2014年11月20日
パイプとフィルタ ~ソフトウェア工学における有用なアーキテクチャ~
本記事は、原著者の許諾のもとに翻訳・掲載しております。
パイプライン は、最近のソフトウェアエンジニアリングにおいて、非常に便利な(そして驚くほど活用されていない)アーキテクチャパターンです。ソフトウェアでデータの流れを制御するためにパイプとフィルタを用いる考え方は、最初のUNIXシェルが作られた1970年代からあります。もしターミナルエミュレータでパイプ” | ”を使ったことがあるなら、”パイプとフィルタ”を活用できていることになります。以下の例を見てみましょう。
cat /usr/share/dict/words | # Read in the system's dictionary.
grep purple | # Find words containing 'purple'
awk '{print length($1), $1}' | # Count the letters in each word
sort -n | # Sort lines ("${length} ${word}")
tail -n 1 | # Take the last line of the input
cut -d " " -f 2 | # Take the second part of each line
cowsay -f tux # Put the resulting word into Tux's mouthこのパイプラインを bash で実行すると、LinuxのマスコットであるペンギンのTuxのASCIIアートが返され、辞書の中から”purple”を含む一番長い単語を言います。
_____________
< unimpurpled >
-------------
\
\
.--.
|o_o |
|:_/ |
// \ \
(| | )
/'\_ _/`\
\___)=(___/パイプラインのライフサイクル
実は、この数行のコードが実行されると、かなり多くのことが行われます。Enterキーを押した瞬間、以下のステップが走るのです。
- 7つ(7つも!)のプロセスがシェルにより直ちに生成されます。
- 各プロセスの標準入力(
stdin)および標準出力(stdout)のファイルディスクリプタは、シェル内部のバッファにリダイレクトされます(私のマシンでulimit –aを実行して確認すると 、それぞれのバッファサイズは512Byteです)。 - ソースのプロセスは、
catによりファイルから読み取りを開始し、stdoutへ出力します。データは最初のパイプを介して最初のバッファへ送られ、bashにより決められたバッファサイズの制限値に急速に到達します。この値に達するとすぐに、catはwrite(2)コールの途中でブロックされます。これこそがパイプラインの本領が発揮されるところです。catの実行は、パイプラインがデータをそれ以上扱えないことにより明示的に止められます。( コルーチン の考え方になじみがある人は、ここでは各プロセスはコルーチンのようなものとして動いていると考えてください)。 - 最初のフィルタ処理である
grepは、stdinパイプのread(2)コールにより開始されます。プロセスが生成された当初、パイプは空であり、データが読める状態になるまで処理全体が ブロックされます 。繰り返しになりますが、ここでもデータを扱えるかどうかに基づいて非明示的に実行制御が行われています。パイプラインで先行するコマンドによりバッファが埋められ、処理可能な状態に移るとすぐにgrepのread(2)コールに戻り、処理中のプロセスから読み込まれた行をフィルタできます。与えられたパターンに一致する全ての行はそのままgrepのstdoutに出力され、パイプラインの次のプログラムから使用可能になります。 awkはgrepと全く同じことを行いますが、バッファに対する動きだけが異なります。データが使用可能になると、awkは実行を再開してデータを処理し、その結果をstdoutに追加で書き込みます。データが使用できない場合はawkはブロックされて実行できません。sortは前述の2つのプロセスと少し異なった動きをします。ソート処理はデータ全体に対して行われなければならないため、sortはそれまでに受け取った入力全体の( ディスク上の )バッファを保持します
(後続のデータがあると、それまでに受け取ったデータのみをソートしたリストを出力しても意味がありません)。sortのstdinが 閉じられ ると、これ以上読み込むデータが無いことが分かるので、sortはすぐにstdoutに結果を出力できます。tailはデータ全体を受け取るまで一切stdoutに出力しないという点ではsortに似ています。この呼び出しは入力の最終行のみを対象とするため、巨大な内部バッファを保持する必要はありません。cutはgrepやawkと同様に、インクリメンタルに処理を行うフィルタです。cowsayはtailと同様に、処理を実行する前に全ての入力が受け取られるのを待ちます。入力データの長さに基づいて計算する必要があるからです(正し位置に合わせてASCIIアートを出力するのは簡単なことではありません)。
このタスクにパイプラインを使用するのは、非常に簡単なように思えます。ここで行われている全てのタスクはデータを フィルタリング しています。元のデータセットが各ステップで変更されています。各プロセスはそれぞれのはたらきをしており、 UNIX哲学 の教えを的確になぞらえています。どのプロセスも簡単に他のものと入れ替えることができるでしょう。
bashが自動的に行うパイプラインの機能を可視化すると、以下のようになります。

パフォーマンスと複雑性
パイプラインのもう1つの利点は、 本質的にパフォーマンスが優れている 点です。先ほど実行したコマンドの修正バージョンを使い、パイプライン中の各フィルタコンポーネントのメモリとCPUの使用量を見てみましょう。
/usr/bin/time -l cat /usr/share/dict/words 2> cat.time.txt |
/usr/bin/time -l grep purple 2> grep.time.txt |
/usr/bin/time -l awk '{print length($1), $1}' 2> awk.time.txt |
/usr/bin/time -l sort -n 2> sort.time.txt |
/usr/bin/time -l tail -n 1 2> tail.time.txt |
/usr/bin/time -l cut -d " " -f 2 2> cut.time.txt |
/usr/bin/time -l cowsay -f tux 2> cowsay.time.txt( 余談ですが 、私は自分のシェルに内蔵されている time コマンドの使用を避けるため、ここでは /usr/bin/time を呼び出しています。内蔵の time コマンドは詳しい統計を表示する -l オプションをサポートしていないのです。もしあなたがLinuxを使用しているのであれば、 -v オプションを使うといいでしょう。同じように統計を表示します。stdinがパイプを指した状態のまま、 2> (cat, grep他).time.txt の文で、 stderr をファイルにリダイレクトします)
このコマンドを実行し、最大常駐セットサイズと自発的及び非自発的コンテキストスイッチの回数を確認すると、重要なことがいくつか見えてきます。

- 1つのフィルタによるメモリの最大使用量は
cowsayの2,830,336バイトでした。cowsayがPerlで作成されているという事実がこの結果を生んでいます(Perlインタープリタを起動させるだけで1,126,400バイト使用します)。最小使用量はtailの389,120バイトでした。 - 元のソースファイル(
/usr/share/dict/words)のサイズは2.4MBでしたが、パイプライン中のほとんどのフィルタがそのメモリ量の5分の1も使っていません。パイプラインがメモリで 処理できるものだけを保存 するおかげで、このソリューションは非常にメモリ効率がよく軽量です。どんなサイズのファイルでも処理していたら、このソリューションによってメモリ使用量が変わることはなかったでしょう。パイプラインは 効率的に一定の空間 で実行しているのです。 - 最初の2つのプロセス、
catとgrepでは 自発的なコンテキストスイッチ が多数発生しています。つまり 入出力をブロック しているわけです。catはディスクからオリジナルファイルを読み取っている時にOS内で自発的にコンテキストを切り替え、stdoutパイプに書き出す時に再びコンテキストを切り替えなくてはなりません。grepはstdinパイプから読み取っている時とstdoutに書き出す時に自発的にコンテキストを切り替えなくてはなりません。awk、sort、tail、そしてcutでコンテキストスイッチの回数があまり多くないのは、扱うデータがさほど大きくないためです。grepが既にデータをフィルタしており、その結果、与えられたパターンと一致するのはたった12行です。これら12行は、1つのパイプのバッファに容易に収まります。 cowsayは 非自発的な コンテキストスイッチの回数が著しく多いようです。これは恐らく、 処理のタイムクォンタムが時間切れ になったことによって起こっているのでしょう。非常に短い時間で実行する他のプログラムに比べて、Perlで書かれているcowsayは実行までにCPU時間のうち約30ミリ秒かかることがその原因だと私は考えます。
この例に挙げているパイプラインは大変シンプルですが、これらのプロセスのどれか1つでも複雑な計算をしていたら、複数のプロセッサ上で 自動的に並列処理 することもできます。パイプラインってすごいでしょう?
エラー
確かにパイプラインは素晴らしいです。メモリやCPU時間を効率的に使用し、データのアベイラビリティに基づいて黙って自動的に実行のスケジューリングもします。また作成するのも非常に簡単です。なのに、できることならいつでも使いたいと思わないのはなぜでしょう?
答えは、 エラーハンドリング のせいです。パイプラインのどこか一部で間違いが起きたら、パイプライン全体が完全に機能しなくなります。
私がPythonで書いたコマンドを追加して、このパイプラインを試してみましょう。 fail.py は標準入力を標準出力にそのまま表示させますが、50パーセントの確率で行を読む前にクラッシュします。
cat /usr/share/dict/words | # Read in the system's dictionary.
grep purple | # Find words containing 'purple'
awk '{print length($1), $1}' | # Count the letters in each word
sort -n | # Sort lines ("${length} ${word}")
python fail.py | # Play Russian Roulette with our data!
tail -n 1 | # Take the last line of the input
cut -d " " -f 2 | # Take the second part of each line
cowsay -f tux # Put the resulting word into Tux's mouthfail.pyのソース:
import sys
import random
while True:
if random.choice([True, False]):
sys.exit(1)
line = sys.stdin.readline()
if not line:
break
sys.stdout.write(line)
sys.stdout.flush()この場合、何が起こるでしょうか? fail.py が入力を読んでいる途中で失敗すると、 stdin と stdout のパイプは閉じます。これによって パイプラインが半分に切断されます 。失敗したプロセスからさらに先へ行くと各プロセスがどうなるのかを見ていきましょう。
Pythonの直前のプロセスであるsortは、開かれたパイプの1つ(sort自身のstdout)が閉じたことを伝えるSIGPIPEシグナルをすぐに受け取ります。sortはこのSIGPIPEにすぐに対処することもできますし、write(2)をリトライすることもできます。ですがwrite(2)コールには結局、-1が返されるでしょう。sortはどこにも出力を書くことができず、 自分のstdinパイプを閉じて終了します。これによって、その前のプロセスに同じことが起こります。 次々にパイプがシャットダウン していくこの流れはパイプラインの最初のプロセスまでたどり着きます(もちろん、書き込みエラーがあったりSIGPIPEを受け取ったりした時にシャットダウンする 必要 はありませんが、これらのプロセスは出力パイプが閉じた時に他にできるふるまいがないのです)。Pythonの直後のプロセスであるtailもまた、自分のstdinパイプが閉じるとすぐにSIGPIPEシグナルを受け取ります。tailはハンドラでSIGPIPEを処理することもできますし、シグナルを無視することもできます。しかし、いずれにしても、次のread(2)コールにはエラーコードが返されるでしょう。この事象は、入力ストリームが済んだ時にtailがどの道受け取るストリームの最後を示す事象と 区別するのが困難 です。そのため、tailはこれを通常のストリームの最後を示す事象であると解釈し、予想通りのふるまいをするでしょう。cutもまた、ストリームが閉じると予想通りのふるまいをするでしょう。cowsayは、ストリームが閉じると予想通りのふるまいをし、Pythonの処理がクラッシュする前に受け取ったソートされたリストの最後の単語を表示するでしょう。
その結果は?
__________
< repurple >
----------
\
\
.--.
|o_o |
|:_/ |
// \ \
(| | )
/'\_ _/`\
\___)=(___/Tuxは先ほどのように”unimpurpled”と言っていません。間違っていますね。コマンドパイプラインの出力が 正しくないのです 。フィルタの1つがクラッシュしても反応が戻ってきて、その後のパイプラインの全てのステップが、尚も予想通りに実行されました。
さらに悪いことに、パイプラインのリターンコードを確認すると以下のようになります。
bash-3.2$ echo $?
0bashは親切にもパイプラインは 正常に実行された と報告しています。bashはパイプラインの 最後の プロセスの終了ステータスのみ報告するためです。パイプラインの中でより早く問題を見つけ出す唯一の方法は、比較的知られていないbashの$PIPESTATUS変数を確認することです。
bash-3.2$ echo ${PIPESTATUS[*]}
0 0 0 0 1 0 0 0この配列が、前の連結したパイプにおけるあらゆるプロセスのリターンコードを保存し、先ほどクラッシュしたフィルタはここでしか確認することができません。
これは従来のUNIXのパイプを使う上で大きな欠点の1つです。パイプラインがまだデータを処理している間にエラーを検知するには、何らかの形で失敗した処理を見つけ、他のプロセスにメッセージを送る 帯域外の シグナルが必要となります(1つのフィルタに対し複数の入力パイプがあればこれは簡単ですが、UNIXのパイプだけを使用していたら難しくなります)。
パイプラインのその他の利用法
良い感じです。ASCIIアートでペンギンを描くためのメモリ効率の良いパイプラインを作れます。でもこんな質問が聞こえてきそうです。
実際、パイプはどう便利なんですか?
Webアプリケーションにおいて、パイプを使うメリットは何でしょうか?
いい質問です。データを 非常に小さな塊 に分けられる場合や 処理を徐々に終わらせられる 場合は、パイプを使うと非常に便利です。例をいくつか挙げてみましょう。
例えば、とても高品質な音声フォーマットである.flacのファイルでいっぱいのフォルダがあるとしましょう。これらのファイルを自分のMP3プレイヤーに入れたいのですが、そのMP3プレイヤーは.flacをサポートしていません。そして、どういうわけかコンピュータは10MBのRAMしか使えないのです。ここでパイプラインを使ってみましょう。
ls *.flac |
while read song
do
flac -d "$song" --stdout |
lame -V2 - "$song".mp3
doneこのコマンドは今まで見てきたものよりも少し複雑ですね。まず、whileループの条件式にreadコマンドがある、ビルトインのbashコンストラクトを使っています。この条件式では、入力された各行を読み込み(lsの結果をパイプで送っています)、1行ごとに内部のコードを1回実行します。そして、内部のループでsongをデコードするためのflacを呼び出し、songをMP3にエンコードするためのlameを呼び出します。
このパイプラインはどのくらいメモリ効率が良いのでしょうか? このコードを115MBのflacファイルでいっぱいのフォルダに対して実行してみると、使用したメモリはたったの 1.3MB でした。
では、あるWebアプリケーションを利用するために、自分のお気に入りのWebフレームワークを使っているとしましょう。ユーザがそのWebアプリケーションにフォームをサブミットする場合、バックエンドでは非常にコストの高いプロセスを実行しなければなりません。フォームデータに対してはサニタイジングを行い、外部のAPIを使って検証し、PDFファイルとして保存する必要があります。これら全てのプロセスは重すぎるので、Webサーバでは実行できません( その通り、この例は少し不自然ですが、今まで私が見てきたユースケースから大きく外れてはいません )。ではここで、パイプラインを使ってみましょう。
my_webserver |
line_sanitizer |
verifier |
pdf_rendererユーザがmy_webserverにフォームをサブミットするとすぐ、stdoutにJSONの文字列を送ります。こんな感じの文字列です。
{"name": "Raymond Luxury Yacht", "organization": "Flying Circus"}パイプラインにおける次のプロセスのline_sanitizerでは、各行に対して以下のコードを実行します。
import sys
import json
for line in sys.stdin:
obj = json.loads(line)
if "Eric Idle" in obj['name']:
# Ignore forms submitted by Eric Idle.
continue
sys.stdout.write(line)
sys.stdout.flush()その次のプロセスではフォームから入力された組織が存在するかどうかを検証します。
import sys
import json
import requests
for line in sys.stdin:
obj = json.loads(line)
org = obj['organization']
resp = requests.get("http://does.it/exist", data=org)
if resp.response_code == 404:
continue
sys.stdout.write(line)
sys.stdout.flush()そして最後のプロセスでは、残った文字列をPDFファイルに書き込みます。
import sys
import json
import magical_pdf_writer_that_doesnt_exist as writer
for line in sys.stdin:
obj = json.loads(line)
writer.write_to_file(obj)これでお分かりかと思いますが、たった数行のコードで大量のデータを処理することが可能な、非常にメモリ効率の良い 非同期の パイプラインができました。
でも、この例では疑問が1つ残ります。もしエラーが発生したら、どう処理するのか? という疑問です。Eric IdleがこのWebサイトにフォームをサブミットしたとして、サイトがそのフォームを受け付けなかったら、どのようにエラーが通知されるのでしょうか? とてもUNIXっぽいやり方ですが、以下のように 名前付きパイプ を作ってエラー処理を行うという方法があります。
mkfifo errors # create a named pipe for our errors
my_webserver |
line_sanitizer 2> errors |
verifier 2> errors |
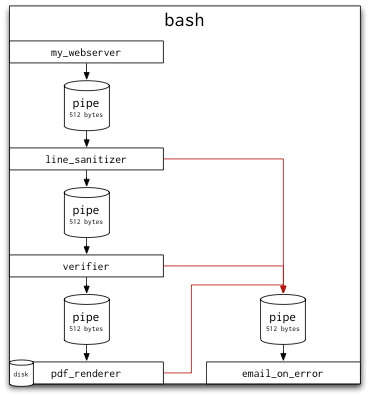
pdf_renderer 2> errorsどんなプロセスでもカスタマイズされたerrorという名前のパイプから読み込みが可能で、パイプラインの各プロセスはエラーになる入力値をパイプに出力します。エラーについての電子メールを送信するリーダを、そのパイプにつけることも可能です。
mkfifo errors # create a named pipe for our errors
email_on_error < errors & # add a reader to this pipe
my_webserver |
line_sanitizer 2> errors |
verifier 2> errors |
pdf_renderer 2> errorsそして、line_sanitizerが文字列に対してエラーを返す場合は、このように動きます。
import sys
import json
for line in sys.stdin:
obj = json.loads(line)
if "Eric Idle" in obj['name']:
sys.stderr.write(line)
sys.stderr.flush()
else: sys.stdout.write(line)
sys.stdout.flush()このパイプラインは、通常とは少し違いますね(赤線がstderrの出力を表します)。

分散型パイプライン
UNIXのパイプは便利ですが、もちろん欠点もあります。全てのソフトウェアがUNIXのパイプの枠組みを直接使えるわけではなく、最新式のWebトラフィックで見られるスループットにUNIXのパイプがうまく合うわけではないのです。しかし、違う方法が使えます。
マシン間で基本的なFIFOキューを使うことを可能にした、最新式の”ワークキュー”ソフトウェアパッケージが、ここ数年で次々と作られてきました。 beanstalkd や celery といったパッケージは、プロセス間で任意のワークキューを作成できます。これらのパッケージは従来のUNIXのパイプを簡単にシミュレート可能で、多くのマシンに分散されているという大きな利点もあるのです。一方で、非同期のタスク処理に極めて適しており、メッセージを送信しようとしているプロセスがキューによってブロックされることはありませんが、UNIXのパイプではできた暗黙の実行制御ができません。サービスは、コルーチンというよりも、メッセージングシステムやワークキューとして動いています。
そこで、同期性の欠如や分散型パイプラインシステムに対処するため、Redisベースで信頼性のある分散型同期パイプラインのライブラリを自分で作り、 pressure と名付けてみました。 pressure を使うと異なるプロセス間でパイプをセットアップすることが可能ですが、パイプのバッファを 保つ 機能と 複数のマシン間で 使える機能が加えられています。安定したメッセージブローカとしてRedisを使うことによって、このライブラリは全ての内部プロセスのコミュニケーションを処理し、 OSやプラットフォームに依存しない ものになりました(Redisには他にも、信頼性やレプリケーションといった数多くの役立つ機能があります)。
pressure のリファレンス実装はPythonにあり、まだ初期段階です。性能を見るため、この投稿の初めから使ってきたパイプラインの例を、 pressure のUNIXのパイプアダプタを使うことでレプリケートしてみましょう(putやgetは、従来のUNIXのパイプとRedisで保たれる分散型 pressure キューの間のブリッジとして動く、Cプログラムのコードです)。
# Read in the system's dictionary
cat /usr/share/dict/words | ./put test_1 &
# Find words containing 'purple'
./get test_1 | grep purple | ./put test_2 &
# Count the letters in each word
./get test_2 | awk '{print length($1), $1}' | ./put test_3 &
# Sort lines
./get test_3 | sort -n | ./put test_4 &
# Take the last line of the input
./get test_4 | tail -n 1 | ./put test_5 &
# Take the second part of each line
./get test_5 | cut -d " " -f 2 | ./put test_6 &
# Put the resulting word into Tux's mouth
./get test_6 | cowsay -f tux最初の注意点は、このメソッドにおいては何メガバイトものファイルをフィルタリングしているので、 極めて 重い処理になるということです。最終的には235,912メッセージをRedisで送ることになり、処理に4分ほどかかります(catのすぐ後、かつRedisにデータを送る前にgrepを実行する場合は、この1,200倍よりも速い処理速度となります)。どうであれ、最終的には、求めている正しい答えが得られます。
_____________
< unimpurpled >
-------------
\
\
.--.
|o_o |
|:_/ |
// \ \
(| | )
/'\_ _/`\
\___)=(___/しかし、Redisのコマンドラインツールであるredis-cliを実行してみると、妙なプロパティが見られる場合があります。大量のデータ入力をしているにもかかわらず、パイプラインでは非常に少ないメモリしか使われていないことになっているのです。
$ redis-cli info | grep memory
used_memory:3126928
used_memory_human:2.98M
used_memory_rss:2850816
used_memory_peak:3127664
used_memory_peak_human:2.98M
used_memory_lua:31744pressure はまだアルファ版であり、広範囲に渡る製品デプロイメントには間違いなく 時期尚早 です。とは言っても、ぜひ 使ってみて ください。
ソフトウェアにおいてパイプラインは、リソースの使用量を低減させる手段になり得る、非常に便利なツールです。パイプラインは必要時に演算をするためだけに コルーチン として動き、リアルタイムのオーディオ処理のような特定のアプリケーションにとっては極めて重要なツールになります。 pressure は複数のマシンで信頼性を持ってパイプラインを簡単に使う方法を提供します。ソフトウェアアーキテクチャの問題を解決するためにパイプとフィルタの枠組みを使い、これがどんなに簡単で効果的なものかを体験してみてください。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事