2016年8月25日
世界最速のフォントレンダラ、font-rsの内部に迫る

本記事は、原著者の許諾のもとに翻訳・掲載しております。
この2年間、フォントのレンダリングソフトについて性能の限界を追究してきました。結論は、Rustで書かれたフォントレンダラ font-rs が、業界標準のFreeTypeに比べて、マグニチュード単位のレベルで速いということです。現時点ではこれは製品レベルのライブラリではなく技術的なデモではありますが、その速さを解析するに十分すぎるほどの理由になります。今回の投稿では、目を見張るようなパフォーマンスがどうやって生まれたのかを正確に記すつもりです。
測定結果
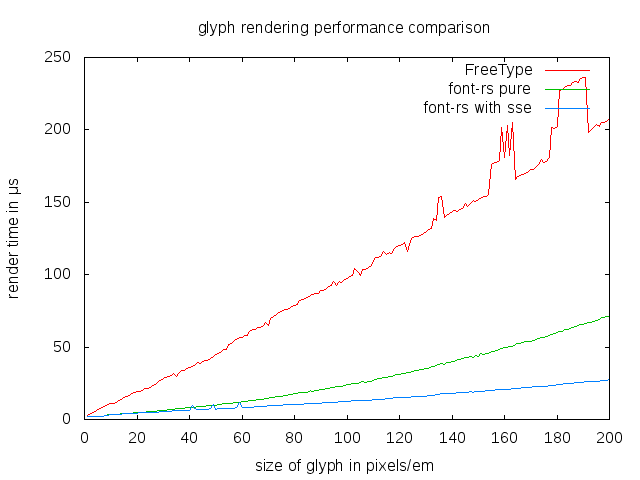
最初に数値について説明します。以下は、pixels/emの値を 1から200の間で変化させて、Roboto Regularフォントの「g」のレンダリングに要した時間を測定した結果です。測定は2.9GHzのXeon E5-2690で行いました。比較したレンダラは、FreeType2.6.5、純正Rustのみのfont-rs、SIMDで加速したバージョンのfont-rsです。
SIMDで加速すると、大きいサイズの方でfont-rsがFreeTypeに比べて大体7.6倍の速さです(42pixels/emがAndroidの解像度xxhdpiのデフォルト値であることを覚えておいてください)。比較的小さいサイズの12pixels/emでさえも、4倍の速さです。CJK書体(世界の中でもフォントのレンダリングにCPU処理の大半を使います)で測定した際には、さらに速さを増しました(12pixels/emで6倍以上)。
注釈:グリフのレンダリング パフォーマンス比較
(y軸)レンダリング時間(単位:マイクロ秒)
(x軸)グリフの大きさ(単位:pixels/em)
レンダリング時間の行先
レンダリングにはCPU集約的な要素が3つあります。それは、フォントからバイナリのアウトラインを分析すること、アキュムレーションバッファへ書き込み、アキュムレーションバッファを統合すること、結果を1ピクセルあたり8ビットのビットマップへ格納することです。
描画中、アキュムレーションバッファには実際の符号付き面積の0以外の差分が(スキャン順に)格納されます。グリフの(エッジに触れず)完全に内部または外部にあるピクセルの値は全て0です。さらに重要なのは、第1番目の差分において、符号付き面積の総和がそれぞれのエッジへの負荷の総和に等しいということです。

符号付き面積について詳細をご覧になりたい方は How the stb_truetype Anti-Aliased Software Rasterizer v2 Works. (stb_truetypeアンチエイリアスのソフトウェアラスタライザv2の仕組み)を参照してください。
下図は詳細を示すグラフです。
注釈:レンダリングスピードの詳細比較
(y軸)時間(単位:マイクロ秒)
(x軸)大きさ(単位:pixels/em)
(凡例)(上から)レンダリング時間の合計/最終アキュムレーション以外全て/描画を除いたパス反復/アキュムレーションバッファへの割り当てのみ
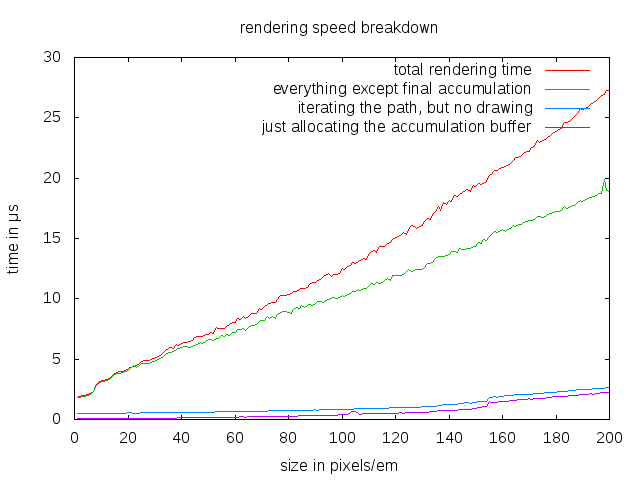
1つ興味深い発見は漸近的計算量と関連する定数因数の間の比較です。アキュムレーションバッファはO(n²)なので、それを割り当て、ゼロを入力するのも二次式です。しかし、些末なオペレーションでありほとんど影響しません。線を描くのはO(n)ですが、大きな定数因数になると、正確な面積を出す複雑な計算を、アウトラインの交わるすべてのピクセルに対して行うためです。最後に、アキュムレーションバッファの統合もO(n²)ですが、60 pixels/emのサイズまでは有意ではありません。非常に大きなグリフの場合は、二次式のパーツが優位に立ちます。
構文解析:割り当てなし
Font-rsはバイナリフォントデータを解析するのに460ナノ秒を消費し、線のシーケンスと二次ベジェ曲線に変換します。解析の対象が30ほどなので、各パス要素に対し15ナノ秒です。
多くの場合、バイナリパーサーはバイナリフォントデータにアクセスし、結果を内包するデータストラクチャ(ベクターであることが多い)を生成する関数として記述します。しかし、結果を収集し、輪郭ごとにベクターにするだけで870ナノ秒が必要で、解析時間が3倍になります。普通のテキストサイズ(全レンダリング時間が5マイクロ秒以下)では、この追加時間は重大です。
対して、Rustではパーサーを イテレータ 、繰り返し呼び出す next メソッドのオブジェクトとして記述するのがほとんど通例です。これらのイテレータの状態はたいていヒープ領域よりも、スタック領域に割り当てられます。このため、構文解析は完全にヒープ領域の割り当てなしに起こるのです。
font-rsのパーサーは2つのイテレータで書かれ、構成されています。1つ目のパーサーはバイナリフォントデータを曲線上と曲線外の点のシーケンスに分析します。2つ目は、それを線とベジェ曲線に変換します。Rustスタイルのイテレータを別の言語で書くこともできますが、滅多にお目にかかりません。しかし、C++の ライブラリ が存在し、標準化を意図していることは知っておいてもよいでしょう。
アキュムレーションバッファに描画する:隙間なく即座に
様々なレンダラが様々な戦略でどのようにアキュムレーションバッファを格納するか、その中にいつ描画オペレーションを配列するかを決めています。多くのレンダラ(FreeTypeを含む)は、 スパース 表現を使い、多くのエントリーがゼロのままである事実を活かそうとしています。さらに、レンダラのほとんどはスキャンライン、あるいは少なくともストライプによってレンダリングを配列しようとします。この場合、アウトラインはスキャンライン配列には格納されていないため、再配列を要します。
font-rsのアプローチでは、アキュムレーションバッファをシンプルな、ピクセルあたり4バイトの浮動小数の配列として表現します。よって、バッファのアドレス指定は分岐のない1つの機械命令です。また、全ての描画オペレーションはパーサーからバッファへと行なわれます。
スパース表現は常にトレードオフです。ある点で、ストラクチャの空の部位に触れないことで、スパース表現そのものが離れ、オーバーヘッドの限界を超えることがあります。このトレードオフがどこで交差するかは、データシートの問題とサイズによります。しかし、次のセクションで見ていきますが、隙間のない表現は、データ並行処理が可能な場合には大きな利点です。
最後の統合: SIMD
統合は4つのオペレーション、累積合計、絶対値(非ゼロワインディング規則を実装するため)、[0, 1]への固定、そして8-bit ピクセルへの変換からなり、全てのピクセルに適用されます。 累積合計のためのSMIDテクニック を使い、その他3つも戸惑うほど似ています。加えて、累積合計はたいていレイテンシ制限があるため、2つをインターリービングすることで別々に行うよりも速くなり得ます。
font-rsでもう1つ革新的なのは、各行のループをリスタートするでのはなく、累積合計をバッファ全体に走らせることです。これによって基本的に分岐予測ミスによるオーバーヘッドが生じず、内部ループは「ホット」な状態で稼働します。さらに、幅は2のべき乗の境界に合わせる必要もありません。
私は内部ループを約 15行のSSSE3固有 で記述しました。Rustには(まだ)SIMD専用のサポートがないので、これらをC言語で書きました。幸い、C言語の関数をRustのコードベースに落とすのは 非常に簡単です 。大きなサイズの場合、2倍以上の驚異的なスピードアップが起こります。より小さいサイズでは、O(n) パス描画の圧力があり、それほど大きなインパクトは得られません。
将来
もしかすると、font-rsは製品レベルで使われるようになるかもしれません。その未来はコミュニティの関心次第です。もう1つの強い可能性は、FreeTypeのような既存レンダラがfont-rsのアイデアを取り入れることです。いずれにしても、font-rsはどのようなパフォーマンスができるかを示しました。Rustが「クラス最速」モジュールを作っている訴求力ある言語だということもデモに説得力を与えています。基本的には、低いレベルのコードの断片では、C++と同様のパフォーマンスですが、言語や標準ライブラリのレベルにおいては、優れたサポートとなるものです。低いレベルの断片をつなぎ合わせ、問題のない高いレベルの構成物に変えられるのです。
速いレンダリングの未来はソフトウェアではないかもしれません。GPUベースのレンダリングの新たな進歩、特に マルチチャネル符号付きの距離視野 は、より高いパフォーマンスを実現する可能性すらあります。しかし、これらのテクニックは時間のかかるプロセスステップ、中間のビットマップを保持する大きなメモリを要します。それでも、バイナリフォントからレンダリングされたピクセルデータへ移すタスクを行う場合には、font-rsのようなレンダラは間違いなく最初から最後までレイテンシが低いのです。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事