2022年1月24日
Rustのビルドを高速化する方法
(2021-09-04)by Aleksey Kladov
本記事は、原著者の許諾のもとに翻訳・掲載しております。
Rustコードのコンパイルが遅いことは誰でも知っています。しかし筆者は、世の中のほとんどのRustコードはコンパイルをもっと速くできると強く感じています。
例えば、つい最近の記事にこのように書かれていました。
一方、Rustでは、プロジェクトやCIサーバーの性能にもよりますが、 CIパイプラインの実行に15~45分かかります。
これは筆者には理解できません。GitHub Actions上にあるrust-analyzerのCIの所要時間は8分です。しかも、これは100万行の依存関係に加え、20万行の独自コードが記述されたとても大規模で複雑なプロジェクトでの話です。
確かに、Rustは根本的な部分で非常にコンパイルが遅いのは間違いありません。Rustはジェネリクスのジレンマにおいて「遅いコンパイラ」を選び、全体的な設計思想としてコンパイル時間よりもランタイムを優先しています(この点に関する優れたシリーズ記事を紹介します:1、2、3、4)。しかし、rustcは低速なコンパイラではありません。rustcは業務用コンパイラの中で最も先進的なインクリメンタルコンパイル手法を導入し、適切なモジュール(クレート)に基づくコンパイルモデルを活用しており、細かい部分まで最適化されています。Rustプロジェクトの高速なコンパイルは、たとえ一般的ではなくても現実に可能です。ただし、それにはいくつかの注意点と専門知識が必要です。
それでは、私たちがrust-analyzerのコンパイル時間を妥当な範囲に収めるために実施した対策を詳しく見ていきましょう。
ビルド時間を気にする理由
筆者が明確にしておきたいのは、プロジェクトのビルド時間を最適化するのは、ある意味ではあまり価値のない取り組みだという点です。コンパイル時間を削減しても、ユーザーにとっての直接的なメリットはごくわずかで、あくまで本質から外れた問題にすぎません。
とはいえ、コンパイル時間はほぼすべての作業の所要時間を倍増させます。追加機能の搭載、コードの高速化、要件変更への対応や、新しいコントリビュータの勧誘にもビルド時間が関わってきます。
コンパイル時間には間接的な影響もあります。コンパイラの作業を待つだけなら比較的小さな問題です。大きな問題は、コードのコンパイルの間に、集中力が失われたり、さらに悪いことに気分が変わって別の作業をしたくなったりすることです。コンパイラにとっては1分の仕事でも、人間にとっては1分以上の時間が無駄になります。
こうした影響を定量化するのは困難ですが、直感的にはプロジェクトの1人当たりのコードが数千行を超えると、ビルド時間は非常に重要になると思います。
ビルド時間の最も恐ろしい特徴は、気づかないうちに増大する点です。プロジェクトが小規模なうちは、ビルド時間は許容できる範囲にとどまるでしょう。プロジェクトが成長するにつれて、ビルド時間もゆっくりと増加し始めます。放っておくと、後でコントロールできる状態に戻そうとしても困難になる恐れがあります。
プロジェクトのコンパイル時間がすでに許容できないほど遅くなっている場合は、以下のような事態を招きます。
-
ビルド時間の改善には時間がかかります。なぜなら、「変更を試し、ビルドを実行して、改善度を測定する」ためのイテレーションに毎回長い時間がかかるからです(ビルド時間はすべての作業の所要時間を倍増させますが、それにはビルド時間自体も含まれます)。
-
簡単に成果を上げるのは難しいでしょう。ランタイムのパフォーマンスとは異なり、パレートの法則は機能しません。1,000行のコードのうち、パフォーマンスに影響するのは100行かもしれませんが、コンパイル時間は1行ごとに増えます。
-
ビルド時間がわずかに短縮されても、それが十分に蓄積するまでは、取るに足らないと感じられるでしょう。コンパイル時間を5秒削減できたとして、元々のビルド時間が5分であれば非常に大きな成果ですが、1時間であればそうでもありません。
-
同様に、ビルド時間がわずかに増加しても誰も気づきません。
これには文化的な要因もあります。あなたがプロジェクトに参加して、そのCIに1時間かかるとしたら、1時間のCIは普通だと思うようになるでしょう。
うれしいことに、ビルド時間の問題を解決するには簡単なコツがあります。
銀の弾丸
ビルド時間は、問題になる前から注視し、修正する必要があります。ビルド時間の短縮は、最適化に関する問題としてはかなり簡単です。直接的なフィードバックを得る方法は明確で(ビルド時間を測るだけです)、プロファイリングツールも数多く存在し、目安となるベンチマークを考案する必要さえありません。課題となるのはコンパイラ全般のパフォーマンスの向上ではなく、特定のプロジェクトのビルド時間の最適化です。一般に、ビルド時間の最適化のように本質的でない問題では、ほとんどのケースでこのような好ましい特徴が見られます。つまり、エンジニアリング問題としての定義が明確で、その解決策もよく知られている傾向があります。
コンパイル時間に関して唯一難しいのは、実際に問題になるまで、それが問題だと認識できない点です。ですから、この記事から学べる最も有益なポイントは、もしあなたがRustプロジェクトに取り組んでいるなら、今日はビルドの最適化のためにある程度時間をとり、今後もなるべく、たまには最適化を行うべきだということです。
これでソフトウェアエンジニアリングの話は終わったので、ようやく実用的なプログラミングのアドバイスに入ることができます。
bors
筆者は、注目すべき主要な指標の1つとして好んでCI実行時間を利用します。
理由の1つはCI時間それ自体が重要だからです。機能の開発がCIに制約されない場合でも、CI時間は1つの作業を終えて次の作業を始めるための意識の切り替えによる負担に直接影響します。CI完了を待ちながら、5件のプルリクエスト(PR)を同時並行で処理するのは生産的ではありません。またCIが長くなると、作業を独立したまとまりに分割しにくくなります。1つのタイポを訂正するのにPRタブを30分開いておく必要があるなら、次の機能のブランチで修正を実行する方が良いでしょう。
しかし、それより大きな理由は、CIが標準的なベンチマークになることです。ローカル環境では、コンパイルは徐々に行われ、変更の内容によってビルド時間は大きく異なります。通常、コンパイルするのはプロジェクトの一部です。こうした変動が避けられないため、ローカル環境におけるビルドでは、ビルド時間に関する継続的なフィードバックを十分に得られません。一方、標準化されたCIはすべての変更に対して実行されるので、直接比較可能なデータを時系列で把握できます。
CIによる標準化を推進するには、“ロケットサイエンスのルール”ではなく、メインブランチのあらゆる段階でCIを確実に実行するためのマージボットの設定をお勧めします。筆者は特にborsをよく導入していますが、他の方法もあります。
borsのようなツールには、(導入の決め手には全くなりませんが)妥当なコンパイル時間を実現するうえで2つのメリットがあります。
-
あらゆる変更に対してCIが確実に実行されるようにし、全体的なCIの健全性の維持を推進します。
-
PRに
r+コメントを付けてから「PR merged」の通知を受け取るまでの時間を常にフィードバックループで活用できます。わざわざビルド時間を測定する必要はなく、あらゆるPRがビルドのベンチマークとなります。
CIキャッシング
考えてみれば、優れたキャッシング戦略がCIにとって有効なのはどう見ても明らかです。めったに変更されないものをキャッシュするのは理にかなっていますが、頻繁に変更されるものをキャッシュしても無意味です。つまり、依存関係はすべてキャッシュすべきですが、プロジェクト自体のクレートはキャッシュすべきではありません。
しかし、残念なことに、これを実践している人はほとんどいません。よくあるのが./targetディレクトリ全体をキャッシュしているケースです。これは間違っています。./targetはサイズが大きく、その大部分はCIには不要です。
とはいえ、修正するのはそれほど簡単ではありません。悲しいことに、Cargoを使用しても、./targetのどの部分が持続的な依存関係で、どの部分が変更されやすいローカルなクレートであるかを容易には判別できません。ですから、キャッシュを保存する前に./targetを整理するためのコードを書く必要があります。特にGitHub ActionsではSwatinem/rust-cacheも利用できます。
CIワークフロー
キャッシングは通常、簡単に大きな成果を上げられます。しかし、他にも微調整できる点はいくつか存在します。
まず、CIをcargo test --no-runとcargo testに分割します。CIのどの部分がビルドで、どの部分がテストかを把握するのは必要不可欠です。
次に、インクリメンタルコンパイルを無効化します。CIビルドはスクラッチビルドに近いケースが多いです。通常、変更はローカルな編集とコンパイルのサイクルよりはるかに大規模になるからです。スクラッチビルドでは、インクリメンタルコンパイルによって、新たな依存関係を追跡するオーバーヘッドが増えます。IOの量と./targetのサイズも大幅に増加し、キャッシングの有効性が低下します。
debuginfoを無効化するのも有効です。debuginfoは./targetのサイズを大幅に増大させるため、やはりキャッシングにとって悪影響です。望ましいワークフローに応じて、debuginfoを無条件に無効化することを検討しても良いでしょう。ローカル環境でのビルドにとっても一定のメリットがあります。
ついでに、-D warningsをRUSTFLAGS環境変数に追加して、すべてのクレートの警告をまとめて拒否しましょう。#![deny(warnings)]をコードに追加するのは良いアイデアではありません。すべてのクレートで同じことを繰り返さなければならず、ローカルの開発を不必要に困難にし、ユーザーがコンパイラをアップグレードする際に気力をそがれる恐れがあります。Cargoネットワークのリトライ回数を増やすのも有効かもしれません。
Lockfileを読み込む
他のアドバイスとしては、当然のことですが、利用する依存関係の数を減らし小規模化すると良いでしょう。
ただし、これには微妙な点があります。ライブラリは実際に問題を解決するものです。crates.ioで解決済みの問題に自分でソリューションを導入するのはばかげています。そして、あなたのソリューションがより小規模である保証はありません。
しかし、アプリケーションが解決しようとしている問題と、そうでない問題を認識するのは重要です。数千人が利用するCLIユーティリティを構築している場合、clapとそのすべての機能は絶対に必要です。一方、CIの間に実行する簡単なスクリプトを書いていて、それがチームにしか使用されない場合、コマンドラインのパーシングを単純にして、ビルドを高速化しても構わないでしょう。
これに関して、Cargo.lock(Cargo.tomlではありません)を読み、それぞれの依存関係が自分のアプリケーションを使用する人たちにとってどんな実際の問題を解決するか考えてみるのは、とても有用なトレーニングとなります。自分の環境では依存関係が全く意味を持たないのに気づくのは非常によくあることです。
例を挙げると、rust-analyzerはregexに依存していますが、これは無意味です。私たちには RustとMarkdown向けの厳密なパーサーとレキサーがあるため、ランタイムで正規表現を解釈する必要はありません。さらに、regexは小規模な言語を丸ごと導入するため、依存関係がかなり重いクレートの1つです。この依存関係が存在する理由は、私たちが利用しているロギングライブラリにおいて、以下のような記述が可能になるためです。
RUST_LOG=rust_analyzer=very complex filtering expressionこの場合、フィルタリング式のパーシングは正規表現によって行われます。
これは一部のアプリケーションにとって間違いなくとても便利な機能ですが、rust-analyzerに関しては不要です。env_logger-の単純なフィルタリングで十分でしょう。
同様に冗長な依存関係を特定したら、どこかのfeaturesフィールドを微修正するか、PRを上流に送信して不必要な部分を変更可能にすれば十分です。
時にはもっと大規模なyak shaving(※訳注 問題を解決しようとすると別の問題が出てきて、それを解決しようとするとさらに別の問題が出てくるという繰り返しのこと)が必要な場合もあります。例えば、rust-analyzerはオプションでjemallocクレートを利用しており、そのビルドスクリプトはfs_extraと(よりによって)pasteを呼び出します。ここでの理想的な解決策はもちろん、堅牢で安定した純正なrustメモリアロケータの導入です。
最適化の前にプロファイリングを
ここまで常識的な対策を実施してきたので、そろそろビルド時間を削減する前に測定してみましょう。今回使用するツールはCargoのtimingsフラグです(ドキュメントはこちら)。悲しいことに、筆者はこの機能の質の高さと洗練性を十分に表現できるだけの雄弁さを持ち合わせていません。そこで、ここでは愛 ❤️ を表明するだけにとどめ、ドライに説明を続けさせてください。
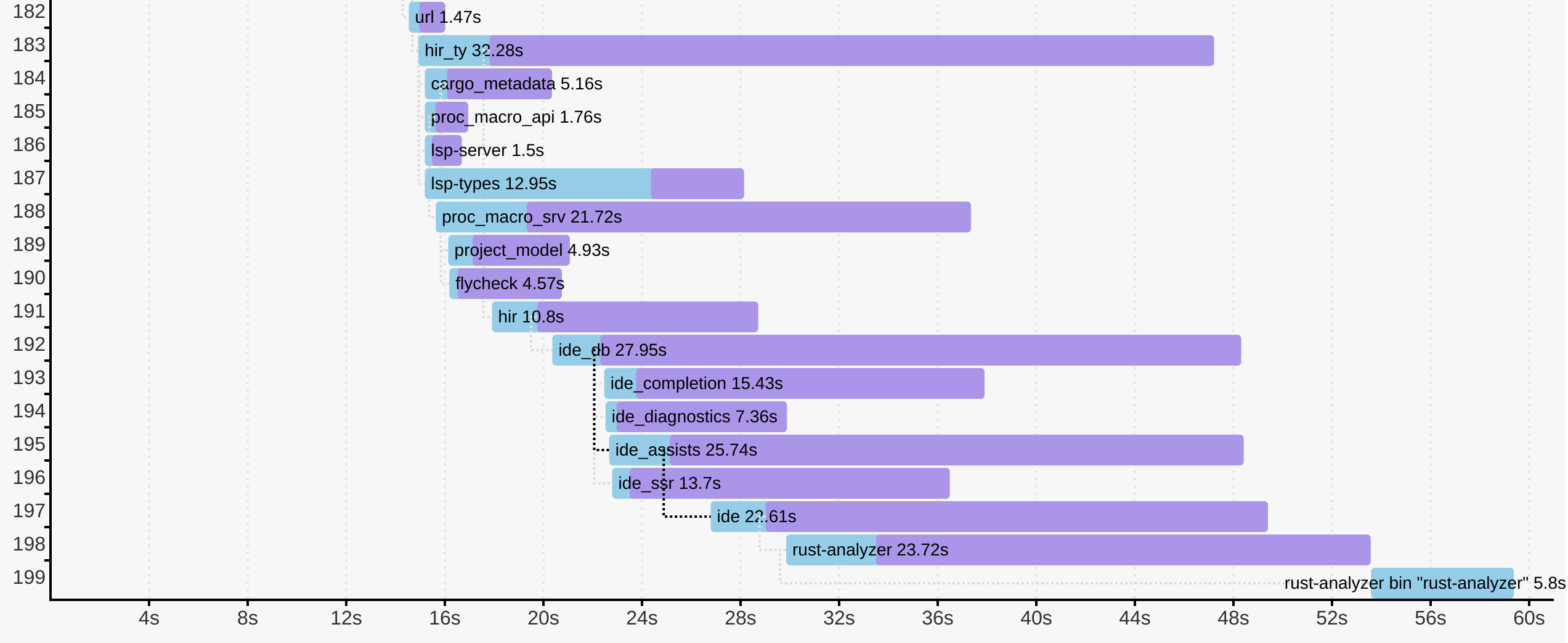
cargo build -Z timingsは、ビルド中のプロファイリングデータを記録し、それをとても読みやすくて情報が詰まったHTMLファイルとして出力します。これはナイトリー版の機能であるため、+nightlyトグルが必要です。とはいえ、ときどき手動で実行すればよいだけなので、実際は問題ありません。
以下はrust-analyzerの例です。
cargo +nightly build -p rust-analyzer --bin rust-analyzer \
-Z timings –release
各クレートのコンパイルにどれだけ時間がかかったかだけでなく、個々のコンパイルがどのようにスケジューリングされ、各クレートのコンパイルがいつ開始されたかや、クリティカルな依存関係も分かります。
コンパイルのモデル:クレート
ここからは重要な最後のポイントを説明します。クレートは依存関係の有向非巡回グラフを形成し、マルチコアのCPUではこのグラフの形状がコンパイル時間に大きく影響します。
以下はすべてのクレートを順番にコンパイルする必要があるため、コンパイルに時間がかかります。
A -> B -> C -> D -> E一方、以下のグラフでは並列処理が可能な部分が大幅に増えるため、コンパイルははるかに速くなります。
+- B -+
/ \
A -> C -> E
\ /
+- D -+並列処理とインクリメンタリティにも関係があります。2番目の大きいグラフでは、Bを変更してもCとDを再びコンパイルする必要はありません。
Rustのコンパイル時間について不満を言うと、最初に返ってくるアドバイスは「コードをクレートに分割しよう」です。しかし、これはさほど簡単ではありません。最初のグラフのような形状になっている場合、大きな成果は見込めません。アプリケーションを2番目のグラフのように構築するのが重要となります。つまり、共通用語のクレート、複数の独立した機能、そしてすべてを繋ぐ「葉」の役割を果たすクレートから成る構造です。クレートの最も重要なプロパティは、そのクレートが(推移的に)依存していないクレートはどれかということです。
もう1つの重要な検討事項は、最終的なアーティファクト(最も一般的にはバイナリ)の数です。Rustは静的リンク方式であるため、2つの異なるバイナリが同一のライブラリを使用する場合、各バイナリにはそれぞれ別にリンクされたライブラリのコピーが含まれます。仮にn個のバイナリとm個のライブラリが存在し、各バイナリが各ライブラリを使用するとき、リンクを作成する際の作業量はm * nです。そのため、アーティファクトの数は最小限に抑えると良いでしょう。よくあるテクニックの1つが、BusyBoxのような多機能ナイフ型の実行可能ファイルです。このアイデアは、同じ実行可能ファイルを、異なる名前を持つ複数のファイルとしてハードリンクするものです。プログラムは0番目のコマンドライン引数を参照することで、自らが呼び出されたファイル名を把握し、それをサブコマンドの名前として有効に利用できます。ただし、Cargoに特有の注意点として、./examplesと./testsフォルダ内の各ファイルはデフォルトで新たな実行可能ファイルを作成します。
コンパイルのモデル:マクロとパイプライン化
しかし、Cargoにはそれ以上にスマートな機能があります。それはコンパイルのパイプライン化です。Cargoはクレートのコンパイルをメタデータとコード生成の段階に分け、メタデータの段階が終わるとすぐに依存するクレートのコンパイルを開始します。
このとき、手続きマクロ(とビルドスクリプト)との間に面白い関係が発生します。rustcはクレートのメタデータを計算するために手続きマクロを実行する必要があります。これは手続きマクロがパイプライン化できないことや、手続きマクロが完全にコンパイルされてバイナリコードになるまで、その手続きマクロを使用するクレートがブロックされることを意味します。
一方、手続きマクロはRustコードをパースする必要がありますが、これはかなり複雑なタスクです。この機能を担うデファクトスタンダードのクレートであるsyn/serdeはコンパイルに長い時間がかかります(肥大化しているからではなく、単純にRustのパーシングが難しいからです)。
これは一般に、プロジェクトにおいて、コンパイル中のCPU稼働率のプロファイルに syn/serde は大きく穴をあける傾向にあることを意味します。(訳注: syn/serde によって、 コンパイル中にCPUに対して大きく負荷がかかります)そのため、手続きマクロはそれが十分に活用される場合のみ使用し、cargo -Z timingsグラフでsynの前にクレートを配置することがかなり重要です。
ただし、後者は難しい場合があります。手続きマクロの依存関係はいつの間にか増大する可能性があるからです。こうした依存関係はフィーチャーフラグに隠れていることが多く、それらのフィーチャーフラグが川下のクレートによって有効化されるケースが問題となります。以下の例を考えてみましょう。
便利なユーティリティ型、例えばSSO文字列がsmall_stringクレートに存在するとします。シリアル化を実装するには、実は継承は必要ないため(Stringへの委譲で十分です)、serdeとの(任意の)依存関係を追加します。
[package]
name = "small-string"
[dependencies]
serde = { version = "1" }SSO文字列は非常に便利な抽象型なので、コードベース全体で使用されます。その後、例えばJSON APIを公開する必要がある葉のクレートに、serdeフィーチャーを持つsmall_stringと、deriveフィーチャーを持つserde自体との依存関係を追加します。
[package]
name = "json-api"
[dependencies]
small-string = { version = "1", features = [ "serde" ] }
serde = { version = "1", features = [ "derive" ] }ここで問題になるのは、json-apiがserdeのderiveフィーチャーを有効化するため、small-stringとその逆依存関係のすべてがsynのコンパイルを待つ必要があることです。同様に、あるクレートがsynのフィーチャーの一部にしか依存していなくても、クレートグラフ内の別の何かがすべてのフィーチャーを有効化すると、元のクレートにはそのフィーチャーも追加されます。
これは必ずしも破滅的な状況ではありませんが、依存関係グラフがフィーチャーの存在によって厄介なものとなり得ることが分かります。うれしいことに、cargo -Z timingsは問題の発生を気づきやすくしてくれます。もっとも、いったい何が間違っているのか明らかになるとは限りませんが。
手続きマクロは、もっと直接的にコンパイルを遅くする原因にもなります。マクロが大量のコードを生成する場合、コンパイルに一定の時間がかかります。というのも、一部のマクロは少量のソースコードを書くことを可能にしており、それ自体は害がないように感じられますが、そのコードが大量のロジックに拡大するのです。代表的な例はシリアル化です。筆者は、数値からJSONへの変換(とその逆)がコンパイルにおいて驚くほど大きな部分を占めていると気づきました。ここではクレートのグラフ全体について考えるのが役立ちます。シリアル化は、システムの境界の葉のクレートで実行するようにすべきです。システムの根幹の付近にシリアル化を導入すると、すべての中間クレートがビルド時間のコストを負担することになります。
いずれにせよ、面白いポイントは、手続きマクロは本質的にコンパイルが遅いわけではないことです。むしろ、ほとんどの手続きマクロはRustをパースする必要があるか、あるいは多くのコードを生成するために遅くなっています。ときには、マクロはsynなしでパースできる単純な構文を受け入れ、それに基づいてわずかなRustコードを生成する場合もあります。有効なRustの生成は、そのパーシングに比べれば全く複雑ではありません。
コンパイルのモデル:モノモーフィゼーション
以上でクレートレベルのマクロに関する問題はカバーしたので、コードレベルの問題を詳しく見ていきましょう。主に注目するのはジェネリクスです。ジェネリクスがどのようにコンパイルされるかを理解するのは非常に重要です。Rustの場合はモノモーフィゼーションによって実現されます。以下のありふれたジェネリック関数について考えてみましょう。
fn frobnicate<T: SomeTrait>(x: &T) {
...
}Rustがこの関数をコンパイルするとき、実際には機械語は出力しません。代わりに、関数の本体の抽象表現をライブラリに保存します。実際のコンパイルは、関数を特定の型の変数でインスタンス化したときに行われます。直感的な理解のためにC++の用語を借用するならば、 frobnicateは「テンプレート」です。これは変数Tに具体的な型が代入された際に実際の関数を生成します。
言い換えると、以下のケースでは
fn frobnicate_both(x: String, y: Widget) {
frobnicate(&x);
frobnicate(&y);
}機械語のレベルで2つの異なるfrobnicateのコピーが生成されます。両者は変数の詳細な処理が違っていますが、それ以外は同一です。
これではとても困ると思いませんか?どうやら大規模なジェネリック関数を書くと、それをインスタンス化するために複数の型のコードを少し書いただけで、コンパイラに大きな負荷がかかるようです。
ここで残念なお知らせがあります。現実は想像よりもはるかに悪いのです。型が異なっていない場合さえ、重複は発生します。例えば、以下のようなダイヤモンド型の4つのクレートがあるとしましょう。
+- B -+
/ \
A D
\ /
+- C -+frobnicateはAで定義され、BとCで使用されます。
// A
pub fn frobnicate<T: SomeTrait>(x: &T) { ... }
// B
pub fn do_b(s: String) { a::frobnicate(&s) }
// C
pub fn do_c(s: String) { a::frobnicate(&s) }
// D
fn main() {
let hello = "hello".to_owned();
b::do_b(&hello);
c::do_c(&hello);
}このケースではfrobincateをStringでしかインスタンス化していませんが、モノモーフィゼーションはクレートごとに行われるため、コンパイルは2回となります。BとCは別々にコンパイルされ、それぞれにdo_*関数の機械語が含まれるため、frobnicate<String>を必要とします。最適化が無効な場合、rustcはテンプレートのインスタンス化を直接の依存関係と共有できますが、親が共通の依存関係とは共有しません。最適化が有効な場合、rustcは直接の依存関係とさえモノモーフィゼーションを共有しません。
言い換えると、Rustのジェネリクスによって、多くのクレートでコンパイル回数が意図せず二次関数的に増加する恐れがあります。
これ以上悪いことがあり得るのかと考えているなら、その答えはイエスです。筆者は、モノモーフィゼーションの実際の単位はコード生成単位だと考えており、そのため重複は1つのクレート内でも発生する可能性があります。
インスタンス化に注意
ジェネリクスには、重複に加えて、コンパイル時間を利用者に転嫁する問題もあります。ジェネリック関数のコンパイル時間のコストの大部分はその機能を使用するクレートが負担する一方、定義が記述されたクレートはコードを一切生成せず、コードの型をチェックするだけです。何が、どこで、なぜインスタンス化されるかが全く明確でない場合(例)もあるため、ジェネリックAPIを直接追跡するのは困難です。
しかし、うれしいことに、その作業は必要ありません。そのためのツールがあるからです。cargo llvm-linesは、特定のクレートでどのようなモノモーフィゼーションが起きているかを教えてくれます。
以下は最近の調査に基づく例です。
$ cargo llvm-lines --lib --release -p ide_ssr | head -n 12
Lines Copies Function name
----- ------ -------------
533069 (100%) 28309 (100%) (TOTAL)
20349 (3.8%) 357 (1.3%) RawVec<T,A>::current_memory
18324 (3.4%) 332 (1.2%) <Weak<T> as Drop>::drop
14024 (2.6%) 332 (1.2%) Weak<T>::inner
11718 (2.2%) 378 (1.3%) core::ptr::metadata::from_raw_parts_mut
10710 (2.0%) 357 (1.3%) <RawVec<T,A> as Drop>::drop
7984 (1.5%) 332 (1.2%) <Arc<T> as Drop>::drop
7968 (1.5%) 332 (1.2%) Layout::for_value_raw
6790 (1.3%) 97 (0.3%) hashbrown::raw::RawTable<T,A>::drop_elements
6596 (1.2%) 97 (0.3%) <hashbrown::raw::RawIterRange<T> as Iterator>::nextこの表は各ジェネリック関数について、生成されたコピーの数とその合計サイズを示しています。サイズは関数のエンコードに必要なllvm irの行数として非常に大ざっぱに測定されています。有益な情報としては、llvmはジェネリック関数を持っていません。関数テンプレートをインスタンス化によって実際の関数に変えるのはrustcの仕事です。
インスタンス化のコントロール
モノモーフィゼーションの落とし穴が分かれば、大まかな対策も明らかになります。それはジェネリックコードをクレート間の境界に設置しないことです。大規模なシステムを設計するときは、一連のコンポーネントとして設計したうえで、各コンポーネントが具体的な作業を行い、ジェネリックでないインターフェースを持つようにします。
型安全性や作業効率を改善するためにジェネリックインターフェースが必要な場合は、必ずインターフェースのレイヤーを薄くし、ジェネリックでない実装にすぐに委譲するようにします。ここで埋め込むべき関数の典型的な例は、str::fsモジュールに記述され、パス上で動作するさまざまな関数です。
pub fn read<P: AsRef<Path>>(path: P) -> io::Result<Vec<u8>> {
fn inner(path: &Path) -> io::Result<Vec<u8>> {
let mut file = File::open(path)?;
let mut bytes = Vec::new();
file.read_to_end(&mut bytes)?;
Ok(bytes)
}
inner(path.as_ref())
}外側の関数はパラメータ化されており、効率良く使用できますが、川下のあらゆるクレートで毎回コンパイルされます。とはいえ、この関数は非常に小規模で、stdでコンパイルされるジェネリックでない関数にすぐ移譲されるので問題ありません。
引数としてパスを必要とする関数を記述する場合、&Pathを利用するか、あるいはimpl AsRef<Path>を利用してジェネリックでない実装へ委譲しましょう。APIの効率が気になって、implトレイトを利用するくらいなら、innerをうまく使うべきです。関数を呼び出すのに使用される構文と同様に、コンパイル時間も効率の大きな要素となります。
第2の典型的なケースはクロージャです。基本的に&dyn Fn()をimpl Fn()よりも優先しましょう。パスの場合と同様に、implベースの優れたAPIを薄いラッパーとして、dynベースの実装が大部分の作業を実施するのが良いでしょう。
これに関する別のアイデアは、「ジェネリックなインラインのホットパスと、コンクリート(具体的)なアウトラインのコールドパス」です。once_cellクレートには、以下のような面白いパターンが記述されています(以下は簡略化済み。実際のソースはこちら)。
struct OnceCell<T> {
state: AtomicUsize,
inner: Option<T>,
}
impl<T> OnceCell<T> {
#[cold]
fn initialize<F: FnOnce() -> T>(&self, f: F) {
let mut f = Some(f);
synchronize_access(self.state, &mut || {
let f = f.take().unwrap();
match self.inner {
None => self.inner = Some(f()),
Some(_value) => (),
}
});
}
}
fn synchronize_access(state: &AtomicUsize, init: &mut dyn FnMut()) {
// One hundred lines of tricky synchronization code on atomics.
}このinitialize関数は2回ジェネリックになります。最初にOnceCellが、保存された値の型とともに変数化され、次にinitializeがジェネリックなクロージャ変数を受け取ります。initializeの仕事は、(たとえ同時に多くのスレッドから呼び出されたとしても)最大で1つのfしか実行されないようにすることです。この相互排他タスクは、コンパイル時間を改善するために、実際は具体的なTやFに依存せず、ジェネリックではないsynchronize_accessとして実装されています。理想的にはinit: dyn FnOnce()引数を使用したいのですが、現在のRustでは記述できないのが欠点です。このケースでは、let mut f = Some(f) / let f = f.take().unwrap()が標準的な次善の策となります。
結論
大体こんなところでしょうか!要点を振り返っておきましょう。
ビルド時間はプロジェクトに取り組む人間のトータルな生産性に大きく影響します。ビルド時間の最適化はエンジニアリング課題としては単純で、ツールも存在します。恐らく難しいのは、取り組みが少しずつ後退しないようにすることです。この記事がそのための十分なモチベーションとインスピレーションになるように願っています。大まかな目安として、20万行のRustプロジェクトのビルド時間を妥当な範囲に収めるためにある程度最適化すれば、GitHub Actions上のCIの所要時間は約10分となるはずです。
/r/rustでの議論はこちらです。
本記事はOne Hundred Thousand Lines of Rustシリーズの一部です。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事