2018年11月15日
機械が私たちの偏見を継承する仕組み

本記事は、原著者の許諾のもと�に翻訳・掲載しております。

機械は言語の処理を学習する際、人が書いた文章のサンプルから性別や人種的な偏見を継承します。
トルコ語では、”彼(he)”、”彼女(she)”、”それ(it)”を表すための代名詞が、”o”の1つしかありません。”o”の代名詞が含まれるトルコ語の文章をGoogle翻訳で英語に翻訳する場合、翻訳アルゴリズムは英語のどの代名詞が”o”に相当するのかを推測することになります(性別が不明な場合、大抵は”彼”)。そして、アルゴリズムは ジェンダーバイアス(性差に基づく偏見) を反映しながら、”彼は医者です”、”彼女は看護師です”、”彼は勤勉です”、”彼女は怠け者です”のような形で文章を翻訳するのです。言語処理の学習に際して、多くのアルゴリズムは人が書いたニュース記事やWikipediaなどの文章を参考にしており、こうした言語モデルから単語間の関連付けを行っています。しかしそうすることで、例えば” 「彼」:「彼女」には「聡明だ」:「可愛らしい」 が対応する”といったような性差別的な問題も生じてきます。人間社会における言語を通じた暗黙の偏見モデルによって、機械は私たちの文化に蔓延する性差別主義や人種差別主義の薫陶を受けることになるのです。
John Searleは、彼の”中国語の部屋”の思考実験を通じてあることを提示しました。それは、機械はそれ自体の振る舞いの内容を理解しなくても、人間の行動を模倣できるということです。また、機械がそれ自体の振る舞いを顧みることなく害を及ぼし得るという事例は増加しています。一般的に機械は、”意識”を持たない限り、日々の生活の中で脅威にはならない有用なツールであると思われがちです。しかし、それは 誤解 だとカリフォルニア大学のコンピュータ科学者、Stuart Russellは言います。コンピュータのアルゴリズムが、その作成者と同様のジェンダーや人種的偏見を持つ可能性は十分にあり得ます。そしてそうしたアルゴリズムが、例えば求職者の選定や犯罪者に対する刑罰内容の(類似の罪を犯した犯罪者に基づいた)決定支援など、幅広い用途で使われた場合、結果的に適正のある女性求職者が競争の激しい就労機会から除外されたり、無実の人が刑務所に拘留されたりするような事態が起こるかもしれません。一定のグループへの偏見を持つ人工知能を使用した結果は不公平であり、不道徳でさえあります。AIに”そういうつもり”がなくても脅威にはなり得るのです。それを考慮すると、そのうち偏見を抱えながら意識を持つAIが出てくるかもしれません。その時には、AIがジェンダーや人種に基づいて判断しないよう、アルゴリズムから偏見をなくす取り組みが要求されるようになるでしょう。
“中国語の部屋”は、部屋の中にいる男性がマニュアルに従って中国人の女性にメッセージを書くというアナロジー(例え)を通じて、コンピュータは何も理解していなくても人々とコミュニケーションができるということを示したものです。中の男性は中国語が全く話せませんが、マニュアルの指示に従いながらその女性と会話を続けます。このシナリオについては、実際に中国語でコミュニケーションするための情報を十分に含むマニュアルをその男性用に書くことは恐らく不可能なため、思考実験の域を出てはいませんが、人間の文章に基づいたコンピュータ用のマニュアルが作成されています。このアナロジーにおける男性がコードの命令に従うコンピュータだとした場合、そしてそのコードに性差や人種に関する偏見が含まれていた場合、その男性はきっと自分の言っていることを理解しないまま、それらの偏見を表現してしまうでしょう。コンピュータによる偏見をなくすためには、そのマニュアルを書き直す必要があります。
アルゴリズムにおける性差別語
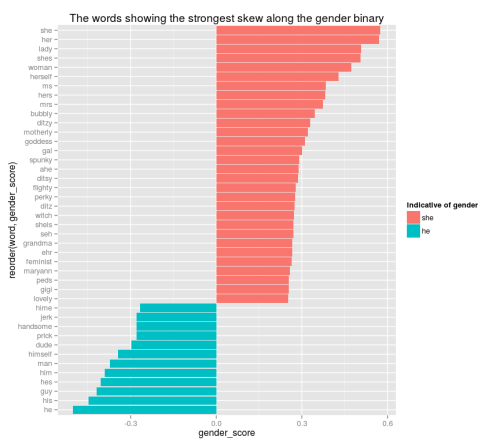
Microsoftの研究員、Adam Kalaiもそうした必要性を感じています。彼はボストン大学と協力し、人間の文章を通じて性差別的な言語を取り込んでいるGoogle翻訳のようなアルゴリズムから偏見をなくす取り組みを行っています。Kalaiと彼のチームが焦点を当てたのは、コンピュータが言語を処理するために”辞書”として使用するコードの一種、 単語の分散表現(単語埋め込み) です。単語の分散表現では、単語間の関係は数字に符号化されます。”姉妹”、”兄弟”、”母親”、”父親”という言葉は、関連する単語としてクラスタリングされており、”彼(he)”と”彼女(she)”のような単語1組を分散表現のアルゴリズムに入力すると、”彼”:”彼女”と同じ関係を持つ2つの単語、例えば、”コンピュータプログラマ”:”専業主婦”が出力されます。
Kalaiたちが単語の分散表現から始めたのは、多くのプログラムの動作にそれが必要だからです。コンピュータのプログラマは、それを大きなプログラムに組み込み、それらのプログラムが、どのような検索結果や広告、ソーシャルメディアのコンテンツを表示するかを決めます。この単語の分散表現には既存のものがあるため、そのアルゴリズムが必要とする300次元のベクトル空間をゼロから開発する必要はありません。しかし、既存のアルゴリズムが持つ偏見を修正することなしにそれを引き継いだ場合、支障が出ることがあります。例えば、コンピュータプログラミングの職に対して従業員の候補者数を減らすアルゴリズムが偏見を持っていた場合を考えてみてください。もしそのアルゴリズムがコンピュータのプログラミングと男性らしさを密接に関連付けていたとしたら、候補者の条件に適合するのは男性の履歴書だと判定するでしょう。
Kalaiたちはアルゴリズムに特定の関係性を無視させる新しい方法を開発し、その方法を、関係性が問題になり得る全ての事例に対して一般化しました。彼らが注目したのは、”actress(女優)”や”queen(女王)”のような、英語においてジェンダーが指示される単語と、性差を表した場合に問題が生じる”nurse(看護師)”や”sassy(生意気:主に女性に対して使われる)”のような単語です。そして問題が生じる単語のタグ付けを外し、中性的なものとして分類しました。

線の上の単語は、性差を表した場合問題があるため、中性的なものとして分類されています。
画像: Adam Kalai
単語の分散表現に関するKalaiたちの取り組みについて、他のコンピュータプログラマたちも着目してくれることを望みますが、機械に偏見を持たせるような媒体は他にもあります。しかし、そうした媒体の偏見をなくす方法については、それほど明らかではないかもしれません。以下では機械の画像ラベリング技術、特に顔認識ソフトウェアや、広告に使用される提案アルゴリズムにある偏見について見ていきます。
顔認識ソフトウェアのレイシズム
Googleフォトのソフトウェアは、写真の中の物体や顔を認識し、それを人、動物などについて分類することによって写真を保存・整理しています。しかし、このプログラムの 顔認識 は、肌の色の濃い人々を認識して区別するようには訓練されていません。Jacky Alcineという人は、ある写真の中でアフリカ系アメリカ人の友人にゴリラというラベルが付けられているのを見つけて、ぞっとするほど驚きました。Googleは、さまざまな人種の従業員にGoogleフォトのテストをさせたと主張しています。しかし、このソフトウェアは明らかに、肌の色の濃い人々について、もっと包括的で正確になるように改善する必要がまだあります。友達や自分自身が別の生物種としてタグ付けされているのを見せられたら、侮辱的だし、心が傷つけられるでしょう。特に、レイシストの論法を正当化するためにそれが使われていたなら。

iPhone Xの顔認識ソフトウェアは同じ人種の人々の顔を識別できなかったため、中国人女性のスマホのロックを、その女性の同僚に対して解除してしまい、プライバシーの侵害につながりました。
それに似た事例 では、Hailingという中国人女性のiPhone Xの顔認識機能が、同僚の顔をスキャンした後でスマホのロックを解除しました。宣伝では、この顔認識ソフトウェアで他人がiPhone Xのロックを解除できる確率は”100万分の1″だとうたわれていました。そこで、Hailingはスマホのカメラ機能がどこか故障しているのだろうと考えて、スマホを交換しましたが、新しいスマホも同僚の顔をスキャンするとロックを解除しました。この事例では、カメラが同じ人種の人々の顔を識別できなかったためにプライバシーの侵害が起こりました。そのせいで個人的な機密情報が漏洩したかもしれません。ユーザのプライバシー権の侵害を確実に防ぐために、この顔認識ソフトウェアは、さまざまな人種の人々について再評価する必要があります。
ステレオタイプを永続化させる提案アルゴリズム
Googleなどの検索エンジンで使われている提案アルゴリズムは、ユーザに訓練されることによって、人種やジェンダーに関するステレオタイプを永続化させる広告を表示するようになることもあります。Google検索で、アフリカ系アメリカ人に一般的には結び付く名前を検索すると、犯罪歴をアーカイブする会社の広告が表示されます。ハーバード大学の教授でデータプライバシーが専門のLatanya Sweeney博士が、自分の名前を検索してみると、犯罪歴がないのにも関わらず、”Latanya Sweeney, Arrested?(Latanya Sweeney、逮捕?)”と書かれた広告が出てきました。そこで教授は、犯罪歴に関する広告が表示される見込みについて調査しました。2100の他の”黒人系”の名前について検索をかけた結果、”黒人系”の名前が検索された場合は”白人系”の名前と比較して、このような 広告 が表示される見込みが25%高いことが判明しました。ここで、”提案アルゴリズムは、当初はこの広告を”黒人系”と”白人系”の両方の名前について表示していたが、アフリカ系アメリカ人のように聞こえる名前を検索したときにだけ広告をクリックするというユーザの選好を学習した”という仮説が立てられます。アルゴリズムはユーザの偏見を学習し、その後の検索では、それが考慮に入れられました。そして今、このアルゴリズムは、”黒人系”の名前が検索されたときに犯罪歴をアーカイブする会社の広告を表示し、人々が見たがりそうなものを見せることによって、人々の偏見を増強しているのです。
技術を通して人々の偏見を増強する危険は脅威ですが、ユーザの行動からもまた、いかに人がステレオタイプを内面に持っているかが分かります。他の研究からは、女性が男性よりも低賃金の仕事の広告を見せられることが多いとの結論が得られましたが、これは、もともと女性が高賃金の仕事の広告は自分たちには当てはまらないと純粋に信じて、その広告をクリックすることが少ないからかもしれません。ユーザの経験をカスタマイズするように設計されたアルゴリズムを使うとき、人が既に持っている偏見をそのアルゴリズムが考慮する場合には、結果として差別が生まれることがあります。
偏見をなくし、客観的な機械動作を優先しよう
アルゴリズムから偏見をなくす方法は、Kalaiたちが単語の分散表現から偏見を取り除いた例のように、いくつかありますが、偏見に備えて警戒するようにアルゴリズムをプログラムするための対策は優先されていません。アルゴリズムには人間に似た偏見があり、それが、ある人々のグループに対する差別を増強します。ですから、偏見に備えて警戒するために、アルゴリズムをプログラムするときに予防措置をとることは人の責任です。将来には、意識のあるマシンが自身の偏見を認識する熟考能力を持つようになるでしょうが、今のところ、コンピュータにはフェミニスト批判をするような能力はありません。コンピュータが偏見と予断のない仕事を行うようになるまでは、コンピュータを、人が毎日の生活に役立てるために使える客観的なツールと考えることはできません。マシンの動作に客観性を確保するために、科学的な方法に客観性を確保する原理と同じものを適用できます。つまり、マシンの動作の結果が恣意的でなく偏見のない方法で処理されているならば、マシンの動作に客観性があると考えることができます。
偏見のないアルゴリズムから生まれる結果が人にとって不適切になることもあります。例えば、Google翻訳が、性差があいまいな他言語の代名詞に遭遇したときに、客観的な翻訳では、制限された文脈からは性別が不明だということを示すために、センテンス内でその代名詞のあるべき位置に空白が入るかもしれません。このような結果にユーザは満足できないかもしれませんが、技術が自らの欠点を認める方が偏見のある結果を表示するよりも良い場合が多いと思います。Googleフォトの画像ラベリング技術に、ラベリング結果をダブルチェックする機能を導入することもできるでしょう。例えば、人だけが写っている他の写真に混じって、ある写真の中にゴリラというラベル付けがあったとすれば、その写真は動物園で撮られたものではない可能性が高いので、不正確な結果が出たとアルゴリズムで結論付けることもできるでしょう。人を動物としてラベル付けする危険を考えれば、Googleフォトが、写真の中の人と動物を識別できないとユーザに伝える方が、自動的に動物としてラベル付けするよりも良いと思います。アルゴリズムからすぐに偏見をなくすことができないなら、完全にチェックが済むまで公開しない方が賢明です。
あるアルゴリズムから偏見をなくすのは実現不可能だとプログラマが判断したなら、そのアルゴリズムは公共の使用に供するべきではなく、廃止すべきです。コンピュータプログラマと広告主は、提案アルゴリズムの性質を再考すべきかもしれません。こうしたアルゴリズムは消費者としての人々の興味にうまく対応することはできますが、アルゴリズムの本来の性質が、ユーザの好みに追従することである場合には、そのアルゴリズムを客観的なものとして信頼できるか否か見抜くのは困難です。広告に客観的なアルゴリズムを実装すれば、消費者の特定の興味を狙うというターゲティングの目的が崩れるかもしれませんが、広告をクリックしたか否かに基づいて人々をプロファリングしたり差別したりする危険はなくなるでしょう。
世間では、人工知能が”意識を持った”場合にだけ脅威となって人間に敵対してくるのだ、と人々に思い込ませるような話が語られています。それでも、人間に似た偏見を示すコンピュータが直接もたらす結果に対処することは、重要です。そうしたコンピュータのプログラムは性差と人種に基づく差別を行い、機会の不平等を生み出すことがあるからです。私たちが自分たちの偏見でコンピュータに指示を与えてきたのですから、コンピュータから偏見をなくし、客観的に動作するためのツールをコンピュータに装備するのは、私たちの責任です。偏見に備えて警戒するようにコンピュータを訓練することは、人が独力で自らをそのように訓練するためにも役立つでしょう。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事