2017年6月13日
MXNet API入門 パート1
(2017-04-09)by Julien Simon
本記事は、原著者の許諾のもとに翻訳・掲載しております。
(注:2017/06/16、いただいたフィードバックを元に翻訳を修正いたしました。)
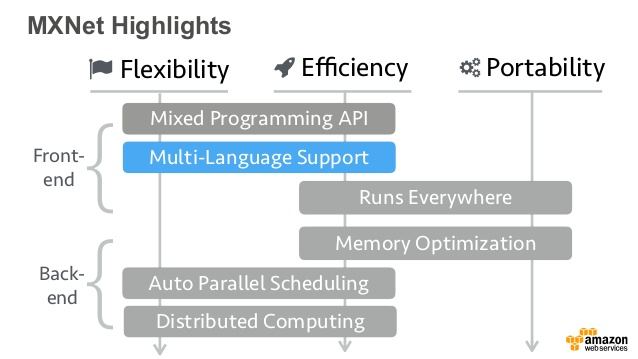
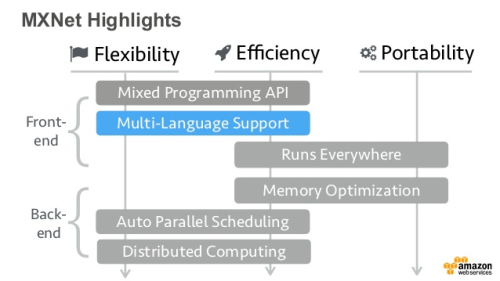
MXNetチュートリアル
このシリーズでは、 MXnet 深層学習ライブラリの概要をまとめていきます。主な機能やPython API(もっとも選択しやすいと思います)について説明します。それからMXNetチュートリアルやオンラインで提供されているノートブックを探究してみましょう。うまくいけば、なんとかコードの1行1行を理解出来るようになるでしょう。
MXNetの理論的根拠やアーキテクチャについて学びたい方は、ぜひ『 MXNet: A Flexible and Efficient Machine Learning Library for Heterogeneous Distributed Systems(MXNet: ヘテロジニアス分散システムのための柔軟で効率的な機械学習ライブラリ) 』という 論文 をお読みください。この論文に書かれている概念のほとんどに触れますが、より分かりやすく説明できればと思っています。
ゆっくりと進めながら可能なかぎり説明します。計算や専門用語も必要最低限にしますが、意図的にレベルを下げた説明はしません。これを読んだからといって専門家にはなれません。これを書いている私も専門家ではありません。それでも、独自のアプリケーションに深層学習機能を追加出来るだけの知識を得ることはできると思います。
MXNetをローカルで動かす
最初にMXNetをインストールしましょう。公式の使用説明書は ここ にありますが、さらに秘訣を幾つか教えましょう。
MXNetのカッコいい機能の1つに CPUとGPUで全く同じように動いてくれる ものがあります(後で演算の際の選択方法について説明します)。これは、(私のMacBookのように)Nvidia GPUが搭載されていないコンピュータでも、後ほど、GPU対応システムで使うことになるMXNetコードを書くことも実行することも可能だということです。
もし使っているコンピュータにGPUなるものが搭載されていれば最高ですが、 悪夢 をもたらす可能性の高い CUDA ツールキットおよび cuDNN ツールキットをインストールする必要があります。MXNetバイナリとNvidiaツールの間で少しでも不一致が生じるとこれまでのセットアップは破たんし、使えなくなってしまいます。
このため、MXNetのWebサイトで提供されているDockerイメージをそれぞれ、CPU環境およびGPU環境に使うよう 強く 忠告します( nvidia-docker が必要になります)。これらのイメージには、必要なもの全てがあらかじめインストールされているので、すぐに始めることができます。
sudo -H pip install mxnet --upgrade
python
>>> import mxnet as mx
>>> mx.__version__
'0.9.3a3'参考までに付け加えますが、Dockerイメージは「pip」で提供されるPythonパッケージ よりも最新 のバージョンが提供されていると思います。
docker run -it mxnet/python
root@88a5fe9c8def:/# python
>>> import mxnet as mx
>>> mx.__version__
'0.9.5'MXNetをAWSで動かす
AWSでは、 Linux 用と Ubuntu 用の 深層学習AMI を提供しています。AMIには、MXNet含め、多くの深層学習フレームワークがあらかじめインストールされています。 特別な調整は不要です。
====================================================================
__| __|_ )
_| ( / Deep Learning AMI for Amazon Linux
___|\___|___|
====================================================================
[ec2-user@ip-172-31-42-173 ~]$ nvidia-smi -L
GPU 0: GRID K520 (UUID: GPU-d470337d-b59b-ca2a-fe6d-718f0faf2153)
[ec2-user@ip-172-31-42-173 ~]$ python
>>> import mxnet as mx
>>> mx.__version__
'0.9.3'このAMIは、通常のインスタンス上またはGPUインスタンス上で実行できます。コンピュータにNvidia GPUを搭載していない場合は、後でネットワークのトレーニングを始める時に便利になります。最も安価なオプションは g2.2xlarge インスタンスを1時間約73円で使用することです。
今ここで必要となるのは、昔ながらのCPUです。では、始めましょう。
NDArrayはなぜ重要か
MXNet APIで最初に見るのは、 NDArray API です。NDArrayとは、 全く同じ型とサイズの項目を含む (32ビット浮動小数点数や32ビット整数など)、 n次元配列 です。
なぜこれらの配列は重要なのでしょうか。 前の記事 でも説明しましたが、ニューラルネットワークのトレーニングや実行には多くの数学演算を必要とします。多次元配列でデータ保存を行います。
入力データやニューロンウェイト(重み値)、出力データはベクトルや行列に格納されるため、この種の構造体を使用するのは至って自然です。
簡単な例、画像の分類を見てみましょう。下記の画像は手書きの数字の「8」を18×18ピクセルで表示しています。

18×18ピクセルで表した数字の8
これは、18×18行列の画像と同じ画像を表しています。該当するピクセルに対応するセルがそれぞれグレースケール値を持っています。例えば、「0」は白で、「255」は黒、その間の値は254種の灰色の色合いを表します。この行列の表現をニューラルネットワークに実行して、0から9までの数値を分類するトレーニングをさせます。

上記の画像に対応するグレースケール値を持つ18×18行列
では、グレースケールの画像の代わりにカラーの画像を使った場合を想像してください。それぞれの画像は、それぞれのカラー用の3つの行列を使って表すため、入力データは若干複雑になります。
さらに進めてみましょう。自立粗鋼のためのリアルタイム画像認識をしていると仮定します。最新のデータを元に決定を下すために 1000×1000ピクセルのRBG画像を毎秒30フレームで使用します。毎秒90個の1000×1000行列(30フレーム×3色)が処理されます。各ピクセルは32ビット値で表しているので、90×1000×1000×4バイト、つまり343メガバイト前後になります。複数のカメラがある場合は、バイト数はすぐに膨れ上がってしまいます。
最高のパフォーマンス(例えば最低限のレイテンシ)で、ニューラルネットワークが処理するデータとしては膨大な量なので、GPUは画像を1つ1つ処理するのではなく、バッチで処理します。仮にバッチサイズが8だとすると、ニューラルネットワークは入力データを1000×1000×24の束で処理します。例えば、3次元配列が8個の3色の1000×1000画像を持つ場合です。
肝心なのは、NDArrayを理解することです。ニューラルネットワークに必須で、ほとんどのデータを格納するために使用されます。
NDArray API
なぜNDArrayが重要なのか分かったので、どのようにして動くかを見てみましょう(やっとコード部分です)。 numpy Pythonライブラリを使ったことある方には朗報です。NDArrayはとても良く似ていて、すでにAPIのほとんどを知っていると思います。完全にドキュメント化されていますので、 こちら で入手してください。
では、基礎から始めましょう。解説は不要ですよね。
>>> a = mx.nd.array([[1,2,3], [4,5,6]])
>>> a.size
6
>>> a.shape
(2L, 3L)
>>> a.dtype
<type 'numpy.float32'>NDArrayはデフォルトで32ビット浮動小数点数を持っていますが、これは変更可能です。
>>> import numpy as np
>>> b = mx.nd.array([[1,2,3], [2,3,4]], dtype=np.int32)
>>> b.dtypeNDArrayの出力は下記のとおり簡単です。
>>> b.asnumpy()
array([[1, 2, 3],
[2, 3, 4]], dtype=int32)期待している数学演算子の全てが利用可能です。では、要素ごとの行列の乗算を試してみましょう。
>>> a = mx.nd.array([[1,2,3], [4,5,6]])
>>> b = a*a
>>> b.asnumpy()
array([[ 1., 4., 9.],
[ 16., 25., 36.]], dtype=float32)正しい行列の乗算はどうでしょう(「ドット積」とも呼ばれます)。
>>> a = mx.nd.array([[1,2,3], [4,5,6]])
>>> a.shape
(2L, 3L)
>>> a.asnumpy()
array([[ 1., 2., 3.],
[ 4., 5., 6.]], dtype=float32)
>>> b = a.T
>>> b.shape
(3L, 2L)
>>> b.asnumpy()
array([[ 1., 4.],
[ 2., 5.],
[ 3., 6.]], dtype=float32)
>>> c = mx.nd.dot(a,b)
>>> c.shape
(2L, 2L)
>>> c.asnumpy()
array([[ 14., 32.],
[ 32., 77.]], dtype=float32)それでは、少し複雑なことを試してみましょう。
- 1000×1000行列を一様分布で初期化し、GPU#0に保存します(ここではg2インスタンスを使用しています)。
- 別の1000×1000行列を正規分布(平均値1と標準偏差値2)で初期化し、これもGPU#0に保存します。
>>> c = mx.nd.uniform(low=0, high=1, shape=(1000,1000), ctx="gpu(0)")
>>> d = mx.nd.normal(loc=1, scale=2, shape=(1000,1000), ctx="gpu(0)")
>>> e = mx.nd.dot(c,d)MXNetがCPUとGPUで全く同じように動いてくれることを忘れないでください。例えば、上記の例で “gpu(0)” を “cpu(0)” に置きかえれば、ドット積はCPUで処理されることになります。
これで、NDArrayで遊べるだけの知識はついたと思います。ニューラルネットワークを構築するために使える高度な機能もありますが、ネットワークの説明の時に触れます( FullyConnected ニューラルネットワークなど)。
今回はここまでです。次のパートでは、ニューラルネットワークにとって重要なデータフローを定義させてくれるSymbol APIについて見ていきます。最後まで読んでいただきありがとうございます。今後もご期待ください。
続きのパート:
訳注:原文ウェブサイトに遷移します。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事