2017年5月10日
興味深いデータ構造:BK木

(2017-04-03)by Michele Lacchia
本記事は、原著者の許諾のもとに翻訳・掲載しております。
BK木とは、 距離空間 内のデータをインデックス化する目的に特化した、木構造を指します。距離空間は基本的に、要素の組 $ (a,b) $ 全てについて距離関数 $ d(a,b) $ を持つオブジェクトの集合です。この距離関数は正しく動作することを保証するために、一連の公理を満たしていなければなりません。これが必要になる理由は、後述の「検索」のセクションできちんと説明します。
BK木のデータ構造は、一連のキーを検索し、与えられた検索キーの値に最も近いキーを見つける問題の解決策として、 1973年にBurkhardとKellerが提案したもの です。この問題を解決する素朴な方法は、要素の組に含まれる各要素と検索キーの値を単純に比較することです。一定の時間内に比較が完了した場合、この検索の解は $ O(n) $ となります。一方、BK木を採用すると、この時実行する比較の回数を減らせる可能性が高くなります。
木構造の構築
BK木は以下の方法で定義されます。任意の要素 $ a $ をルートとして選択します。ルートは0個以上の部分木を持つことができます。 $ k $ 番目の部分木は、全ての要素 $ b $ について $ d(a,b)=k $ となるように再帰的に構築されます。
では、現実的なシナリオを使って、BK木を構築する方法を見ていきましょう。単語の辞書を用意して、そこに含まれている語の中から、与えられた検索語と最も近似しているものを探すとします。対象となっている2つの語がどれほど近似するかを測る基準として、 レーベンシュタイン距離 を使います。これは基本的に、ある単語を別の単語に変更するために必要な、1文字ずつの編集操作(挿入、削除、置換のいずれか)の最小限の実行回数で表します。例えば、「soccer」(サッカー)と「otter」(ラッコ)との距離は $ 3 $ です。「soccer」の最初の文字sを削除し、真ん中の2つの c を2つの t と置き換えれば、「soccer」を「otter」に書き換えることができるからです。
今回は以下の辞書を使います。
{'some', 'soft', 'same', 'mole', 'soda', 'salmon'}木構造を構築するには、まず任意の単語をルートノードとして選択し、続いて他の単語を追加して、ルートノードからその単語までの距離を計算します。ここでは「some」をルート要素とします。次に2つの単語を追加すると、以下の木構造ができます。
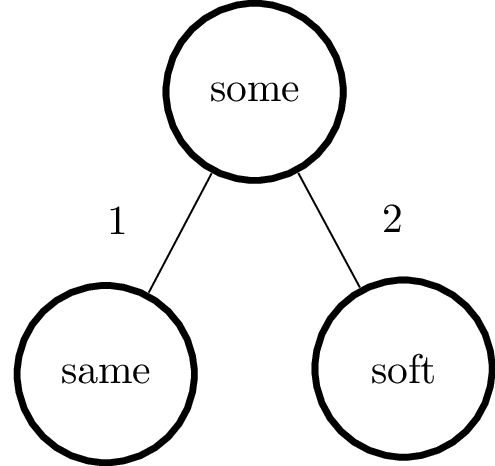
ここで、「some」と「same」の距離は $ 1 $ 、「some」と「soft」の距離は $ 2 $ となります。ではこの木構造に、次の単語である「mole」を追加しましょう。「mole」と「some」の距離が再び $ 2 $ となることに注目してください。距離に応じた数の枝を持たせるため、「mole」が「soft」の子ノードとなるようにツリーを構築します。同様に全ての単語を追加すると、木構造は以下のようになります。

検索
では話を戻して、そもそもの問題は「特定の検索キーに最も近い単語を全て選び出す」だったことを思い出してください。ここで、許容できる最大の距離(半径と呼ぶことにします)を $ N $ とします。アルゴリズムは以下のように進みます。
- 候補のリストを作成し、そこへルートノードを追加する
- 候補を1つ選択して、検索キーとの距離 $ D $ を計算し、半径と比較する
- 選択基準:現在のノード、即ち親ノードからの距離が $ D−N $ と $ D+N $ の間の値となる子ノードを(全て)候補リストに追加する
今回は、辞書内で「sort」という語からの距離が $ N=2 $ 以下となる単語を全て探すことにします。唯一の候補はルートノードである「some」です。では次の式の実行から始めましょう。
$ D=Levenshtein(‘sort’,‘some’)=2 $
半径は $ 2 $ なので、「some」を結果リストに追加します。次に、ルートノードからの距離が $ D−N=0 $ と $ D+N=4 $ の間となる子ノードを全て含むよう、候補リストを拡張します。こうすると、全ての子ノードがこの条件を満たすことになります。では別の条件を考えましょう。次の式を実行します。
$ D=Levenshtein(‘sort’,‘same’)=3 $
ここで $ D>N $ なので、このノードは求める結果ではありません。従って次の要素「soft」に移り、次の式を実行します。
$ D=Levenshtein(‘sort’,‘soft’)=1 $
このように「soft」は条件に合致する結果です。その子ノードを対象に、距離が $ D−N=−1 $ から $ D+N=3 $ の範囲にあるものを見つけます。全ての対象に同様の処理を行うと、”soda”だけが条件に合致します。最終的に、「salmon」は条件に合致しません。この結果を距離でソートすると、以下のようになります。
[(1, 'soft'), (2, 'some'), (2, 'soda')] どうして機能するのか?
上記のポイント3の基準に合わない子ノードを どうして 切り離してよいのかを理解するのは興味深いことです。導入部で述べましたが、距離空間の構造を得るために、距離関数 d はいくつかの公理を満たす必要があります。以下に挙げたのがその公理です。全ての要素 $ a $ 、 $ b $ 、 $ c $ に対して、以下の条件を満たさなければなりません。
- 非負性: $ d(a,b)≥0 $
- $ d(a,b)=0 $ は $ a=b $ を意味する(逆もまた可)
- 対称性: $ d(a,b)=d(b,a) $
- 三角不等式: $ d(a,b)≤d(a,c)+d(c,b) $
最初の3つは「距離」に関する直感的な考えを形式化しただけですが、最後の1つは、ユークリッド幾何学における三角形の辺の間の関係から導かれる公理です。これはしばしば、一般的な距離が実はメトリックであるということを証明する際に、実証が最も難しい性質となります。これが判明すれば、レーベンシュタイン距離はその性質を満たすので、メトリックであると言えます。上記の例でこの公理を使えるのは、そのためです。
検索キーを $ \overline{x} $ と呼ぶことにします。木において、任意のノード $ A $ の子ノードである $ B $ を評価するとします。この木は、検索キーからの距離が $ D=d(\overline{x},A) $ となるように計算したものです。この状況をまとめると以下の図のようになります。
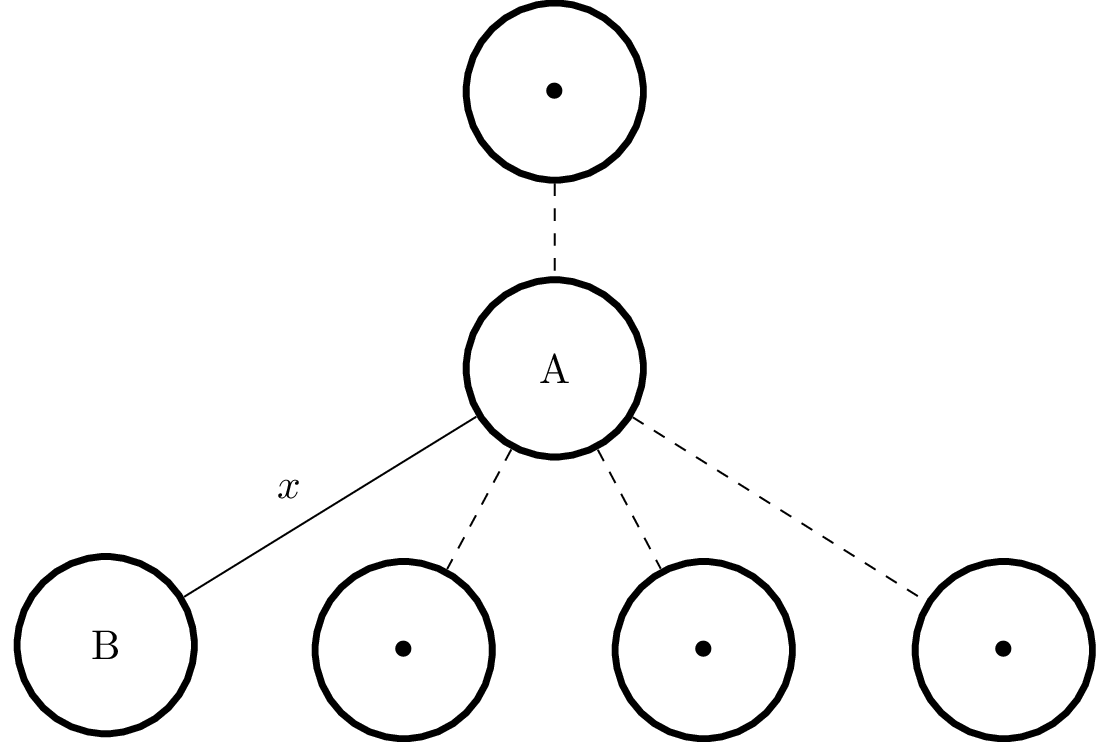
$ d $ はメトリックなので、三角不等式によって次のようになります。
$ d(A,B)≤d(A,\overline{x})+d(\overline{x},B) $
これから次の式が導かれます。
$ d(\overline{x},B)≥d(A,B)−d(A,\overline{x})=x−D $
今度は $ d(A,\overline{x}) $ と $ B $ に対して再び三角不等式を適用すると、次の式が得られます。
$ d(\overline{x},B)≥d(A,\overline{x})−d(A,B)=D−x $
検索キー $ \overline{x} $ から 最大 $ N $ の距離にあるノードを求めたいので、 $ d(\overline{x},B)≤N $ という制約を与えます。これは次のようになります。
\begin{equation}
\left \{
\begin{array}{l}
x−D≤N \\
D−x≤N
\end{array}
\right.
\end{equation}
これは次の式と等しくなります。
$ D−N≤x≤D+N $
$ d $ がメトリックであれば、前述した基準に合わないノードを注意深く切り離すことができることを証明しました。最後に、(BK木の構造から) $ B $ の いずれ の子ノードも $ A $ からの距離が $ x $ であるということに注意してください。そのため、 $ B $ が基準に合致しないというだけで、その部分木を全て切り離しても安全なのです。
実装
枝を表すために辞書を使う場合、このデータ構造はPythonで容易に実装できます。
from collections import deque
class BKTree:
def __init__(self, distance_func):
self._tree = None
self._distance_func = distance_func
def add(self, node):
if self._tree is None:
self._tree = (node, {})
return
current, children = self._tree
while True:
dist = self._distance_func(node, current)
target = children.get(dist)
if target is None:
children[dist] = (node, {})
break
current, children = target
def search(self, node, radius):
if self._tree is None:
return []
candidates = deque([self._tree])
result = []
while candidates:
candidate, children = candidates.popleft()
dist = self._distance_func(node, candidate)
if dist <= radius:
result.append((dist, candidate))
low, high = dist - radius, dist + radius
candidates.extend(c for d, c in children.items()
if low <= d <= high)
return result実装は非常に分かりやすく、前に説明したアルゴリズムに完全に沿ったものです。いくつかコメントがあります。
-
__init__メソッドに引数rootを加える必要はありません。どの要素もルートノードになることが可能だからです。今回の例では最初に加えた要素がルートとなります。 -
なぜ
dequeが必要なのでしょうか。最初はsetを使いましたが、エラーになってしまっただけでした。辞書はハッシュ処理が可能な状態ではないからです。 $ O(1) $ が得られて挿入ソートができるような他のデータ構造が必要です。ビルトインのdequeは、双方向連結リストなので、無理なく適合します。
まとめ
BK木は、最近傍探索(NNS)に適したデータ構造ですが、認知度はあまり高くありません。処理を行う距離を メトリック とした場合、BK木によって検索空間をかなり削減できます。実際に使ってみると、部分木の切り離しによって処理速度がどの程度向上するかは、検索空間 および 選択した半径に大きく依存します。当面の問題に対処する際には、常に何度か実験する必要があるのはそのためです。BK木の得意分野の1つに、スペルチェックがあります。半径を $ 1 $ か $ 2 $ に維持する限り、検索空間は当初の $ 10% $ 以下にまで削減されます。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事