2016年3月22日
ストリーミング検索プラットフォームの構築
(2016-02-17)by Insight Data Engineering
本記事は、原著者の許諾のもとに翻訳・掲載しております。
7週間の Insightのデータエンジニアリングのための特別研究員プログラム では、直近の卒業生と経験豊富なソフトウェアエンジニアが、大きなリアルタイムのデータセットを扱うためのデータプラットフォームの構築を通じて 最新のオープンソース技術 について学びます。Ryan Walker(今はCasetextのデータエンジニア)が自身のストリーミング検索プラットフォームのプロジェクトを考察します。
平均すると、世界中のTwitterユーザにより 1秒間に約6,000ツイート されています。明らかに、この膨大かつ騒がしいデータストリームからリアルタイムシグナルを抽出することはとても興味深いことです。より一般的には、リアルタイムイベントをトラックするために高速度のストリーミングテキストソースを用いる際に、数多くの面白い未解決の問題があります。この投稿では、TwitterのFirehoseのようなストリーミングテキストデータソースのリアルタイム検索に近いプラットフォームのキーコンポーネントについて説明します。
このようなプラットフォームは、Twitterのモニタリングだけではなく、はるかに多くのアプリケーションを持っているのです。例えば、音声認識モニタのネットワークは、ラジオやテレビのフィードをテキストに変換し、プラットフォームにそのトランスクリプションを渡すこともできます。キーフレーズや特徴がフィードに見つかった場合に、プラットフォームがリアルタイムイベントマネジメントを引き起こすような設定をすることも可能です。このアプリケーションは、金融やマーケティング、リアルタイム情報処理に頼っているその他の分野との関係を深めていく可能性を秘めています。
ここで説明するプラットフォームのコードは全て、Githubのリポジトリ、 Straw にあります。コードベースには以下が含まれています。
-
完全にJavaベースの Storm の実装。これには Lucene-Luwak や Elasticsearch-Percolators といったストリーミング検索の実装も含まれています。
-
boto3を使ったAWSのデプロイを自動化するためのスクリプト。
-
Docker化されたコンポーネントを使った一台のマシンでのテストを可能にするローカルランモード。
-
ベンチマークユーティリティ。
-
シミュレーションされたTwitterのFirehoseから、ユーザがクエリを登録したり、ストリーミングマッチを受け取ったりするマルチユーザWebインターフェースのデモ。
私は Insightのデータエンジニアリングプログラム でフェローとしてこのプロジェクトを完遂しました。このプロジェクトに対する最初のひらめきは、以下の2つのストリーミング検索に関する優れたブログの投稿から生まれました。
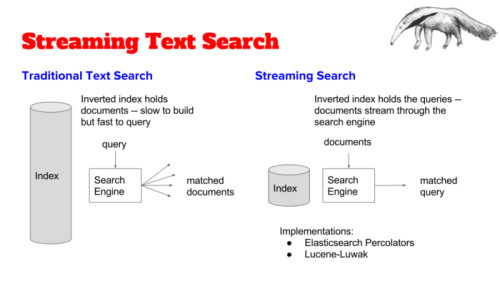
ストリーミング検索
従来のテキスト検索の問題を解決するためのキーのデータ構造は、クエリできるようにしたいドキュメント群から構築した転置インデックスです。そのもっとも単純な形では、転置インデックスは、マップのキーがドキュメント内で全て一意に定まる語のセットとなるような、単なるマップとなります。マップで個々の語と結び付けられる値は、その語を使用する全てのドキュメントの一覧となります。

注釈:転置インデックス
インデックスが構築された後、ユーザはインデックスに対して処理を走らせるクエリを実行することができます。例えば、”llama(ラマ) pajamas(パジャマ)”というフレーズの両方の語を含む全てのドキュメントを戻り値とするクエリがあるとしましょう。まずクエリエンジンは、入力されたフレーズを”llama”と”pajamas”という2つのトークンに分割します。次に”llama”という語を含む全てのドキュメントの一覧と”pajamas”という語を含む全てのドキュメントの一覧を得るために、転置インデックスをチェックします。エンジンは、これら2つのリストの共通部分、つまり両方のリストに存在しているドキュメントのリストを返します。
ストリーミングの場合、ドキュメントは格段に速いペースで到達しています(例えば、Twitterの場合1秒間に平均6000ツイートです)。この速さと量では、リアルタイムにドキュメントの転置インデックスを構築することは非現実的です。更に言えば、ツイートの静的インデックスを作ることが目的ではなく、どちらかと言えば、ツイートが届いたときにリアルタイムでツイートをスキャンし、登録されたクエリとマッチするかどうかを判定することが目的なのです。ここで巧妙な手段が使えます。ドキュメントから転置インデックスを構築しないで、代わりにクエリ自体からインデックスを構築するのです。

注釈:
ストリーミングテキスト検索
従来のテキスト検索
転置インデックスはドキュメントを保持
構築は遅いがクエリは早い
ストリーミング検索
転置インデックスはクエリを保持
ドキュメントは検索エンジンを通り抜ける
簡単な例を挙げましょう。ユーザが”llama”と”pajamas”という単語を含んだツイートを見たいと仮定します。このクエリを転置インデックスに追加するには次のようにします。
-
クエリの識別子を作成します。例えば”q1″など。
-
“llama”が転置インデックスに存在するなら、”llama”のキーのリストに”q1″と追加します。存在しなければ、”q1″を含むリストのインデックス中の”llama”を初期化します。
-
“pajamas”が転置インデックスに存在するなら”pajamas”のキーのリストに”q1″と追加します。存在しなければ、”q1″を含むリストのインデックス中の”pajamas”を初期化します。
ツイートがストリームの形で配信されると、クエリエンジンはテキストをトークンに分割します。それからクエリエンジンはキーが.転置インデックスの中のトークンと同じリストの値の共通部分を全て返します。

注釈:
クエリの転置インデックス
「淑女はラマが好きだがラマはパジャマが好き」
ラッキーなことに、クエリの転置インデックスを構築するのに使えるツールがいくつか存在しています。
-
Elasticearchの Percolator はElasticsearchの標準機能で、クエリの索引を作成し、ドキュメントを「パーコレーション」できるようにしてくれます。
-
Apache Luceneの Luwak は、Luceneのモジュールで、大幅なプレフィルタリングによりクエリの転置インデックスに対しマッチングを最適化します。Percolatorに比べ、速度のパフォーマンスは 非常に顕著です 。
アーキテクチャ
ストリーミング検索の基本的なツールが出揃ったところで、(Elasticsearch-Percolator、またはLucene-Luwak)、プラットフォームのアーキテクチャについて解説しましょう。Strawのプラットフォームは以下のコンポーネントから構成されます。
-
TwitterのFirehoseのようなストリーミングテキストソース。一連のJSONドキュメントのストリームを排出します。
-
Apache Kafka クラスタ。テキストストリームの取り込みを処理します。
-
Apache Storm クラスタ。複数の検索エンジンワーカにまたがって計算結果を分配します。
-
Redis サーバ。Pub/Subフレームワークを提供し、サブスクライブしているユーザに対してマッチしたものを収集したり分配したりします。
-
少なくとも1つのクライアント。クエリをサブミットし、ユーザの代わりにマッチ結果をリスニングします。

注釈:
サブスクライバに結果をパブリッシュする
ストリーミングソース
TwitterのストリーミングAPI は特別な権限がない限りFirehoseへのアクセスを許可しません。StrawがFirehoseレベルの読み込みでどのように振る舞うか見るためには、サンプルのエンドポイントを使って大量のツイートを収集します。そのツイートをファイルに保存するか、または、Kafkaクラスタのドキュメントトピックに直接送信するかします。
または、簡単なプロデューサスクリプトを使ってファイルからKafkaにツイートを読み込むこともできます。
高負荷を維持するため、このスクリプトのインスタンスを複数実行し、 supervisor などを使って、スクリプトがファイルを読み終えたらすぐに再起動します。
Strawプロジェクトは離散したJSONドキュメントを扱うために設計されましたが、内部パーサを変更すればXMLなど他のフォーマットを利用するのも非常に簡単になるかもしれません。挑戦する価値がありそうなのは、一連のストリームデータ、例えば音声トランスクリプションなどを扱うことです。この場合、いくつかの戦略が考えられます。例えば、文の改行を検出し、検出された改行をストリームの中では別のドキュメントとして扱う、などです。
Kafka
Kafkaクラスタは2つのトピックを持っています。ドキュメントとクエリです。上述のプロデューサスクリプトはドキュメントトピックを追加するのに使えます。フロントエンドのクライアントはユーザサブスクリプションのクエリトピックを追加します。本番環境では、5つのノードを持つKafkaクラスタはTwitterレベルのボリュームを容易に収容できるということが分かりました。ドキュメントトピックについて、私は5個のパーティションファクタと2個のレプリケーションファクタを使いました。大量のストリームを収容するのに、高い供給性は大変重要ですが、ドキュメントを多少失っても大した問題ではなさそうです。クエリには3個のレプリケーションファクタと2個のパーティションだけを使いました。クエリは頻度が低いので供給に関してはそれほど重要ではありませんが、クエリの紛失は許容できません。パーティションファクタはStormトポロジの中のKafkaスパウトの数以下でなくてはならないことに注意してください。各スパウトがきっちり1つのパーティションを消費するからです。
他にKafkaの設定で重要なことがkafka.server.propertiesにあります。
# The minimum age of a log file to be eligible for deletion
log.retention.hours=1注釈:削除される対象となるログファイルの古さの最低値はlog.retention.hours=1
Kafkaのデフォルト値は168時間で、これでは、負荷をかけたそれなりのサイズのディスクがすぐにいっぱいになってしまいます。理想的にはメッセージはリアルタイムに消費されるべきなので、最低値の1時間にすることをお勧めします。ただし、Kafkaのログのために十分大きな容量を確保しておく必要があります。本番環境では、Kafkaのノードごとに、64GBの容量と1時間の保持を設定しています。
Storm
StormのトポロジはドキュメントのためにKafkaスパウトを実装し、トピックをクエリします。本番環境では、私は5つのドキュメントスパウトと3つのクエリスパウト(Kafkaのパーティショニングと一貫性がある)を使いました。トポロジの中のボルトがドキュメントストリームを検索し、マッチしたものがあればRedisにパブリッシュします。本番環境では、全部で6ワーカを割り当てました。クラスタを適切にサイジングするのは少し大変でした。この 投稿 はStormパラレリズムの主要な概念について説明しているので、読むことを強くお勧めします。また、StormにビルドインされたUIも、クラスタの振る舞いをモニタし理解するのに役立ちます。

注釈:
Stormトポロジ
ドキュメントがシャッフルされる
クエリが伝達される
もっとも基本的なシナリオでは、クエリの数が少なく、一台のマシン上のメモリで足りるはずです。そこからストリームのボリュームを拡張するのはとても簡単です。つまり各ボルトにLucene-Luwakインデックスのインメモリを全部コピーするのです(クエリはここにインデックスされていることを思い出してください)。ですからユーザが新たなクエリを登録するたびに、ローカルのクエリインデックスを維持するため、トポロジの全ボルトにそれを伝達しなくてはなりません。ドキュメントがストリームから到着すると、各ボルトがクエリインデックスの全コピーを持っているので、そこからランダムにどれかのボルトに割り当てることができます。フェイルオーバーを処理するには、全クエリのグローバルコピーを保持することもできるので、ボルトが使えなくなっても新しい物と交換することができ、グローバルストアからそのインデックスを追加できます。次のJavaスニペットでこのトポロジを定義できます。
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("query-spout", new KafkaSpout(query_spout_config), 3);
builder.setSpout("document-spout", new KafkaSpout(document_spout_config), 5);
builder.setBolt("search-bolt", new LuwakSearchBolt(), 5)
.allGrouping("query-spout")
.shuffleGrouping("document-spout");このプラットフォームはマルチユーザとマルチテナントを想定しているので、クエリの数がどのボルトのインメモリにも実際には適合しないような状況も容易に想像できます。この場合、Stormトポロジにもう1つボルトのレイヤを追加すればいいのです。

上記のように、処理が完了したクエリのインデックスは、小さなボルトのクラスタにパーティション分けされています。入ってくるクエリはファンボルトに伝達され、各ファンボルトは伝達されたクエリをインデックスするために、1つのLuceneワーカをランダムに選択します。ストリームからのドキュメントは、ファンボルト間でシャッフルされ、各ファンボルトがドキュメントを伝達します。そうすることで、各Luceneボルトは、インデックスのパーティションに対してドキュメントをチェックするようになります。
Luwakの代わりにPercolatorを使用すると、各ボルトにElasticsearchクライアントが含まれるようになります。この場合、Elasticsearchクラスタをサーチボルトと連結し、高性能なレプリケーションを使用すれば、ネットワークのオーバーヘッドを最小限にすることができます。ただし、Percolatorクエリもインメモリに保存されるので、依然として、多くのクエリのサイズが大きくなるという問題には直面します。
Redis
インメモリのアプリケーションキャッシュとして、最も一般的に使用されているのがRedisです。これにもまたシンプルで見事なPub/Subフレームワークが備わっています。以下は、Redis-cliを使用したPub/Subの例です。
ターミナルAでは、リスナーがトピックをサブスクライブ。
127.0.0.1:6379> SUBSCRIBE "llama-topic"別のターミナルBでは、パブリッシャーがトピックをパブリッシュ。
127.0.0.1:6379> PUBLISH "llama-topic" "llamas love to wear pajamas"するとターミナルAでは、サブスクライバがメッセージを受信。
1) "message"
2) "llama-topic"
3) "llamas love to wear pajamas"これだけです。全ての標準Redisクライアントは、Pub/Subフレームワークと相互作用するために、APIを露出します。
ユーザがStrawプラットフォームにクエリを登録すると、以下のようなことが起こります。
-
クライアントが、Kafkaクエリのトピックにクエリを渡します。
-
クライアントが、クエリIDとなるクエリのMD5ハッシュを算出します。
-
クライアントが、ユーザにRedisのPub/Sub機能で算出されたIDをサブスクライブします。
-
Stormクラスタが、Kafkaスパウトからクエリを受け取り、Luceneボルトに伝達します。
-
各ボルトが、クエリのMD5ハッシュを算出し、クエリIDとしてハッシュを使用するLuwakでクエリを登録します。
-
ボルトがドキュメントを受け取ると、ドキュメントと一致するクエリがインデックスにあるのかをLuwakを使って確認します。一致するクエリをLuwakが見つけると、1つもしくは複数の一致するクエリIDを返してきます。Luwakによって返された各IDをトピックとして使い、ボルトがRedisのPub/Sub機能でオリジナルのドキュメントをパブリッシュします。
-
サブスクライブされたクライアントは、Redisにパブリッシュされたドキュメントを受け取ります。
クエリIDとしてハッシュを使うことで、単体のクエリをインデックスする必要がある場合のみ、2つもしくはそれ以上のユーザが同じクエリをサブスクライブすることを可能にします。
クライアント
Strawのクライアントには、以下の役割があります。
-
ユーザの管理。特に、どのユーザがどのクエリをサブスクライブしているのかを監視します。
-
Kafkaにユーザクエリをプッシュ、Redisのクエリにサブスクライブ。
-
クエリからの応答をリスニング。
Strawプラットフォームは、シンプルなPython FlaskのWebサーバであるデフォルトのクライアントと一緒にパッケージされており、Webサーバがセッション化されているので、ユーザは特定のクエリを追跡することができます。サーバはKafkaにクエリをパブリッシュするために基本的なKafkaプロデューサを実装しており、Redisが各ユーザに対してサブスクライブされたクエリIDのリストを監視します。リスニングは、アクティブユーザの全セットに渡る、全てのユニークなクエリに対してサブスクライブされたRedisクライアントを持つ、シングルバックグラウンドスレッドによって処理されます。クエリIDとドキュメントのペアが見つかると、バックグラウンドスレッドがRedisに対して、該当するクエリIDをサブスクライブしたユーザを見つけるようにクエリを行うのです。そして、サブスクライブした各ユーザに対して、ドキュメントテキストを結果プールにコピーします。ユーザインターフェースは、ユーザのプールが更新されているかを0.5秒毎に確認するので、結果はコンソールへとストリームされるわけです。以下は、UIの動作を動画にしたものです。
ベンチマークと結論
今回のStrawプロジェクトの目的の1つは、Easticserch-PercolatorsとLucene-Luwakのパフォーマンスを比較、測定することでした。パフォーマンスの測定は、そう簡単なものではないので、スループットを測定するために以下の非常に基本的なアプローチを使用しました。
-
Kafkaのドキュメントトピックを大量のドキュメントで埋めます。
-
Kafkaのクエリトピックに一定数のかなり複雑なクエリを加えます。
-
Kafkaクラスタを起動します。
-
各ワーカボルトにカウンタとストップウォッチを持たせ、バックグラウンドスレッドで走らせます。
-
ドキュメントがLuceneに渡され、応答(空もしくは非空)を受け取るたびに、カウンタをインクリメントします。
-
ストップウォッチが10秒を計測したら、”ベンチマーク”といった特別のRedisトピックにカウンタ値をパブリッシュします。そしてカウンタを0にリセットし、再度ストップウォッチをスタートします。
Redisでベンチマークチャネルを監視することによって、システムのサーチスループットを追跡することができます。以下の画像は、この手順を数時間起動して得られた、毎秒の合計スループットを割り出すためのプロット密度です。

注釈:あるベンチマーク
m4.xlargeインスタンスの5ボルトStormクラスタ上で、500以下の登録されたクエリに対する毎秒のスループット
密度
Twitterの平均スループット:毎秒6000ツイート以下
ツイート/秒

注釈:あるベンチマーク
m4.xlargeインスタンスの5ボルトStormクラスタ上で、10万以下の登録されたクエリに対する毎秒のスループット
密度
Twitter:毎秒6000ツイート以下
ツイート/秒
これらの仮推定値に対する解説と結論は、以下の通りです。
-
両方のケースで、Elasticsearch-PercolatorよりもLucene-Luwakの方が格段に優れています。しかし、私が使用したElasticsearchクラスタは、この実験のために最適化されていませんでした。サーチボルトに対して、Elasticsearchインデックスを限定するためのよりよい配慮がなされていれば、この差は縮まっていたことでしょう。
-
クエリ数が増加していることから分かるように、スループットでは著しい減少が起きています。上記の画像に表示されているファンボルトのソリューションがパフォーマンスを向上させるなら、興味深い結果となるはずです。
-
スループットの変数は、特にLuwakでは、非常に高くなります。
-
少数クエリのケースでは、Twitterレベルのボリュームの平均値を簡単に調整することができる。また多数クエリでは、ソリューションを得るために水平に近い増減とすることができる。
-
今回使用したクエリは、Strawリポジトリで入手可能です。これらは、40Mの英語によるツイートのサンプルを基にバイグラムの頻度を計測したり、最も頻度の高いバイグラムを保持したりすることで、生成しています。より複雑なクエリでパフォーマンスを評価すると面白いでしょう。
-
使用したドキュメントは、140文字に制限されたツイートである。より長い文字数のツイートでパフォーマンスを評価するのも面白いと思います。
データベースエンジニアへの転職をお考えの方は・・・
ニューヨークやシリコンバレーで実施されている Insightのデータエンジニアリングのための特別研究員プログラム) をご覧ください。今すぐ申し込む方は こちら から、プログラムの最新情報を入手したい方は こちら にアクセスしてください。
データサイエンティストまたはデータベースエンジニアの方は・・・
データプロフェッショナルに関する 上級者向けワークショップ をご覧ください。2日間で行われる Apache Spark や Data Visualization のワークショップ申し込む方は こちら から、ワークショップの最新情報を入手したい方は こちら にアクセスしてください。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事