2017年9月12日
JITコンパイルでの冒険 パート1:インタプリタ

本記事は、原著者の許諾のもとに翻訳・掲載しております。
本記事は、JITコンパイラに関するシリーズの第1回目です。計画としては、シンプルな入力言語を使ってそのインタプリタとJITをいくつか開発し、段々と複雑なものにしていくつもりです。このシリーズが終わるまでに、JITコンパイラの開発に何が必要か、そのためにどんな支援ツールが使えるかを、読者の皆さんによく理解していただけるようになれば幸いです。
入力言語は Brainfuck です。本シリーズでは以後、BFと呼んでいきます。BFはプログラマビリティの本質を突き詰めるので、今回の目的に適した言語だと思います。BFは、プログラミングは非常に冗長ですが、なじみのC構造体に直接マップするメモリポインタやループのような概念を持つ点で、プログラミング言語としてはかなりの”メインストリーム”です。
実装言語にはC++を使います。”手始め”の言語としては一般的ではないかもしれません。とはいえ、私の知っている大部分のコンパイラはC++(あるいはC)で書かれていることから、現存する非常にポピュラーな低水準のコード生成ライブラリの多くはC++やCで書かれています。本シリーズでは後ほど、いくつかのC++ライブラリを使います。その方が、C++自身から実行するよりもはるかに容易なのです。さらに、本シリーズではコードが回りくどくならないようにしたいと思いますので、C++の高度な機能はほとんど使用しません。
BF言語
BF言語の特徴を述べるのは簡単なのですが、ここでは省略します。 仕様 を参照していただくか、前述のWikipediaページや他の参考資料をお読みください。 こちら のようなブラウザ内インタプリタは非常に便利です。
この言語に興味を持っていただけるよう、1つ例を挙げましょう。以下のBFプログラムは、1から5までの数字を画面に出力します。
++++++++ ++++++++ ++++++++ ++++++++ ++++++++ ++++++++
>+++++
[<+.>-]ここでは以下の処理を実行しています。
- 1行目は、メモリセル0を値48に初期化する。48はたまたま、
0のASCIIコードである。 - 2行目は、メモリセル1を5に初期化する。これをループカウンタとする。
- 3行目はループで、各反復においてセル0をインクリメントしてその値を出力し、セル1をデクリメントしてそれが値0に達しているかチェックする。
シンプルなインタプリタ
まずはBF言語の雰囲気を知るため、そして信頼性のあるリファレンス実装を行うため、1度に1個のBF文字を処理してそれを”実行”するのに必要な作業を行うシンプルなインタプリタから始めましょう。
私がBFをソース言語として選んだ理由の1つは、その単純さです。ネットでは、インタプリタやコンパイラを開発すると称しながら、90%の時間は結局そのパーサを書くことに費やしているようなチュートリアルが多数あります。私はコンパイルの終盤の方がはるかに面白いと思いますので、今回のBF向け”パーサ”は以下のようにします。
struct Program {
std::string instructions;
};
Program parse_from_stream(std::istream& stream) {
Program program;
for (std::string line; std::getline(stream, line);) {
for (auto c : line) {
if (c == '>' || c == '<' || c == '+' || c == '-' || c == '.' ||
c == ',' || c == '[' || c == ']') {
program.instructions.push_back(c);
}
}
}
return program;
}これは BF仕様 に準じた有効な実装であることに注目してください。サポートされた8文字以外のあらゆる文字はコメント扱いとなり無視されるからです ^(1) 。このパーサは本シリーズを通して使っていきます。
それを確認したところで、以下が実際のインタプリタです。
constexpr int MEMORY_SIZE = 30000;
void simpleinterp(const Program& p, bool verbose) {
// 状態を初期化する。
std::vector<uint8_t> memory(MEMORY_SIZE, 0);
size_t pc = 0;
size_t dataptr = 0;
while (pc < p.instructions.size()) {
char instruction = p.instructions[pc];
switch (instruction) {
case '>':
dataptr++;
break;
case '<':
dataptr--;
break;
case '+':
memory[dataptr]++;
break;
case '-':
memory[dataptr]--;
break;
case '.':
std::cout.put(memory[dataptr]);
break;
case ',':
memory[dataptr] = std::cin.get();
break;
// [...]以上のケースはどれも、ちょっと退屈です。もっと面白いケースは、フローを制御する [ 演算と ] 演算です。まずは、 [ を見てみましょう。現在のデータ位置がゼロなら次にジャンプするという演算です。これを使うと、ループをスキップしたりシンプルな if 風の条件を実装したりすることができます。
case '[':
if (memory[dataptr] == 0) {
int bracket_nesting = 1;
size_t saved_pc = pc;
while (bracket_nesting && ++pc < p.instructions.size()) {
if (p.instructions[pc] == ']') {
bracket_nesting--;
} else if (p.instructions[pc] == '[') {
bracket_nesting++;
}
}
if (!bracket_nesting) {
break;
} else {
DIE << "unmatched '[' at pc=" << saved_pc;
}
}
break;ここで最も興味深いのは、BFの [ ブラケットと ] ブラケットはネストできることです。したがって、どこにジャンプするかを把握するには、対応するブラケットを見つける必要があります。これを実行時に行うのは無駄なように思われたなら、それは正しい感覚です。読み進めてください!
] で行うこともよく似ています。BFの ] は、現在のデータ位置がゼロでなければ、前方の [ にジャンプします。このようにして、ループは次の反復に進む(または停止する)のです。
case ']':
if (memory[dataptr] != 0) {
int bracket_nesting = 1;
size_t saved_pc = pc;
while (bracket_nesting && pc > 0) {
pc--;
if (p.instructions[pc] == '[') {
bracket_nesting--;
} else if (p.instructions[pc] == ']') {
bracket_nesting++;
}
}
if (!bracket_nesting) {
break;
} else {
DIE << "unmatched ']' at pc=" << saved_pc;
}
}
break;これだけです。インタプリタのループは以下で終わります。
default: { DIE << "bad char '" << instruction << "' at pc=" << pc; }
}
pc++;
}このシンプルなインタプリタの全コードは、 simpleinterp.cpp にあります。
BFプログラムのパフォーマンスを測定する
インタプリタやコンパイラのようなものを開発する時は必ず、実行速度が主な関心事となります。したがって、コンパイラ作成者にとって、測定に使うベンチマークスイートを持つことは一般的です。本シリーズではBFについて、実装の速度を測定するのに2つのプログラムを使います。1つは マンデルブロー集合ジェネレータ (mandelbrot)、もう1つは大きめの素数179424691で呼び出される 因数分解プログラム (factor)です ^(2) 。
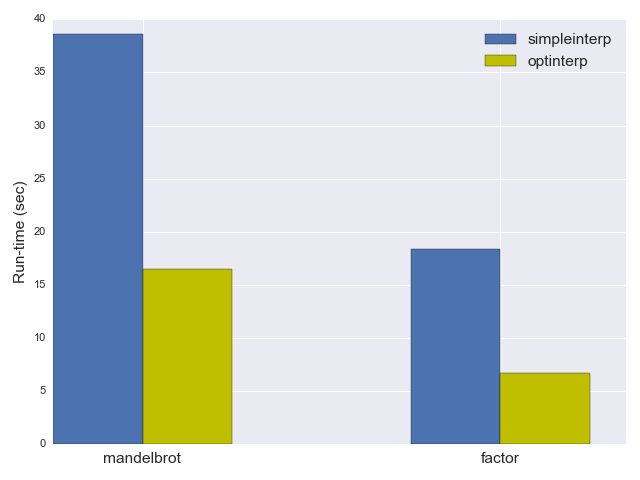
前掲のシンプルなインタプリタは、 mandelbrot の実行に38.6秒、 factor に16.5秒かかりました ^(3) 。では、これらの数値をどうやって大幅に改善できるか、見ていきましょう。
最適化されたインタプリタ:その1
今回のシンプルなインタプリタで最適化が最も明らかに見込まれる方法は、 [ や ] に遭遇する度に対応するブラケットを探すという骨の折れる処理を避けることです。ホットな内部ループを持つ実際的なプログラムを想像してみてください(ここでの”ホット”とは、何度も何度も、ことによっては何十億回も、プログラムの実行中に繰り返されるという意味です)。対応するブラケットを見つけるために毎回必ずソースをスキャンすることは本当に必要でしょうか? もちろん、その必要はありません。このBFプログラムは実行中に変化しませんから、事前にジャンプ先を計算しておくだけでいいのです。
この考えを基にしたのが、本シリーズ最初の最適化されたインタプリタ、 optinterp.cpp です。コードの大部分はシンプルなインタプリタと同じですので、違いを明示しておきましょう。追加された決定的要素は以下の関数で、実際の解釈前に実行されます。
std::vector<size_t> compute_jumptable(const Program& p) {
size_t pc = 0;
size_t program_size = p.instructions.size();
std::vector<size_t> jumptable(program_size, 0);
while (pc < program_size) {
char instruction = p.instructions[pc];
if (instruction == '[') {
int bracket_nesting = 1;
size_t seek = pc;
while (bracket_nesting && ++seek < program_size) {
if (p.instructions[seek] == ']') {
bracket_nesting--;
} else if (p.instructions[seek] == '[') {
bracket_nesting++;
}
}
if (!bracket_nesting) {
jumptable[pc] = seek;
jumptable[seek] = pc;
} else {
DIE << "unmatched '[' at pc=" << pc;
}
}
pc++;
}
return jumptable;
}上記は、プログラムにある全ての [ 演算と ] 演算のジャンプ先を計算します。この演算は、シンプルなインタプリタのメインループにおいて対応するブラケットを順方向や逆方向にスキャンすることと本質的に変わりません。返されるのはベクトル jumptable で、プログラムにおけるオフセット i での全ての [ と ] について、対応するブラケットのオフセットを jumptable[i] が保持します。オフセット i での他の演算についてはいずれも、 jumptable[i] は単に0となります。
optinterp の実際のメインループは simpleinterp とほぼ同じですが、唯一違うのはブラケットの節が以下のように単純化されていることです。
case '[':
if (memory[dataptr] == 0) {
pc = jumptable[pc];
}
break;
case ']':
if (memory[dataptr] != 0) {
pc = jumptable[pc];
}
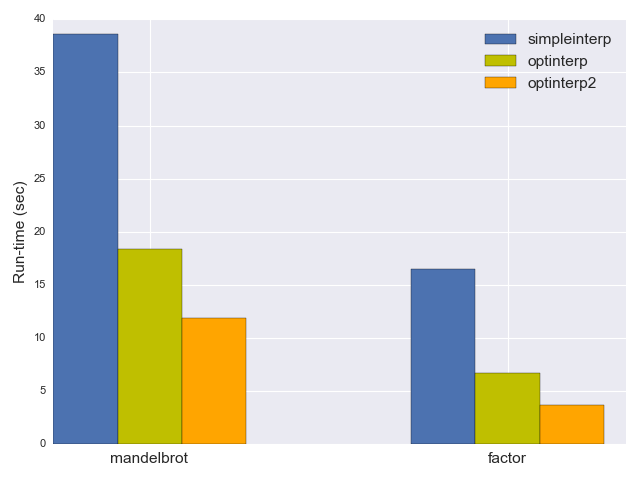
break;予想どおり、 optinterp はかなり速くなり、 mandelbrot の実行には18.4秒、 factor には6.7秒しかかかりませんでした。つまり、パフォーマンスが2倍以上改善されたのです!
最適化されたインタプリタ:その2
前のセクションで適用した最適化は非常に有益でしたが、かなり当たり前の方法でもありました。コンパイル時に事前に計算できるなら、実行時に全く必要のない処理は避けるというやり方です。今回のインタプリタをさらに高速にするには、もっと独創的な視点が必要でしょう。
何かを最適化する最初のステップは、現在のコードの測定とプロファイリングを行うことです。この工程では、過去の経験が不必要なステップの回避に役立ちます。例えば、このインタプリタの実行時間のほぼ100%が、プログラムを解釈する1個の関数に費やされることは大体明らかなので、関数や呼び出しのプロファイリングをしてもあまり役立たないでしょう。
しかし、メインループはかなり小さく、一見したところでは最適化できそうな部分はあまりなさそうです(ここでは微細なレベルの最適化については考えません)。それ以外の点としては、このループは、ソースプログラムにおいて遭遇するBF命令の度に実行されますので、実行回数は 大量 です。そこで、これから行うのは、典型的なプログラム稼働の際に実行される命令を分析することです。 optinterp のコードには、そのトレーシングをすでに組み込んでいます。コストが高く”実際の”稼働時には実行を避けたいので、 BFTRACE プリプロセッサマクロで保護してあります。
以下は、素数179424691で factor ベンチマークを典型的に実行して得られた実行プロファイルです。左側が演算、右側が目下のプログラムのためにインタプリタに実行された回数です。
. --> 21
, --> 10
+ --> 212,428,900
] --> 242,695,606
< --> 1,220,387,704
- --> 212,328,376
> --> 1,220,387,724
[ --> 118,341,127
.. Total: 3,226,569,468見るとすぐに気づく点が2つあります。
- インタプリタのメインループで30億回以上と、合計演算数が 膨大 である。インタプリタにC++を使っていることは適切でした。より高水準な言語で30億回もの反復を実行すれば、多大なコストがかかるからです。
- ループへのポインタ移動命令の比率が疑わしいほどに高い。ループの反復が2億4,200万回実行されていますが(
]の数)、ポインタ移動の<と>は合計24億回です。
ホットループは短くタイトであってほしいものですが、各ループがこれほど多数の処理を行っているのはなぜなのでしょうか。
factor.bf のソースをざっと見てみると、手掛かりが得られました。以下は、それをよく表す部分のスニペットです。
<<<<<<<<<<<<<<<<<[<<<<<<<<<<]>>>>>>>>>>
[>>>>>>>>[-]<<[->+<]<[->>>+<<<]>>>>>]<<<<<<<<<<
[+>>>>>>>[-<<<<<<<+>>>>>>>[-<<<<<<<->>>>>>+>
[-<<<<<<<+>>>>>>>[-<<<<<<<->>>>>>+>
[-<<<<<<<+>>>>>>>[-<<<<<<<->>>>>>+>
[-<<<<<<<+>>>>>>>[-<<<<<<<->>>>>>+>
[-<<<<<<<+>>>>>>>]]]]]]]]]<<<<<<<
[->>>>>>>+<<<<<<<]-<<<<<<<<<<]
>>>>>>>
[-<<<<<<<<<<<+>>>>>>>>>>>]
>>>[>>>>>>>[-<<<<<<<<<<<+++++>>>>>>>>>>>]>>>]<<<<<<<<<<
[+>>>>>>>>[-<<<<<<<<+>>>>>>>>[-<<<<<<<<->>>>>+>>>
[-<<<<<<<<+>>>>>>>>[-<<<<<<<<->>>>>+>>>
[-<<<<<<<<+>>>>>>>>[-<<<<<<<<->>>>>+>>>
[-<<<<<<<<+>>>>>>>>[-<<<<<<<<->>>>>+>>>
[-<<<<<<<<+>>>>>>>>]]]]]]]]]<<<<<<<<
[->>>>>>>>+<<<<<<<<]-<<<<<<<<<<]
>>>>>>>>[-<<<<<<<<<<<<<+>>>>>>>>>>>>>]>>
[>>>>>>>>[-<<<<<<<<<<<<<+++++>>>>>>>>>>>>>]>>]<<<<<<<<<<
[<<<<<<<<<<]>>>>>>>>>>
>>>>>>
]
<<<<<< <<<<<<< と >>>>>>> というかなり長い列に注目してください。この理由は、BFのセマンティクスについて少し考えるだけで分かります。データを更新するためには、セルからセルへと移動しなければならないので、何をするにしても必要な演算なのです。
では、このインタプリタで <<<<<<< のような演算列を実行することが何を意味するのか考えてみましょう。メインループは7回実行され、毎回以下を行います。
pcを進めて、それをプログラムサイズと比較する。pcでの命令を取得する。- 命令の値に基づいて適切な
caseに切り替える。 - そのケースを実行する。
これはかなりコストの高い処理です。長い <<<<<<< の列を圧縮できるとしたらどうでしょうか。結局のところ、1個の < で実行するのは以下です。
case '<':
dataptr--;
break;よって、7個の < なら、以下になるでしょう。
case ... something representing 7 <s ...:
dataptr -= 7;
break;これは簡単に一般化できます。BFソースにある演算列を全て検出して、それを演算と反復回数のペアとしてコード化します。そして、実行時に必要回数だけその演算を繰り返せばいいのです。
このインタプリタの全コードが optinterp2.cpp です。前は、入力プログラムの [ 命令と ] 命令に関連づけた別個のジャンプテーブルを維持していました。今は、全てのBF命令について追加情報が必要となりましたので、 Program をその種類に応じた演算列に変換します。
enum class BfOpKind {
INVALID_OP = 0,
INC_PTR,
DEC_PTR,
INC_DATA,
DEC_DATA,
READ_STDIN,
WRITE_STDOUT,
JUMP_IF_DATA_ZERO,
JUMP_IF_DATA_NOT_ZERO
};
// どの演算も1個の数値引数を持つ。
// その引数は、JUMP_*演算の場合はジャンプ先のオフセットであり、
// 他の演算の場合は演算の反復回数である。
struct BfOp {
BfOp(BfOpKind kind_param, size_t argument_param)
: kind(kind_param), argument(argument_param) {}
BfOpKind kind = BfOpKind::INVALID_OP;
size_t argument = 0;
};解釈は2ステップで行われます。 translate_program を実行してプログラムを読み取り、 std::vector<BfOp> を生成するのです。この変換はかなり分かりやすいものです。 < のような演算の反復を検出して、それを argument フィールドにコード化するのです。ここで少し注意が必要なのは、ジャンプの扱いです。プログラムにおける全ての演算のオフセットは変化するからです(例えば、7個の連続した < は1個の DEC_PTR に変化)。詳細についてはコードをご覧ください。
構想どおり、インタプリタのメインループは以下のようになります。
switch (kind) {
case BfOpKind::INC_PTR:
dataptr += op.argument;
break;
case BfOpKind::DEC_PTR:
dataptr -= op.argument;
break;
case BfOpKind::INC_DATA:
memory[dataptr] += op.argument;
break;
case BfOpKind::DEC_DATA:
memory[dataptr] -= op.argument;
break;
// [...] etc.どのくらいの速さなのでしょうか。 mandelbrot ベンチマークには今や11.9秒、 factor には3.7秒と、実行時間はさらに40%短縮されました。
最適化されたインタプリタ:その3
最適化されたインタプリタは現在、 mandelbrot ベンチマークの実行速度が元のナイーブなインタプリタの3倍も速くなっています。これをさらに高速にできるでしょうか?
まずは、前の実験を繰り返して、 optinterp2 の命令トレーシングを見てみましょう。
. --> 21
] --> 242,695,606
, --> 10
+ --> 191,440,613
< --> 214,595,790
- --> 205,040,514
> --> 270,123,690
[ --> 118,341,127
.. Total: 1,242,237,371合計の命令数が3分の1近くにまで減少しています。また、BFのループの実行数も他の命令の数に近い水準になりましたので、繰り返しの度に 過剰な 処理は行わないということです。結局、これが反復の最適化の目標でした。
それどころか、この実行プロファイルは厄介なほどに平坦です。パフォーマンスの達人は、最適化できそうな突出箇所のない平坦なプロファイルは好みません。こういう状態の時は何か別のものも測定あるいはトレースしてみるべきです。
答える価値のある興味深い疑問があります。BFの各ループは何を行っているのかということです。言い換えると、どれが一番ホットなループで、それを最適化するためにより特化した対策を取ることができるでしょうか?そのためには、より高度なトレーシングの仕組みが必要となりますが、 optinterp2 のコードにすでに組み込んであります。この仕組みはプログラムにあるループをトレースし、ループの各反復で実行される命令列を記録します。そして、記録した命令列を出現回数順にソートして、最もよく実行された(最もホットな)ループを示します。 factor ベンチマークでの結果は以下のとおりです。
-1<10+1>10 --> 32,276,219
-1 --> 28,538,377
-1<4+1>4 --> 15,701,515
-1>3+1>1+1<4 --> 12,581,941
-1>3+1>2+1<5 --> 9,579,970
-1<3+1>3 --> 9,004,028
>3 --> 8,911,600
-1<1-1>1 --> 6,093,976
-1>3+1<3 --> 6,085,735
-1<1+1<3+1>4 --> 5,853,530
-1>3+2<3 --> 5,586,229
>2 --> 5,416,630
-1>1+1<1 --> 5,104,333このトレースは何を意味しているのでしょうか。一番上の、最もホットなループを見てみましょう。
- 現在のメモリセルをデクリメントする
- 10個左のセルに移動する
- 現在のメモリセルをインクリメントする
- 10個右のセルに移動する
これを行うループは3,200万回も実行されていました! 同様に、単純な「現在のセルをデクリメントする」ループは2,800万回の実行です。 factor.bf のソースをのぞいてみれば、該当するループは簡単に見つかります。前者は [-<<<<<<<<<<+>>>>>>>>>>] 、後者は単なる [-] です。
これらのループを最適化で完全になくせるとしたらどうでしょうか。結局、高水準言語の方がずっと簡単に表現できる処理なのです。 [-] は現在のメモリセルを0にセットするだけです。 [-<<<<<<<<<<+>>>>>>>>>>] の方が複雑ですが、大差はなく、現在のメモリセルの値を10個左のセルに移すことだけです。上掲のトレースを見ると、このようなループがたくさんあることが分かります。別の種類のものとしては、例えば、 [>>>] はゼロでないセルに遭遇するまで右に3個移動するループです。
optinterp2 では、インタプリタに高水準な演算を追加しました。こうしたループを最適化でなくすために、もっと高水準な演算を追加することができます。それを行ったのが optinterp3.cpp です。実行頻度の高いループをコード化するために、演算種類をいくつか追加してあります。
enum class BfOpKind {
INVALID_OP = 0,
INC_PTR,
DEC_PTR,
INC_DATA,
DEC_DATA,
READ_STDIN,
WRITE_STDOUT,
LOOP_SET_TO_ZERO,
LOOP_MOVE_PTR,
LOOP_MOVE_DATA,
JUMP_IF_DATA_ZERO,
JUMP_IF_DATA_NOT_ZERO
};新たに加えた演算は、 [-] の代わりとなる LOOP_SET_TO_ZERO 、 [>>>] のようなループに対する LOOP_MOVE_PTR 、 [-<<<+>>>] のようなループに対する LOOP_MOVE_DATA です。そうすると、入力プログラムにあるこうしたループを検出して、適切な LOOP_* 演算を返すような、もう少し高度な変換ステップが必要となりそうです。その仕組みの例として、 [-] に対する変換は以下のようになります。
std::vector<BfOp> optimize_loop(const std::vector<BfOp>& ops,
size_t loop_start) {
std::vector<BfOp> new_ops;
if (ops.size() - loop_start == 2) {
BfOp repeated_op = ops[loop_start + 1];
if (repeated_op.kind == BfOpKind::INC_DATA ||
repeated_op.kind == BfOpKind::DEC_DATA) {
new_ops.push_back(BfOp(BfOpKind::LOOP_SET_TO_ZERO, 0));
// [...]この関数は、BFプログラムを演算列に変換する時に呼び出されます。 loop_start は ops のインデックスで、直近のループの開始位置を指します。上掲のコードは、ループの中身が1個の - だけ(あるいは + だけ。BFでは、メモリセルは符号なしの値をラップアラウンドで保持するため)というケースを検出します。そのようなケースでは、 LOOP_SET_TO_ZERO 演算を返します。インタプリタ自身が LOOP_SET_TO_ZERO に遭遇した時の振る舞いは、皆さんの予想どおりです。
case BfOpKind::LOOP_SET_TO_ZERO:
memory[dataptr] = 0;
break;他のループ最適化はもう少し複雑ですが、どれも基本的な考え方は同じです。
この最適化が大いに意義深いものであってほしいものです。プログラムが実行するホットなループを検出して、単一の効率的な命令(ポインタ移動ループについては効率的な命令列)に変換したのですから。そして実際、 optinterp3 は非常に高速となりました。 mandelbrot の実行時間は3.9秒、 factor は1.97秒です。
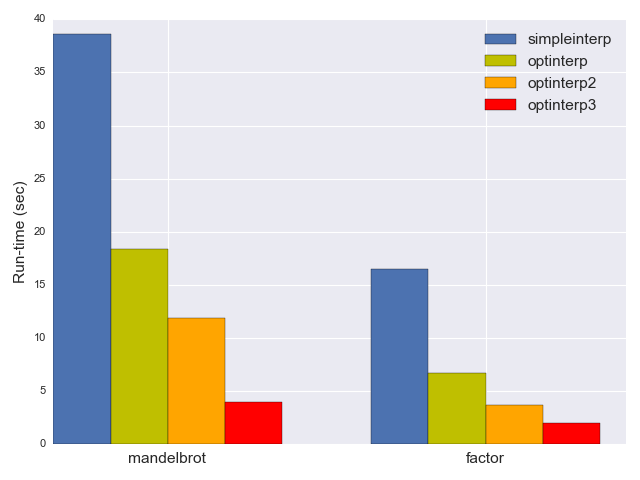
総体的に見て、劇的なスピードアップです。今回のベンチマークでは、 optinterp3 は simpleinterp のほぼ10倍も高速なのです。きっとさらに速くすることもできるでしょうが、今回求める性能としては、ここまでの最適化で十分だと思います。その代わりに、以上のことから得られる教訓について考えていきましょう。
コンパイラ、バイトコード、トレーシングJITに関して
本記事で行ってきた検証から驚くほどたくさんの知見が得られることが分かりました。
まずは、コンパイラとインタプリタの区別から始めましょう。 Wikipedia によれば、コンパイラとは、
あるプログラミング言語(ソース言語)で書かれたソースコードを別のコンピュータ言語(ターゲット言語)に変換するコンピュータプログラム(またはプログラム一式)。後者は多くの場合、オブジェクトコードとして知られるバイナリ形式を取る。
gcc はこの標準的な例でしょう。C(またはC++)で書かれたソースコードを、例えばIntel CPU向けのアセンブリ言語に変換するのです。しかし、他の種類のコンパイラも多数あります。 Chicken はSchemeをCに、 Rhino はJavaScriptをJVMバイトコードに、 Clangフロントエンド はC++をLLVM IRにコンパイルします。そして、標準的なPython実装であるCPythonは、Pythonソースコードを バイトコード にコンパイルする、といった具合です。概して、 バイトコード という用語は、効率的な解釈のために設計された何らかの中間表現や仮想命令セットを指します。
この定義に基づくと、 simpleinterp は確かに単なるBFインタプリタですが、今回ご紹介した最適化されたインタプリタは「コンパイラ+バイトコードインタプリタ」に近いものがあります。例えば optinterp3 を考えてみましょう。ソース言語はBFで、ターゲット言語は以下の命令セットを持ったバイトコードです。
enum class BfOpKind {
INVALID_OP = 0,
INC_PTR,
DEC_PTR,
INC_DATA,
DEC_DATA,
READ_STDIN,
WRITE_STDOUT,
LOOP_SET_TO_ZERO,
LOOP_MOVE_PTR,
LOOP_MOVE_DATA,
JUMP_IF_DATA_ZERO,
JUMP_IF_DATA_NOT_ZERO
};ここで、各命令は1個の引数を持ちます。 optinterp3 はBFをこのバイトコードにまず コンパイル し、それから初めてそのバイトコードを実行します。ですので、ちょっと違った角度で見れば、ここにJITコンパイラがすでに存在しているとも言えます。ただし、コンパイルのターゲットは実行可能な機械コードではなく、この特化されたバイトコードではありますが。でも心配は要りません。本シリーズの次のパートでは、真のJITに取り掛かります。
最後に、 optinterp3 で行ったループ最適化は トレーシングJIT の静的バージョンであることを指摘しておきたいと思います。トレーシングによって今回のベンチマークでどのループが最もよく実行されるかを観察し、そのループを最適化しました。最適化したループは非常に汎用的でしたので、大抵の大規模BFプログラムで確実に使われているものでしょうが、もっと踏み込むことも可能でした。さらに多くのホットループを最適化することもできたのですが、いずれ、今回のベンチマークのより特化されたパスを見ていくことになるでしょう。
完全に汎用なものとするには、この最適化を実行時にまで延ばす必要があります。それがトレーシングJITのやり方です。トレーシングJITはソース言語のコードを解釈し、最もホットなループ(動的言語の場合は、実際の実行時にループで繰り返される値の型)を追跡します。同じループが何らかの閾値を超える場合は(例えば100万回以上呼び出される)、そのループを最適化し、効率的な機械コードにコンパイルするのです。
パート1の結び
本記事では、BFのインタプリタがナイーブなアプローチから最適化されたバイトコードにコンパイルするアプローチへと徐々に洗練され、その過程で10倍も高速化されていく様子を見てきました。このソース言語と、その最適化に伴うトレードオフのいくつかについて理解を深めていただけたようでしたら幸いです。
本シリーズの次回のパートではBFの実際のJITをご紹介します。BFをタイトなx64機械コードにコンパイルして呼び出すという処理を、全て実行時に行うものです。そのようなJITコンパイラを全く一から構築する方法(標準のシステムライブラリだけを使用)と、開発をより容易にするアセンブリエンコーディングライブラリの使い方についてもお見せしたいと思います。次回もどうぞお楽しみに!
-
注意深い読者の方は、ここで効率を高めるためにスイッチ文や参照テーブルを使えたということに気づくでしょう。私は「計測するまでは遅くない」という主義を強く支持しています。BFのパース段階にかかる時間は、実際的なプログラムではごくわずかなので、この部分を最適化する意義はほとんどありません。確認できた最大のBFプログラム(mandelbrot)にはおよそ1万1,000個の命令がありますが、私のマシン上では、これのパースにかかった時間は360マイクロ秒であり、その大部分はほぼ間違いなくファイルの読み取り時間が占めています。 ↩
-
2種類のプログラムを使うことにしたのは、1つの特定のベンチマークに過剰適合するのを防ぐためです。もちろん、ベンチマークスイートを駆使した方が本格的な検証になるでしょうが、これは単なる趣味のブログ記事ですので、やりすぎない程度にいきましょう B-) 実のところ、大規模プロジェクト向けの実際のベンチマークスイートでさえ、現実との近似性に乏しい傾向があります。 ↩
-
本シリーズのパフォーマンス数値は全て、私のHaswell Linux(Ubuntu 14.04)マシン上で採取し、C++コードはデフォルトのgcc 4.8.4でコンパイルしました。Clangを使うと結果が少し異なるケースもありましたが、本シリーズの趣旨はホストC++コンパイラを比較することではないため、ずっとgccを使っていきます。また、これらの実行時間がバイナリ全体の処理を包括しており、インタプリタバイナリのロード、BFファイルの読み取り、前処理や最適化やコード出力、そして実際のベンチマーク実行を含んでいることにも注目する価値があります。およそ100ミリ秒を超える実行時間においては、どの二次的要因も、実際のベンチマーク実行時間(目下のBFプログラムの実行にかかった時間)に比べれば無視できるレベルです。 ↩

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事