2015年7月28日
キャッシュフレンドリーな二分探索 ー データ構造を再考する

(2015-06-25)by Joaquín M López Muñoz
本記事は、原著者の許諾のもとに翻訳・掲載しております。
現代のコンピュータのアーキテクチャに搭載されている高速のキャッシュメモリは、 参照の局所性 に優れた(=一連のものとしてアクセスした要素が、互いに近いメモリのアドレスに配置されている)データ構造を好みます。これは、 Boost.Containerの平坦な(ツリー状ではない)連想コンテナ のようなクラスを陰で支えている理論的根拠です。要素を連続的に(かつ順序だてて)保存すると同時に、標準的なC++ノードベースの連想コンテナの機能性をエミュレートします。以下にあるのは、要素が0から30の範囲の時、 boost::container::flat_set の中で 二分探索 がどのように行われるのかを示した例です。

探索で目的の値を絞り込むにつれて、アクセスされる要素は次第に近くなっていきます。そのため、最初のうちは大きな距離を飛び越えていくような感じであっても、参照の局所性は このプロセスの最後の部分では 非常に良くなっています。概して、このプロセスは基本の std::set (アロケータの気まぐれで、要素はメモリのあちこちに散らばっています)での検索よりもキャッシュフレンドリーで、結果として探索時間もより改善されます。しかし、それよりもさらにキャッシュフレンドリーな方法があります。
0から30までの値を持つ、古典的な 赤黒木 の構造を考えてみてください。

そしてその要素を、次のような木の 幅優先 (レベル順)の連続した配列に並べます。

この レベル順ベクトル では、次の例が示すように、最初にある要素(根)から二分探索を始め、”左”あるいは”右”の子にジャンプしていきます。

このジャンプのパターンは、 boost::container::flat_set: とは違いますね。最初にアクセスされる要素は互いに近くにあり、ジャンプはだんだん長くなります。ですから、参照の局所性は プロセスの最初の部分で 良くなっています。先ほどと正反対ですね。この新しい配置によって楽になるとは思えないでしょう。でも実際はそうなのです。 boost::container::flat_set: の ヒートマップ を見てみましょう。

この図から、平均的な二分探索の操作によって、与えられた要素がアクセスされる頻度が分かります(”より熱い”ことを示す赤色の濃い方が、ここではより頻繁にアクセスされていることを意味します)。全ての検索は中央にある要素15から始まるので、この要素を訪れる頻度は100%となり、要素7と23を訪れる頻度は50%といった具合です。一方で要素をレベル順に並べ直し、同じようなヒートマップで示すと様子が全く異なります。

この並び順では、熱い要素がより近くに集まっているのが分かります。キャッシュ管理のメカニズムでは熱いエリアをより長くキャッシュ内に保持しようとするので、このレイアウトにすれば全体的なキャッシュミスがほとんどなくなることが期待できます。つまり、グラフの冷たい要素のエリアを利用して、熱い要素での参照の局所性を改善しているのです。
実際にこのデータ構造を検証してみましょう。プロトタイプのクラステンプレート levelorder_vector<T> を記述しました。これはレベル順にコンテンツを保存し、二分探索のためのメンバ関数を提供します。
const_iterator lower_bound(const T& x)const
{
size_type n=impl.size(),i=n,j=0;
while(j<n){
if(impl[j]<x){
j=2*j+2;
}
else{
i=j;
j=2*j+1;
}
}
return begin()+i;
}テストプログラム があり、これを用いて std::set 、 boost::container::flat_set 、 levelorder_vector などの1万から300万までの要素数( n )となるコンテナに対する値のランダムシーケンスで lower_bound の実行時間を測定します。
WindowsのMicrosoft Visual C++
テストを、Microsoft Visual Studio 2012のデフォルトのリリースモード設定を使ってビルドして、Intel Core i5-2520M CPU @2.50GHz環境におけるWindows boxで実行しました。値はマイクロセカンド/コンテナ内の要素数(n)で表されます。

*注釈
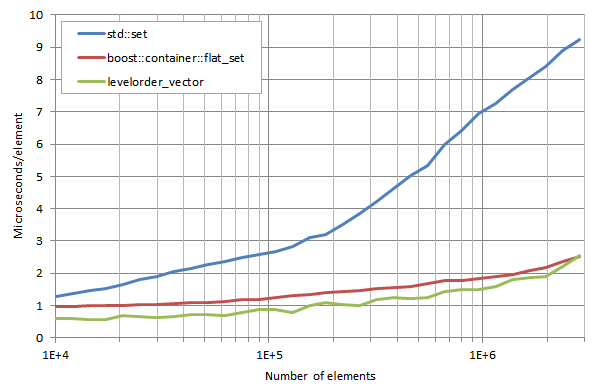
lower_bound execution times / number of elements:
lower_boundの実行時間/要素数
3つのコンテナの理論上の検索時間はO(log n )となり、直線(水平方向の単位は対数)となるはずですが、 n の増加に伴ってキャッシュミスが増えるためグラフが上向きに変化します。 levelorder_vector のパフォーマンスは boost::container::flat_set よりも10~30%の改善度で上回っています。どちらにしても、両方とも std::set よりはずっと速く、 n が5×10の5乗あたりになるまでパフォーマンスはほとんど低下しません( std::set は7×10の4乗あたりから低下が始まります)。この結果には上位キャッシュのフレンドリネスが直接影響しています。
LinuxにおけるGCC
Philippe Navaux、 xckd 、 Manu Sánchez の3人は、親切にも様々なLinuxプラットフォームでのGCCのテスト出力を送ってくれました。結果はどれもよく似ていたので、ここではIntel Core i7-860 @ 2.80GHz環境におけるDebianのLinux kernel 4.0でのGCC 5.1に対応する結果をお見せしましょう。
*注釈
lower_bound execution times / number of elements:
lower_boundの実行時間/要素数
levelorder_vector は boost::container::flat_set に比べて全体的に処理が速いのですが、説明のつかない奇妙な現象が起きています。 n の値が小さい時には、改善度はおよそ40%ですが、その後、 n が3×10の6乗に近づくあたりで改善度が低下し、さらにマイナスにさえなっています。この現象を説明してくれる読者がいらっしゃるとありがたいのですが。 Laurentiu Nicola は後に、 -march=native -O2 の設定で実行し、上で紹介したものとかなり異なる結果を得ました。Intel Core i7-2760QM CPU @ 2.40GHzにおけるGCC 5.1(未公開Linux ディストリビューション)のテスト結果です。
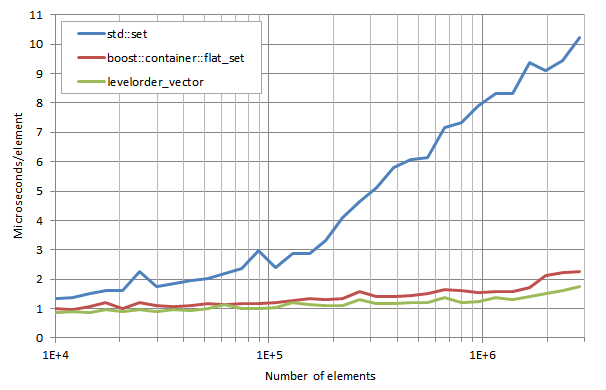
*注釈
lower_bound execution times / number of elements:
lower_boundの実行時間/要素数
そして以下が、Intel Celeron J1900 @ 1.99GHzにおけるGCC 5.1のテスト結果です。

*注釈
lower_bound execution times / number of elements:
lower_boundの実行時間/要素数
-march=native によって大きな違いが出るようです。 n が3×10の6乗に近づくあたりで、 levelorder_vector の処理時間は boost::container::flat_set に比べて最大25%(i7)または、40%(Celeron)速くなります。しかし、 n の値が小さい時には、大差はありません。
OSXにおけるClang
fortch が提供してくれたテスト結果によると、Intel Core i7-3740QM CPU @ 2.70GHz 環境でのDarwin 13.1.0 boxにおける -std=c++0x モードのclang-500.2.79では、以下のようになります。
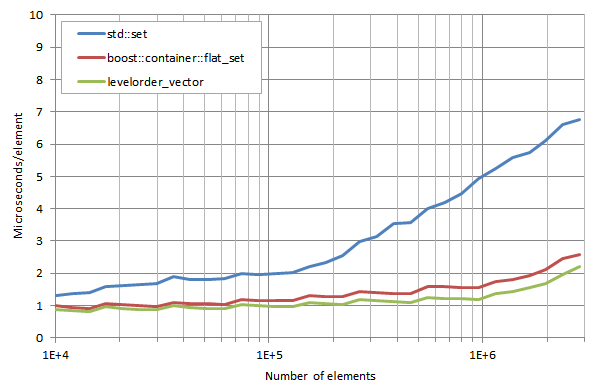
*注釈
lower_bound execution times / number of elements:
lower_boundの実行時間/要素数
boost::container::flat_set に対する levelorder_vector のパフォーマンスの改善度は、10%から20%です。
LinuxにおけるClang
Manu Sánchezは、Intel Core i7 4790k @4.5GHz環境のArch Linux 3.16 boxにおけるClang 3.6.1でテストを行いました。最初は、 libstdc++-v3 標準ライブラリを使用しました。
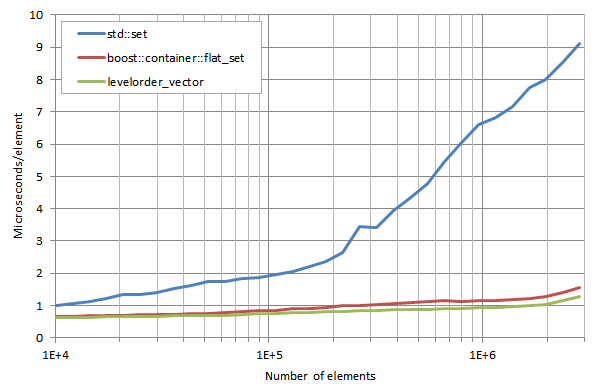
*注釈
lower_bound execution times / number of elements:
lower_boundの実行時間/要素数
次に、 libc++ で再びテストを行いました。
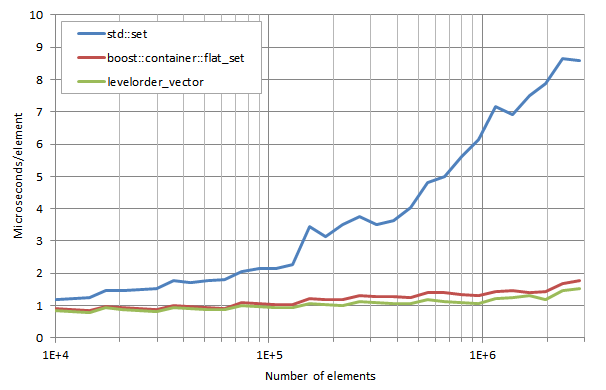
*注釈
lower_bound execution times / number of elements:
lower_boundの実行時間/要素数
似たようなテスト結果が出ました。 levelorder_vector の処理速度は boost::container::flat_set よりも5%から20%速くなっています。これら2つのコンテナで、libc++を使用した時にはグラフ上にはっきりと凹凸が見られます。この凹凸は、OS XにおけるClangでテストした際にも現れていますが、標準ライブラリにlibstdc++-v3を使用した場合は現れていません。ということは、この凸凹は、libc++のメモリアロケータに関連する何かが作用しているせいかもしれません。
Laurentiuが行った -march=native -O2 のClang 3.6.1 でのテスト結果は、先ほどお見せした、Manuが行ったIntel Celeron J1900 @ 1.99GHz環境におけるi7CPUでの結果と似ています。
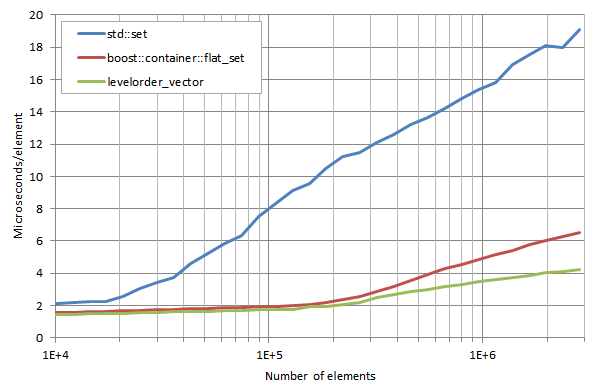
*注釈
lower_bound execution times / number of elements:
lower_boundの実行時間/要素数
levelorder_vector の処理速度は boost::container::flat_set よりも最大35%速くなっています。
結論
ソートされた配列に対する二分探索の方がノードベースのデータ構造に対する処理速度より速いとしても、代替手段の連続レイアウトの方が、さらにキャッシュフレンドリーです。ソートされた数列を持つ二分木の幅優先で、要素の配列に基づく様々な可能性を見てきました。このデータ構造は、パフォーマンスは低いかもしれませんが、追加や削除などの操作ではどうでしょうか。このテーマについては、今後の記事で考察したいと思います。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事