2014年12月1日
機械学習とNode.jsを使用してInstagramユーザの性別を知る
(2014-09-25)by Stanislas Polu
本記事は、原著者の許諾のもとに翻訳・掲載しております。
この記事の目的は、機械学習ソリューションを大規模に展開するための実用的なガイドを提供することです。全てのものが正しいと立証されたわけでもありませんし、また最適であるとも限りません。私たちが実際に展開した際には、いくつかのトレードオフもありました。アカデミックな環境であれば必要とされるであろうあらゆる論拠の積み上げを必ずしも行うことなく、随時簡便な方法で済ませたところもあり、それについてはおわびします。そのような箇所は投稿を通じて明確に示しながらも、この記事が皆さんの役に立つことを願っています。
少し背景から説明します。TOTEMS AnalyticsはInstagramの(ハッシュタグと関連のあるオーディエンスやコミュニティの)解析を行います。この1年で、Instagramのオーディエンスに関する統計情報への需要はかつてないほどクライアントから寄せられています。そこで私たちは6カ月前、プラットフォーム上に見つけられるソーシャルシグナルに基づく性別分類器を構築することに時間を費やそうと決めました。(InstagramはAPIでユーザの統計情報を公開していません)。プロジェクトには2人月の工数をかけました。名前の抽出や人口調査といった基本的な方法を試したあと(成功率は0.65にとどまり、ランダムな分類の成功率0.5をかろうじて上回る程度でした)。私たちは、比較的シンプルなニューラルネットワークアプローチを思い付きました。これによりクライアントに、他のどこにも見つけることができない独自の情報を提供できます。そして、この実装方法をシェアすることにより、皆さんもシンプルな機械学習の技術を活用して、自分でクライアントおよびユーザのエクスペリエンスを強化し、差別化できるだろうと私たちは考えたのです。
制約事項
私たちのプラットフォームは1秒につきおよそ400ユーザのプロフィールを読み出したり、リフレッシュしたりします(これはAWSを利用したInstagramのAPIサーバにコロケーションされている4台の高帯域サーバで管理されています)。受信したプロフィールは断片化されたMySQLテーブルに格納され、オーディエンス(フォローする人とされる人の関係)およびコミュニティ(特定のハッシュタグへの貢献者)に関する集約された情報を計算します。これにより、私たちが作ろうとしている性別分類器の必須条件は次のようになりました。
- リアルタイム分類: 扱うデータ量は既に把握しており、プロフィールを処理するために必要とされるサーバ容量を急激に増やさないようにすることは、分類器にとって重要なことでした。
- 成功率0.9超: 私たちの最初の目標値でした。この値は全く任意で決めたものでしたが、この程度の成功率の分類器で計算された集約データは、全てのクライアントに満足のいくものであり、最初の指標として十分であると考えました。
訓練データセット
訓練全体を通して、おそらくこれが最も重要な部分です。分類器を作成する際、元々足りていないデータを導き出したいという場合が見受けられます。しかし、訓練データセットとして使うためには、適切に分類された、かなり大きなデータセットが必要です。私たちの場合、Instagramアカウントの莫大な人口の性別を判定する必要がありました。私たちはこの性別情報が他のプラットフォーム上で簡単に入手可能であることが分かっていました。特にほとんどのユーザが自分の性別を公開しているFacebook[1] などがそうです。FacebookのURLを含む(たくさんありました)Instagramのプロフィールに絞ることで事態は進展しました。
私たちは、適切なFacebookプロフィールへのURLではないものを除外するために、数行の単純な正規表現を書き、目に留まるユーザID全てを調べました。そして、妥当な場合は、更にその人たちのフォロワーまでも確認しました。数億のInstagramユーザ(当時のユーザ基盤の大半でした)を検証した結果、私たちは、関連がある場合はいつでもInstagramのユーザ名とFacebookプロフィールの連携を抽出することができました。次のステップでは、情報が利用できる場合にFacebookの性別情報を抜き出します。57万件のプロフィールを訓練データセットとしました。
適切な入力シグナルの抽出
ニューラルネットワークを構築する前に、どの入力シグナルを使用するかについて理解を深める必要がありました。以下のようなアプローチが私たちの目的に適していると考えられました。
- ユーザからの投稿のキャプションや自己紹介やフルネームの全単語
- ユーザからの投稿のキャプションや自己紹介やフルネームのN-gram
ここでの大きな問題は、入力シグナルのスペースが非常に大きく(全てのN-gram一式、もしくは全単語一式)、全てのプロフィールに合う(ほとんどの分類器から求められる)一貫した固定サイズの入力ベクトルをデザインするのが困難である点です。
この問題に対する興味深いソリューションは、相互情報量を頼りに入力スペースを整え[2]、性の確率変数を使って相互情報量[3]が上位N個のN-gramもしくは全単語を選ぶことです。直観的に、2つの確率変数間の相互情報量は、この2つの変数のうちの1つが分かっていればもう一方についての不確実性をどれだけ減らせるかを測ります。以下のように相互情報量を計算しました。
/**********************************************************************/
/* count_: the number of occurrences of the feature (n-gram or word) */
/* all_count: training set size */
/* f_count_: the number of occurrences of `feature & female` */
/* m_count_: the number of occurrences of `feature & male` */
/* all_count_f: number of occurrences of `female` */
/* all_count_m: number of occurrences of `male` */
/**********************************************************************/
/* p(feature) */
double p_ = (double)count_ / all_count;
/* p(feature & gender) */
double p_feature_f = (double)f_count_ / all_count;
double p_feature_m = (double)m_count_ / all_count;
/* mutual information */
mi_ = p_feature_f * log(max(p_feature_f, 0.001) / (((double)all_count_f / all_count) * p_)) +
p_feature_m * log(max(p_feature_m, 0.001) / (((double)all_count_m / all_count) * p_));
/* p(gender|feature) */
p_f_c_ = p_feature_f / p_;
p_m_c_ = p_feature_m / p_;訓練データセットに含まれるユーザからの最近の投稿のキャプションに使用されたハッシュタグと全単語、N-gramを抽出し、上記の計算を実行しました。
好奇心から、使用されたハッシュタグを基に女性として分類される条件付き確率に従ってハッシュタグを並べました。これらは女性ユーザと最も関連性の強いハッシュタグです。
TOP WOMENs WORDS [P(F|feat)]
┌─────────────────┬────────────────────────┬────────────────────┬─────────────────────┬────────┐
│ feat │ MI │ P(F|feat) │ P(M|feat) │ count │
├─────────────────┼────────────────────────┼────────────────────┼─────────────────────┼────────┤
│ obrigada │ 0.00027892588535643266 │ 0.9685880320402072 │ 0.03141196795979268 │ 6367 │
│ nails │ 0.0005797362527263134 │ 0.9323099021456146 │ 0.0676900978543855 │ 22278 │
│ nail │ 0.0003044173746727099 │ 0.9318902523093892 │ 0.06810974769061078 │ 7253 │
│ lipstick │ 0.00027485524057785637 │ 0.9307852898667095 │ 0.0692147101332905 │ 6227 │
│ nomakeup │ 0.00027682050785528235 │ 0.9210108073744437 │ 0.07898919262555626 │ 6292 │
│ girly │ 0.00027218400694593495 │ 0.9180381293791755 │ 0.08196187062082451 │ 6137 │
│ curls │ 0.0002435655460170567 │ 0.8963601532567049 │ 0.103639846743295 │ 5220 │
│ brunette │ 0.00028464803178129177 │ 0.8939740655987796 │ 0.10602593440122045 │ 6555 │
│ makeup │ 0.0005653528345263387 │ 0.8796942505815887 │ 0.12030574941841143 │ 21063 │
│ curly │ 0.0002803670622783461 │ 0.8796816479400749 │ 0.1203183520599251 │ 6408 │
├─────────────────┼────────────────────────┼────────────────────┼─────────────────────┼────────┤男性ユーザと最も関連性の強いハッシュタグも計算しました。
TOP MENs WORDS [P(M|feat)]
┌───────────────────┬────────────────────────┬─────────────────────┬─────────────────────┬─────────┐
│ feat │ MI │ P(F|feat) │ P(M|feat) │ count │
├───────────────────┼────────────────────────┼─────────────────────┼─────────────────────┼─────────┤
│ instagay │ 0.00022357298801020352 │ 0.08653846153846154 │ 0.9134615384615384 │ 4576 │
│ instaboy │ 0.00028438645833364835 │ 0.11872780608306316 │ 0.8812721939169369 │ 6477 │
│ beard │ 0.00023996501077783796 │ 0.13137099960489926 │ 0.8686290003951008 │ 5062 │
│ bmw │ 0.00023463541132113985 │ 0.17349643221202854 │ 0.8265035677879714 │ 4905 │
│ ps3 │ 0.00024576041454740495 │ 0.17954588818927686 │ 0.8204541118107231 │ 5241 │
│ legend │ 0.000242332533506523 │ 0.2024133904242896 │ 0.7975866095757104 │ 5138 │
│ obrigado │ 0.0003176356382986596 │ 0.2052521557355631 │ 0.7947478442644369 │ 7654 │
│ nba │ 0.00027535078270119487 │ 0.21474773609314357 │ 0.7852522639068563 │ 6184 │
│ polo │ 0.00021974648596766796 │ 0.2204337133914599 │ 0.7795662866085402 │ 4473 │
│ champions │ 0.00023537731520623432 │ 0.22271805273833672 │ 0.7772819472616632 │ 4930 │
├───────────────────┼────────────────────────┼─────────────────────┼─────────────────────┼─────────┤最後に、男性と女性のどちらからも使われる上位のハッシュタグ1万個を生成しました。
┌───────────────────┬────────────────────────┬─────────────────────┬─────────────────────┬────────┐
│ feat │ MI │ P(F|feat) │ P(M|feat) │ count │
├───────────────────┼────────────────────────┼─────────────────────┼─────────────────────┼────────┤
│ 2013 │ 0.0007369516096940501 │ 0.4390515775552617 │ 0.5609484224447384 │ 52930 │
│ some │ 0.000736858500749544 │ 0.445240713107673 │ 0.5547592868923271 │ 50932 │
│ old │ 0.0007365194018360236 │ 0.4566446562018109 │ 0.5433553437981891 │ 50582 │
│ followme │ 0.0007364834465793508 │ 0.4685242121445043 │ 0.5314757878554958 │ 52040 │
│ em │ 0.0007364028645929781 │ 0.47138620491724864 │ 0.5286137950827514 │ 52265 │
│ 1 │ 0.0007363022436669361 │ 0.47312624679395837 │ 0.5268737532060416 │ 52635 │
│ picoftheday │ 0.000736169463191504 │ 0.41519248894366706 │ 0.5848075110563329 │ 55172 │
│ para │ 0.0007359991588507289 │ 0.4798029186098992 │ 0.5201970813901008 │ 53176 │
│ dog │ 0.0007357796669777269 │ 0.5020947036666923 │ 0.4979052963333077 │ 52036 │
│ here │ 0.0007356472568846146 │ 0.5000987673830595 │ 0.49990123261694064 │ 50624 │
├───────────────────┼────────────────────────┼─────────────────────┼─────────────────────┼────────┤このリストを使って、ユーザが最近投稿したキャプションの中で男性と女性のどちらからもよく使われるハッシュタグがあるか(ないか)を示している、任意サイズ(1k, 2k, 4k, 10k)で固定サイズのバイナリ入力ベクトルが生成できました。この作業をN-gramと全単語で繰り返し、どちらの入力シグナルがより効率的かはニューラルネットワークを構築してから評価することにしました。
直観的に、男性か女性かの条件付き確率は、相互情報量よりも効果的な指標であるように見えますが(これらのリストは確かにそれを良く表しています)、相互情報量は特徴を見つける確率を考慮に入れています(男性と女性のどちらからも使われる上位の単語が、いかに条件付き確率によって分類された単語よりも確率が高く、回数がはるかに大きいかを見てください)。つまり、関連が高いが確率が低い単語よりも、関連が低くて確率がはるかに高い単語を分類器が持っている方がより効率的なのです。前者はユーザの分類には全く役に立たないでしょう。
Node.jsを使ったニューラルネットワークの構築
私たちは評判の良いレファレンス[4][5]に基づき、Node.jsを使って独自のニューラルネットワークを実装しました。小さな訓練データセットから始め、Javascriptのガベージコレクタの限界に達する(あまりに頻繁に止まってしまう)までサイズを徐々に増やしていき、C++でNode.jsのネイティブアドオンとしてリライトしました(こちらから利用可能です: https://github.com/totemstech/neuraln )。
ニューラルネットワークは複数の層で構成された図です。第1層は分類されるべき入力ベクトル値に設定されます。ここで入力ベクトル値に当たるのは、ユーザの最近の投稿において男性と女性のどちらからも使われる上位N個のハッシュタグやN-gramです。それぞれの層は重みの値によって他の層とリンクしていて、1つの層にあるノードはどれも次の層の全ノードとリンクしています。入力層と出力層の間には複数の層があることがあり、これらを中間層といいます。最後に、外層は出力ベクトルを表しますが、出力ベクトルのサイズは導き出される値に依存しています。
そのためニューラルネットワークは、その層構造から”layers_[l]”(各層にあるノードの数)と定義され、各層の間の重みの値は”W_[l][i][j]”と定義されます。他のメンバは割愛しますが、ニューラルネットワークはまさにこのようにして定義されるのです。
//
// ## NN Class
//
class NN : public ObjectWrap {
/* ... */
vector<int> layers_; /* layers structure */
vector< vector< vector<double> > > W_; /* weights */
/* ... */
};また、ネットワーク内の各ノードは、その活性化関数によって定義されます。この関数は、ノードが前の層から受け取った入力の合計を踏まえて、次の層に出力するものを定義します。これは入力ベクトルによって値が設定されている入力層を除く全ての層に当てはまります。私たちは実装においてノードの活性化関数のために以下のコードを使用します。
for(int j = 0; j < layers_[l-1]; j++) {
sum_[l][i] += W_[l][i][j] * val_[l-1][j];
}
/* Activation function */
val_[l][i] = 1 / (1 + exp(-sum_[l][i]));ニューラルネットワークを表す適切なデータ構造ができたので、訓練できるようにする必要があります。私たちが類型化したネットワークはフィードフォワード型ネットワークで、値は各ノードで次の層にフィードする活性化関数を使いながら、重みに従って入力ベクトルから出力ベクトルへ伝搬されます。そうしたネットワークの訓練はバックプロパゲーション[6]に依存しています。
バックプロパゲーションそのものは、1回のブログ投稿[7]に相当し、書籍[4]で非常に良く説明されていますので、詳しく理解したいという方は参照されることをお勧めします。覚えておくべきことは、バックプロパゲーションは、エラー(出力された値と訓練データセットから期待されている値の違い)をネットワークの勾配に従って伝搬することによって、ニューラルネットワークの重みの更新を可能にするということです。ところで、その勾配を計算するには活性化関数が微分可能である必要があります。バックプロパゲーションは1970年に発明されましたが、やっと実用化されたのは1986年で、ニューラルネットワークのより幅広い使用が可能になりました。それ以来、ニューラルネットワークの訓練において信頼の置けるソリューションとなりました。
バックプロパゲーションを使用することで、私たちは訓練データセットの要素を繰り返し、望ましい値に達するまでエラー率を減らすことができます。私たちは実装において、計算された出力”res”と、期待されていた出力”train[i]”の間にある二次エラーの合計を計算し、訓練データセット全体を通して平均化します。この計算は、独立引数として通用する目標値”error”に達するまで繰り返されます。
do {
err = 0;
for(unsigned int i = 0; i < train_in_.size(); i++) {
vector<double> res = this->learn(train_in_[i], train_out_[i]);
/* error calculation */
double e = 0;
for(unsigned int j = 0; j < res.size(); j++) {
e += pow(res[j] - train_out_[i][j], 2);
}
err += e / res.size();
}
err /= train_in_.size();
it++;
if(log_) {
cout << "[" << it << "] " << err << endl;
}
} while(err > error && it < iterations);最善の入力シグナルの選択
機能的なニューラルネットワークと訓練アルゴリズムが揃ったので、次のステップは異なるネットワーク構造と入力シグナルをテストして、最も期待できるシグナルを見つけることでした。以下は、最初の結果です。
- 「Type」は、入力タイプ(N-gram、単語、またはハッシュタグ)で、ユーザの最近の投稿のキャプションから取得したものです(初期の結果では、[2]の結果とは異なり、自己紹介やフルネームの使用がより良い結果をもたらすことはないと分かりました)。
- 「L1,L2,L3」は、ネットワーク構造、つまり各層のサイズです。ここでは2層から3層までのネットワークに制限しました。「L1」は入力ベクトルのサイズも示します。これは、先ほど説明したとおり、特徴と最善の相互情報量を使用して算出したものです。
- 「Cov」は訓練データセットの各要素で見つかった特徴の平均数と同じ指標値です(一致する単語/N-gram/ハッシュタグの数の平均)。
- 「Err」は訓練の目標エラー率です(過度に低い値を設定すると、ネットワークがオーバーフィットする、つまり訓練データセットに限定し過ぎることになります)。
- 「Train」は訓練データセットのサイズです。
- 「It」は目標エラー率に達するために必要な訓練データセットの反復回数です。
- 「Res」はテストセットの成功率です(通常、訓練データセットのサイズの10%)。ここで基準値は0ではなく0.5であることを覚えておく必要があります。個人のランダムな集合に対して性別分類を行うために、0.5まではランダムな関数が実行されることが予想されます。
Type, L1, L2, L3, Cov, Err, Train, It, Res
--------------------------------------------------------
hashtags, 1000, 10, 2, -, 0.05, 2000, -, 0.73
hashtags, 1000, -, 2, -, 0.05, 2000, -, 0.73
hashtags, 1000, 50, 2, -, 0.05, 10000, -, 0.75
hashtags, 2000, 50, 2, -, 0.03, 10000, -, 0.78
hashtags, 1000, 50, 2, -, 0.03, 10000, -, 0.76
hashtags, 4000, -, 2, 47.44, 0.05, 10000, 4, 0.78
words, 4000, -, 2, 34.82, 0.03, 4000, 2, 0.75
words, 2000, 50, 2, 27.66, 0.03, 10000, 135, 0.75
hashtags, 2000, 50, 1, 40.39, 0.05, 10000, 80, 0.78
hashtags, 4000, 50, 1, 48.95, 0.05, 10000, 54, 0.78
words, 2000, 50, 1, 29.23, 0.05, 10000, 77, 0.74
words, 4000, 50, 1, 37.45, 0.05, 10000, 45, 0.78
ngrams, 2000, 50, 1, 103.6, 0.05, 10000, 182, 0.74
ngrams, 4000, 50, 1, 157.8, 0.05, 10000, 67, 0.77
hashtags, 2000, 50, 1, 59.2, 0.1, 100000, 73, 0.76
ngrams, 2000, 50, 1, 363.3, 0.1, 100000, 742, 0.76
hashtags, 10000, 50, 1, 114.8, 0.05, 100000, 122, 0.82
hashtags, 10000, -, 1, 67.2, 0.05, 10000, 13, 0.75
ngrams, 10000, -, 1, 445.2, 0.05, 10000, 103, 0.76 ここで注目されるのは、中間層(パーセプトロンと言います)のないネットワークは線型分類器であることです。その予測は、入力された特徴のシンプルな線形結合に基づきます。これらのネットワークがエンコードするモデルの単純さを考えると、その効率の良さに大変驚かされました。
一番良い結果は、1つの隠れ層(中間層)を持つネットワークから得られました。この結果から、大きい(10k)ハッシュタグベースの入力ベクトルを使用することで最善の結果を得られるだろうと私たちは推測しました。特に、より大きい訓練データセットを使用できるならなお更です。
微調整と結果
私たちは200k要素の訓練データセットを使っていくつかのネットワークを訓練することができました。このような大きいデータセットの訓練は、私たちが用意したサーバで最大5時間かかるため、そのプロセスは極めて苦痛になっていきました。200k要素の訓練データセットを使用しながら、私たちは成功率を0.83まで高めることができました。
最後に、ブースティング[8]からヒントを得て、それぞれ200k要素を持つ2つの全く異なる訓練データセットを使って男性ネットワークおよび女性ネットワークの訓練実験を行いました。そして両方のネットワークを使って、指定された入力に強い反応を示した方のネットワークを選択することで分類しました。これは、ここで説明してきた非広範な実験的アプローチ以外の何にも根差さない、純粋に使用可能なソリューションです。しかし私たちにとっては、これが一番うまくいきました。このテクニックを使って、70k要素のテストセットで最初の目標値に近い0.88という成功率を達成することができたのです。
ライブラリにシリアライゼーション(「to_string」)とデシリアライゼーション(コンストラクタ)関数を追加して、生成された分類器を製品に組み込みました。フィードフォワード式ニューラルネットワークの性質として優れているのは、ネットワークがメモリに読み込まれてしまえば、分類は非常に高速に行われることです。インフラストラクチャに分類器を追加しても、集約サーバの読み込みに明白な影響はありませんでした。
生成されたニューラルネットワークの分析
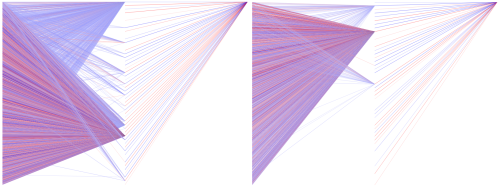
この投稿を準備するにあたって、ネットワークの構造を視覚化するために、ニューラルネットワークのシリアライズされたフォーマットをSVGで表すためのスクリプトをいくつか追加しました。これらのスクリプトを、この数カ月使用してきた作成中のネットワーク(男性および女性)で実行してみました。
この可視化の結果を以下に示します(クリックすると拡大します)。「重い」リンク、つまり0.8を超える絶対重量を持つリンクのみを表示しています。正の重量は青の線で、負の重量は赤の線で示されています。リンクが重くなるほど、色が濃くなります(半透明のリンクは0.8に近く、それ以外は絶対重量より重いリンクです)。

結果として現れた構造のシンプルさには驚きましたが、ここに表示されていない低重量のリンクが重要な役割を果たしている可能性に気付きました。特に、この図に進入リンクを持たない一定数の中間層ノードが重要な出力リンクを持っていると思えるからです。
別の驚くべき側面は、2つのネットワークの類似性です。どちらも主に、結果に正の影響を与える中間層ノードをフィードする正のコンポーネントを持っています。そして、正と負の混合コンポーネントは結果に負の影響を与える中間層をフィードします。前者のコンポーネントは推進因子の役割を果たし、後者のコンポーネントは阻害因子の役割を果たしているようです。
まとめ
作成中の機械学習ソリューションを展開する私たちの実験について説明してきましたが、これが、オンラインや教科書で公開されている多数の理論的リソースを解説する、有益な実例として役立つことを願っています。このニューラルネットワークを構築して訓練するために使用し、現在TOTEMSで使用されているコードは、当社のGitHubアカウント: https://github.com/totemstech/neuraln でオープンソースとして公開されています。純粋なJavaScriptネットワークの実装でC++実装のスピードが足りないという製作状況で役立てていただければと思います。
-stan
[1] Facebook Graph API https://developers.facebook.com/docs/graph-api/reference/v2.1/user
[2] Dicriminating gender on Twitter – The MITRE Corporation https://www.mitre.org/sites/default/files/pdf/11_0170.pdf
[3] 相互情報量 – ウィキペディア http://ja.wikipedia.org/wiki/%E7%9B%B8%E4%BA%92%E6%83%85%E5%A0%B1%E9%87%8F
[4] Artificial Intelligence: A Modern Approach – S.Russel, P.Norvig http://www.amazon.com/Artificial-Intelligence-Modern-Approach-Edition/dp/0136042597
[5] Brain.js – @hartur https://github.com/harthur/brain
[6] バックプロパゲーション– ウィキペディア http://ja.wikipedia.org/wiki/%E3%83%90%E3%83%83%E3%82%AF%E3%83%97%E3%83%AD%E3%83%91%E3%82%B2%E3%83%BC%E3%82%B7%E3%83%A7%E3%83%B3
[7] How the backpropagation algorithm works – M.Nielsen http://neuralnetworksanddeeplearning.com/chap2.html
[8] ブースティング(機械学習)– ウィキペディア http://ja.wikipedia.org/wiki/%E3%83%96%E3%83%BC%E3%82%B9%E3%83%86%E3%82%A3%E3%83%B3%E3%82%B0)

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事