronam_vectors[["colonists"]]))
## colony suburb group society island prominent recently
## 0.3112762 0.6375631 0.6682267 0.6696360 0.6784742 0.6857096 0.6867107
## villa wealthy village
## 0.6925267 0.6940062 0.6949403ジェンダー二元語の排除
従来のマトリックスを使った言語表現に対し、この新しいword embeddingモデルの際立った特徴は「単語間のベクトルは、意味論的に線形の意味を持つ」という点です。ですから、ベクトル排除の過程は、単語 それ自体 のベクトルと同様に、単語 相互の間 のベクトルについても意味があります。「ジェンダー二元語を排除する」ことの正式な定義は次のようなものです。つまり、それぞれの要素を変換して古いベクトル空間から新しいベクトル空間を構築し、その際、男女を分けるベクトルにはいかなる有向性も持たせないようにするということです。
genderless_RMP =RMP %>%reject(RMP[[]]-RMP[["she"]]) %>%reject(RMP[["man"]]-RMP[["woman"]])この2つのシステムを比較して、「she」(彼女)という単語に、どんな単語が最も近いのかを見てみましょう。ジェンダーのある枠組みでは、「she」(彼女)に意味的に近い単語のほとんどは3つのカテゴリに分類されます。
- 明らかに女性的な単語(「her」(彼女の)、「lady」(婦人)、「woman」(女性)など)
- 女性のみに属する形容詞(「ditzy」(うっかりした)、「bubbly」(はしゃいだ))
- 「she」(彼女)のような検索対象から除外される単語(ストップワード)
RMP %>%nearest_to(RMP[["she"]],) %>%names
## [1] "she" "her" "shes" "lady" "woman" "herself" "ms"
## [8] "mrs" "and" "bubbly" "ahe" "that" "very" "it"
## [15] "also" "hers" "is" "to" "teacher" "ditzy"ジェンダーのない枠組みでは、最も意味の近い単語は明らかに異なります。2番目に近い単語は「he」(彼)で、「his」(彼の)は4番目に近い単語です。「guy」(やつ)は近い単語ですが、「lady」(婦人)、「women」(女性)はリストから消えます。「ditzy」(うっかりした)と「bubbly」(はしゃいだ)は、コーパスの一般的な語(「to」(に向かって)や「class」(授業))に置き換わります。「teacher」(先生)は「Professor」(教授)に置き換わります。というのも、学生たちは男性に呼びかける際に、より高い肩書をより使う傾向があるからです(恐らく、女性は男性に比べて教育関連の周辺的な地位につくからというのが理由でしょう。または、学生は女性に対して、男性ほどは敬意を込めた肩書きを使う傾向がないというのも理由かもしれません。)
genderless_RMP %>%nearest_to(genderless_RMP[["she"]],) %>%names
## [1] "she" "he" "her" "his" "and"
## [6] "that" "guy" "is" "also" "the"
## [11] "very" "it" "shes" "to" "s"
## [16] "really" "but" "class" "professor" "you"この2つのベクトル空間の違いをうまく表現するために、斜線でつないだグラフを描く方法があります。左側は、最も似た単語とそのベクトル空間における順位を表し、右側は、ジェンダーを取り除いたベクトル空間における順位を表します。ここにある単語は全て、どちらかのベクトル空間において意味の近い上位10個の単語です。
slopegraph(set1="RMP",set2="genderless_RMP",word="she",)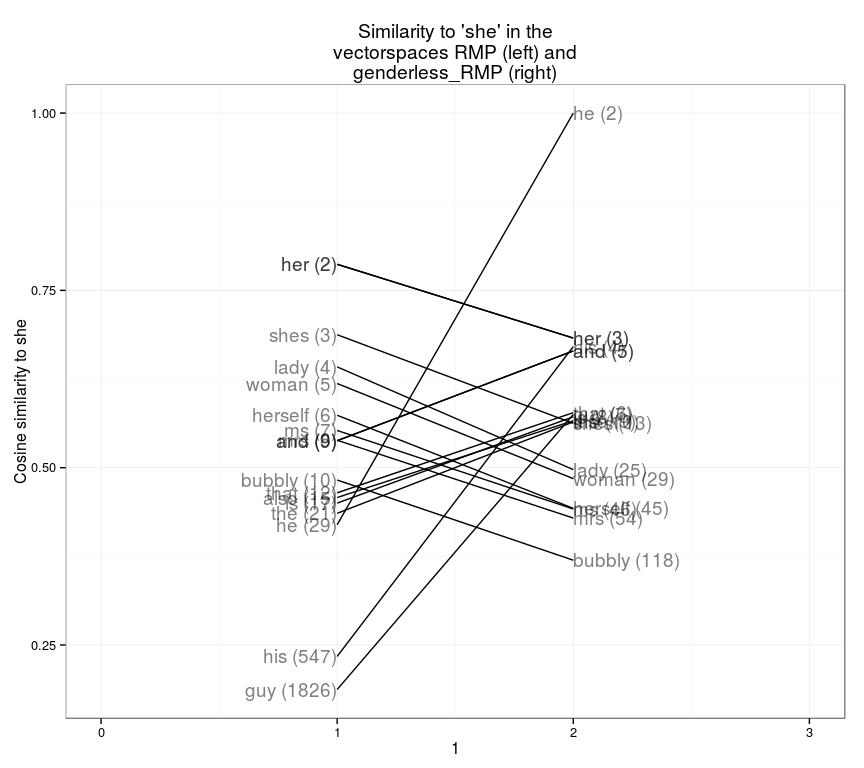
(訳注:「she(彼女)」という単語との類似度(左:ジェンダー排除前、右:ジェンダー排除後))
所々に、劇的な変化が見られます。「guy」(やつ)は、ジェンダーを調整しないベクトル空間では「she」(彼女)に1,826番目に近い単語ですが、ジェンダーを取り除いて調整したベクトル空間では6番目に近い単語です。
他の単語を見ると、小さい変化でも目を引くものがあります。「bubbly」(はしゃいだ)はジェンダーを 取り除く と意味論的に多くの意味を持っているので、リスト上では「guy」(やつ)と似た結果になります。しかしジェンダーを取り除いてみると、同義語(「upbeat」(陽気な)や「energetic」(活動的な)など)のほうが もっと 似ていると分かります。他の同義語(「perky」(活発な)と「spunky」(活気のある)など)は、文脈の他の要素とは対照的に、どちらも似たようなジェンダーの適用状況であることから、非常に高い類似性を示していると言えます。「charismatic」(カリスマ性のある)や「animated」(生き生きした)などの類似性の高い単語は、全く異なるジェンダーの適用状況を取り除けば、通常、「bubbly」(はしゃいだ)と同様の文脈を共有します。
slopegraph(set1="RMP",set2="genderless_RMP",word="bubbly",)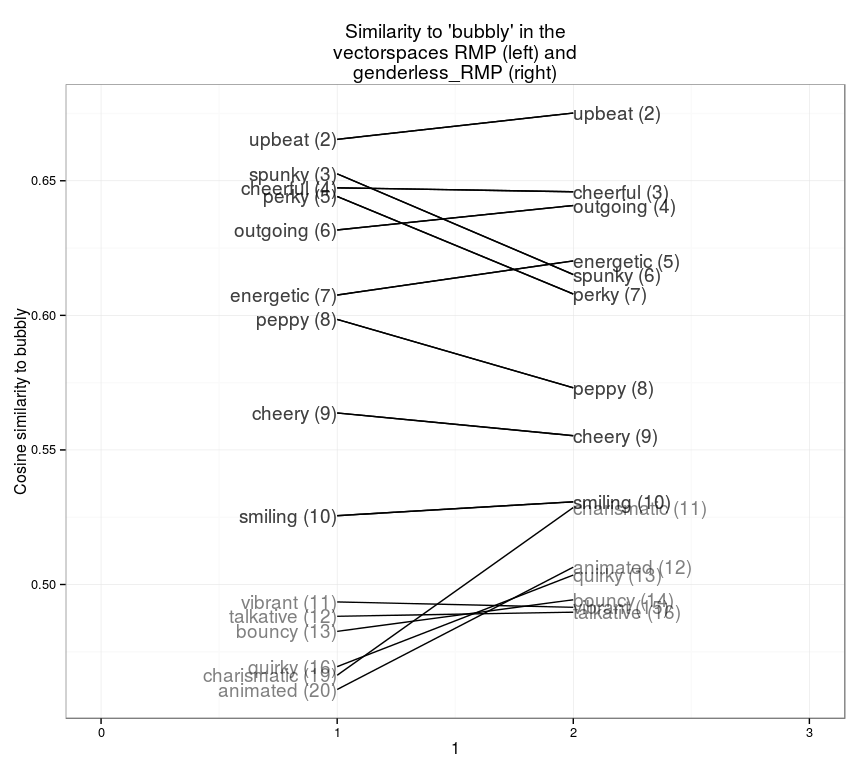
(訳注:「bubbly(はしゃいだ)」という単語との類似度(左:ジェンダー排除前、右:ジェンダー排除後))
「bubbly」(はしゃいだ)であることは、一般的には良いことです。さらに、「bossy」(威張った)などのネガティブな単語についても調べられます。実生活で、最も意味の近い単語は「pushy」(強引な)です。しかし、ジェンダーを取り除いて調整すると、「arrogant」(傲慢な)と「cocky」(横柄な)がどちらもかなり近い単語となります。(この図の順位は全て2位から始まります。説明を省きましたが、対象となる単語自体が1位となります。)
slopegraph(set1="RMP",set2="genderless_RMP",word="bossy",)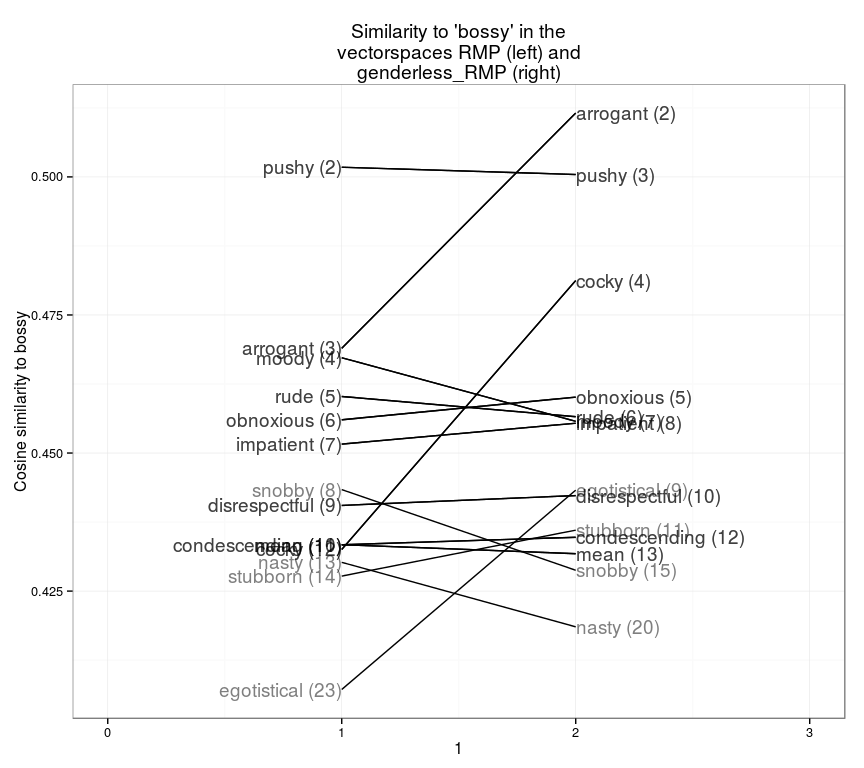
(訳注:「bossy(威張った)」という単語との類似度(左:ジェンダー排除前、右:ジェンダー排除後))
1日中座ってこのベクトル空間をずっと調べていても飽きません。実際、あらゆる種類の異なるword embeddingモデルを相互比較することは、非常に有効な方法かもしれません。(いつかはこの筋書きを、例えば19世紀と20世紀の新聞の比較へと展開させたいと思います。そうすれば、政治関連の一連の用語が、時代とともにどのように変化したかが分かるかもしれません。)
これを更に一般化する前に、まとめをしておきたいと思います。まずは新しい用語を定義しましょう。「ジェンダーのある同義語」です。例えば、「he」(彼)と「she」(彼女)は、一方が男性でもう一方が女性だということを除けば、同じ意味であると言えます。「man->woman」(男性->女性)、「uncle->aunt」(おじ->おば)、「wife->husband」(妻->夫)の他にもいろいろあります。(「wife->husband」(妻->夫)であって、「husband->wife」(夫->妻) ではありません 。この言語モデルでは、夫は、それ自体がジェンダーを持つタイプの人物ではありません。女性が夫に関連づけられがちな傾向があるというだけです。「skirt」(スカート)や「feminism」(フェミニズム)に、男性より女性のほうが関連づけられるようなものです。)
偏ったジェンダーの適用が見られる単語を探すことで、ジェンダーのある同義語の包括的なリストを生成することができます。次に、 ジェンダーベクトルの反対側のベクトル空間で 対応する語を探します。これは計算的に言えば、 男性 のセットと 女性 のセットからの全ての異なる単語を、ジェンダーのない空間で相互に比較することで、簡単に作成できます。それが、以下のコードで行っていることです。自分で実際にやってみようと思っている方以外は、この部分は無視していただいて構いません。
ungenderize =function(model,reference) {
model %>%reject(reference[[]]-reference[["she"]]) %>%reject(reference[["man"]]-reference[["woman"]])
}
masculine_RMP =RMP %>%filter_to_rownames(word_scores$word[word_scores$gender_score>.])
feminine_RMP =RMP %>%filter_to_rownames(word_scores$word[word_scores$gender_score<(-.)])
similarities =cosineSimilarity(feminine_RMP,masculine_RMP)
genderless_similarities =cosineSimilarity(ungenderize(feminine_RMP,RMP),masculine_RMP %>%ungenderize(RMP))
pairings =data.frame(source=(rownames(similarities),(similarities)),target=(colnames(similarities),each=(similarities)),true_similarity=as.vector(similarities),genderless_similarity=as.vector(genderless_similarities))
pairings =pairings %>%
group_by(source) %>%
mutate(source_rank=(-genderless_similarity)) %>%
group_by(target) %>%
mutate(target_rank=(-genderless_similarity)) %>%
mutate(share=((-genderless_similarity)/(-true_similarity))) %>%
mutate(label = paste(source,target,"->")) %>%
# We don't need *everything*, and this saves memory.
# But skip the filter for thoroughness.
filter(source_rank<=,target_rank<=) %>%
ungroupこのように、このコードを用いてジェンダーのない同義語の組合せのリストを生成し、よく対応している順に並べることができます。それぞれの単語がジェンダーのない空間においても、対となる単語と最も意味が近い場合に、対応が完全であると言えます。リストアップされたのは、377の組み合わせです。以下のリストは、ジェンダーベクトル ^(2) によって説明された2つの単語の間の違いを、パーセンテージの順に並べた上位100位のリストです。
pairings %>%
filter(source_rank<=,target_rank<=) %>%
arrange(share) %>%
() %>%mutate(joint = paste(source,target,"->")) %>%(joint)
## [1] "he->she" "hes->shes"
## [3] "himself->herself" "his->her"
## [5] "man->woman" "guy->lady"
## [7] "grandpa->grandma" "dude->chick"
## [9] "wife->husband" "grandfather->grandmother"
## [11] "dad->mom" "uncle->aunt"
## [13] "fatherly->motherly" "brother->sister"
## [15] "actor->actress" "grandfatherly->grandmotherly"
## [17] "father->mother" "genius->goddess"
## [19] "arrogant->snobby" "priest->nun"
## [21] "dork->ditz" "handsome->gorgeous"
## [23] "atheist->feminist" "himmmm->herrrr"
## [25] "kermit->degeneres" "mans->womans"
## [27] "hez->shez" "himmm->herrr"
## [29] "trumpet->flute" "checkride->clinicals"
## [31] "gay->lesbian" "surgeon->nurse"
## [33] "daddy->mommy" "cool->sweet"
## [35] "monsieur->mme" "jolly->cheerful"
## [37] "jazz->dance" "wears->outfits"
## [39] "girlfriends->boyfriends" "drle->gentille"
## [41] "gentleman->gem" "charisma->spunk"
## [43] "egotistical->hypocritical" "cutie->babe"
## [45] "wingers->feminists" "professore->molto"
## [47] "gruff->stern" "demonstrations->activities"
## [49] "goofy->wacky" "coolest->sweetest"
## [51] "architect->interior" "sidetracked->frazzled"
## [53] "likeable->pleasant" "grumpy->crabby"
## [55] "charismatic->energetic" "cisco->cna"
## [57] "masculinity->gender" "girlfriend->boyfriend"
## [59] "king->queen" "sesame->kindergarden"
## [61] "russir->cela" "cologne->perfume"
## [63] "racquetball->volleyball" "humble->compassionate"
## [65] "simpsons->oprah" "entertaining->lively"
## [67] "cracking->smiling" "chords->melody"
## [69] "frat->sorority" "comic->childrens"
## [71] "philosophy->sociology" "dj->cher"
## [73] "chemists->nurses" "geek->lover"
## [75] "solidworks->indesign" "haircut->makeover"
## [77] "drumming->dancing" "stagecraft->costume"
## [79] "disgusting->nasty" "bear->kitten"
## [81] "sales->retail" "maestro->excelente"
## [83] "quietly->kindergartners" "willy->np"
## [85] "mets->perso" "weightlifting->workout"
## [87] "stroke->breast" "girls->girl"
## [89] "policing->victimology" "evan->nonverbal"
## [91] "biomechanics->knes" "moe->dee"
## [93] "absentminded->scatterbrained" "discoveries->nutritional"
## [95] "philosopher->sociologist" "fungi->microbes"
## [97] "inappropriate->unprofessional" "broadcasting->communications"
## [99] "heap->piles" "hieroglyphics->rosetta"リストは、最もはっきりとジェンダーを表す代名詞の組み合わせから始まっていますが、すぐに、より興味深い単語が現れてきます。女性は「nasty」(意地悪な)なのに対して、男性は「disgusting」(むかつくような)です。魅力的な女性は「kittens」(子猫)なのに対し、魅力的な男性は「[teddy] bears」([テディ]ベア)です。
これが意味することは、違いを読み解く上ではっきりしています。学生たちが「Goddess」(女神)という単語を使う場合、「genius」(天才)と相補的に使っているつもりなかもしれませんが、ほとんどの研究者は評価されるなら「genius」(天才)と言われたほうがありがたいと思うでしょう。「sweet->cool」(かわいい->かっこいい)や「activities->demonstrations」(活動->実演)と似たようなものです。
そして、私たちは、なんとなくネガティブな男っぽい単語(「gruff」(ぶっきらぼうな)や「grumpy」(無愛想な))には、実は優しい心が隠されているという思い込みをウォルター・マッソーやビル・マーレーの映画から長年の間に植え付けられており、その女性版の単語「crabby」(すねた)や「stern」(厳格な)にはそういった救いはありません(少なくとも私にはそのように聞こえます)。 ^(3)
私が最も興味をひかれることは、米国とカナダの大学文化に共通してジェンダーが奇妙な現れ方をしているという、その類似性かもしれません。男性の「liberals」(進歩主義者)は「feminists」(フェミニスト)であり、「gender」(ジェンダー)そのものは「masculinity」(男らしさ)の女性版であり、女性は「children’s [literature]」(児童[文学])を教え、男性は「comic [books]」(コミック[本])を教えます。女性がphilosophy(哲学)をするとき、その学問は「sociology」(社会学)と呼ばれます。男性はpolicing(治安維持)を教え、女性はvictimology(被害者学)を教えます。
このことを検索の基盤として、直接は想像されないが性差別的である語句を検索するための興味深い方法が期待できます。これを、この自動記述著作の分野に適用すると興味深いと思います。ジェンダーレスなオートコレクトや偏見検出機能が考えられるし、形容詞をアルゴリズム的にシャッフルして次世代のためにジェンダーをなくし、ハーマイオニーが「geek」(おたく)、ハグリッドが「crabby」(すねている)、ハリーが「compassionate」(情け深い)になった、ジョージ・オーウェルっぽい児童文学シリーズも考えられます。
二元ではない単語
このようにして二元語を調べてみると、性差はゼロサムゲームだということがある程度示唆されます。ですから、他方の性に相当する語がない語について調べることには価値があります。
それを調べるための完璧な方法は私にはわかりませんが、例えば1つの方法として、まず、女性とされる単語を集め、その中からジェンダーがほとんど何の説明にもならない単語を探します。このセットの中で最も極端な例は、「thang」(発音綴り:thing)のジェンダーが女性とされていることです(そのことに関して何も言うことはありませんが、ほとんど使われていない言葉です)。ジェンダーをなくした空間内で最も近い単語を探してみると、「da」(発音綴り:the)が該当しますが、ジェンダーをなくした基軸によって調節しても、実際には、この2つの単語の差は 開きます 。ですから、ジェンダーをなくしても、ここでの特定の意味の説明にはほとんどなりません。 ^(4)
pairings %>%
filter(source_rank==) %>%
mutate(percent_explained_by_shift=round(*(genderless_similarity-true_similarity)/(-true_similarity),)) %>%
select(source,target,percent_explained_by_shift,true_similarity) %>%
arrange(percent_explained_by_shift) %>%() %>%as.tbl
## Source: local data frame [20 x 4]
##
## source target percent_explained_by_shift true_similarity
## (fctr) (fctr) (dbl) (dbl)
## 1 lolz imma -0.15616 0.2971851
## 2 playin writin -0.11033 0.3147785
## 3 durin willin -0.08365 0.3322802
## 4 gators tide -0.07049 0.2556017
## 5 somtimes techer -0.05738 0.3331312
## 6 emphasize express -0.05647 0.2745898
## 7 incessantly unprofessional -0.05188 0.3272740
## 8 kewl thas -0.05163 0.3443178
## 9 juss thas -0.04684 0.3771921
## 10 framed painted -0.02295 0.3018685
## 11 ridiculing attacks -0.01478 0.3922021
## 12 tryin willin -0.01051 0.3658269
## 13 ely absolutley -0.00001 0.3114403
## 14 awesum amazing 0.00185 0.3559082
## 15 avaible willin 0.00425 0.3173047
## 16 becuse techer 0.03276 0.3241463
## 17 relevance coincide 0.03963 0.2818240
## 18 duno imma 0.04630 0.2832912
## 19 imparting expressing 0.05099 0.3493221
## 20 mabe teacher 0.05150 0.2712957ここには多くのスラングがありますが、1つの著しい傾向も見られます。「unbalanced」(取り乱した)、「unprofessionally」(プロフェッショナルでない)、「invasive」(出しゃばった)、「unsafe」(信用できない)という多くの語が、ジェンダーのない空間ではすべて「inappropriate」(不適)に割り当てられますが、それらの語のジェンダーに関する偏見のほとんどは、これでは説明できません。言い換えれば、豊富な語に満ちた女性側の意味論領域からジェンダーの川を越えると、対岸の男性側にはこれらの語に相当する語がない、ということです。これを解釈すると、 学生は、「プロフェッショナルでない」ことを批判する語彙について、男性を批判するよりも女性を批判するためにはるかに精巧な語彙をもっている ^(5) とも言えるでしょう。
あまり明白ではありませんが、興味深いことに、女性側に「work」(作業)と「workloads」(作業負荷)があります。学生は、女性の教授に課される作業について不満を言います。これは、男性から与えられた作業負荷に対して他の語があるからではなく、女性が教えるクラスでの作業負荷の方が文句を言うに値するように見えるからです。
訳注: 原文 では「workload」「assignment」とジェンダーの関わりについて、インタラクティブSVG・静的画像(2015/12/01現在リンク切れ)・生データ・Bookwormクエリの4つの方式で閲覧できる箇所になっています。本ページにおいて忠実に再現できないため、 原文のページ での閲覧を推奨します。
次に、反対側からの対応する単語のセットを見ましょう。対応する女性版の単語がない男性的な単語です。これに関してはあまり言うことはありません。比較になるほど問題のある語はないと思います。
pairings %>%
filter(target_rank==) %>%
mutate(percent_explained_by_shift=round(*(genderless_similarity-true_similarity)/(-true_similarity),)) %>%
select(source,target,percent_explained_by_shift,true_similarity) %>%
arrange(percent_explained_by_shift) %>%() %>%as.tbl## Source: local data frame [20 x 4]
##
## source target percent_explained_by_shift true_similarity
## (fctr) (fctr) (dbl) (dbl)
## 1 coolest teachers -0.30119 0.3704935
## 2 achievements excelling -0.15700 0.2895593
## 3 demented appealed -0.10803 0.2065204
## 4 hi glade -0.06953 0.2479673
## 5 kewl theirs -0.06328 0.2231822
## 6 juss thas -0.04684 0.3771921
## 7 alows opprotunity -0.02921 0.2778482
## 8 deters prevented -0.02857 0.2500117
## 9 phds degree -0.01229 0.3619205
## 10 tryin willin -0.01051 0.3658269
## 11 cliches splices -0.01035 0.2624913
## 12 stores located -0.00748 0.2926399
## 13 interject express 0.00270 0.2746089
## 14 interject voiced 0.01097 0.3067609
## 15 furthered overcoming 0.02716 0.2688549
## 16 phds bachelors 0.04500 0.3636374
## 17 actualy elses 0.05142 0.2433585
## 18 wnat wor 0.05296 0.2137709
## 19 experiances opnion 0.05443 0.2817289
## 20 loudly peeve 0.05608 0.2279445ジェンダー二元語への回帰
では、この方法で、ジェンダー二元語が、ほとんどの人が考えるような形で排除されるでしょうか? そんなことはありません。
この方法で実際にできることは、テキスト解析の1つの分野として、ジェンダーに過剰なほどに固執することです。この観点から見たジェンダーのない世界が興味深い理由は、「ジェンダーのない世界を知ることで、ジェンダーのこと/ジェンダーというものの強さを知ることができる」ということです。「ジェンダーのない世界によって、好き勝手に強情な振る舞いが許される世界を利用できること」ではなく、「ジェンダーのない世界が、ジェンダーその物が果たす様々な役割を浮かび上がらせる」ということなのです。 この夏、Miriam Posnerは「ラディカル」なデジタルヒューマニティーズのための戦略を明確に示しました。この戦略は、受け継がれてきた抑圧的な規範構造の不快な重圧を弱めるために、洗練された絶対的な論理的枠組みを使用します 。ここでの戦略は、ある意味ではその逆で、優勢なDHのマルクスに対するフォイエルバッハのようなものです。重要なことは、世界を変えるのではなく、さまざまな方法で世界を理解することです。
ここでの実際の問題は、このような方法によって私たちが新しいことを理解できるという望みがあるのだろうか、ということです。[6^] この方法の前途には、あることが約束されています。私がずっと思うに、デジタルリーディングの魅力の1つは、ビッグデータや大規模なリーディングのレトリックではなく、いつかコンピュータが火星人のように文を読んでくれたり、私たちが見落とすようなことを何でも知っていて明確に伝えてくれたりするかも知れないという望みでした。ジェンダーは特に言語に深く刻み込まれているので、自分の表現と含意がどのようにジェンダーに影響されるのかについて誰もが十分敏感だとは思えません。データとしてのテキストに対する最も強力な反論は、豊富な経験がただの数字に格下げされることに対する反論です。でも、複雑に歪んだものが問題になって嫌になったら、経験をグリッドに合わせて留めてみるのも良い方法です。
-
正確には、オリジナルのword2vec Cコードを使った、約12の小文字で句読点のないウィンドウの500次元skip-gramモデルです。次に、いつも大文字で出現する単語は固有名詞であるとの仮定に基づいて、それらの単語を排除しました。 ↩
-
少なくとも、これが式
(1-genderless_similarity)/(1-true_similarity)を使って果たそうとしていることです。しかし、ラジアンで測定された2つの角度を互いに比較するために本当に正しい方法なのかはあまり深く考えてはいません。もし間違いがありましたら、三角法に詳しい方からのご指摘を頂きたいと思います。 ↩ -
こうしてステレオタイプを報告して、根絶やしにできることを願っています。この活動の一部分を不快に感じる人々がいらっしゃるかもしれないことは承知しています。お気づきの点がありましたら、ご指摘いただけると幸いです。 ↩
-
この操作はその上の操作の正確な逆操作ではなく、実際には、1つの単語が両方のリストにある場合もあります。 ↩
-
注意:このセンテンスをTwitterの文字数に収めるのに苦労しました。 ↩

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事