2017年7月25日
レガシープロトコル向けレガシー検索エンジンの構築
(2017-05-21)by Ben Cox
本記事は、原著者の許諾のもとに翻訳・掲載しております。
現在、ほとんどのインターネットユーザが主に注目するプロトコルは3つあります。それはHTTP、TLS、DNSです。
最近のユーザはWebページの表示方法に対する関心がないかもしれませんが、よく知られ、好まれているプロトコルであるHTTPとは相容れないプロトコルがかつてありました。
それはTCPのポート番号をHTTPから10減らしたポート番号70の Gopher です。ベーシックなHTTP/1.0に非常によく似たプロトコルです。
基本であるHTTP/1.0では以下のようにしなければなりません。
$ nc blog.benjojo.co.uk 80
GET / HTTP/1.0
HTTP/1.1 403 Forbidden
Date: Wed, 03 May 2017 19:11:28 GMT
Content-Type: text/html; charset=UTF-8
Connection: closeしかし、Gopherのリクエストはもっと基本的です。
$ echo "/archive" | nc gopher.floodgap.com 70
1Floodgap Systems gopher root / gopher.floodgap.com 70
i error.host 1
iWelcome to the Floodgap gopher files archive. This contains error.host 1
imirrors of popular or departed archives that we believe useful error.host 1基本的なbashユーティリティを使用してファイルをダウンロードできるので、基本的なファイル転送には最適です!
しかし、結局、HTTPがGopherをしのぎました。HTTPはインターネットでほとんどのユーザが使うプロトコルになりました。その理由は興味深いものですが、既にうまく説明した人がいます。 こちらの優れた記事を見てください 。
検索エンジンはHTTP向けにあるものです。Gopherは自らのプロトコルの中に検索機能をサポートしていますが、全てのGopher向け検索エンジンが “Gopher空間” の中にあります。HTTPには(私の知るかぎり)ありません。
私の 友人 に、インターネットで zmap スキャンをポート番号70に実行してもらったあと、実際のGopherのサーバ向けに結果をフィルタリングしました。
[ben@aura tmp]$ pv gopher.raw | grep 'read":"i' | jq .ip | sort -n | uniq -c | wc -l
2.14GiB 0:00:08 [ 254MiB/s] [================>] 100%
370インターネット上にはGopherを提供する悲しき370のサーバが残されています。
クローラの構築
簡単なRFC1436実装とクローラのコードを書き、ゆっくり(これらのホストの後ろには非常に古いサーバがあります)セレクタであるすべてのメニューと私が見つけたテキストファイルがクロールされ始めました。
同じタイミングで、Gopher空間自体の検索を開始しました。ぜひともお伝えしたいのは、Gopher空間が全くピュアなコンテンツにとっては何ともすばらしい空間で、CSSやadtechがあらゆる所に配置された現在のインターネットとは全く違っているということです。

コンテンツへのインデクシング
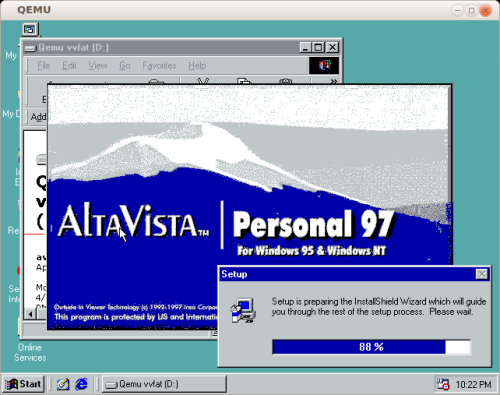
Gopherは1990年代から提供されているので、当時から検索エンジンの技術を使うことが当然のこととされていたと思われます。かつて AltaVista が個人/ホームユース用にデスクトップコンピュータ向けの検索エンジンを販売したことがあります。しかし、それはWin32専用のソフトウェアでした。私はWINE上での実行は試みませんでしたが、その代わりに、ソフトウェアのより本格的な運用を目標にしました。 NeoZeedによるすばらしい出来栄えのガイド を使って、自分のWindows 98の検索 “サーバ” へのプロビジョニングを終わらせたのです。
I never thought I be doing this again, and yet, here we are! Join me in the adventures of "oh god we are installing windows 98 again" pic.twitter.com/Ub83PQ4sV7
— Ben Cox (@Benjojo12) 2017年5月6日
もう一度この作業を行うことになるとは思いもしませんでした。でも、今、実行しているところです。 “Windows 98をもう一度インストールするという驚き” の出来事に参加してみてください。
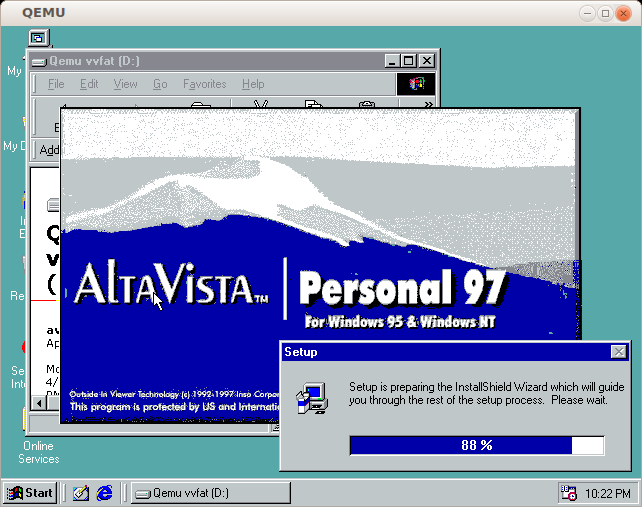
以下のように、検索エンジンが動作しました。
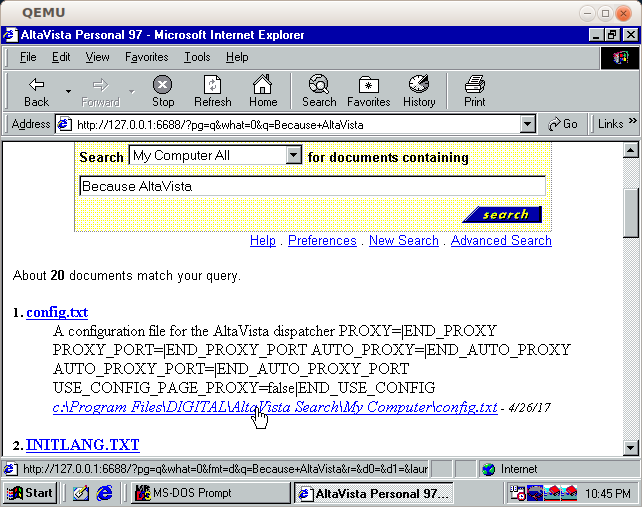
NeoZeedが見つけ出したように、検索インターフェースは(ハードコードされた)ループバックだけを監視しています。これは、より広い世界に検索インターフェースを公開したい場合には、とても厄介なことです。この解決策として、SSLを追加して、全てを監視し、中継コネクションがローカルインスタンスに戻るように stunnel がデプロイされました。 かなり怪しげな(しかしCTが記録した)デフォルトのSSL証明書も使っています ( アーカイブ )。
インデクサにデータを提供する
インデクサとバックエンドはWindows 98のQEMUのVMなので、AltaVistaのインデクサがインデックスを参照してインデックスに含めたりするために、約5ギガバイトになる小さなファイルをVMに与える方法が必要です。このため、24時間ごとにクロールされたデータのスナップショットとしてFAT32ファイルシステムを作成し、その後、新しいファイルを参照するためにクローリングVMを再起動することにしました。この方法は、少数ファイルでのテストでは、実際にとてもうまく動作したのですが、いくつかの問題点が明らかになりました。まずFAT32には、注意を払わなければいけないファイル制限があります。例えば、FAT32ではルートディレクトリには255を超えるファイルを置くことはできません。そのため、ファイルをフォルダ構造に展開する必要があります。
覚えておかなければならない別の問題は、FAT32に対する最大のドライブサイズは約32ギガバイトだということです。これは、テキストコンテンツの容量がその値を超えることはできないということ意味しています(または、さらに多くの仮想ドライブを設置する必要があるということです)。幸いなことに、クロールされたコンテンツの大きさは、それよりはるかに小さいので、このことは問題になりません。
“プロダクトサイズ” データセットのクローリングを行っている間、システムはインデックスプログラムの実行中にランダムな時点でリセットされることになります。
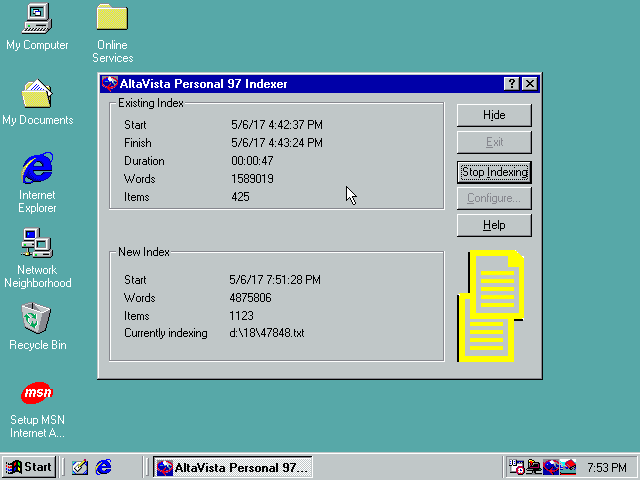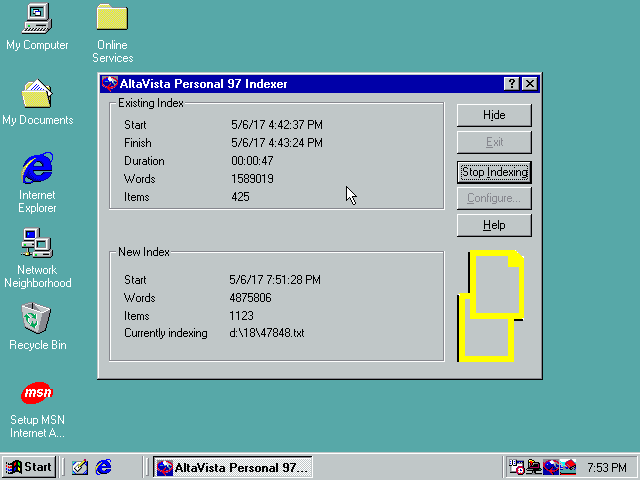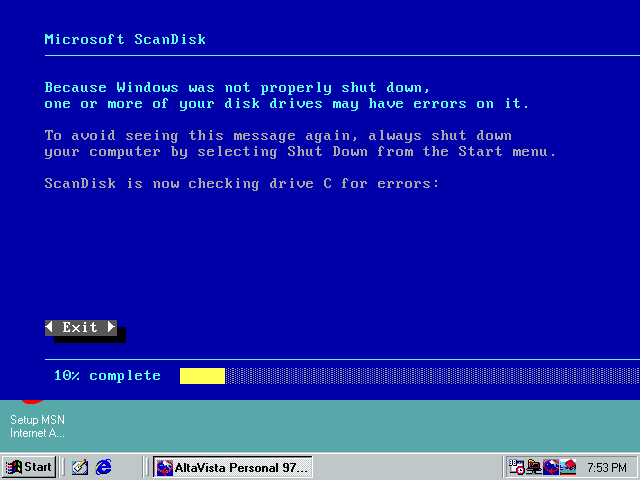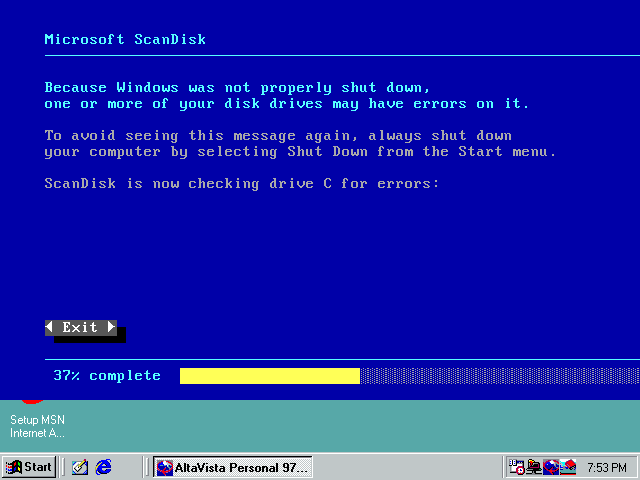
ディスクキャッシュに関する設定を調整した後、やや建設的なエラーが得られました。
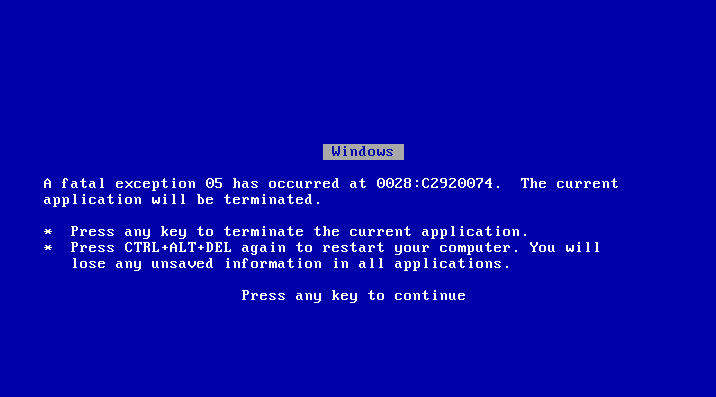
これはよいことです。 ”exception 05 has occurred at 0028:C2920074″ を探せばいいのです。そうですよね?あいにく、インターネットにはこれと同じようなクラッシュについての情報はほとんどありません(過去のどこかの時点では存在していたかもしれませんが、すでに削除されています。やはり、このOSは約20年前に生まれたものですから)。しかし、検索により収集できた情報の1つによると、VFATドライバに関連しているということです。高いIO負荷とQEMUの INT 13 の実装との組み合わせが悪さをしていると思い、他の唯一のファイルシステムや入力システムであるCD/DVD ROMを使うことにしました。
小さな500メガバイトでテスト(FAT32はパスできなかったもの)すると、小さいインデックスが作成されました。
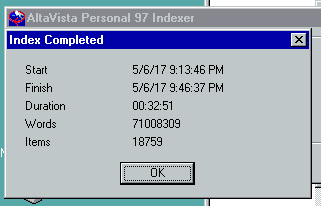
ここで、ソリューションを300キロバイトや4ギガバイトのファイルまでスケールアップする必要がありました。ドライブの容量が2ギガバイトよりはるかに大きくても、UIは2ギガバイト分しか表示しませんが、Windows 98がそれよりも大きいDVDをサポートすることを発見しました。全てのコンテンツがアクセス可能で、最初のインデックスは(ゆっくりと)構築されました。
インデックスインターフェイスのサニタイズ
約20年前のインデクサを使用する際の問題点が1つだけあります。それは、インターネットに直接公開するというのは 非常に 悪い考えだということです。この他に困るのは、ほとんどのページでインターフェースがローカル( file:// のように)アセットを参照のように扱っていることです。つまり、単純なリバースプロキシは機能しません。
さらに、ローカルパスは検索する側にとって、あまり役に立つものではありません。 alta-sanitise は、Windows 98のAltaVistaのインデックスをバックエンドで保持しながら、正しくフロントエンドを提供するために書かれているからです。
そのため、ダウンロードした全てのファイルを含むファイルシステムを作成し、データベースIDの名前をつけました。
しかし、alta-sanitiseでは、クローリングで作成したデータベースを使用して表示可能なURLに書き直します。
VMが1つ以上のプロジェクトで使用できるようにするために、lighttpdを alta-sanitise のリバースプロキシとして前に置いて、Cloudflareをキャッシュに使いました。最終フローは次のようになります。
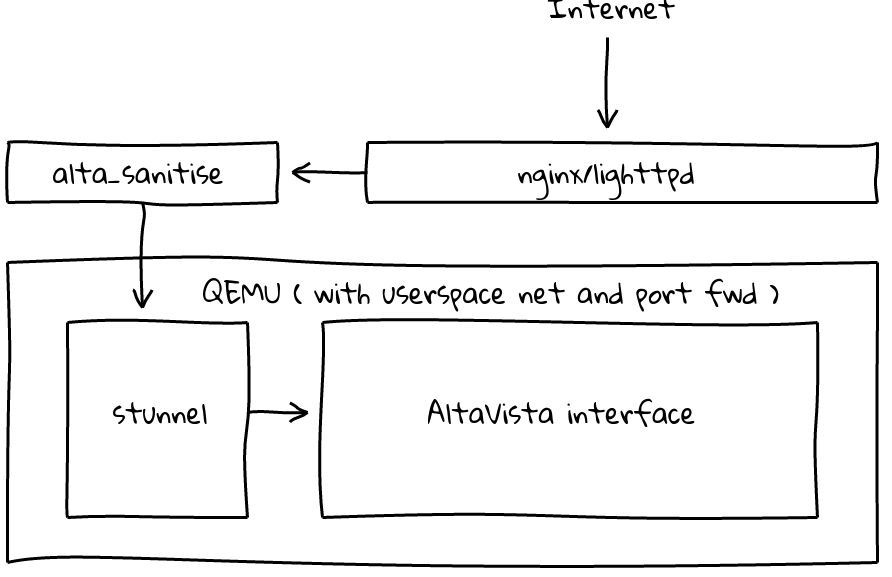
注釈:インターネット
alta-sanitise、nginx/lighttpd
QEMU(ユーザ空間ネットとポートフォワード)
stunnel、AltaVistaインターフェース
Windows 98の監視
私のサーバのほとんどはcollectdで監視されています。しかし残念なことに、collectdに対応するWindows 98のクライアントは存在しないのです。自分で作成することにしました。
シンプルなVisual Basic 6のアプリケーションで10秒ごとにポーリングし、シリアルポート経由で collectdコマンド文字列 を出力します(ハイパーバイザー上のcollectdにパスされます)。
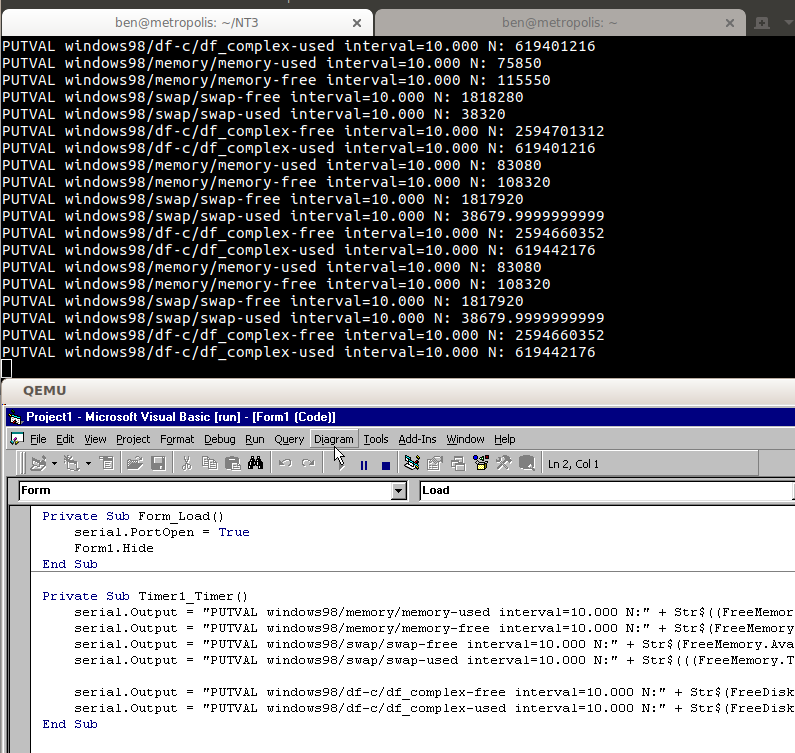
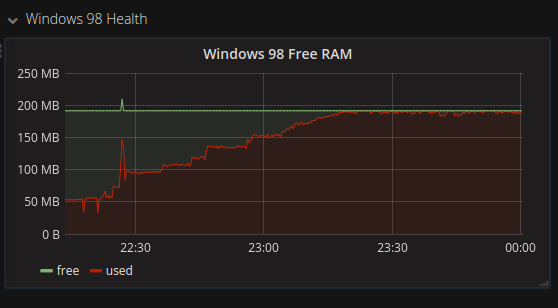
このコードは https://github.com/benjojo/win32-collectd に単独で載っています。(Gopherのクローラ以外にも、悩める方の役に立つものが見つかるかもしれません)
コミュニティに還元する
Gopher空間の大きなインデックスを手にすることができたので、今度はこれをGopher空間に返すべきでしょう。
Gopherで私のブログ gopher.blog.benjojo.co.uk を検索することができます(Gopherでのみアクセス可能。ちなみに、LynxもGopher をサポートしています)。
以下のサイトで検索エンジンが使用できます: http://gophervista.benjojo.co.uk
以下のサイトでコードが見つかります: https://github.com/benjojo/gophervista

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- Twitter: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事