2016年2月10日
C++11のスレッド、アフィニティ、ハイパースレッディング

(2016-01-17)by Eli Bendersky
本記事は、原著者の許諾のもとに翻訳・掲載しております。
背景と導入
何十年もの間、CやC++の標準規格は、マルチスレッディングや並行処理を「その標準の範囲を超えたもの」として扱ってきました。標準規格の目的である”抽象機械”の力が及ばない、”対象依存”という影の世界においてです。メーリングリストやニュースグループの質問には並行処理に関するものが山ほど寄せられましたが、それらにすぐに突き返された回答は「C++はスレッドには関知しません」という何とも冷淡なものでした。この件によって当時のことを思い出す人々は、今後も絶えないでしょう。
しかしC++11の登場で、そんな状況に終止符が打たれたのです。C++標準化委員会は、時代の流れに乗らないと、この先C言語が取り残されてしまうと悟ったのでしょう。彼らはスレッドや同期メカニズム、アトミック操作、メモリモデルなどの存在に、ようやく気付いたわけです。そして標準規格として、C++コンパイラやライブラリのベンダーに、それらの機能を全対応プラットフォーム向けに実装させました。これはC++11というバージョンにおける数々の改善点の中でも、とりわけ重要で、そして前向きな変化の1つだと私は見ています。
なお、本稿はC++11のスレッドのチュートリアルではありませんが、主なスレッディングの仕組みについて要点を説明するため、C++11のスレッドを使用します。まずは基本的な例から始めますが、途中から一気に専門的な内容に入り、スレッドアフィニティやハードウェア・トポロジ、ハイパースレッディングのパフォーマンス予測といった内容を扱います。ポータブルなC++についても可能な範囲で触れますが、こちらは本筋からそれてプラットフォーム固有の内容になるので、かなり専門的な知識が必要になります。
論理CPU、コア、スレッド
最近のマシンは、ほとんどがマルチCPUです。もちろんCPUソケットが複数あったり、ハードウェアのコアがマシンに依存していたりはしますが、OS側ではタスクを並行処理できる”論理”CPUの数を把握しています。
この情報をLinuxで取得するには、 cat /proc/cpuinfo というコマンドを使うのが最も簡単な方法です。こうすると、システムのCPUが順番で一覧表示され、各CPUの情報(現在の周波数やキャッシュサイズなど)が分かります。私のマシン(8-CPU)では以下のような情報が得られます。
$ cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 60
model name : Intel(R) Core(TM) i7-4771 CPU @ 3.50GHz
[...]
stepping : 3
microcode : 0x7
cpu MHz : 3501.000
cache size : 8192 KB
physical id : 0
siblings : 8
core id : 0
cpu cores : 4
apicid : 0
[...]
processor : 1
vendor_id : GenuineIntel
cpu family : 6
[...]
[...]
processor : 7
vendor_id : GenuineIntel
cpu family : 6 lscpu を使うと、整理された結果が出力されます。
$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 8
On-line CPU(s) list: 0-7
Thread(s) per core: 2
Core(s) per socket: 4
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 60
Stepping: 3
CPU MHz: 3501.000
BogoMIPS: 6984.09
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 8192K
NUMA node0 CPU(s): 0-7上の結果からも、このマシンにはコアが4つあり、各コアには2つのハードウェアスレッドがあること(詳細は ハイパースレッディング・テクノロジー の説明をご覧ください)が簡単に分かります。でもOS側には、0から7までの8つの”CPU”があるように見えているのです。
各CPUでスレッドを1つ起動する
C++11のスレッドライブラリで提供されるユーティリティ関数を使うと、マシンのCPU数が分かり、並列化の方針を決めることができます。その hardware_concurrency という関数を利用して、適切な数のスレッドを起動する例を以下に示します。なお、ここに載せているのはコードの一部だけです。本稿で使用しているコードサンプル一式とLinux用のMakefileは、 こちらのリポジトリ から入手できます。
int main(int argc, const char** argv) {
unsigned num_cpus = std::thread::hardware_concurrency();
std::cout << "Launching " << num_cpus << " threads\n";
// A mutex ensures orderly access to std::cout from multiple threads.
std::mutex iomutex;
std::vector<std::thread> threads(num_cpus);
for (unsigned i = 0; i < num_cpus; ++i) {
threads[i] = std::thread([&iomutex, i] {
{
// Use a lexical scope and lock_guard to safely lock the mutex only for
// the duration of std::cout usage.
std::lock_guard<std::mutex> iolock(iomutex);
std::cout << "Thread #" << i << " is running\n";
}
// Simulate important work done by the tread by sleeping for a bit...
std::this_thread::sleep_for(std::chrono::milliseconds(200));
});
}
for (auto& t : threads) {
t.join();
}
return 0;
} std::thread は、プラットフォーム固有のスレッドオブジェクトに使う薄いラッパーです。これは、もう少し後で活用します。まず std::thread を起動すると、実際のOSスレッドが立ち上がります。かなり低水準のスレッド制御ですが、本稿ではタスクベースの並列処理を扱うような回り道はしません。そういった高水準の概念ついては、またいつか別の記事で紹介することにしましょう。
スレッドアフィニティ
ここまで、システムにCPU数をクエリする方法と、任意の数のスレッドを起動する方法を学びました。では、次にもう少し高度な内容を見ていきましょう。
最近のOSはどれも、スレッドごとにCPUアフィニティの設定ができます。アフィニティとは、どのCPU上でも自由にスレッドを実行させるのではなく、1つまたは事前に定義された複数のCPU上でスレッドを実行するよう、OSのスケジューラ側にスケジューリングをさせることです。デフォルトでは、システム上にあるすべての論理CPUがアフィニティの対象になります。そのためOSは、スケジューリングを考慮した上で、任意のスレッドに対して任意のCPUを選択できます。さらにスケジューラに支障がなければ、OSはスレッドをCPU間で移動させる場合があります(これにより、スレッドの移動元のコアに存在するウォームアップされたキャッシュが失われるため、OSはスレッドの移動を最小限に抑えようとします)。では、この動きを別のサンプルコードで見てみましょう。
int main(int argc, const char** argv) {
constexpr unsigned num_threads = 4;
// A mutex ensures orderly access to std::cout from multiple threads.
std::mutex iomutex;
std::vector<std::thread> threads(num_threads);
for (unsigned i = 0; i < num_threads; ++i) {
threads[i] = std::thread([&iomutex, i] {
while (1) {
{
// Use a lexical scope and lock_guard to safely lock the mutex only
// for the duration of std::cout usage.
std::lock_guard<std::mutex> iolock(iomutex);
std::cout << "Thread #" << i << ": on CPU " << sched_getcpu() << "\n";
}
// Simulate important work done by the tread by sleeping for a bit...
std::this_thread::sleep_for(std::chrono::milliseconds(900));
}
});
}
for (auto& t : threads) {
t.join();
}
return 0;
}このサンプルは4つのスレッドを立ち上げます。各スレッドはスリープし、どのCPUで実行しているかを報告するという処理を無限に繰り返します。この報告を行う際に使われるのが sched_getcpu という関数です(これはglibc固有のもので、他のプラットフォーム用には同様の機能を持つ別のAPIがあります)。ではサンプルを実行してみましょう。
$ ./launch-threads-report-cpu
Thread #0: on CPU 5
Thread #1: on CPU 5
Thread #2: on CPU 2
Thread #3: on CPU 5
Thread #0: on CPU 2
Thread #1: on CPU 5
Thread #2: on CPU 3
Thread #3: on CPU 5
Thread #0: on CPU 3
Thread #2: on CPU 7
Thread #1: on CPU 5
Thread #3: on CPU 0
Thread #0: on CPU 3
Thread #2: on CPU 7
Thread #1: on CPU 5
Thread #3: on CPU 0
Thread #0: on CPU 3
Thread #2: on CPU 7
Thread #1: on CPU 5
Thread #3: on CPU 0
^Cここで考察をしましょう。まず、スレッドは同じCPUにスケジューリングされる時もあれば、別のCPUにスケジューリングされる時もあります。さらにCPU間の移動は頻繁に行われています。それでも最終的にはスケジューラが、なんとか各スレッドを別々のCPUに配置し、その配置を保持しています。制約(システム負荷など)が違えば、当然のことながらスケジューリングも変わります。
では、先ほどのサンプルを再実行しましょう。今回は taskset を使って、プロセスのアフィニティを5と6の2つのCPUに制限します。
$ taskset -c 5,6 ./launch-threads-report-cpu
Thread #0: on CPU 5
Thread #2: on CPU 6
Thread #1: on CPU 5
Thread #3: on CPU 6
Thread #0: on CPU 5
Thread #2: on CPU 6
Thread #1: on CPU 5
Thread #3: on CPU 6
Thread #0: on CPU 5
Thread #1: on CPU 5
Thread #2: on CPU 6
Thread #3: on CPU 6
Thread #0: on CPU 5
Thread #1: on CPU 6
Thread #2: on CPU 6
Thread #3: on CPU 6
^Cやはり今回も移動は発生していますが、スレッドは指定した5または6のどちらかのCPUに必ず割り当てられています。
ここで少し回り道:スレッドIDとネイティブ型のハンドル
C++11の標準規格にスレッドライブラリが追加されたとはいえ、すべてが標準化されたわけではありません。OSごとに実装方法やスレッドの管理方法は異なるので、C++の標準規格であらゆるスレッド実装を公開すると、あまりにも制限が多くなってしまいます。そうする代わりにスレッドライブラリでは、標準的な方法として多くのスレッディングの概念を規定し、さらにネイティブ型のハンドルを公開することで、プラットフォーム固有のスレッディングAPIを扱えるようにしています。ネイティブ型のハンドルは低水準のプラットフォーム固有のAPI(Linux上のPOSIXスレッドやWindows上のWindows APIなど)に渡されると、プログラム上できめ細かい制御を行います。
以下のプログラムはシングルスレッドを起動し、スレッドIDとネイティブ型のハンドルをクエリする例です。
int main(int argc, const char** argv) {
std::mutex iomutex;
std::thread t = std::thread([&iomutex] {
{
std::lock_guard<std::mutex> iolock(iomutex);
std::cout << "Thread: my id = " << std::this_thread::get_id() << "\n"
<< " my pthread id = " << pthread_self() << "\n";
}
});
{
std::lock_guard<std::mutex> iolock(iomutex);
std::cout << "Launched t: id = " << t.get_id() << "\n"
<< " native_handle = " << t.native_handle() << "\n";
}
t.join();
return 0;
}以下は、私のマシンで実行した結果の1つです。
$ ./thread-id-native-handle
Launched t: id = 140249046939392
native_handle = 140249046939392
Thread: my id = 140249046939392
my pthread id = 140249046939392メインスレッド(エントリポイントの main 関数をデフォルトで実行するスレッド)と子スレッドの両方で、スレッドIDを取得しています。スレッドIDとは、出力可能なopaque型に関する 標準規定された概念 で、コンテナ内に保持されるもの( hash_map 内にある何かにマッピングされるなど)、とだけ言っておけばいいでしょう。またスレッドオブジェクトには native_handle メソッドがあり、これはプラットフォーム固有のAPIによって認識されるハンドル用に、”実装で定義された型”を返します。上の出力結果には、2つの注目すべきポイントがあります。
- スレッドIDは、実際にはネイティブ型のハンドルと同等である。
- さらに両者は、
pthread_selfによって返される数字のpthread IDと同等である。
native_handle とpthread IDが等しいことは、標準規格でも明らかに示唆されていますが ^(1) 、1番目の内容は驚きです。これは、実装上できてしまったが、決して当てにしてはならないものという感じがします。そこで新しい libc++ のソースコードを調べてみたところ、 pthread_t id は”ネイティブ”ハンドルと、 thread オブジェクトの実際の”ID”の両方として使用されていることが判明しました ^(2) 。
これらの内容はすべて、本稿の本筋から大幅にそれているので、そろそろ要点をまとめます。この遠回りしたセクションの中で一番のポイントは、 std::thread の native_handle メソッドを使うと、既存のプラットフォーム固有のスレッドハンドルが利用できるという点です。このPOSIXプラットフォーム上のネイティブ型のハンドルは、実際にはスレッドの pthread_t IDです。よって、スレッドそのものの中で pthread_self を呼び出すことは、同じハンドルを取得する上で非常に有効な方法なのです。
CPUアフィニティをプログラムで設定する
これまで見てきたように、 taskset のようなコマンドラインツールを使うと、プロセス全体のCPUアフィニティを制御できます。しかし、さらに細かいことをしたい場合や、プログラムの内部から特定のスレッドのアフィニティを設定したい場合は、どうしたらよいでしょうか?
Linux上では、pthread固有の pthread_setaffinity_np 関数を利用できます。以下は、前に扱ったコードと同じ動きをするコードの例ですが、今回はプログラムの内部から制御をしています。実際には、もう少し凝ったことをして、アフィニティを設定し、各スレッドを1つの既知のCPUに固定しています。
int main(int argc, const char** argv) {
constexpr unsigned num_threads = 4;
// A mutex ensures orderly access to std::cout from multiple threads.
std::mutex iomutex;
std::vector<std::thread> threads(num_threads);
for (unsigned i = 0; i < num_threads; ++i) {
threads[i] = std::thread([&iomutex, i] {
std::this_thread::sleep_for(std::chrono::milliseconds(20));
while (1) {
{
// Use a lexical scope and lock_guard to safely lock the mutex only
// for the duration of std::cout usage.
std::lock_guard<std::mutex> iolock(iomutex);
std::cout << "Thread #" << i << ": on CPU " << sched_getcpu() << "\n";
}
// Simulate important work done by the tread by sleeping for a bit...
std::this_thread::sleep_for(std::chrono::milliseconds(900));
}
});
// Create a cpu_set_t object representing a set of CPUs. Clear it and mark
// only CPU i as set.
cpu_set_t cpuset;
CPU_ZERO(&cpuset);
CPU_SET(i, &cpuset);
int rc = pthread_setaffinity_np(threads[i].native_handle(),
sizeof(cpu_set_t), &cpuset);
if (rc != 0) {
std::cerr << "Error calling pthread_setaffinity_np: " << rc << "\n";
}
}
for (auto& t : threads) {
t.join();
}
return 0;
}ここで注目していただきたいのは、先ほど説明した native_handle メソッドを使い、既存のネイティブ型のハンドルをpthreadの呼び出し時に渡す方法( pthread_t IDを第1引数として取る)です。以下は、私のマシンでこのプログラムを実行した結果です。
$ ./set-affinity
Thread #0: on CPU 0
Thread #1: on CPU 1
Thread #2: on CPU 2
Thread #3: on CPU 3
Thread #0: on CPU 0
Thread #1: on CPU 1
Thread #2: on CPU 2
Thread #3: on CPU 3
Thread #0: on CPU 0
Thread #1: on CPU 1
Thread #2: on CPU 2
Thread #3: on CPU 3
^Cスレッドは要求通り、1つのCPUに正確に固定されています。
ハイパースレッディングでコアを共有する
さあ、ここからが本当に面白くなるところです。CPUトポロジについて少し学んだので、この先は徐々に高度で複雑なプログラムを扱っていきましょう。C++のスレッディングのライブラリとPOSIX呼び出しによって、所定のマシンにおけるCPUの使い方を微調整し、どのCPUでどのスレッドを実行するかまで正確に指定します。
ところで、なぜこんな風にスレッドを任意のCPUに固定する必要があるのでしょう? スレッド管理はOSの得意分野なので、OSに任せるのが妥当だとは思いませんか? まあ、ほとんどの場合はそうなのですが、中には例外もあるのです。
まず、すべてのCPUが似通っているわけではありません。マシン上で最新のプロセッサを使っている場合、おそらくコアは複数あり、各コアには複数のハードウェアスレッドが(大抵2つ)あります。本稿の最初でも説明しましたが、例えば私の(Haswell)プロセッサには4つのコアがあり、各コアにはスレッドが2つあるため、合計で8つのハードウェアスレッドがあります。つまりOSには、8つの論理CPUがあるように見えています。 lstopo という優れたツールを使って、私のプロセッサのトポロジを表示してみましょう。
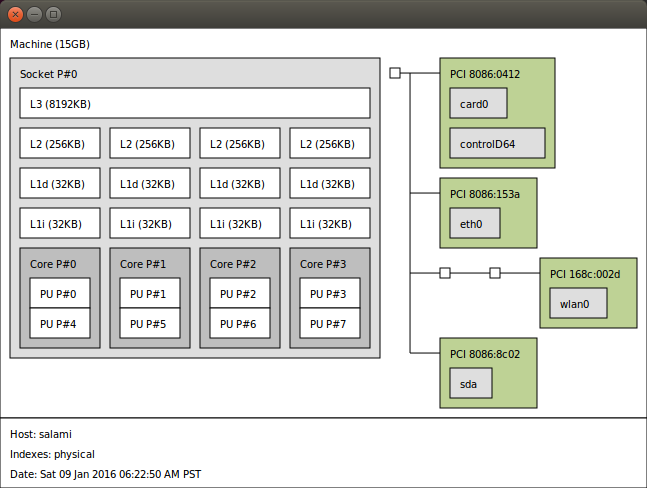
どのスレッドが同じコアを共有するのかを確認する、グラフィックを用いない別の方法は、論理CPUごとに存在している特別なシステムファイルを見ることです。例えば、CPU 0は以下のようになります。
$ cat /sys/devices/system/cpu/cpu0/topology/thread_siblings_list
0,4よりパワフルな(サーバクラスの)プロセッサには、複数のソケットがあり、それぞれがマルチコアCPUを備えています。例えば、私の職場のマシンは、ソケットが2つあり、それぞれがハイパースレッディングを使用できる8コアのCPUです。つまり全部で32のハードウェアスレッドということになります。さらに一般的なケースは、通常 NUMA の配下に含まれていて、そこでOSは、同じシステムメモリとバスさえも共有しないような、非常に緩く結合された複数のCPUの管理ができます。
問うべき重要なことは、ハードウェアスレッドは何を共有するのか、また私たちが書くプログラムにどのように影響を及ぼすのか、ということです。上の lstopo の図をもう一度見てください。キャッシュL1とL2がすべてのコアで、2つのスレッドに共有されているのが、簡単に見て取れるでしょう。L3はすべてのコアで共有されています。マルチソケットマシンの場合には、同じソケット上のコアはL3を共有しますが、大抵はそれぞれ独自のL3があります。NUMAにおいて、通常、各プロセッサは内蔵のDRAMにアクセスします。そして、あるプロセッサが別のプロセッサのDRAMにアクセスするために、コミュニケーションメカニズムが使用されます。
しかし、コアの中のスレッドが共有するのは、キャッシュだけではありません。コアの実行プロセスの多くを共有します。例えば実行エンジン、システムバスインタフェース、命令フェッチ、デコードユニットや分岐予測などです ^(3) 。
こういうわけで、もしあなたが、なぜハイパースレッディングはCPUベンダーが作ったトリックだと思われることがあるのだろう、と疑問をお持ちでしたら、お分かりになるでしょう。コアの2つのスレッドが、これだけ多くのものを共有するので、一般的には完全に独立したCPUではありません。確かに、このアレンジは、あるワークロードに対しては有効ですが、有効でないこともあります。”アプリXのパフォーマンスを向上させるためにハイパースレッディングを抑制する方法”としてスレッドオンラインに示されているように、時には害を及ぼすことさえあります。
共有コアと個別コアのパフォーマンスデモ対決
並行したスレッドにおいて、異なる論理CPU で異なる浮動小数点による”ワークロード”を実行するようなベンチマークを実装し、終了するまでの時間を比較しました。それぞれのワークロードはそれ自体の大きな float 配列を得て、1つの float の結果を計算しなければなりません。ベンチマークでは、ユーザのインプットから、どのCPU上で、どのワークロードを実行するべきかを判断します。つまり、インプットを準備し、すべてのワークロードを別々のスレッドに並行に振り分けます。要求通り、各スレッドの正確なCPUアフィニティを設定するために、先ほど見たAPIを使用します。もし興味がおありでしたら、ベンチマーク一式とLinux版 Makefile は、 こちらからご利用になれます 。ここには、コードの一部と結果を載せておきます。
2つのワークロードに注目します。最初は簡単なアキュムレータです。
void workload_accum(const std::vector<float>& data, float& result) {
auto t1 = hires_clock::now();
float rt = 0;
for (size_t i = 0; i < data.size(); ++i) {
rt += data[i];
}
result = rt;
// ... runtime reporting code
}入力配列のすべての浮動小数点数を合計します。これは、 std::accumulate の動きと似ています。
ここで3つのテストを実行します。
- 単一CPUで
accumを実行する。ベースライン性能の数値を得るためです。処理時間を計測します。 - 異なるコアで2つの
accumインスタンスを実行する。各インスタンスの処理時間を計測します。 - 同じコアの2つのスレッドで2つの
accumインスタンスを実行する ^(4) 。 各インスタンスの処理時間を計測します。
(以降で)報告する数字は、1つのワークロードの入力として1億個の浮動小数点数をもつ1つの配列に対する実行時間です。数回実行して平均をとると以下のようになりました。
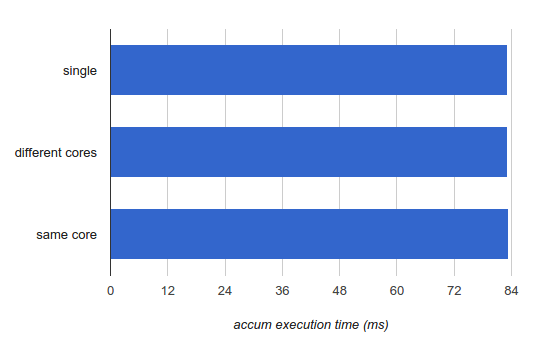
注釈:
single:シングルスレッド
different cores:異なるコアを使う場合
same core:同じコアを使う場合
accum execution time (ms):累積実行時間(ミリ秒)
これは、 accum を実行しているスレッドが、別の accum を実行しているスレッドとコアを共有している場合には、実行時間がまったく変化しないということを明らかに示しています。これには良いニュースと悪いニュースがあります。良いニュースは、同じコアで実行される2つのスレッドは、お互いを邪魔しないよう管理されているので、この特定のワークロードはハイパースレッディングにとても適しているということです。悪いニュースは、プロセッサのリソースを最適に使用していないことが一目瞭然であることから、まったく同じ理由で優れたシングルスレッドの実装ではないということです。
もう少し詳しい情報を得るために、 workload_accum の内部ループを分解してみてみましょう。
4028b0: f3 41 0f 58 04 90 addss (%r8,%rdx,4),%xmm0
4028b6: 48 83 c2 01 add $0x1,%rdx
4028ba: 48 39 ca cmp %rcx,%rdx
4028bd: 75 f1 jne 4028b0非常に簡潔ですね。コンパイラは、SSE(128ビット)レジスタの下位32ビットに浮動小数点数を加えるため、 addss というSSE命令を使います。Haswellでは、この命令のレイテンシは3サイクルです。 xmm0 に浮動小数点数を加え続けるためには、レイテンシ(スループットではありません)が重要です。前の加算作業が完全に終わらなければ次の数は追加できません ^(5) 。さらに、Haswellには実行ユニットが8つありますが、 addss が使うのはその中の1つだけです。これは、ハードウェアの使用率をかなり低く抑えてくれます。そのため、2つのスレッドを同じコアで実行しても、お互いの邪魔にならないということが分かります。
別のサンプルとして、もう少し複雑な負荷をかけてみましょう。
void workload_sin(const std::vector<float>& data, float& result) {
auto t1 = hires_clock::now();
float rt = 0;
for (size_t i = 0; i < data.size(); ++i) {
rt += std::sin(data[i]);
}
result = rt;
// ... runtime reporting code
}単純に数字を加えるのではなく、正弦を加えることにしました。 std::sin は、とても複雑な関数です。減算したテイラー級数の多項式近似を実行し、内部で込み入った計算を数多く行います(通常はルックアップテーブルと一緒に利用されます)。単純に数字を加算する場合より、コアの実行ユニットの稼働率を高く保たなければなりません。3つの異なる実行モードを、もう一度チェックしてみましょう。
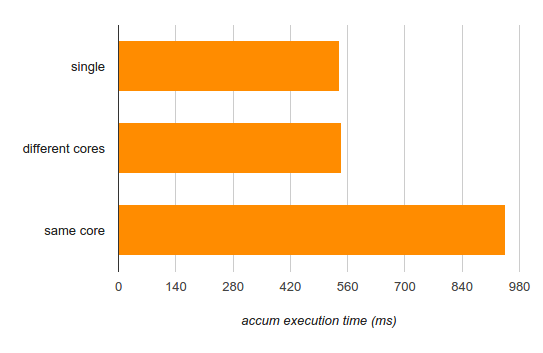
注釈:
single:シングルスレッド
different cores:異なるコアを使う場合
same core:同じコアを使う場合
accum execution time (ms):累積実行時間(ミリ秒)
さらに興味深い結果ですね。異なるコアで実行すれば、シングルスレッドの性能を損なうことはありません(つまり、並列計算をうまく行えています)。しかし、同じコアで実行すると影響は甚大です(75%以上増加します)。
ここでも、良いニュースと悪いニュースがあります。良いニュースは、できるだけ多くの数を計算したい場合、2つのスレッドを使うと、同じコアを使ってもシングルスレッドより速く計算できることです(2つの入力配列を計算するのに、シングルスレッドでは540×2=1080ミリ秒かかりますが、2つのスレッドを使うと945ミリ秒で完了します)。悪いニュースは、レイテンシを重要視する場合、複数スレッドを同じコアで実行するとレイテンシが大きくなってしまうことです。コアの実行ユニットをめぐってスレッド間で競合が起こり、お互いのパフォーマンスを下げてしまうのです。
ポータビリティに関する注意
ここまでのところ、本稿で取り上げた例はLinuxに特化したものでした。しかし、これらはすべて複数のプラットフォームに適応していて、これらを利用するためのポータブルなライブラリもあります。これらのライブラリはネイティブAPIより扱いにくく冗長です。しかし、複数のプラットフォームで利用できるポータビリティが必要なら、それほど大きな代償ではないでしょう。私が使いやすいと思った優れたポータブルライブラリは、Open MPIプロジェクトの一環である hwloc です。これは非常にポータビリティが高く、Linux、Solaris、BSD系OS、Windowsなどで実行できます。実際、前述した lstopo は、 hwloc 上で構築されたツールです。
hwloc はジェネリックなC言語APIです。これは、アフィニティを設定したりクエリしたりするだけでなく、システムのトポロジ(ソケット、コア、キャッシュ、NUMAノードなどを含む)をクエリすることも可能です。それほど時間をかけて説明はしませんが、本稿のために 簡単な例 をソースリポジトリと共に用意しました。これはシステムのトポロジを説明し、スレッドの呼び出しを特定の論理プロセッサにバインドしています。また、 hwloc を使うプログラムの構築方法についても確認できます。この例をポータビリティの改善に役立ててもらえれば嬉しいです。もし皆さんが、 hwloc の別の便利な使い方や、これと同じように使える別のポータブルライブラリをご存知でしたら、是非メールで教えてください。
まとめ
ここまでで分かったことは何でしょうか。本稿ではスレッドアフィニティの検証と設定の方法について説明してきました。また、POSIXの呼び出しと共にC++の標準スレッドライブラリを使って論理CPU上のスレッドの配置を制御する方法についても述べました。C++のスレッドライブラリがネイティブ型のハンドルを公開することでPOSIXスレッドなどと相互作用するようになります。さらにプロセッサの正確なハードウェアトポロジの確認方法や、どのスレッドが1つのコアをシェアし、どのスレッドが異なるコアで実行するのかを選択する方法と、どうしてそれが大切なのかを学びました。
結論として、唯一かつ最も重要なことは計測です(これと一緒に、パフォーマンス・クリティカルなコードもいつもと変わらず重要です)。現在、パフォーマンス調整を制御するための変数は数多くありますが、どれが速く、なぜ速いのかを事前に予測することはとても困難です。負荷が異なると、CPUの使い方がまったく違ってくるのです。これによって、CPUコア、ソケット、NUMAノードなどを共有するのに適しているかどうかが変わってきます。OSには、マシン上にCPUが8つあるように見えていて、標準のスレッドライブラリは、この個数をポータブルな方法でクエリさせようとします。しかし、マシンにとって最高のパフォーマンスを引き出すためには、すべてのCPUが同じではないことを理解しなければいけません。
私は、存在する2つのワークロードのマイクロ操作レベルのパフォーマンスについて、そこまで深く分析していません。本稿の主題ではないからです。本稿が、複数のスレッドを使用した時に何が問題になるのかについて、別の角度から考察する助けになれば嬉しく思います。アルゴリズムを並列化する方法を考える時、物理資源の共有は必ずしも考慮されません。しかし、ここまでに説明してきたとおり、これは必ず考慮すべきことなのです。
-
標準C++ライブラリは何がPOSIXなのかを”知らない”ため、保証できません。 ↩
-
libstdc++のPOSIXポートでも同じことが行われます(しかし、自分自身で確認しようとすると、コードはどこか複雑になってしまいます)。 ↩
-
さらに詳しく知りたい場合は、 ウィキペディアの「ハイパースレッディング・テクノロジー」のページ とAgner Fogによる こちらの投稿 をご覧ください。 ↩
-
どのCPUが同じコアに属し、どのCPUが別のコアに属すかは、
lstopoが示すマシンの図を見ると分かります。 ↩ -
このループを最適化する方法として、手動でループ展開して複数のXMMレジスタを使う方法があります。また、さらに優れた方法として、
addps命令を使って4つの浮動小数点数の加算を同時に行うこともできます。浮動小数点数の加算はアソシエイティブではないため、厳密に安全とは言えません。コンパイラは、このような最適化を可能にするために-ffast-mathフラグを確認する必要があるでしょう。 ↩

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事