2017年4月27日
Go言語のリアルタイムGC 理論と実践
(2016-12-01)by Will Sewell
本記事は、原著者の許諾のもとに翻訳・掲載しております。
(編注:誤訳、意味の分かりづらい訳を修正しました。リクエストありがとうございました。)
毎日、Pusherは数十億のメッセージをリアルタイム、つまり送り元から宛先まで100ms未満で送信しています。どのようにしてそれを可能にしているのでしょうか。重要となる要因はGoの低レイテンシのガベージコレクタです。
ガベージコレクタはプログラムを一時停止させるものであり、リアルタイムシステムの悩みの種です。そのため、新しいメッセージバスを設計する際には慎重に言語を選びました。Goは 低レイテンシを強調している ものの、私たちは懐疑的でした。「本当にGoを使えば実現できるのか? もしできるならどうやって?」
このブログ記事ではGoのガベージコレクタを、どのように機能し(トリコロールアルゴリズム)、なぜ機能し(こんなに短いGCによる一時停止時間の実現)、そして何よりも、それが機能するのかどうか(GCによる一時停止のベンチマークと、他言語との比較)という観点から見ていきます。
HaskellからGoへ
それまでに構築してきたシステムは、送信メッセージをインメモリで処理するPub/Sub方式のメッセージバスでした。Goで作成したバージョンは、最初にHaskellで実装したもののリライトです。5月にHaskellバージョンの開発を止めたのは、GHCのガベージコレクタに根本的なレイテンシの問題を見つけたのが理由でした。
以前、 Haskell実装の詳細なポストモーテム(事後検証) を投稿したのですが、根本的な問題はGHCの一時停止時間がワーキングセット(つまり、メモリ内のオブジェクトの数)のサイズに比例することでした。そのケースでは、メモリ内に多数のオブジェクトがあり、結果、数百ミリ秒の一時停止時間が発生しました。コレクションを遂行している間、プログラムを妨げるのが、あらゆるGCについて回る問題です。
では、Goはどうでしょう。全スレッドが一時停止するようなGHCのコレクタと違い、Goのコレクタはプログラムと並行に走るので、長い一時停止時間を防げます。 バージョンアップのたびにレイテンシが改善している ことを知って、Goの低レイテンシ重視の姿勢に後押しされました。見込みがあるのが分かったのです。
並行ガベージコレクタはどのように動いているか
いかにしてGoはGCの並行処理を実現しているのでしょうか。その核心は トリコロールマーク&スイープアルゴリズム です。以下のアニメーションはそのアルゴリズムの機能を示したものです。それがどのようにGCとプログラムの並行処理を可能にしているかに留意してください。つまり、一時停止時間はスケジューリングの問題になるということです。スケジューラはGCコレクタを短い期間で実行するよう設定でき、プログラムを差しはさむこともできます。低レイテンシを求めている私たちには朗報です。
(編注:以下ではアニメーションを画像に切り出しています)
(スライド1 フェーズ:プログラム)

しばらく処理が進んでからプロセスに加わります。
プログラムはリンクリストを操作します。ノード A,B と C を作成しています。赤いオブジェクト A と B は ルートオブジェクト であり、常に到達可能です。ポインタも1つ存在します。 B.next = &C です。ガベージコレクタはオブジェクトを黒、グレー、白の3セットに割り当てます。現在、ガベージコレクタはサイクルを回していないため、3つのオブジェクトは白セットの中にあります。
(スライド2 フェーズ:プログラム)
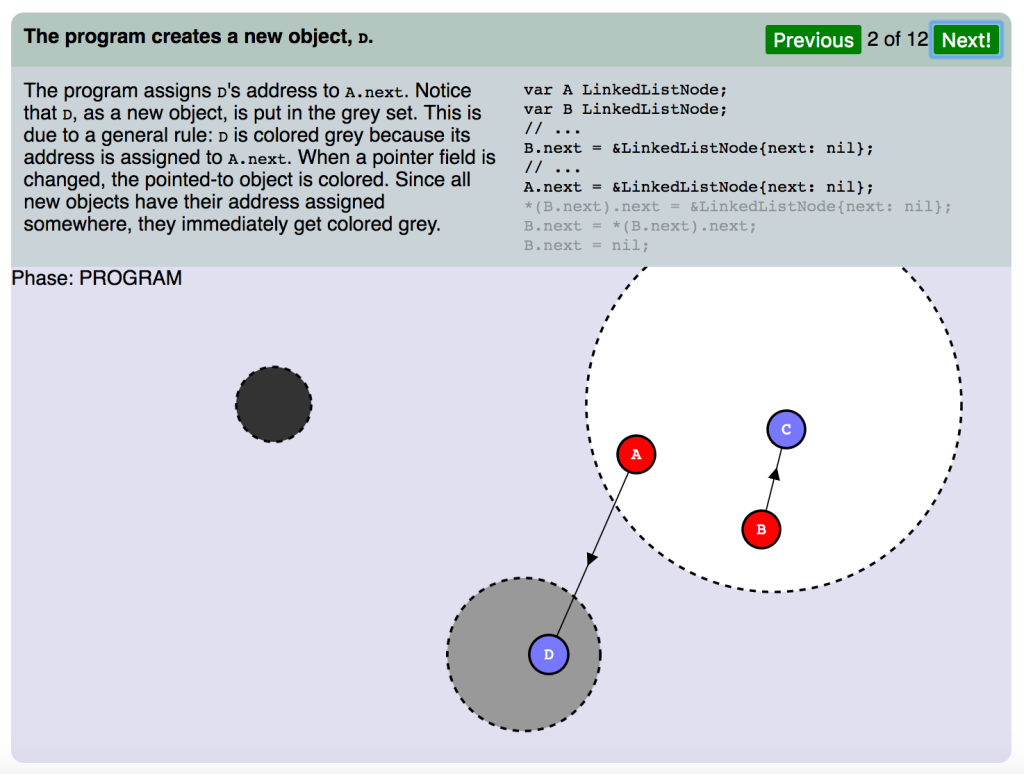
プログラムが新規オブジェクト、 D を作成します。
プログラムは D のアドレスを A.next に割り当てます。 D は新規オブジェクトなので、グレーセットに配置されたのが分かります。これは一般規則によるもので、 D がグレーに色分けされたのは、そのアドレスが A.next に割り当てられたためです。ポインタフィールドが変わると、ポイント対象のオブジェクトが色分けされます。アドレスを持つすべての新規オブジェクトはいずれかに割り当てられたので、それらは即座にグレーになります。
(スライド3 フェーズ:GC)
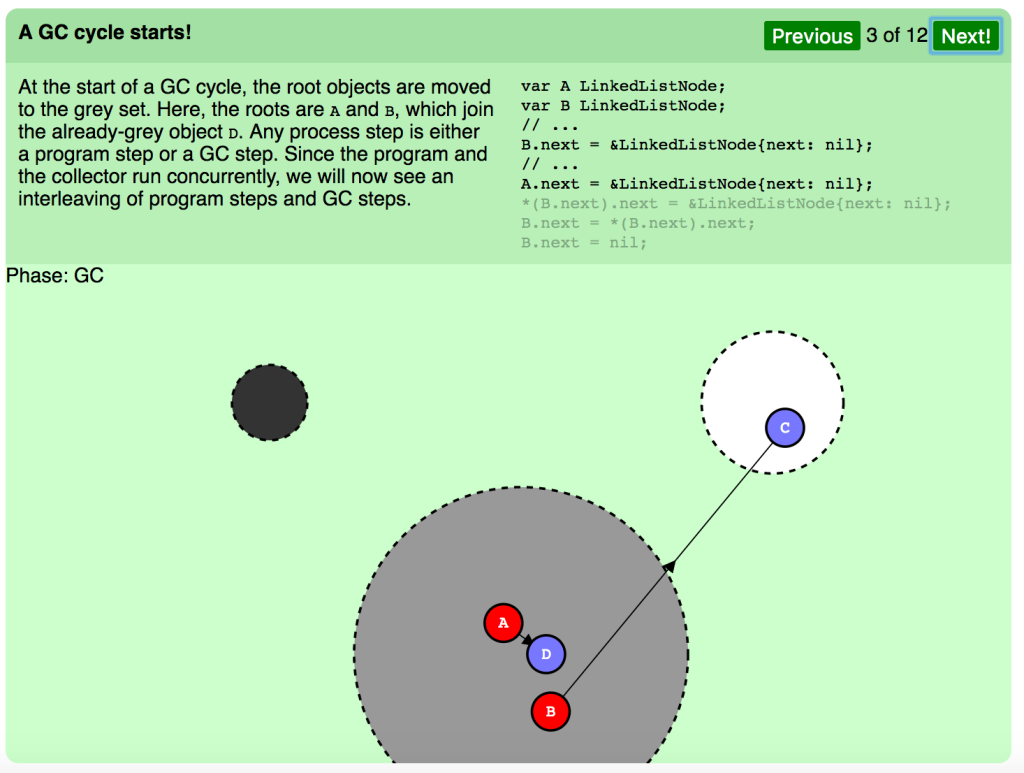
GCサイクルの始まりです。
GCサイクルの開始時、ルートオブジェクトはグレーセットに移されます。見てください、ルートは A と B で、既にグレーのオブジェクト D に加わっています。あらゆるプロセス段階はプログラムステップ、GCステップのいずれかに当たります。プログラムとコレクタは並行に走るので、プログラムステップとGCステップの差しはさみが見られるでしょう。
(スライド4 フェーズ:GC)
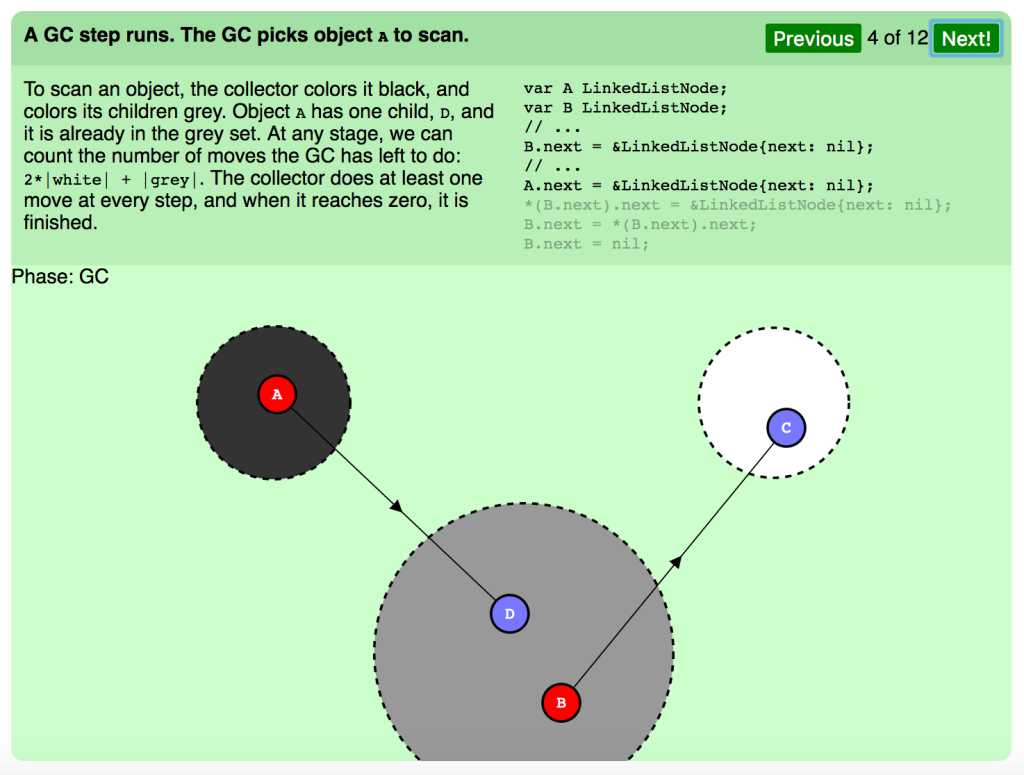
GCステップの実行。スキャンのため、GCはオブジェクト A を選びます。
オブジェクトをスキャンするため、コレクタはそれを黒、その子階層をグレーに色分けします。オブジェクト A は1つの子階層、 D を持っており、それは既にグレーセットの中です。どのステージでも、GCがやり残した移動の数を 2*|white| + |grey| のようにカウントできます。コレクタは全ステップで少なくとも1つの移動を行い、それがゼロに達すれば終了です。
(スライド5 フェーズ:プログラム)
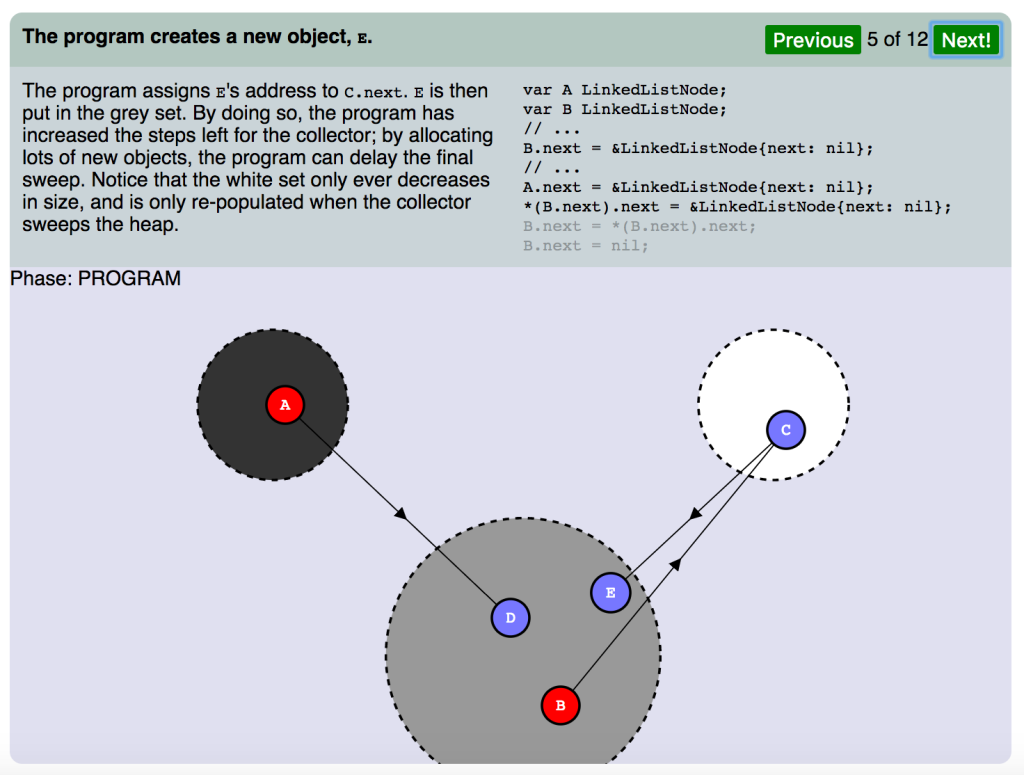
プログラムが新規オブジェクト E を作成します。
プログラムは E のアドレスを C.next.E に割り当て、グレーセットに配置しました。それにより、プログラムはコレクタに残されたステップを増やしました。たくさんの新規オブジェクトを割り当てることで、プログラムは最終の破棄(スイープ)を遅延させます。ここまでで、サイズが減り、コレクタがヒープを破棄した時に再ロードされているのは白セットだけであることが分かります。
(スライド6 フェーズ:プログラム)
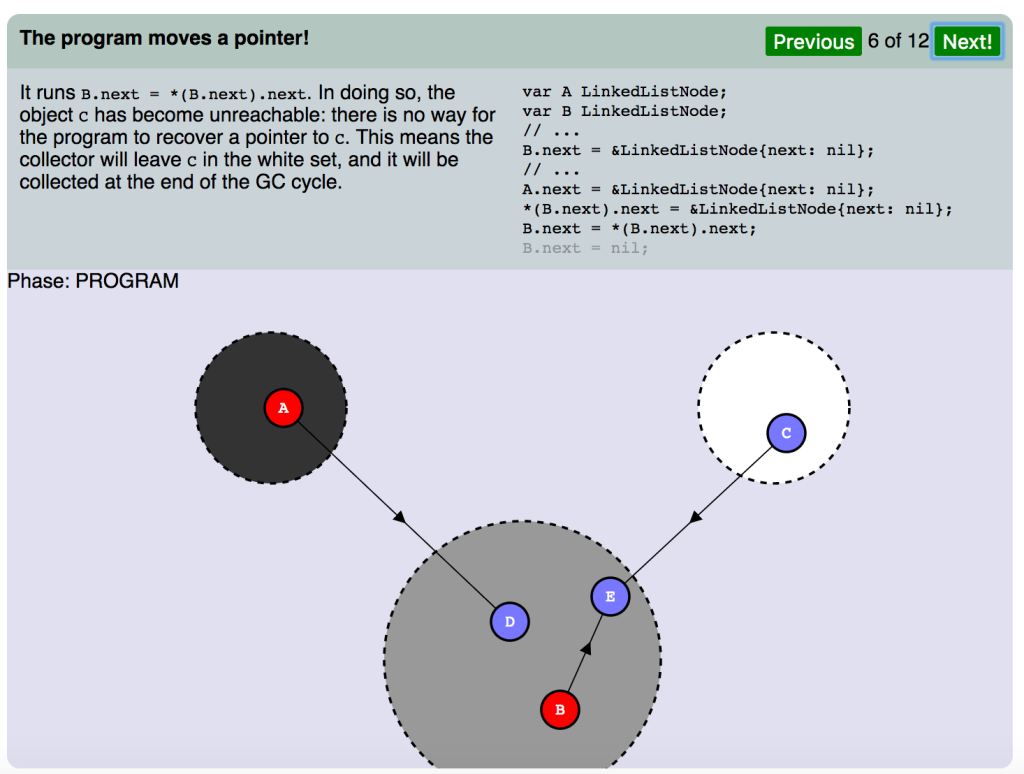
プログラムがポインタを動かします。
B.next = *(B.next).next が実行されました。それにより、オブジェクト C は到達不能になります。プログラムは C へのポインタを復旧することはできません。つまり、コレクタは C を白セットに残し、それをGCサイクルの最後に回収することになります。
(スライド7 フェーズ:GC)
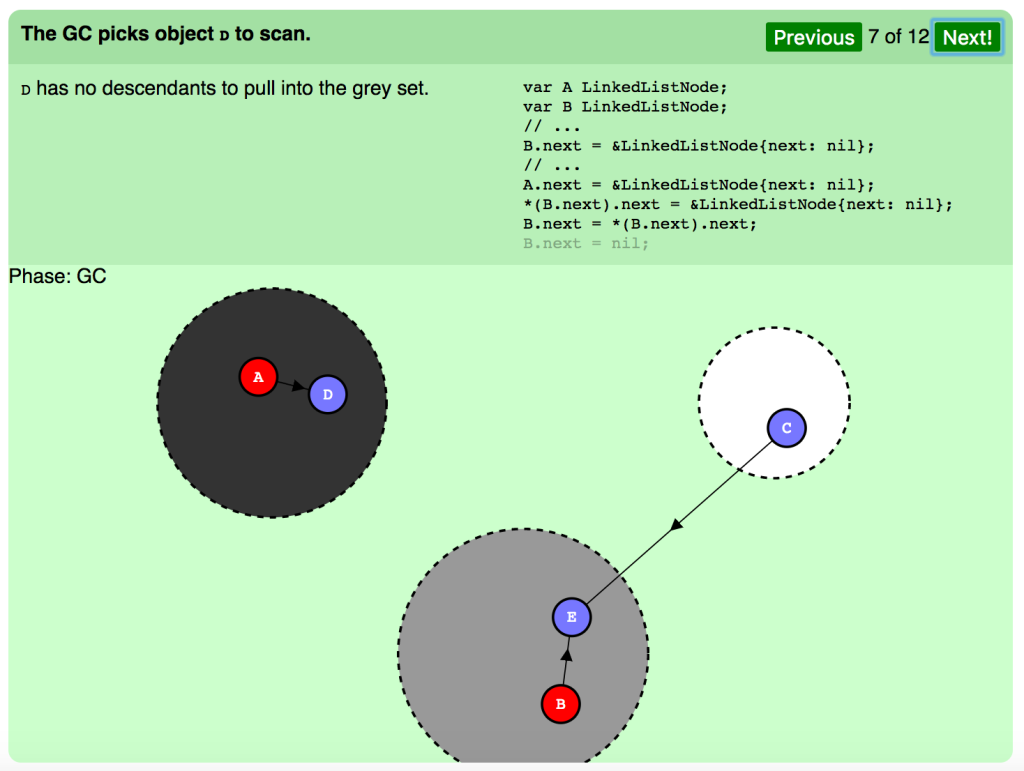
スキャンのため、GCはオブジェクト D を選びます。
D にはグレーセットに引き入れる下層はありません。
(スライド8 フェーズ:プログラム)
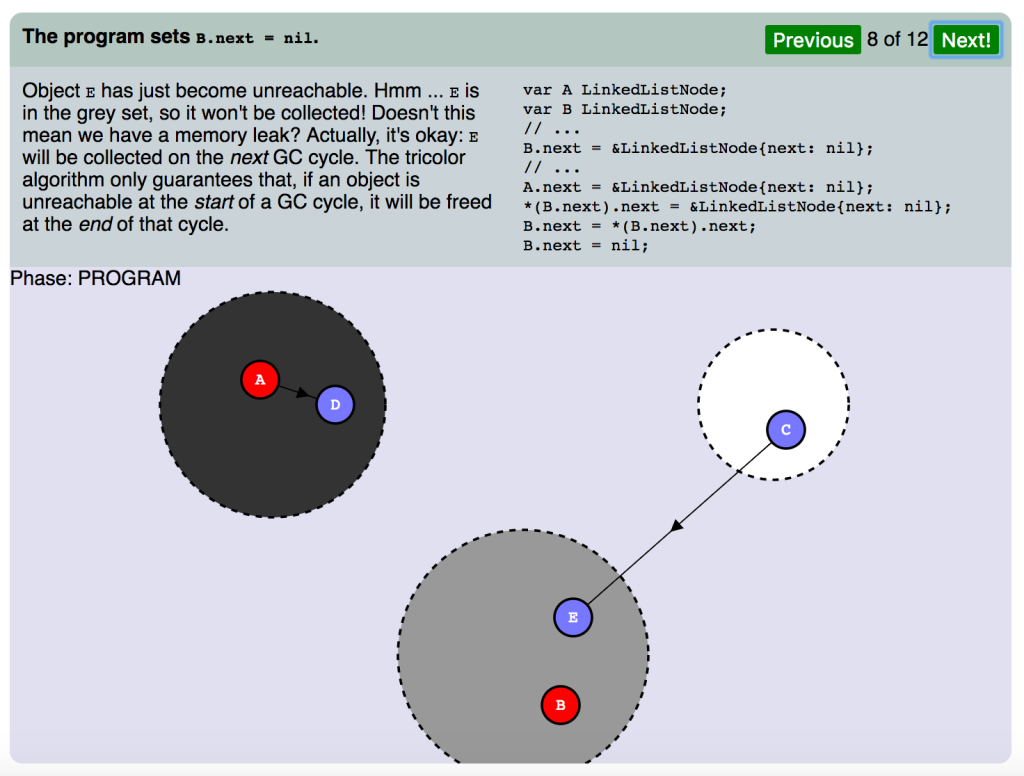
プログラムが B.next = nil を設定します。
オブジェクト E が到達不能になりました。フム。 E はグレーセットの中で、これでは回収ができません。メモリリークの心配はないのでしょうか。実際のところ、問題ありません。 E は 次の GCサイクルで回収されます。トリコロールアルゴリズムは、オブジェクトがGCサイクルの 始め に到達不能だった場合、サイクルの 終わり にそれを解放することを保証しています。
(スライド9 フェーズ:GC)
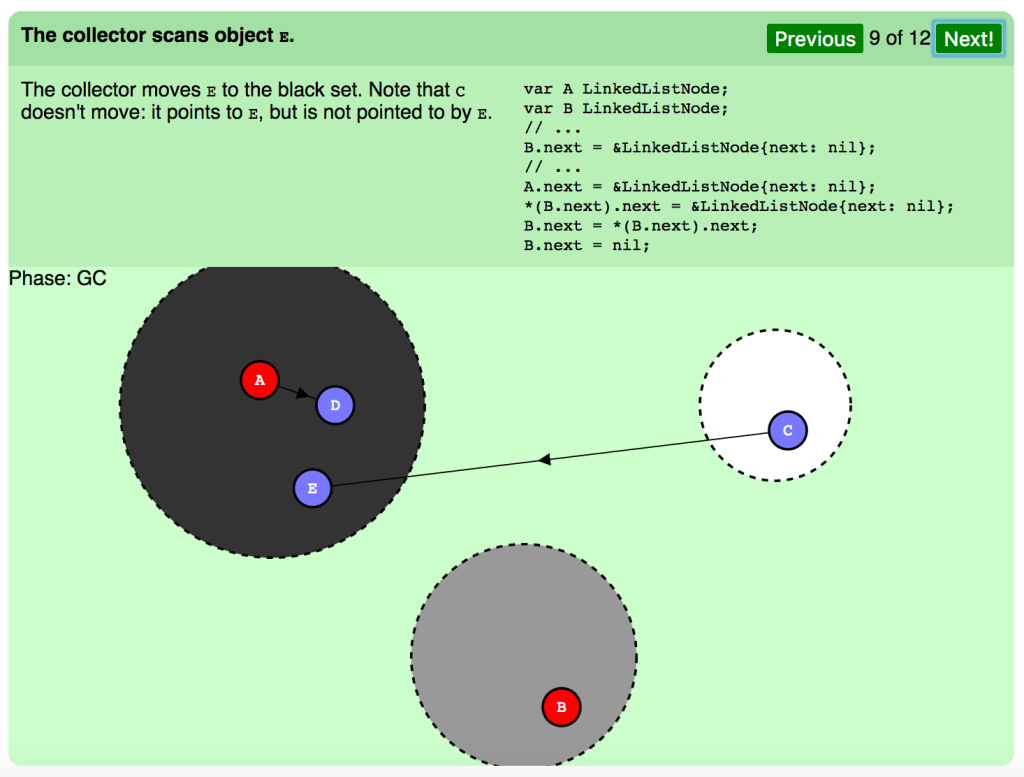
コレクタがオブジェクト E をスキャンします。
コレクタは E を黒セットに動かします。 C は動いていません。それは E をポイントしますが、 E のポイント先ではありません。
(スライド10 フェーズ:GC)
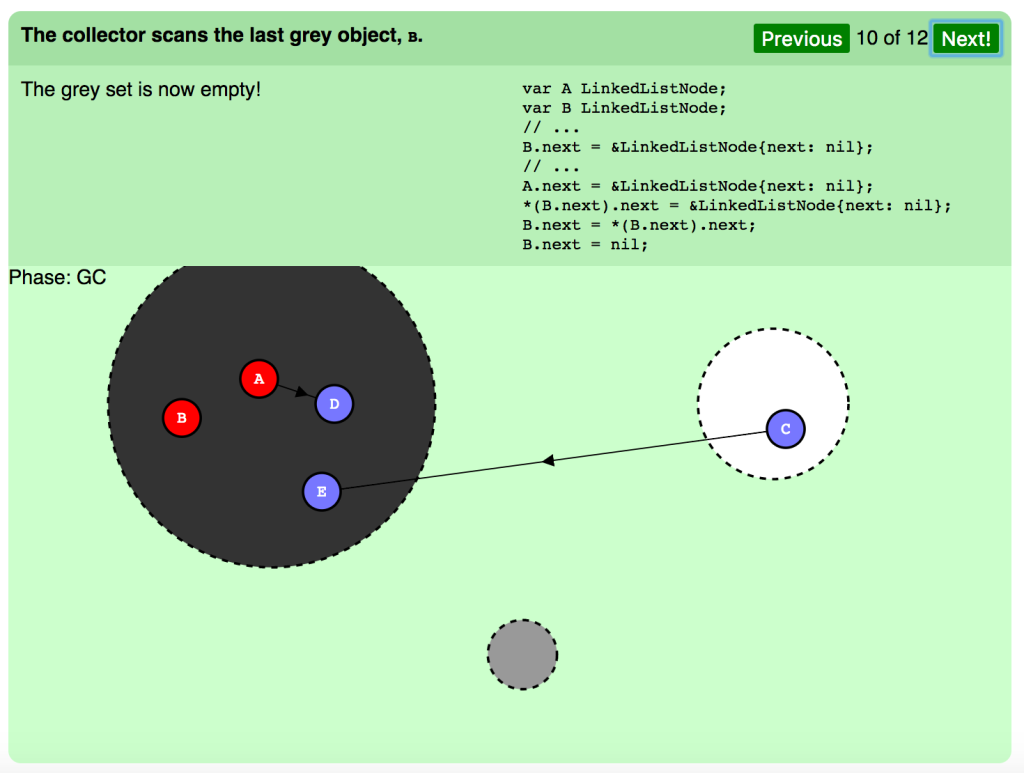
コレクタは最後のグレーオブジェクト B をスキャンします。
グレーセットは空になりました。
(スライド11 フェーズ:GC)
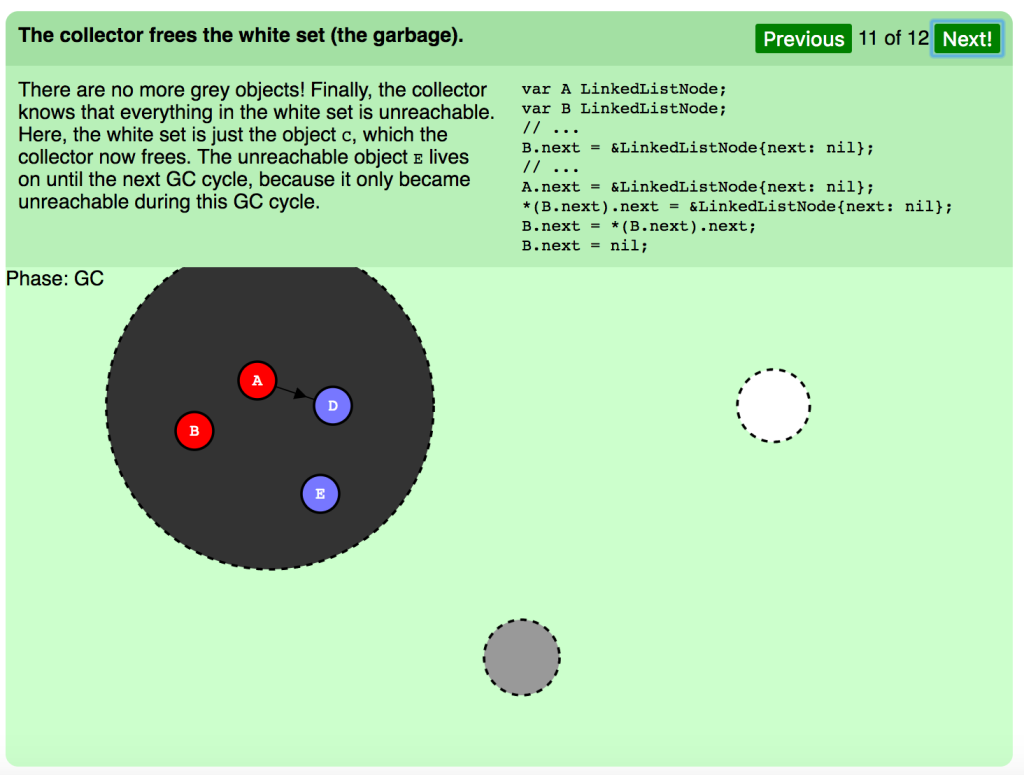
コレクタは白セット(ガベージ)を解放します。
グレーのオブジェクトはゼロになりました。最終的に、白セットの中身はすべて到達不能ということです。ここで、白セットにあったオブジェクト C をコレクタが解放します。到達不能なオブジェクト E は、GCサイクルの最中に到達不能になったため、次のGCサイクルまで残ります。
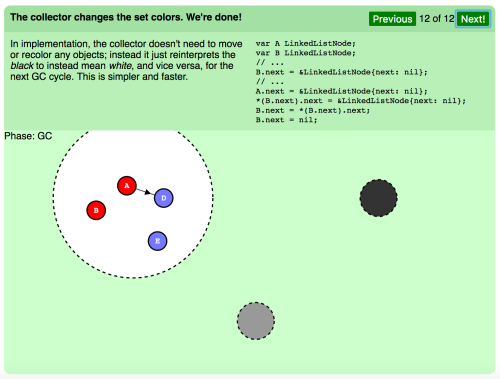
(スライド12 フェーズ:GC)
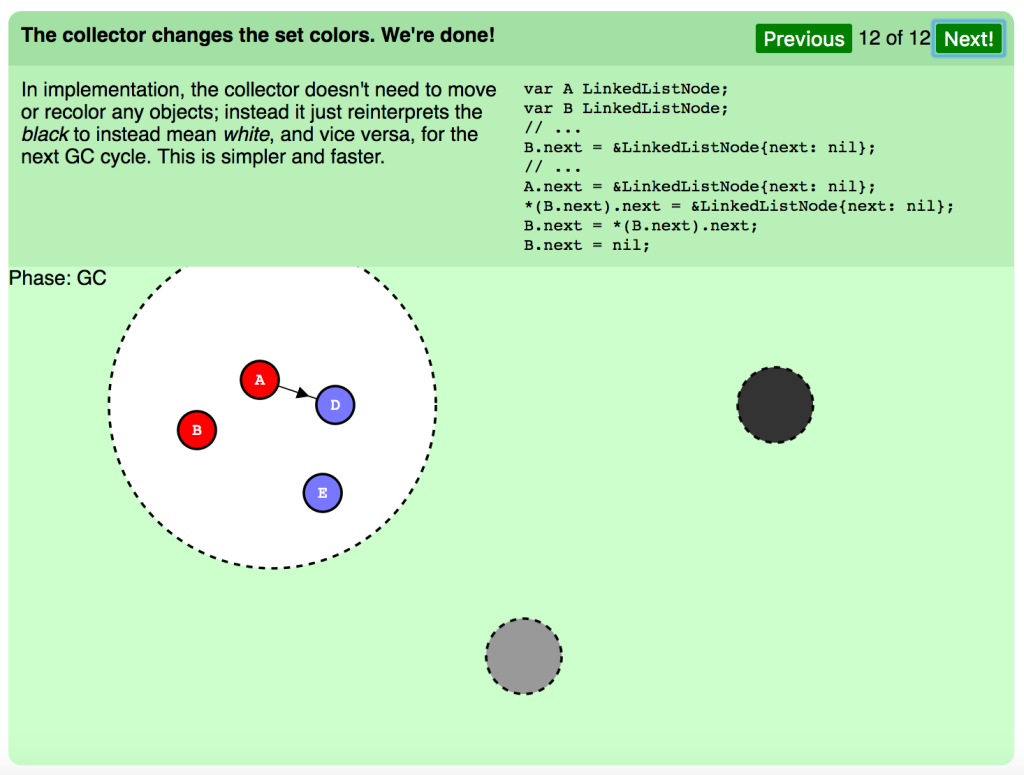
コレクタがセットカラーを変えます。すべて完了しました。
実行中、コレクタは一切オブジェクトを移動したり、再度色分けしたりする必要はありません。その代わり、次のGCサイクルに備えて黒を再解釈して白を意味するようにしたり、その逆を行なったりします。よりシンプルで速いやり方です。
上のアニメーションはマーキングのフェーズの詳細を示しています。GCにはなお2つのストップザワールドフェーズがあります。
ルートオブジェクトに対する初期スタックスキャン、そしてマーキングフェーズの終了です。嬉しいことに、 終了フェーズは最近除去されつつあります 。この最適化については後で取り上げます。実際に試してみて、これらのフェーズの一時停止時間は非常に大きなヒープで1ms未満であることがわかりました。
並行GCであれば、複数プロセッサで同時にGCを実行する能力も見込めるということです。
レイテンシ vs. スループット
並行GCで大きなヒープサイズに対しても大幅に低いレイテンシをもたらすなら、なぜストップザワールドコレクタを選ぶのでしょう。Goの並行ガベージコレクタは、GHCのストップザワールドコレクタに比べれば いくらかマシ 、という程度に過ぎないのでしょうか。
そうとも言い切れません。低レイテンシには代償があります。最も重大な代償は スループット低下 です。平行処理は、同期と複製に余分の作業を要し、プログラムが有用な処理に使える時間を損ないます。GHCのガベージコレクタはスループットを最適化していますが、Goが最適化しているのはレイテンシです。Pusherにとってはレイテンシのほうが重要なので、これは格好のトレードオフでした。
並行ガベージコレクションの2つ目の代償は、 予測できないヒープ拡張 です。プログラムは、GCの実行中に任意のサイズのメモリを割り当てることができます。つまり、ヒープが目標最大サイズに到達する前にGCを実行しなければならないのです。しかし、GCの実行が早過ぎると、必要以上の回収が起こってしまいます。このトレードオフには要注意です( この件に関しては、Austin Clementsの優れた概説があります )。Pusherでは、それを予測できないことは問題ではありませんでした。私たちのプログラムは予測可能な一定の割合でメモリを割り当てる傾向があるからです。
実際の成果は?
ここまで見ると、GoのGCはPusherのレイテンシの必要条件に最適に思えます。しかし実際の動きはどうでしょうか。
今年の初め、Haskellの実装の一時停止時間を検査する時に、一時停止時間を計測するベンチマークを作成しました。ベンチマークプログラムは、サイズの限られたバッファに繰り返しメッセージをプッシュします。古いメッセージの期限は絶えず切れていき、解放されます。ヒープサイズは大きく保つことは重要です。ヒープは参照されているオブジェクトを検知するために行ったり来たりしなければならないからです。これは、GCの実行時間が、その間で有効なオブジェクト、ポインタの数に比例する理由でもあります。
以下がGoの中のベンチマークで、バッファは配列として表されます。
package main
import (
"fmt"
"time"
)
const (
windowSize = 200000
msgCount = 1000000
)
type (
message []byte
buffer [windowSize]message
)
var worst time.Duration
func mkMessage(n int) message {
m := make(message, 1024)
for i := range m {
m[i] = byte(n)
}
return m
}
func pushMsg(b *buffer, highID int) {
start := time.Now()
m := mkMessage(highID)
(*b)[highID%windowSize] = m
elapsed := time.Since(start)
if elapsed > worst {
worst = elapsed
}
}
func main() {
var b buffer
for i := 0; i < msgCount; i++ {
pushMsg(&b, i)
}
fmt.Println("Worst push time: ", worst)
}James Fisherのブログ記事に続いて、Gabriel Schererが フォローアップの記事 を書きました。そこでは、オリジナルのHaskellベンチマークと、OCaml、Racketの複数バージョンの比較をしています。彼はそれらのベンチマークを含む レポジトリ を作り、Santeri Hiltunenが Java用のバージョン を追加しました。ここでは、ベンチマークをGoに移植し、パフォーマンスを比較することにしました。
ややこしい話はここまでにして、以下が 当方のシステム におけるベンチマークの結果です。
| ベンチマーク | 最長一時停止時間 (ms) |
|---|---|
| OCaml 4.03.0 (マップベース) (マニュアル タイミング) | 2.21 |
| Haskell/GHC 8.0.1 (マップベース) (rts タイミング) | 67.00 |
| Haskell/GHC 8.0.1 (配列ベース) (rts タイミング) ^(1) | 58.60 |
| Racket 6.6 増分実験GC (マップベース) (調整あり) (rts タイミング) | 144.21 |
| Racket 6.6 増分実験GC (マップベース) (調整なし) (rts タイミング) | 124.14 |
| Racket 6.6 (マップベース) (調整あり) (rts タイミング) ^(2) | 113.52 |
| Racket 6.6 (マップベース) (調整なし) (rts タイミング) | 136.76 |
| Go 1.7.3 (配列ベース) (マニュアル タイミング) | 7.01 |
| Go 1.7.3 (マップベース) (マニュアル タイミング) | 37.67 |
| Go HEAD (マップベース) (マニュアル タイミング) | 7.81 |
| Java 1.8.0_102 (マップベース) (rts タイミング) | 161.55 |
| Java 1.8.0_102 G1 GC (マップベース) (rts タイミング) | 153.89 |
ここで2つ驚いたのは、Javaの極度な成績の悪さと、OCamlの突出した優秀さです。OCamlの3ms以下の一時停止時間は、OCamlが旧世代で使っている 増分GCアルゴリズム によるものです(OCamlを選ばない理由は並行処理マルチコア並行処理のサポートの乏しさです)。
見てのとおり、Goの一時停止時間は約7msと、上々の結果です。もちろん、Pusherが求める条件にかなっています。
注意点
ベンチマークには常に気をつけましょう。様々な実行時間は様々なユースケース、様々なプラットフォームに最適化されます。しかし、ここでははっきりとしたレイテンシの条件があり、このベンチマークは私たちのユースケースを表しているので、私たちにとってGoは役立つ、と言えます。
マップ vs 配列ベース - 元々、私たちのベンチマークはマップでアイテムの挿入、削除を行なう処理をベースにしていました。しかし、GoのGCには、大きなマップの取り扱い方に バグ があるため、結果が曖昧になっていました。そこで、マップを可変配列に切り替えることにしたのです。この詳細は マージリクエスト を参照してください。GoのマップのバグはGo 1.8では修正されていますが、すべてのベンチマークが移植されているとは言えないため、私は2つを区別しています。とはいえ、GCの時間がマップによって極度に悪化すると予想するだけの理由はありません(バグや実装の不備を除く)。
マニュアルタイミング vs RTSタイミング – 2つ目の注意事項は、ベンチマークはタイミングの設定によって変わるということです。マニュアルタイマーを採用するベンチマークもありますが、その他は実行時間システム統計を用いています。違いが存在するのは、実行時間によってこのシステム統計が使えない場合があるからです(例えばGo)。このプロファイリングを有効にすることで、逆にGCがいくらか影響を受ける可能性も懸念されます。以上の理由から、すべてのベンチマークをマニュアルタイミングに移植します。
最後の注意事項はベンチマーク実装におけるワーストケースです。ワーストケースで繰り延べされたマップの挿入、削除のオペレーションが逆にタイミングに影響を及ぼす可能性があるのも、シンプルな配列に切り替える理由になります。
もっと多くの言語を 私たちのベンチマーク に提供してください。このシンプルなベンチマークはとても一般的で、言語の選択に重大な役割を果たします。 $YOUR_LANGUAGE のGCがどのように働くかを見たい場合は、プルリクエストを送ってください。:) 特に、Javaの一時停止時間がひどい原因を知りたいと思います。理論上はもう少し低くてもいいはずですから。
Goの結果はもっと良いはず?
マップのバグが修正済みのバージョンのコンパイラか、配列を使った時、一時停止時間は7ms以下でした。極めて良い成績ですが、Goチームの プレゼンテーションスライド「1.5 ガベージベンチマークレイテンシ」 で見たベンチマーク結果から、200MBのヒープサイズなら1ms前後の一時停止が実現できるのではと思っていました(GCの時間はバイト数よりもポインタの数に比例する傾向がありますが、残念ながらその情報は提供されていません)。Twitchチームも、Go 1.7で 1ms以下の一時停止時間が得られたと説明しています (ヒープオブジェクトの数は明らかにしていませんが)。
この件について、 golang-nutsメーリングリストに質問を投げてみました 。Rhys Hilterの考えは、これらの一時停止時間は現状未修正のバグが原因ではないかということでした。仕事が残っているのにも関わらず、GCの待機中のマークワーカーがプログラムを妨害するバグです。実験して確かめるため、 go tool trace ^(3) を起動しました。これで、プログラム実行における実行時間のふるまいを可視化できます。

サンプルから分かるように、12msの区間があり、そこではバックグラウンドのマークワーカーが4つすべてのプロセッサで走ってプログラムを妨害しています。前述のバグのせいではないかという強い疑いが湧いてきました。
この時まで、私たちのベンチマークが示す既存の一時停止時間に満足していましたが、上述の問題の修正については注視し続けるでしょう。
先に述べたように、最近、Goチームによる「GCの一時停止時間を1ms以下にする改良」の 発表 に関していろいろな噂や情報が飛び交いました。束の間、期待が高まりましたが、すぐにこの最適化はGCのストップザワールドフェーズのひとつを取り除いたものであることが分かりました。それであれば、私の使っていたベンチマークでは既に1ms未満を達成していたのです。私たちの一時停止時間の問題は、それがGCの並行処理フェーズが原因で起きていたことでした。
それでもなお、これは歓迎すべきGCの改良であり、チームがさらにGCのレイテンシの改善に注力し続けていることの証しでもあります。この最適化についての 技術的な説明 はそれ自体が面白い読み物になっています。
結論
今回の検査で得た最も重要な気づきは、GCは、より低いレイテンシ、より高いスループットのいずれかに最適化されるということです。プログラム(オブジェクトはたくさんありますか? その寿命は長いですか、短いですか?)のヒープ使用量によって、それらのパフォーマンスは良くも悪くもなります。
あなたのユースケースに適しているかどうかを決めるには、根本的なGCのアルゴリズムを理解していることが大切です。また、必ずGCの実装を実際にテストしましょう。ベンチマークは、実装しようとしているプログラムと同じヒープ使用量でなければなりません。そうすれば実際にGCを実装した場合の効果をチェックできます。見てきたように、Goの実装には欠陥もありますが、私たちのケースではその問題は許容範囲内でした。同じベンチマークをもっと多くの言語で見たいと思いますので、ぜひ貢献してください。:)
問題があるとはいえ、GoのGCは他のGC導入言語に比べれば優れています。Goチームはレイテンシの改善に努めており、今もそれは続いているようです。私たちは、理論においても実践においてもGoのGCでハッピーです。
クレジット
- アニメーション作成 James Fisher
- ベンチマーク作成 Gabriel SchererとSanteri Hiltunen
脚注
-
マニュアルで調整したバージョンのパフォーマンスは、ここではGabriel Schererよりもはるかに悪いものでした。最適化が極度にシステム依存であることに原因があるのではないかと思っています。 ↩
-
go tool traceを知ったのはGoを使い始めて3か月後でした。このようなツールはないと思い込み、しょっちゅう落胆していたのです。RTSのパフォーマンスの問題をトラッキングするには、このツールは欠かせません。Haskellの Threadscope によく似ています。近いうちに、go tool traceの使い方のチュートリアルを書くつもりです。 ↩

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事