2017年9月26日
JITコンパイルでの冒険 パート2:x64 JIT

本記事は、原著者の許諾のもとに翻訳・掲載しております。
このシリーズの最初のパート (訳注:POSTDの翻訳記事へのリンクです) で簡単にBFソース言語を紹介し、最適化レベルが高まる4つのインタプリタについて述べました。実際にJITをいじる前に背景を知る上で役に立つと思います。
さらに背景を知る上で有効なのが、2013年に私が書いた『 JITの方法 – 入門編 』という記事です。ここでは、実行時に実行可能なx64機械コードの生成と実際にLinux上で実行するために必要な基本ツールについて説明しました。初めての方はまずこれらの記事を読んでください。
JITの2つの段階
以前 にも書きましたが、JIT手法を2段階に分けて考えると理解しやすいと思います。
- プログラム実行時に機械コードを作成する。
- 作成した機械コードもプログラム実行時に実行する。
BF JITの第2段階は前記事で説明した方法と全く同じ内容です。詳細は jit_utils の JitProgram クラスを参照してください。今回は、BFをx64機械コードに変換する第1段階に集中的して説明します。このシリーズのパート1の定義に基づき、実際にBFコンパイラ(BFソースからx64機械コードへのコンパイル)を開発します。
コンパラ、アセンブラ及び命令のコード化
伝統的にコンパイルは複数の段階に分けられています。実際のソース言語コンパイラは高水準な言語をターゲット固有のアセンブリに変換してくれます。その後、アセンブラはアセンブリを実際の機械コードに変換します ^(1) 。アセンブリ言語は生機械コードよりも重要な利点を多く提供してくれます。顕著な例として以下が含まれます。
-
命令のコード化:レジスタ
r13の内容をインクリメントするためにinc %r13を書いた方が、0x49, 0xFF, 0xC5を書くよりも確かにいいでしょう。一般的なアーキテクチャに命令のコード化を適用するのは 非常に複雑 です。 -
ラベルの命名やジャンプ命令・コール命令の手順:
jl loopを書いた方が、命令のコード化を考えたり、同時にloopラベルの相対的位置を考えたり、差分のコード化を行ったりするよりも簡単です(言うまでもありませんが、差分は命令を間に追加するたびに変わり、その都度再計算する必要があります)。関数においても、アドレスを使うよりもcall fooを使って実行する方が簡単です。
プログラミングの分野において私の指針の1つは、問題の解決策(例:Xを行うためのライブラリ)に飛び込む前に、まずは手動で試してみる価値があるということです(ライブラリを使わずXを手動で行う)。歯を食いしばって問題に対峙することは、提供されている解決策やライブラリのありがたみが実感できる最高の手段です。
この姿勢で進めるので、最初のJITは完全に手書きします。
単純なJIT – 手動でのx64命令のコード化
まず、この記事のJITは simplejit.cpp です。パート1のインタプリタ同様、全ての動作は main から起動され、1つの関数(ここでは simplejit と呼びます)で実行されます。 simplejit はBFソースを介して、x64機械コードをメモリバッファに出力します。最終的には、BFプログラムを実行するためにこの機械コードにジャンプします。
初めの部分は以下のとおりです。
std::vector<uint8_t> memory(MEMORY_SIZE, 0);
// プログラムで使用するレジスタ:
//
// r13: データポインタはmemory.data()のアドレスを保持。
//
// rax、rdi、rsi、rdxはABIごとにシステムコールの作成に使用。
CodeEmitter emitter;
// 変換ループの全体を通して、このスタックは修正場所のオフセットを
// (エミッタコードベクトルの中に)保持。
std::stack<size_t> open_bracket_stack;
// movabs <メモリデータのアドレス>, %r13
emitter.EmitBytes({0x49, 0xBD});
emitter.EmitUint64((uint64_t)memory.data());いつものように std::vector にBFメモリバッファがあります。出力されたプログラム全体で使われている規則をコメントによって明らかにしています。ここでは、 “データポインタ” は r13 にあります。
CodeEmitter はバイトとワードをバイトのベクトルに付加する非常に簡単なユーティリティです。 ここ に全コードがあります。リトルエンディアンの前提を除いてプラットフォームに依存しません( EmitUint64 の場合は、64バイトの最下位バイトから書き込んでいきます)。
ここで出力された機械コードの最初の部分は以下の通りです。
// movabs <メモリデータのアドレス>, %r13
emitter.EmitBytes({0x49, 0xBD});
emitter.EmitUint64((uint64_t)memory.data());しかもいい感じです。ホストからの要素を混ぜ(C++プログラムが出力)、コードのJITを行います。まず、 movabs の使用に注意してください。 movabs は、x64命令で、64ビットの直値をレジスタに置くのに便利です。まさにこれをしたいのです。 memory のデータバッファのアドレスを r13 に置きたいのです。16進値の暗黙のシーケンスを使った EmitBytes の起動の前に、コメントでアセンブリのスニペットがあります。アセンブリは人間の読者のための説明で、16進値は機械が理解するための実際のコードです。
次に出てくるのが、次のBF命令を見て対応する機械コードを出力するBFコンパイルループです。このコンパイラは単一パスで動作します。この後分かりますが、ジャンプ命令の扱いには注意が必要です。
for (size_t pc = 0; pc < p.instructions.size(); ++pc) {
char instruction = p.instructions[pc];
switch (instruction) {
case '>':
// inc %r13
emitter.EmitBytes({0x49, 0xFF, 0xC5});
break;
case '<':
// dec %r13
emitter.EmitBytes({0x49, 0xFF, 0xCD});
break;
case '+':
// メモリはバイトアドレスなので、addb/subbを変更に使用
// addb $1, 0(%r13)
emitter.EmitBytes({0x41, 0x80, 0x45, 0x00, 0x01});
break;
case '-':
// subb $1, 0(%r13)
emitter.EmitBytes({0x41, 0x80, 0x6D, 0x00, 0x01});
break;至って簡単だと思います。データポインタが r13 で、それを > と < でインクリメントとデクリメントし、 + と - によってポイント先がインクリメントとデクリメントされます。少し微妙な点はBFの実装にバイト値メモリを選択したことです。つまり、メモリの読み込みや書き込みの際に注意が必要で、デフォルトの64ビットアドレスではなく、バイトアドレス(上の add と sub の b サフィックス)を使う必要がありす。
. と , に対して出力されるコードはもっと面白いです。外部からの依存を一切避けるため、直接 Linuxシステムコール を起動します。 . は WRITE 、 , は READ です。ここでx64のABIを rax のシステムコール識別子と共に使います。
// stdoutに1バイト出力、fd=1(stdout用)で
// 書き込みシステムコールを呼び出す、buf=addressのバイト、count=1
//
// mov $1, %rax
// mov $1, %rdi
// mov %r13, %rsi
// mov $1, %rdx
// syscall
emitter.EmitBytes({0x48, 0xC7, 0xC0, 0x01, 0x00, 0x00, 0x00});
emitter.EmitBytes({0x48, 0xC7, 0xC7, 0x01, 0x00, 0x00, 0x00});
emitter.EmitBytes({0x4C, 0x89, 0xEE});
emitter.EmitBytes({0x48, 0xC7, 0xC2, 0x01, 0x00, 0x00, 0x00});
emitter.EmitBytes({0x0F, 0x05});
break;
case ',':
// stdinに1バイト出力、fd=0 (stdin用)で
// 読み込みシステムコールを呼び出す。
// buf=addressのバイト、count=1.
emitter.EmitBytes({0x48, 0xC7, 0xC0, 0x00, 0x00, 0x00, 0x00});
emitter.EmitBytes({0x48, 0xC7, 0xC7, 0x00, 0x00, 0x00, 0x00});
emitter.EmitBytes({0x4C, 0x89, 0xEE});
emitter.EmitBytes({0x48, 0xC7, 0xC2, 0x01, 0x00, 0x00, 0x00});
emitter.EmitBytes({0x0F, 0x05});
break;確実にコメントが役に立っていると思いませんか。これらスニペットが、手動での命令をコード化をやめて、アセンブリ言語を使うきっかけになればと思います。
BFの中でジャンプ命令が一番面白いと思います。 [ は以下のようにします。
case '[':
// ジャンプの場合、潜在的に短いジャンプや緩和のために
// 常に32ビットPC相対の命令を出力。
// cmpb $0, 0(%r13)
emitter.EmitBytes({0x41, 0x80, 0x7d, 0x00, 0x00});
// スタック内の位置を保存し、後で修正。
// 4つのプレースホルダのゼロでJZ(32ビット相対オフセット)を出力。
open_bracket_stack.push(emitter.size());
emitter.EmitBytes({0x0F, 0x84});
emitter.EmitUint32(0);
break;この時点では移動先が分からないことに注意してください。対応する ] に行くことになりますが、まだ遭遇していません。従って、コンパイルを単一パス ^(2) にしておくためにジャンプのプレースホルダ値を返し、対応するラベルに遭遇した後に修正を行うことで、伝統的な手法の 後埋め を使用することになります。さらに1点注意しなければならないのは、単純さを保つために常に32ビットPC相対ジャンプを使うことです。多くの場合、短いジャンプにすることで数バイト節約することができます(詳しくは アセンブラ緩和についての記事 を参照してください)。しかし、努力する価値はないと思います。
対応する ] をコンパイルするのはちょっと大変です。コメントで何が起きているか理解してもらえると思います。さらに、プログラムは賢さよりも読みやすさを重視して最適化しています。
case ']': {
if (open_bracket_stack.empty()) {
DIE << "unmatched closing ']' at pc=" << pc;
}
size_t open_bracket_offset = open_bracket_stack.top();
open_bracket_stack.pop();
// cmpb $0, 0(%r13)
emitter.EmitBytes({0x41, 0x80, 0x7d, 0x00, 0x00});
// この閉じブラケットにジャンプするJZを指すopen_bracket_offset
// このJZのオフセットの修正と共に正しいオフセットを出力する
// JNZが必要。注意点は、[と]が、対応ブラケットを見つけた
// *後*に条件を満たせば命令にジャンプ
// ジャンプのオフセットを算出。ジャンプ開始の算出は、
// ジャンプ命令の後からで、対象はスタックに保存された命令の後の命令
size_t jump_back_from = emitter.size() + 6;
size_t jump_back_to = open_bracket_offset + 6;
uint32_t pcrel_offset_back =
compute_relative_32bit_offset(jump_back_from, jump_back_to);
// jnz <open_bracket_location>
emitter.EmitBytes({0x0F, 0x85});
emitter.EmitUint32(pcrel_offset_back);
// 対応[への前進ジャンプを修正。"ジャンプ先"オフセットに
// jmpのサイズを追加する必要がないことに注意。
// jmpは出力済みのため、エミッタサイズは前に押し出されている。
size_t jump_forward_from = open_bracket_offset + 6;
size_t jump_forward_to = emitter.size();
uint32_t pcrel_offset_forward =
compute_relative_32bit_offset(jump_forward_from, jump_forward_to);
emitter.ReplaceUint32AtOffset(open_bracket_offset + 2,
pcrel_offset_forward);
break;
}これでコンパイルループを終わります。最終的に vector に実行可能な機械コードができました。このコードはホストプログラム( memory.data() のアドレス)を指していますが、ホストプログラムの寿命はJITコードの寿命を上回るので、問題ありません。実際に機械コードを起動しましょう。
// ... コンパイルループの後
// 出力コードは関数としてC++呼び出されるため、
// 正しい呼び出し規則が必要。'ret'を出力して、呼び出し元へ
// 規則的に返す
emitter.EmitByte(0xC3);
// 実行可能なメモリに出力コードをロードし、実行。
std::vector<uint8_t> emitted_code = emitter.code();
JitProgram jit_program(emitted_code);
// JittedFuncは出力されたJIT関数のC++タイプ。
// C++で出力された関数は呼び出し可能、x64 System V ABIに遵守。
using JittedFunc = void (*)(void);
JittedFunc func = (JittedFunc)jit_program.program_memory();
func();コール命令については『 JITの方法 – 入門編 』を読んでご存知だと思います。ここでは可能な限り最も単純な関数を選択したことに注目してください。引数もなければ、返される値もありません。これ以降のセクションで応用していきます。
JITを動かしてみる
パート1 では、画面に数字の1から5を表示する普通のBFプログラムをお見せしました。
++++++++ ++++++++ ++++++++ ++++++++ ++++++++ ++++++++
>+++++
[<+.>-]では、これをコンパイラがどのように変換するか見てみましょう。 simplejit 内のコードベクトルは短命です(メモリに一時的に存在します)が、バイナリファイルにシリアル化し、その後で逆アセンブルできます( objdump -D -b binary -mi386:x86-64 を使って)。以下の逆アセンブリ一覧にコメント説明を書き込みました。
# memory.data()アドレスの実行時はr13; 注意点は
# JITの呼び出しことに値が異なる可能性が高いこと。
0: 49 bd f0 54 e3 00 00 movabs $0xe354f0,%r13
7: 00 00 00
# +の初期シーケンスに対して48個の命令シーケンスは全て同じことを行う。
# これにより最適化インタプリタをミス可能性あり。
# ご心配なく、記事後半で解決します。
a: 41 80 45 00 01 addb $0x1,0x0(%r13)
f: 41 80 45 00 01 addb $0x1,0x0(%r13)
# [...] 46 more 'addb'
# >+++++
fa: 49 ff c5 inc %r13
fd: 41 80 45 00 01 addb $0x1,0x0(%r13)
102: 41 80 45 00 01 addb $0x1,0x0(%r13)
107: 41 80 45 00 01 addb $0x1,0x0(%r13)
10c: 41 80 45 00 01 addb $0x1,0x0(%r13)
111: 41 80 45 00 01 addb $0x1,0x0(%r13)
# ループです。後埋め処理によって相対ジャンプオフセットは
# 'je'命令に挿入済みであることに注意。
116: 41 80 7d 00 00 cmpb $0x0,0x0(%r13)
11b: 0f 84 35 00 00 00 je 0x156
121: 49 ff cd dec %r13
124: 41 80 45 00 01 addb $0x1,0x0(%r13)
# '.'はWRITEのシステムコールに変換。
129: 48 c7 c0 01 00 00 00 mov $0x1,%rax
130: 48 c7 c7 01 00 00 00 mov $0x1,%rdi
137: 4c 89 ee mov %r13,%rsi
13a: 48 c7 c2 01 00 00 00 mov $0x1,%rdx
141: 0f 05 syscall
143: 49 ff c5 inc %r13
146: 41 80 6d 00 01 subb $0x1,0x0(%r13)
14b: 41 80 7d 00 00 cmpb $0x0,0x0(%r13)
# ループの初めにジャンプで戻る。
150: 0f 85 cb ff ff ff jne 0x121
# 以上で終わり。
156: c3 retqパフォーマンスはどうか
パート1のインタプリタに照らしてここで作成したJITのパフォーマンスを測定しましょう。ナイーブなインタプリタよりも optinterp3 は約10倍も高速化されていました。では、JITはどうでしょう。最適化はされていないことに注意してください(ナイーブなインタプリタのようにループを繰り返すたびにジャンプ先を再計算する必要はありません)。どうでしょう。結果を見たら驚くかもしれません。
単純なJITは、 mandelbrot を2.89秒で処理し、 factor を0.94秒で処理します。 opt3interp よりもかなり高速です。以下は比較です(偏りを避けるため低速なインタプリタは除外しています)。
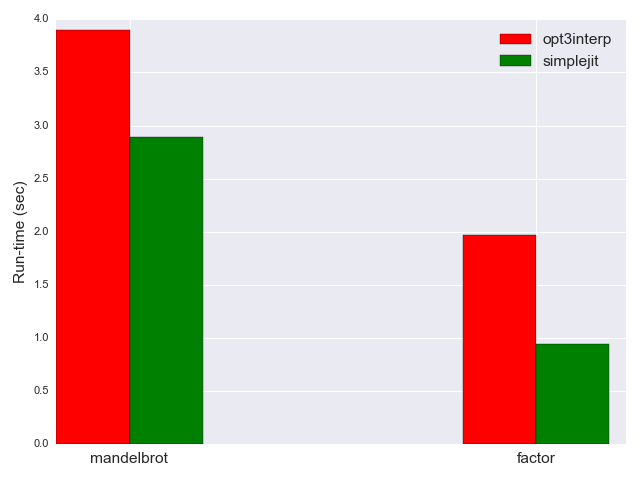
なぜこうなるのでしょうか。 opt3interp の最適化は重点的に実施されています。ループ全体を単一操作に折り畳んでいます。このようなことは simplejit ではではありえません。上で、 addb によって長ったらしい + の格好悪いシーケンスが返されるのを見ました。
理由はJITの 基本的な パフォーマンスが非常に良いからなのです。パート1でも簡単に触れましたが、最高速のインタプリタによって1つの命令を解釈するために必要なものは何かを考えてみます。
pcを進めて、それをプログラムサイズと比較する。pcでの命令を取得する。- 命令の値に基づいて適切な
caseに切り替える。 - その
caseを実行する。
これには、少なくとも2つの分岐を備えた一連の機械命令が必要になります(1つはループ用、1つは switch 用)。その一方で、JITは分岐のない1つの命令を出します。インタプリタコンパイル時のコンパイラの動作にもよりますが、恐らく、どのBF演算を実行するにもJITで実行する方が4倍から8倍高速だと思います。最適化されないため、大量のBF演算を実行することにはなりますが、基本的なパフォーマスのギャップを縮めるには至りません。この記事の後半で最適化したJITでパフォーマンスの向上を見てみましょう。
でもその前に、まず、手間のかかる命令のコード化を見てみましょう。
手動での命令のコード化
約束されているように、 simplejit は完全に自己完結しています。外部のライブラリを使う必要もなく、全ての命令を独自にコード化します。これがどれだけ手間のかかる処理かは分かりやすく、詳細なコメントなしにはコードからは読み取ることができません。さらには、コード変更も大変で、思いもよらない形で変更が生じることがあります。例えば、命令で別のレジスタを使いたいとした場合、出力されるコードの変更は直感的ではありません。 add %r8, %r9 は 0x4C, 0x01, 0xC8 としてコード化されますが、 add %r8, %r10 は 0x4C, 0x01, 0xD0 になります。レジスタはサブバイト二ブルで指定さるため、どこに何が行くのかを覚えておく良い記憶力及び豊富な経験を必要とします。
関連する命令は同じように見えると思いますか。そうではないのです。例えば、 inc %r13 は 0x49, 0xFF, 0xC0 にコード化されます。はっきり言うと、 Mel でない限り、苦労するでしょう。では、複数のアーキテクチャ用にコードを出力することをサポートしなければならないとしたらどうでしょう。
このため、全コンパイラ、VMや関連のプロジェクトにはそれぞれコード化を手伝う独自のレイヤを持っているのです。同時にラベルやジャンプ演算のような関連タスクも持っています。プロジェクト外で使用できるように公開されてはいません。 DynASM (developed as part of the LuaJIT project)のようなものは別途使用するためにパッケージになっています。DynASMは、命令のコード化以外に提供するものがない低水準のフレームワークの一例です。中には、レジスタ割り当てのようにコンパイラ以上のことを実行する水準のフレームワークもあります。その例として挙げられるのが、 libjit やLLVMです。
asmjit
命令のコード化に使えるライブラリを探していた時にDynASMを試してみました。取り組み方が面白いと思いました。 Josh Habermanの記事 を読めば分かりますが、単純なBF JITに使えます。しかし、アバンダンウェアっぽ過ぎると感じました。しかも、独創的なLuaに依存するプリプロセッサ的アプローチが好きではありません。
そして必要条件を満たす別のプロジェクトを見つけたのです。プリプロセッサのない純粋なC++ライブラリである asmjit です。 asmjit は、グラフィックコードのための高速カーネル開発を容易にするために、約3年前に始まったものです。 dynasm のドキュメンテーションに優ってはいませんが、単にC++ライブラリであることが、ドキュメンテーションにない質問の答えがあった場合、ソースをいじればいいと思わせてくれました。さらに、Githubでの質疑に対する応答が活発で早いだけでなく、機能の追加もが積極的で早いのです。このことからも、これ以降は asmjit を使用したBF JITを見ていきます。ライブラリの重要なチュートリアルとしても役に立つと思います。
simpleasmjit – 正当な命令コードを持つJIT
simpleasmjit.cppを入力します。 simplejit と同じ単純なJIT(最適化なし)ですが、命令のコード化やラベルなどに asmjit を使用します。さらに楽しくするために色々と混ぜ合わせます。まず、JITした機能シグネチャを void (*)(void) から void (*)(uint64_t) に変更します。BFメモリバッファのアドレスは、ハードコードされるのではなく、JITした関数に引数として渡されます。
次に、システムコールではなく、実際のC関数を使って文字を出力・入力します。また、 putchar と getchar がシステムによってはマクロである場合があるので、これらのアドレスを取るのには危険が伴います。そのため、実際のC++関数でラップすることで、出力されたコードに安全にその関数を取り込むことができます。
void myputchar(uint8_t c) {
putchar(c);
}
uint8_t mygetchar() {
return getchar();
} simpleasmjit は asmjit の実行時間やコードホルダ、アセンブラを初期化することから始めます ^(3) 。
asmjit::JitRuntime jit_runtime;
asmjit::CodeHolder code;
code.init(jit_runtime.getCodeInfo());
asmjit::X86Assembler assm(&code);次にデータポインタにニーモニック名を付けて、メモリバッファのアドレスのコピーを入れます(x64 ABIの1番目の関数の引数として、最初は rdi にあります)。
// データポンタを引数としてJITした関数に渡す。
// そうすることでrdiに入る。r13へ移動。
asmjit::X86Gp dataptr = asmjit::x86::r13;
assm.mov(dataptr, asmjit::x86::rdi);そして、全BF演算に対しコードを出力する通常のBF処理ループに入ります。
for (size_t pc = 0; pc < p.instructions.size(); ++pc) {
char instruction = p.instructions[pc];
switch (instruction) {
case '>':
// inc %r13
assm.inc(dataptr);
break;
case '<':
// dec %r13
assm.dec(dataptr);
break;
case '+':
// addb $1, 0(%r13)
assm.add(asmjit::x86::byte_ptr(dataptr), 1);
break;
case '-':
// subb $1, 0(%r13)
assm.sub(asmjit::x86::byte_ptr(dataptr), 1);
break;違いに気づいたと思います。もはや曖昧な16進コードはありません。 assm.inc(dataptr) の方が 0x49, 0xFF, 0xC5 よりもずっといいとは思いませんか。
入力・出力にはラッパ関数を呼び出します。
case '.':
// myputchar [dataptr]の呼び出し
assm.movzx(asmjit::x86::rdi, asmjit::x86::byte_ptr(dataptr));
assm.call(asmjit::imm_ptr(myputchar));
break;
case ',':
// [dataptr] = mygetcharの呼び出し。
// 関係ないデータの上書きを避けるため、低位バイトのみをメモリに保存。
assm.call(asmjit::imm_ptr(mygetchar));
assm.mov(asmjit::x86::byte_ptr(dataptr), asmjit::x86::al);
break;秘訣は関数のアドレスを出力されたコードに置く imm_ptr 修飾子です。
最後にasmjitラベルのおかげで [ と ] の扱いも簡単です。実際に出力される前に使うことができます。
case '[': {
assm.cmp(asmjit::x86::byte_ptr(dataptr), 0);
asmjit::Label open_label = assm.newLabel();
asmjit::Label close_label = assm.newLabel();
// もし、[dataptr] = 0; close_labelがまだバインドされていない場合は
// 閉じ']'の先にジャンプ。
// しかし、asmjitによってジャンプを今出力し、後埋めを後回しにする。
assm.jz(close_label);
// open_labelはジャンプを超えてバインド。概して以下を出力。
//
// cmpb 0(%r13), 0
// jz close_label
// open_label:
// ...
assm.bind(open_label);
// スタックに両方のラベルを保存。
open_bracket_stack.push(BracketLabels(open_label, close_label));
break;
}
case ']': {
if (open_bracket_stack.empty()) {
DIE << "unmatched closing ']' at pc=" << pc;
}
BracketLabels labels = open_bracket_stack.top();
open_bracket_stack.pop();
// cmpb 0(%r13), 0
// jnz open_label
// close_label:
// ...
assm.cmp(asmjit::x86::byte_ptr(dataptr), 0);
assm.jnz(labels.open_label);
assm.bind(labels.close_label);
break;
}どのラベルをジャンプに使って全く同じ Label を出力したのかを覚えておく必要があります。 asmjit が自身で後埋めをします。さらに、自動的にジャンプオフセットを算出します。
コード出力をすれば、呼び出しができます。
using JittedFunc = void (*)(uint64_t);
JittedFunc func;
asmjit::Error err = jit_runtime.add(&func, &code);
// [...]
// 呼び出し、メモリのアドレスをパラメータとして渡す。
func((uint64_t)memory.data());以上です。このJITは事実上 simplejit と全く同じコードを出力するため、動作も全く同じです。ここのポイントは asmjit のようなライブラリを使ってコードを出力することがどれだけ簡単で楽なのか知ってもらうことです。ゴチャゴチャとしたコードやオフセット演算などを隠してくれるため、出力される命令のシーケンスのようなプログラム固有の部分に集中することができます。
optasmjit – BFの最適化にJITを組み合わせる
最後にパート1で開発した賢い最適化をJITに組み合わせます。ここでは、パート1の optinterp3 をJITのバックエンドに固定します。結果は optasmjit.cpp になります。
覚えていると思いますが、8つのBF演算の代わりに、整数の引数を持つ拡張セットがあり、場合によっては高水準の演算を伝達します。
enum class BfOpKind {
INVALID_OP = 0,
INC_PTR,
DEC_PTR,
INC_DATA,
DEC_DATA,
READ_STDIN,
WRITE_STDOUT,
LOOP_SET_TO_ZERO,
LOOP_MOVE_PTR,
LOOP_MOVE_DATA,
JUMP_IF_DATA_ZERO,
JUMP_IF_DATA_NOT_ZERO
};BF演算から BfOpKind のシーケンスに変換する段階は optinterp3 での段階と全く同じです。では、新しい演算がどのように実装されているか見てみましょう。
case BfOpKind::INC_PTR:
assm.add(dataptr, op.argument);
break;インタプリタの時のように1のインクリメントは追加した引数に置き換えられます。ここでは、異なる命令を使用します。 inc の代わりに add を使います ^(4) 。では、もっと面白いものをお見せしましょう。
case BfOpKind::LOOP_MOVE_DATA: {
// 現在のデータが0でない場合のみ移動。
//
// cmpb 0(%r13), 0
// jz skip_move
// <...> データの移動。
// skip_move:
asmjit::Label skip_move = assm.newLabel();
assm.cmp(asmjit::x86::byte_ptr(dataptr), 0);
assm.jz(skip_move);
assm.mov(asmjit::x86::r14, dataptr);
if (op.argument < 0) {
assm.sub(asmjit::x86::r14, -op.argument);
} else {
assm.add(asmjit::x86::r14, op.argument);
}
// オリジナルポインタの値を一時的にraxで保持。
// 新しい位置にalを使って追加。
// これにより対象位置のみが影響: addb %al, 0(%r13)
assm.mov(asmjit::x86::rax, asmjit::x86::byte_ptr(dataptr));
assm.add(asmjit::x86::byte_ptr(asmjit::x86::r14), asmjit::x86::al);
assm.mov(asmjit::x86::byte_ptr(dataptr), 0);
assm.bind(skip_move);
break;
}繰り返しになりますが、このコードは asmjit で書く方が簡単です。また、メモリに触れるときに、バイトに粒状されたデータを細心の注意払って処理することにも注目してください。これを開発する際には、いくつかの厄介なバグに遭遇しました。実際、BFメモリセルに機械固有のワードサイズ(この場合は64ビット)を使用すると、全てが簡単になりました。 8ビットのセルは、言語の共通の意味に近く、さらに挑発してくれます。
パフォーマンス
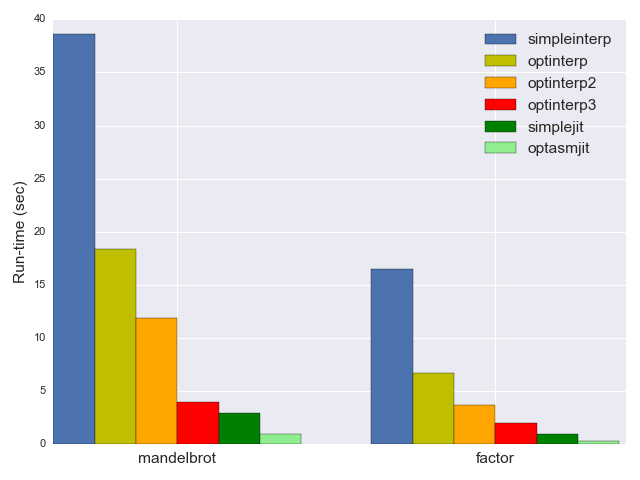
では、 optasmjit のパフォーマンスが最速のインタプリタや最適化されていないJITに比べてどうなのか見てみましょう。 mandelbrot は0.93秒、 factor は0.3秒。3つの比較は以下の通りです。
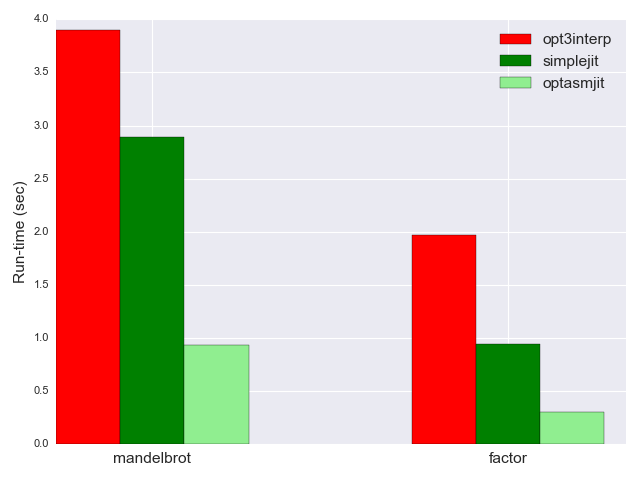
特に最適化したインタプリタとのパフォーマスの差はとても大きいことが分かります。JITは4倍も高速です。単純なインタプリアをも比較に入れると optasmjit は約40倍も高速です。同じグラフで比較するのが困難です。
JITは楽しい
個人的にJITは楽しいと思います。手作業で全ての命令を出力するコンパイラを作成できるのがいいです。しかし、 asmjit のような処理を簡単にするライブラリなしではコード化に手間がかかります。
今回のパートは内容が濃かったと思います。 optasmjit はBFのための本物の最適化JITです。以下のことを実現してくれます。
- BFソースをパースする。
- 高水準演算のシーケンスに変換する。
- これら演算を最適化する。
- 演算をタイトなx64アセンブリをメモリにコンパイルして実行する。
これらのステップを実際のコンパイラ専門用語に結び付けましょう。 BfOpKind 演算は コンパイラIR として見ることができます。ほとんどの場合、コンパイルの最初のステップは、人が読めるソースコードをIRに変換することです(現実的な言語においては変換自体が複数のステップに分割されています)。演算からアセンブリへの変換・コンパイルは、しばしば “下げる” と言われます。コンパイラによっては複数のステップや中間IRが必要となります。
大量のコードになってしまうため、記事に載せなかったコードがたくさんあります。ここで触れたファイルの全ソースファイルを見て理解することをお勧めします。JITは全て単一単体のC++ファイルです。
-
伝統的にと言った理由は、現代の多くのコンパイラはもうこのように動作しないからです。例えば、LLVMはIRを機械コードレベルの命令を表すはるかに低水準のIRにコンパイルします。アセンブリはこのIRから出力されますが、機械コードも直接出力されるため、アセンブラはコンパイラに統合されます。 ↩
-
コンパイラによっては2回のパスを実行します。パート1の最初のインタプリタの最適化に類似しています。2回目のパスがどのオフセットを出力すればいいのか分かるよう、1回目のパスで情報(対応する全ての
)の場所など)を収集します。 ↩ -
詳細については、asmjitのドキュメントを参照してください。また、asmjitには、レジスタ割り当てなどの、より洗練された処理を行う “コンパイラ” レイヤがあります。 この記事ではベースアセンブリレイヤだけを使用しています。 ↩
-
最初から
incの代わりにadd 1を使えばよかったのでは、と思っている方もいるでしょう。確かにそうです。実際、複雑なマルチポートパイプラインのx64 CPUが使われている昨今、別のinc命令がある正当な理由が存在したのかもしれませんが、どちらが高速なのかははっきりしません。多様性を示すため両方をお見せしました。 ↩

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事