2016年9月23日
高速なハッシュテーブルを設計する

(2016-08-28)by Emil Ernerfeldt
本記事は、原著者の許諾のもとに翻訳・掲載しております。
(訳注:2016/9/28、頂きましたフィードバックを元に記事を修正いたしました。)
はじめに
本稿では、高速で汎用的なハッシュテーブルを作るために行う、設計についての多くの意思決定事項を紹介します。最終的に、私の emilib::HashSet とC++11の std::unordered_set の間のベンチマークが出来上がりました。もし、ハッシュテーブルに興味があって、自分で設計したいなら(どのプログラミング言語かに関わらず)、本稿がヒントになるかもしれません。
ハッシュテーブル
ハッシュテーブル は、素晴らしい発明です。 ならし計算量O(1) ( O(√N)時間 )で、挿入、削除、検索を行うことができます。ならし計算量とは、ハッシュテーブルの計算に平均でO(1)の計算量がかかることを意味しますが、時々、これよりも多くの時間がかかる場合があります。具体的には、ハッシュテーブルに空きがない場合で、挿入の際に、 リハッシュ を行います。リハッシュにおいては、新しいテーブルが割り当てられ、全てのキーがその新しい(より大きな)テーブルに移動します。
C++におけるハッシュテーブル
C++11以降、標準テンプレートライブラリ(STL)が std::unordered_map と std::unordered_set という2つのハッシュテーブルを提供しています。これらは、古い(順序付きの) std::map と std::set に非常に近いインターフェイスを持つよう設計されています。このことによる利点は、旧型の std::map や std::set のコードを順序のない新型に移植し、高速化するのが簡単であることです。しかし、STLのハッシュテーブルは、想定よりかなり遅いことが欠点です。遅い理由は、この標準では、要素の挿入や削除によって 他の要素を指すポインタ に影響を与えることが禁じられているからです。従って、リハッシュで、メモリ内で要素を移動してはなりません。ですから、一度要素にメモリが割り当てられると、その後決して動かしてはいけないのです。従って、C++11のハッシュテーブルは、直接要素を含む配列ではなく、要素を 指す 配列を持たなければなりません。そのため、ハッシュテーブル内を検索した後に、ポインタ追跡という余分な手間がかかり、キャッシュミスが起こりやすくなります。これから見ていくように、これによって、ハッシュテーブルは、本来よりもずっと遅くなってしまう可能性があるのです。
自分のハッシュテーブルを作る
他の多くの人々のように、私は、自分のハッシュテーブルを作りました。私の得意なC++で書きましたが、設計の意思決定は、他のプログラミング言語にも適用可能です。
設計目標
- 高速化
- むやみに、ユーザがすべき意思決定を代わりにしない
- ユーザは、適切なハッシュ関数を使っていると想定する
実際、設計目標3は、前の2つの設計目標から出てくるものです。もし、ランダムな整数の集まり(全ビットにおいてランダム)なら、それをハッシュする必要は全くありません。しかし、ポインタアドレスのようなものなら、(エントロピーを全ビットにわたって分布させるために)それをハッシュする必要があります。ハッシュテーブルは、ユーザが入力をこのどちらにしようとしているのか分からないので、設計目標2によって、ユーザに決定を促します。
以下が、主な設計意思決定事項です。
連鎖法 か オープンアドレス法(開番地法) か
連鎖法は、STLの実装で最もよく使われているものです。いずれにせよバケット(キー+値)は個別にアロケートする必要があるので、そうするのが妥当でしょう。この利点は、一度要素がテーブルに入ると、その後は要素が移動するような危険を冒すことなしに安全に要素を指せることです。欠点は、オープンアドレス法よりもずっと遅いことです(上述の通り)。
決定:オープンアドレス法
こちらの方が速いので、設計目標1を満たすことができます。しかし、保管されている値の移動が遅い場合、あるいは、移動不可能な場合はどうすれば良いでしょうか? また、一度その値を指したら、それ以後リハッシュ中にその値が移動することを決して心配しなくても良いような機能が欲しかったら? 簡単です。間接レイヤを自分で追加しましょう。 HashMap<Key, std::unique_ptr<Value>>! を使うだけです。これで、設計目標2を満たします。
2のべき乗か素数か
ユーザがハッシュテーブル内のある要素を探そうとするときは、まずキーをハッシュしてから、次にそのハッシュ値をそのテーブルのサイズにマップする必要があります。これを、ハッシュ値を 制約する 、と呼びます。これを行うには、テーブルサイズを法とするハッシュ値をとります。ただ、テーブルのサイズはどれぐらいにすべきなのでしょうか?
テーブルのサイズについては「2のべき乗に制約すべき」あるいは「素数に制約すべき」という2つの主要な考え方があります。素数の利点は、ハッシュ値の全ビットが使用されることです。2のべき乗の利点は、素数を探す必要がないので、高負荷なモジュロ演算を行う必要がないことです(必要なのは非常に低負荷のビットマスクだけです)。
決定:2のべき乗
こちらの方が高速なので、設計目標2が満たされます。しかし、ハッシュ値の全ビットを使うことに関してはどうでしょうか? 設計目標3によれば、全ビットを使う 必要は ありません。その理由は、どちらにせよ優れたハッシュ関数はエントロピーをうまく分布させるからです。
線形探索法 か 2次探索法 か
キーを挿入したら、そのキーが入るはずのバケットがすでに埋まっていた、という場合はどうしましょう? その場合は、別のバケットにキーを入れる必要があります。そうするための1つの方法は、次の空きバケットにキーを入れることです。この方法の問題は、良くないハッシュ関数を使うと劣悪な衝突の連鎖に陥って、空きバケットを探すのに多数の要素を探索しなければならないことです。そのための1つの解決策は、2次探索を行うことです。この方法では、最初に1つの要素をスキップし、次に2つスキップし、その次は4つスキップするというようになります。
決定:線形探索法
設計目標3によれば良くないハッシュ関数を取り扱う必要はなく、線形探索は(キャッシュのローカル性に起因して)2次探索よりもずっと高速なので、設計目標1が満たされます。
リハッシュ時にハッシュを再計算するか メモ化する か
リハッシュ時には、各キーに対して(制約なしの)ハッシュ値を再計算する必要があります。ハッシュ関数が低速ならば、メモリ空間をいくらか犠牲にしてハッシュ値を各キーと共に保管しておくことによってパフォーマンスを稼ぐこともできます。この方法のもう1つの利点は、衝突時の等価性テストが迅速になることです。実際のキーを比較する前に、まず、制約なしのハッシュ値を比較することができます(実際のキーの文字列は長いことがあり、比較に時間がかかります)。
決定:ハッシュ値をメモ化しない
これは設計目標2「ユーザの代わりに決断を行わない」から派生します。ハッシュ関数が高速なら、その結果を保管することは空間と時間の浪費なので、設計目標1に反します。ユーザはハッシュ値を保管する代わりに、キー型の中にキャッシュする方法を選ぶことができます。これは、ハッシュ関数をメモ化するだけのためにある小さなラッパー型、 emilib::HashCache: の背後にある考え方です。
(注記:大学時代(2003年か2004年)にJava用のハッシュテーブルを書いたときに、ハッシュ値をメモ化すると実行時に非常に大きな良い効果があったことを思い出しました。その理由は、Javaで2つのものの等価性を比較することは、仮想関数呼び出し( Object.equals )を意味するので、とてつもなく遅いからです。つまるところ、Javaを最適化するのは、F1レース用に トラバント をいじるようなものなのです)
ベンチマーク
さて、ここまでの決定事項は実際に有利に働くでしょうか? テストのために ベンチマークを書き 、 emilib::HashCache を使用する場合と使用しない場合の両方で、 std::unordered_set と emilib::HashSet にそれぞれ100万個の一意のキーを挿入しました。キーは次のとおりです。
- 100万個の64ビット乱数(例えば、2947667278772165694)。
std::stringとして10進符号化された、上と同じ数(例えば、”2947667278772165694″)。これは、エントロピーの高い本物の実世界のエミュレーションが目的です。- 100バイトになるようパディングされた、上と同じ文字列(例えば、”2947667278772165694xxxxxxxxxx…”)。この場合、文字列のハッシングの負荷が少し高くなります。
各ベンチマークを10回ずつ実行して、ベストタイムをとりました。コンパイラはClang、プラットフォームはOSXです。
結果
数値はすべてミリ秒単位で表され、 低いほど良い数値です 。
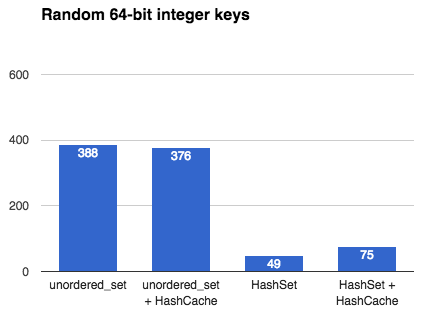
注釈: 64ビット乱数の整数キー
emilib::HashCache を使用すると明らかに空間と時間が無駄になりますが、 emilib::HashSet が std::unordered_set を凌駕していることは印象的です。キーが小さい場合(例えば整数またはポインタ)には、スピードアップが期待できます。

注釈: 19文字の文字列
ここでも emilib::HashSet は std::unordered_set より優れていますが、あまり差はありません。個々のキーの割り当てとハッシングに、さらに時間がかかっています。やはり、ハッシュ値のメモ化は時間の無駄です。
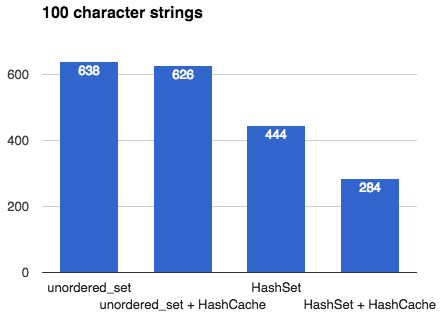
注釈:100文字の文字列
ここでは、 emilib::HashCache の有用性が示されました。リハッシュのたびに100バイトのハッシュの再計算を避けることによって大幅な節約ができます。ただし、 emilib::HashSet を使用した場合だけです。
結論
自分のハッシュテーブルを書くのは楽しい作業ですし、 std::unordered_map/std::unordered_set よりも優れた方法を使えば大幅な節約が可能です。キーが長い場合には、ハッシュ値のキャッシングには価値があります。
私の作った HashMap 、 HashSet 、 HashCache は、シングルヘッダでパブリックドメインにあります。ご自由にお使いください。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事