2017年3月21日
効率的にゲームを更新する
(2017-01-16)by Amos Wenger
本記事は、原著者の許諾のもとに翻訳・掲載しております。
先日、 Things that can go wrong when downloading(ダウンロード時に上手くいかないものごと) についての記事を書きました。その記事に、ネットワークの問題から妥当でないコンテンツ、不完全なハードウェアに至るまで、ゲームを最初にインストールする際に発生することがある一連の原因をリストアップしました。
今回の記事では、ゲームの前バージョンが正常にインストールされているときに、そのゲームを新しいバージョンにアップグレードするのにどんな方法が使えるかについて考えます。
圧縮
あるユーザが利用できる帯域の量は、通常、一定です。ユーザのインターネットアクセスの論理的な最大速度は20mbps、100mbps、1gbps、または、国によってはそれよりずっと低いものです。
私の自宅にはまだ光ファイバが引かれていないので、アクセスは20mbpsという遅さですが、インターネットに文句を言いたくなる度に、もっと悪い状況にいる人のことを思い出します。この、 1分間ローディングした後のサイト表示 のスクリーンショットを撮った人のように。20mbpsなら、総合的に考えれば、そんなに悪くないのでしょう。

これは、 itch.io サーバから何かデータをユーザに転送するために、それとほぼ同じ時間がかかるということを意味します。ユーザのインターネットアクセスをコントロールすることはできないので、私たちにできるのは、ユーザがゲームをプレイできるようにするのに必要な、伝送すべきデータの量を減らすことです。
従来、これは伝送前にデータを圧縮することによって行われています。圧縮は難解な分野で、その研究はこの記事の範囲外ですが、その要点は、繰り返しを利用するということです。例えば、誰かに電話で次のシーケンスを伝える必要があるとします。
banana banana banana banana banana
そのためには、大声で「banana」と繰り返さなくても、「bananaが5回」と言えば済みますね。これは、次のような、もう少し複雑なシーケンスにも使える方法です。
banana cherry apple pie
banana cherry apple source
banana cherry apple pizza
これを伝えるには、次のように言えます。
* “banana cherry apple”を”X”とする。
* シーケンスは、”X pie X source X pizza”。
ここであなたは、知らず知らずのうちに辞書ベースの圧縮手法を行っています。”X” => “banana cherry apple”という対応付けは、あなたが作った辞書の一部です。その対応を決めた後は、それを3回使ってスペースを節約しています。想像してみましょう。あなたは、何年も研究と微調整を重ね、新たな術策を弄した末、ついに新時代の圧縮アルゴリズムを手に入れたのだと。

注釈:データ圧縮会議はどうだった?みんな素晴らしかったけど、僕が”rm”を発表しはじめたら恐れ入ってたよ。
私たちは今、「無損失」圧縮アルゴリズムに注目しています。無損失とは、シーケンスを完全に圧縮してから解凍しても、シーケンスが全く変化しないことを意味します。「損失のある」アルゴリズムとは、友達に電話で「果物についての無意味な言葉の塊だ」と伝えるようなものです。友達に要旨は伝わりますが、途中で情報がいくらか抜け落ちています。
実は、損失のある圧縮は画像、動画、音声には非常に有用です。
そういうデータには、できる限り忠実度を維持しながら(解凍結果がオリジナルと同じように見える)の、高い圧縮率(圧縮されたデータがかなり小さくなる)が求められます。
ゲームの場合は、データの損失や変更は一切、許されません。少しでも変わると、ゲームは動作できなくなります。その上、ゲームのファイルのいくつかは、すでに損失のあるアルゴリズムで圧縮されているのです!
実世界の圧縮
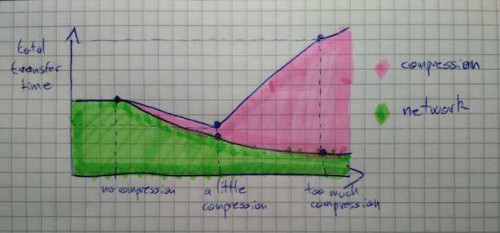
実際の事例について考えましょう。itch.ioのコマンドラインアップローダ butler は、そのアップローダを使って開発者がアップロードする全てのファイルに brotil という圧縮形式を使用します。その概念は、ほんの少し圧縮すると、全体の転送時間を短縮できる、ということです。圧縮しすぎると、圧縮に要する時間が長くなり、単にデータを伝送するよりも遅くなってしまいます。その様子を、下の図にそれぞれの時間を重ねた図で示します。

品質レベルを設定することによって、所望する圧縮の程度を調節することができます。品質レベルが低いほど圧縮度が低い一方で必要な計算量が少なく、品質レベルが高いほど圧縮度が高い一方で多くの計算量(すなわち長い時間)が必要になります。
では、実際のデータを見てみましょう。Linux用の Overland のビルドを例にとります。
* 未圧縮のゲームは 748MiB
* 品質レベル1で圧縮すると、 340MiB (私のマシンで所要時間17秒)
* 品質レベル4で圧縮すると、 327MiB (25秒)
* 品質レベル6で圧縮すると、 316MiB (51秒)
* 品質レベル9で圧縮すると、 311MiB (ほぼ4分間)

この結果から分かるように、品質レベルを上げていくとメリットは減っていきます。最も大きく変わるのは、「非圧縮」と「少しの圧縮」の間です。
だからといって、高い圧縮度が無益だというわけではありません。単に、初回アップロードに使わないだけで、後で、アップロードされたサイズよりもダウンロードサイズを小さくするために itch.io サーバ上のデータを再圧縮するときに、高い圧縮度が使用されます。
差分符号化
ここまでで、ユーザがゲームをプレイするためにダウンロードする必要のあるデータの量を減らすために圧縮が役立つことが分かりました。
- 圧縮によって、開発者がアップロードを高速化できる
- 圧縮によって、プレイヤーがすぐゲームをプレイできるようになる
- 圧縮は、帯域費用を節約するために役立つ(プレイヤーがダウンロードするデータには1バイトごとに料金がかかるから)
しかし、ゲームをアップデートするときに、圧縮よりも良い方法があります。前述した下記のシーケンスを、すでに電話で友達に伝えていると想像しましょう。
banana cherry apple pie
banana cherry apple source
banana cherry apple pizza
そのシーケンスが次のように変わったとします。
banana merry apple pie
banana merry apple source
banana merry apple pizza
この場合、全体を繰り返して伝えるのではなく、単に友達に、全ての”cherry”が”merry”に変わったことを伝えれば済みます。または、全ての”ch”が”m”に変わったことだけ、つまり、より少ないデータでも内容を伝えることができます。
友達が古いデータから新しいデータを再構築できるための最も少ない指令セットを見つけることが、差分符号化の本質です。
Rsync
差分符号化の単純な形が、Andrew Tridgellが1996年に考案した rsyncアルゴリズム です。
その概念はかなり単純です。まず、古いシーケンスを同じサイズ(最後の1つを除く)のブロックに分けます。これまで電話でしつこく友達に伝えてきたシーケンスでやってみましょう。
(bana)(na c)(herr)(y ap)(ple )(pie)
これらのブロックにはそれぞれの位置とハッシュがあります。ハッシュとは、元のものより短いが、元のものをほぼ一意に特定するものです(単純化しすぎた説明ですが、大丈夫です)。私たちの例では、ブロックの最初の文字をハッシュとします。次のようにブロック分けされます。
- (bana)は、位置0、ハッシュは‘b’
- (na c)は、位置4、ハッシュは‘n’
- (herr)は、位置8、ハッシュは‘h’
- (y ap)は、位置12、ハッシュは‘y’
- (ple )は、位置16、ハッシュは‘p’
- (pie)は、位置20、ハッシュは‘p’
(ple )と(pie)はハッシュが同じですね。これはハッシュ衝突と呼ばれますが、大丈夫です。アルゴリズムが上手くいくことを示すために、ここでは、かなり弱いハッシュを使います。
さて、新しいシーケンスをスキャンして、その中に、既知のブロックがどれか入っているか探してみましょう。
(bana)na merry apple pie
先頭の4文字から始めます。ハッシュを計算し(ここでは、最初の文字‘b’をとります)、それを使って、類似している可能性のある古いブロックを調べます。古いシーケンスの位置0に、ハッシュが‘b’のブロックがあります。ハッシュが衝突する場合があるので、内容を比較しなければなりません。実際、(bana)と(bana)の内容は同じですね。これは古いブロックを再利用できることを意味します。
ブロック単位で次に進んで、新しいシーケンスのスキャンを続けます。
bana(na m)erry apple pie
ハッシュが‘n’の古いブロックがありますが、その内容は(na m)ではなく(na c)なので、再利用できません。同様に、(a me)から、( mer)、(merr)、そして、(ry a)までは、それと同じ内容の古いブロックはないので、電話で友達にそのデータを伝えるしかありません。ここまでの作業指示は、次の通りです。
- 長さが4のブロックについて作業している。
- 古いシーケンスの位置0にあるブロックを再利用する。
- “na merr”と記述する。
スキャンを続けます。
banana merr(y ap)ple pie
ハッシュが‘y’の古いブロックがあり、その内容は(y ap)なので、それを再利用できます。ブロック単位で次に進みます。
banana merry ap(ple )pie
ハッシュが‘p’の古いブロック、(ple )と(pie)があります。その2つを比較して、(ple )を再利用すると決めます。作業指示は全部で次のとおりです。
- 長さが4のブロックについて作業している。
- 古いシーケンスの位置0にあるブロックを再利用する。
- “na merr”と記述する。
- 古いシーケンスの位置12にあるブロックを再利用する。
- 古いシーケンスの位置16にあるブロックを再利用する。
- 古いシーケンスの位置20にあるブロックを再利用する。
位置12、16、20にあるブロックは隣接しているので、作業指示を次のとおりに減らすことができます。
- 長さが4のブロックについて作業している。
- 古いシーケンスの位置0にあるブロックを再利用する。
- “na merr”と記述する。
- 古いシーケンスの位置12からの3つのブロックを再利用する。
これが、rsyncの基本的な働きです。電話では大して役に立ちませんが、この方法は、コンピュータには実に適しています。 実際の syncアルゴリズムには2つのハッシュがあります。第1のハッシュは弱いものです(計算負荷は低いが衝突の可能性が高い)。第2のハッシュは強く、計算負荷が高いので、第1のハッシュがマッチしたときにのみ計算されます。
第1のハッシュには、 回転する 、という優れた性質があります。[0…n]ブロックのハッシュを計算するには一定量の作業が必要ですが、その作業を行った後には、[1…n+1]の計算は前の結果を再利用できるので、ずっと速くなります。これは特に、nバイトのブロックを調べてマッチするまでバイト単位で移動するrsyncに適しています。
詳細については、 rsyncの文書 を参照してください。
これが、私たちが itch.io で行う第1レベルの差分符号化です。開発者がゲームの新バージョンをアップロードするときに行われます。
- butler が、まず、旧バージョンのハッシュのセットをダウンロードする。
- 次に、新バージョンをスキャンして、どのブロックが再利用可能なのか、ハッシュに基づいて調べる。
- その次に、「再利用指示」(同じ内容の古いブロックが見つかった場合)を、新しいデータ(再利用できない部分について)と共に伝達する。
そのステップで作成されたパッチは、次のようになります。

BSDiff
rsyncは良い方法ですが、あまり役に立たない場合もあります。
次のシーケンスについて考えます。
(bear)(fall)
これが次のように変わるとします。
(dear)(hall)
あまり違いはありませんよね? まだ電話で友達と「パッチ伝言ゲーム」をやっているなら、”b”が”d”に変わり、”f”が”h”に変わったと言うだけで終わりです。でも、rsyncで考えるとすれば、古いシーケンスの4文字ブロックと同じ4文字ブロックは新しいシーケンスにはないので、古いデータを全部捨て、新しいシーケンス全体を「新規データ」として含めなければなりません。
しかし、この変化には興味深い点があります。アルファベットの中で、‘d’は‘b’の2文字後、‘h’は‘f’の2文字後にあります。各文字の位置の差で新しいシーケンスを作ると、次のようになります。
b e a r f a l l
- d e a r h a l l
-----------------
= 2 0 0 0 2 0 0 0これを使うと、非常に優れた圧縮が可能です。
- 2と記述し、次に0を3つ記述する。
- もう一度それを行う。
これで終わりです。
これが実生活で何の役に立つのかと思うかも知れませんが、ファイルが複数の箇所で同じ差分だけ変更されることはよくあります。
記載先のページ番号付きで関係者のリストが作られている電話帳を考えてみましょう。電話帳の最初に数ページが追加されると、全部の関係者のページ番号を(それと同じページ数の分だけ)調整しなければなりません。
その点で、実行ファイルは電話帳によく似ています。関数を追加すると、大抵は、他の多くの関数のアドレスが変更になります。
Colin Percivalが2003年(rsync文書の7年後)に設計した「素朴な」バイナリ差分符号化アルゴリズム、 bsdiff は、こういう場合にとても役に立ちます。
もちろん、私たちの例は非常に単純なものです。実際には、たったの8文字ではなく、数メガバイト、時には数ギガバイトのデータを調べます。難しいのは、古いデータと新しいデータの間で、良好な「ほぼ近い一致」を見つけることです。
接尾辞のソート
ほぼ近い一致、つまり近似一致(パッチのための差分を保存)を探す時にまず行うべきことは、古いデータと新しいデータとの間の正確な一致を見つけることです。テキスト内で、ある単語を探すことを想像してみると分かりやすいと思います。
テキスト内で任意の単語を比較的速く見つけたい時に構築できるデータ構造として、接尾辞配列というものがあります。この接尾辞配列を構築するには、そのテキストの全ての接尾辞をソートしなければなりません。
テキスト”rabbit”の接尾辞は、”rabbit”、”abbit”、”bbit”…などです。これを辞書的な観点からソートしてみると、結果は以下のようになります。
- “abbit”(接尾辞2)
- “bbit”(接尾辞3)
- “bit”(接尾辞4)
- “it”(接尾辞5)
- “rabbit”(接尾辞1)
- “t”(接尾辞6)
つまり、”rabbit”の接尾辞配列は(2 3 4 5 1 6)となります。次に、例えば”it”の文字列をその配列内で検索したい場合、二分探索と呼ばれる処理を行います。
二分探索
二分探索の背景にある考えは、ソートされた値のセットがある場合、最初に真ん中の値と比較することができるというものです。検索している値よりも真ん中の値が小さければ、前半を除外して後半を検索します。逆に、検索している値よりも大きければ、後半を除外して前半を検索します。

注釈:
20を検索
(1 2 7 9 11 17 20 24 36 41)
17は20よりも小さいので前半を除外
(17 20 24 36 41)
24は20よりも大きいので後半を除外
(17 20)
17は小さいので前半を除外
(20)
見つかりました!
最終的に、サイズ1となったセットが残ります。その中の唯一の要素が検索していたものであればビンゴです。そうでなければ、検索していたものはそのセットに含まれていないことになります。
接尾辞配列を使って最長一致する接尾辞を検索する方法も同様ですが、数字を比較する代わりに、文字列を辞書的な観点で比較します。

注釈:
“rabbit”内で”abba”を検索
(“abbit”、”bbit”、”bit”、”it”、”rabbit”、”t”)
“bit”は”abba”よりも大きいので後半を除外
(“abbit”、”bbit”)
残った接尾辞は2つのみで、”ab”の2文字により共通箇所が多いのは”abbit”。
正確な一致が見つかると、 bsdiff アルゴリズムは次のステップとして、その一致を、少なくとも文字の半分以上が一致している限りにおいて、前方および後方の双方に”拡張”しようとします。これにより、より長い近似一致が得られるというわけです。そして、両方の領域の差を計算して、差分を保存します。これを、パッチ内の新規データ(近似も含め一致するものはありません)も含め、それぞれの近似一致で繰り返します。
bsdiffはパイプラインにどのように適合するか
ここまでをまとめてみましょう。
- ゲームの各ビルドは圧縮して配布することで、そのサイズを小さくできる。
- パッチとしてアップグレードを配布することで、より多くの帯域幅を節約できる(既存の古いバージョンのゲームを活用する)。
- アップロード時にはrsyncパッチが構築されるものの、2回目のパスでbsdiffを使えば、より小さなパッチを作成できる。
bsdiffを実行する。
- 全ての古いファイルと全ての新しいファイルを用意する。
- そのため、bsdiffは開発者のマシン(ディスク上に最新のビルドしかない)ではなく、 itch.io サーバ上(高速インターネット回線で全てのビルドにアクセスできる)で実行する。
- まず、古いファイルの接尾辞配列を計算する(”接尾辞をソート”する)。
- 次に、新しいファイルをスキャンし、近似一致を探す。
1つ言っていないことがありました。それはbsdiffが、あるファイルを、別のファイルを利用して再構築するということです。しかし、ゲームのビルドには多くのファイルが含まれています。では、どの新しいファイルがどの古いファイルに対応しているかを知るには、どうすればいいのでしょうか。ファイルは、リネームや分割、または結合されている可能性もあるため、名前だけを当てにすることはできません。
幸いにも、シンプルな解決策があります。rsyncパッチには”古いファイルからNブロックを再利用する”といったような命令が含まれていましたよね。rsyncパッチをスキャンして、これらの命令を探せばいいのです。bsdiffが対象とするのは、ブロックが最も多く再利用されている古いファイルです。
実際のゲーム、 Mewnbase を例にとりましょう。
- 最新の2つのビルドは 82MiB
- rsyncパッチは 33MiB
- bsdiffパッチは 174KiB
前述したように、bsdiffは(接尾辞の)ソートとスキャンの2段階で行われます。仮に2003年のオリジナルの実装を再利用したとすると、このゲームでは以下のような結果になります。
- ソートに13.6秒
- スキャンに1秒
数字はデータにより異なりますが、総じて、ソートの方が、コストがはるかに高いと言えるでしょう。
Larsson-Sadakane法の並列化
幸い、元のbsdiffによって使用される接尾辞のソートアルゴリズム(いわゆる Larsson-Sadakane法 )は、比較的簡単に並列化することができます。
ここでは詳細に多くは触れませんが、基本的にLarsson-Sadakane法には、接尾辞配列をより速く構築するための仕掛けがあります。その仕掛けは、文字列のそれぞれの真の接尾辞は、別の接尾辞の接尾辞でもあるという観察(Karp、MillerおよびRosenberg)に基づくものです。1番目のシンボル、2番目、3番目、4番目という流れで全ての接尾辞をソートする代わりに、1番目、2番目、4番目、8番目、16番目などのソートに以前のパスを再利用することで、パスの回数をnではなくlog(n)に減らします。
それぞれのパスが接尾辞配列をバケットに分割し(後に全体でマージされる)、そのバケットがソートされます。各バケットは個別にソートされるため、その作業は異なるコアにより並行して行うことができます。私が実装したLarsson-Sadakane法の並列バージョンでは、前のパスの結果を含む、n整数の配列に1つ追加したものを使用しています。そのため、他のスレッドによって書き込み中のメモリから、複数のコアが読み取りを試みることはありません。
実際のところ、これは相対的に有効です。12個のコアを使用した状況で、Mewnbaseの特定のパッチを最適化した時のランタイムは以下のようになります。
- ソートに4.86秒(以前は13.6秒)
- スキャンに1秒
スキャンに関しては、同じ接尾辞配列で同じコードが動くため、時間は全く変わっていませんが、ソートは約3倍、高速化しました。これは良いニュース(bsdiffがついに高速化!)でもありますが、一方で悪いニュースでもあります。12個のコアを使って3倍のスピードアップというのは、さほど良好な数字ではありません。ソートのためにバケットをコアに配布して、それを全体で同期させるというのは、ここでは無視できないコストとなります。
接尾辞の最新ソートアルゴリズム
接尾辞のソートについては、過去数十年にわたり研究が続けられています。その理由は、皆さんが私のように容量の小さなアップデートを熱望しているからではなく(私は望んでいますが)、ソートがバイオテクノロジーに応用できるからです。DNAは4つの記号が連続したもので、異なるゲノム間で共通する配列を迅速に見つけることは、非常に重要と考えられています(ただ、彼らは当然のように128以上のコアを持つスーパーコンピュータで研究をしていますが、そこをつっこむのは控えておきます)。
上記の理由から、Larsson-Sadakane法(1999)よりも新しいSACA(接尾辞配列構築)アルゴリズムが考案されました。最近の興味深い研究としては、Ge Nong(中国広州の中山大学教授)の研究が挙げられます。彼の論文の1つである”An optimal suffix array construction algorithm(最適な接尾辞配列構築アルゴリズム)”は、タイトルから私たちが期待する通りの内容となっています。
それがどのような仕組みのアルゴリズムなのか、私自身、それについての研究が不十分でここでうまく説明はできませんが、そのベースはSA-IS(接尾辞配列を線形時間で求めるアルゴリズム)でinduced sortingという方法(DC3に似たものと思いますが、間違っていたらご指摘ください)が使われているようです。より詳しい情報をお求めの方は、 induced sortingについてはこちら を、 SA-ISの論文についてはこちら をご覧ください。
その接尾辞配列の出力については全く同じなので、bsdiffの第1段階(ソート)に対して当座の代替方法とすることも可能です。そのアルゴリズムの golang実装 を使用すると、ランタイムは以下のようになります。
- ソートに9.9秒(以前は13.6秒)。
- スキャンに1秒。
他の データセット では、違いはより大きくなります。
- dictwords (200KiB)のソートでは、Larsson-Sadakane法の場合は51ミリ秒、gosacaの場合は21ミリ秒
- dictwords (2MiB)のソートでは、Larsson-Sadakane法の場合は1237ミリ秒、gosacaの場合は355ミリ秒
入力が大きくなるほど、Larsson-Sadakane法と比較してgosacaがより高速化しています。ただし、並列化したLarsson-Sadakane法に比べると全体的にはまだ遅いです。gosacaを並列化する方法があればいいのですが…
“最適なSACA”の並列化
Larsson-Sadakane法を並列化した時には、最終的な接尾辞配列は全く同じでした。”最適なSACA”について、それが同じように並列化されるかについては十分に理解していませんが、もし 古いファイル全体 の接尾辞配列を構築する代わりに、それをP個の区間に分割して、それらの区間について並列に接尾辞配列を構築した場合、どうなるでしょうか。

予想通り、このやり方の方が高速化します。8コアのマシンでの結果は以下の通りです。
- dictwords (200KiB)のソートは、
- 単一区間の場合、21ミリ秒
- 2つの区間を並列化した場合、12ミリ秒
- 4つの区間の場合、8ミリ秒
- 8つの区間の場合、7ミリ秒
- dictwords (2MiB)のソートは、
- 単一区間の場合、355ミリ秒
- 2つの区間を並列化した場合、171ミリ秒
- 4つの区間の場合、95ミリ秒
- 8つの区間の場合、72ミリ秒
もちろん、これは特効薬ではありません。この問題は、P個の異なる接尾辞配列(古いファイルの各区間ごとに1つの配列)ができあがることです。そして、bsdiffの”スキャン”段階を実行する時には、どの区間にベストな一致があるかが不明なため、それぞれを調べなければなりません。

では、サイズがはるかに大きいゲーム、 Aven Colony のおけるパッチの最適化の場合はどうでしょうか。ゲーム単体の最近のバージョンの容量は11GiBです。シングルコア(オリジナル)のgosacaを使用すると、次のようになります。
- 532MiBから125MiBへのサイズの短縮
- ソートにかかる時間は25分
- スキャンにかかる時間は5分20秒
区間を2つに分ければ、スキャンに関しては恐らく時間は2倍(約10分)になると思われますが、ソートは13分まで短縮できるはずです。つまり処理時間は35分から23分に短縮できることになり、スキャンの遅延分を考慮に入れてもメリットはあります。
ただし、より多くの区間を使用することは得策とは言えません。区間を4つにしてソートを7分にまで短縮できたとしても、スキャンの遅延が20分と大きくなり、合計ランタイムは27分で、先ほどよりも時間がかかってしまいます。
スキャンの並列化
ここまでで、古いファイルを区間に分割して接尾辞配列を構築すると、パッチの最適化が全体的に高速になるということが分かりました。ただし、スキャンが逆に遅くなるため、メリットは最小限に止まります。

では、P個のコアが利用可能な場合に、どうやったらスキャンのコストを削減できるでしょうか。2つの戦略が考えられます。
1つ目は、P個の接尾辞配列があるので、bsdiffのスキャンプロセスが最長の完全一致を探す時は常に、それらを全て並列化して検索するという方法です。しかし実際には、並列化する時に典型的な同期コストがかさみ、それぞれの接尾辞配列を順番に調べるよりも結果がわずかに悪化しました。
2つ目は、新しいファイルの”ブロック”上で、スキャン段階を並行して実行することです。それぞれの作業単位(新しいファイルの数メガバイトでbsdiffを実行)がはるかに大きいため、同期コストはずっと低くなります。bsdiffの各スキャンは同じ接尾辞配列(ソート後は読み取り専用)から読み取り、近似一致のリストが構築されます。そして、それらが元に戻され、パッチが記述されます。

これは実に良好な結果をもたらしました。ランダムに生成された~800KiBのサンプルファイルに関して、複数の異なる区間で同様のランダムな変更がある場合、
- 順次的なbsdiffでは8.10秒(ソートに7秒、スキャンに1秒)
- 区間が2つのbsdiffでは4.48秒(ソートに3.47秒、スキャンに938ミリ秒)
- 区間が4つのbsdiffでは3.10秒(ソートに2.09秒、スキャンに939ミリ秒)
- 区間が8つのbsdiffでは2.74秒(ソートに1.64秒、スキャンに1.03秒)
なお、ここに掲載した”スキャン”の数値には、近似一致のために新しいデータと古いデータを差分し、それを zstd で圧縮されたprotobufメッセージとして記述する時間も含まれています。
ここで注目すべき点は、直感的に見て分かるように、ソートの時間は減る一方で、スキャンの時間は比較的一定を維持しているということです。技術的にはより多くの作業が実行されますが、より多くのコアに均等に分散されるため、同じままとなるのです。
暫定的な結果
11個のパーティション(コア数:1)を使用することで、Mewnbaseを最適化する時のランタイムは以下のようになります。
- ソートに1.54秒(以前は13.6秒)
- スキャンに866ミリ秒(以前は1秒)
全体的に、パッチの最適化により、時間は14.84秒から2.84秒に短縮され、5.22倍の高速化となりました。
より大規模なゲームのAven Colonyでは、処理時間の合計が69分から10分に短縮されました。こちらは、ほぼ7倍の高速化です。
bsdiffのこれらの改善は全て、 itch.io を利用するプレイヤーへのアップデートをより迅速に提供するのに役立ちますし、帯域幅のコストも抑制してくれます。
リンク
この記事に興味を持たれた方には、 Things that can go wrong when downloading(ダウンロード時に上手くいかないものごと) もお勧めです。ゲームを最初にインストールする時に直面する問題について、簡単に説明しています。

前述の記事に記載されたテクニックは、 itch.io refinery で使用できるものです。itch.io refineryとは、初期リリースとプレイテスト、そして itch.io app で既にリリースされているゲームのためのカスタマイズ可能なツールセットのことで、Linux、Windows、そしてmacOSで使うことができます。

ここに掲載されているものは全て、私たちの差分化とパッチングのオープンプロトコルである wharf でサポートされています。ソースコードは、私たちの GitHubのページ で閲覧可能です。
itch.io の詳細を知りたい場合は、以下もご覧ください。
- 私たちの Aboutページ
- Leaf Corcoranのオリジナル投稿、 Announcing itch.io(itch.ioの告知)
- Leafの2015年の記事、 Running an indie game store(インディーゲームストアの運営)
最後に、この記事で例として使用されているゲームを購入したい場合は、ここをクリックしてください。
※訳注: 原文 下部に購入リンクが貼られているので、そちらを参照してください。
ここまで読んでいただきありがとうございました。また次回の記事で。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事