2016年7月26日
Haskell、Scala、ML、Scheme:あなたが次に学ぶ関数型言語

本記事は、原著者の許諾のもとに翻訳・掲載しております。
(編注:2016/7/27、頂いたフィードバックを元に記事を修正いたしました。)
学生たちから、次に学ぶ言語はどれがいいのかとよく聞かれます。IT業界で働きたい人にお薦めするのは、現在盛んに使われている言語です。C++、Java、C#はもちろん、Python、Ruby、PHP、Perlなども挙げられるでしょう。
一方、向学のためという人や、学術研究や起業に関心がある人にとって、次の言語を選ぶ基準となるのは、就職に有利かではなく言語の表現力でしょう。学術研究や起業活動を行うには、プログラマとしての能力を何倍にも高める必要があります。そして、(おそらく)確立されたコードベースを扱った経験はないでしょうから、手元にあるタスクにとって最適な言語を自由に選ぶことができます。
この記事では、勉強に適したHaskell、Scala、ML、Schemeという4つの言語を、私の好きな特徴や参考資料のリストと併せてご紹介します。
もちろん、この短いリストは決して網羅的なものではありません。普及はしていなくても、ニッチな分野で優れているという言語はたくさんあります。少しだけ例を挙げると、Dはシステムプログラミングに、ErlangやClojureは並行処理に、そしてDatalogは制約プログラミングに適した言語です。それから、昔主流だったコンピューティングから派生した代替言語でありながらも十分な機能を備えている、Smalltalkのような言語もあります。
私は学生たちに、ニッチな言語の勉強を決してやめてしまわないようにと言っています。ニッチな言語を学ぶことで、考え方が広がり、素早く解決できる問題の種類が増え、コンピュテーションの意義に対する認識が深まるのです。
高度な言語の例
- Haskell
- Scala
- Standard MLとOCaml
- Scheme
Haskell
Haskell はコンパイラやインタプリタ、静的アナライザを書く言語として優れています。私は人工知能や自然言語処理、機械学習の研究はあまり行っていませんが、もし本格的に手掛けるとすれば、まずHaskellを選ぶでしょう(2番目はSchemeが有力)。Haskellは、遅延評価を行う純粋関数型プログラミング言語としては唯一広く使われている言語です。
Standard MLやOCamlと同様、Haskellは Hindley/Milner式 の型推論の拡張版を使います。つまり、コンパイラが型を推論できるので、プログラマは(大部分の)型を書く必要がないということです。私の経験上、Hindley/Milnerの型システムではバグがあまり発生しません。実際、経験豊富なプログラマは、正確性を保つための制約をHaskellの型システムに直接コード化することがうまくなります。Haskell(またはML)で初めてプログラムを書いた人からよく聞くのは、コンパイルがうまくいけばほぼ間違いなく正確なコードだと分かるという感想です。
純粋な言語では、副作用(変数やデータ構造の変化、I/O)は言語の中で厳密に禁じられています。このため、言語の設計者はそうした機能を提供する方法を真剣に検討してきました。その解決策が モナド です。モナドは、副作用やI/Oを安全に制約されたフレームワークの内部で実行できるようにしてくれます。もちろん、Haskellではユーザが独自のモナドを定義できますので、プログラマはモナドにアクセスすることで、継続、トランスデューサ、例外、論理プログラミングなどを記述できるようになっています。
純粋であることに加えて、Haskellには遅延性があります。つまり、Haskellにおける式は、計算を進めるのに必要となるまで(かつ必要とならない限り)は評価されません。遅延性から得られるはずの効率が実現されていないとの声もありますが、その点は私にとって問題ではありません。私は、遅延性は 表現力 を高めてくれるものだと考えているのです。Haskellでは、無限のデータ構造を記述するのは簡単なことです。他の言語では相互再帰的な関数を記述できますが、Haskellでは相互再帰的な値を記述できます。
より実用的な点としては、遅延性はオプション型をコード化するのに便利だと気づきました。空値のケースを用いるとプログラムが必ず駄目になってしまうような場面です。Haskellでは、オプション型を生成するのは避けて、代わりに error を使って空値を生成することができます。遅延評価であるがゆえ、Haskellのあらゆる型は2つの付加的な値、つまり非終端とエラーを自動的に持ちます。これをうまく使えば、大部分の冗長なパターンマッチングをなくせます。
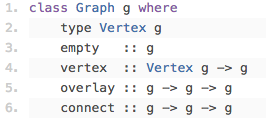
Haskellで私が気に入っている機能は、型クラスです。Haskellの型システムでは、コンパイラは型のコンテキスト でさえ 推論しながら、その型のコンテキストに基づいて正確に実行できるコードを推論します。私がすごいと感じた型クラスの例は、有界束です。 有界束 は数学的な構造であり、最小元( bot )、最大元( top )、部分的に順序づけられた大小関係( <: )があり、和演算( join )と積演算( meet )が可能です。
Haskellでは、有界束を型クラスとして定義できます。
class Lattice a where
top :: a
bot :: a
(<:) :: a -> a -> Bool
join :: a -> a -> a
meet :: a -> a -> aこれは、型 a が Lattice なら、 a は上記の期待された演算をサポートするという意味です。
私がHaskellで特に気に入っている点は、プログラマがクラスの条件付きインスタンスを定義できることです。例を挙げましょう。
instance (Ord k, Lattice a) => Lattice (Map k a) where
bot = Map.empty
top = error $ "Cannot be represented."
f <: g = Map.isSubmapOfBy (<:) f g
f `join` g = Map.unionWith join f g
f `meet` g = Map.intersectionWith meet f gこのルールは、型 k が順序(クラス Ord )のインスタンスで、型 a が束のインスタンスであれば、 k から a へのマップも束のインスタンスになるという意味です。
もう1つ例を挙げると、2つの束のデカルト積を簡単に1つの束にすることができます。
instance (Lattice a, Lattice b) => Lattice (a,b) where
bot = (bot,bot)
top = (top,top)
(a1,b1) <: (a2,b2) = (a1 <: a2) ||
(a1 == a2 && b1 <: b2)
(a1,b1) `join` (a2,b2) = (a1 `join` a2, b1 `join` b2)
(a1,b1) `meet` (a2,b2) = (a1 `meet` a2, b1 `meet` b2) 束の演算、関係、そして元は、容易に”自然な形で”ほぼどんなデータ構造としても使うことができます。この結果、式 bot または関係 <: をコードのどこかで使った場合、Haskellはコンパイル時に、式の型(これも推論可能)に基づいてそれらの”適切な”意味を推論できます。
ML言語には型クラスの役割を演じるファンクタがありますが、Haskellの型クラスのような アドホック 多相のサポートはありません。MLやHaskellを使ったプログラミングにかなりの時間を費やしてきた経験からすると、表現に関する推論から実際に起こってくる問題は、いくら強調してもしすぎることはありません。
好きな特徴
参考資料
- haskell.org 。ダウンロード、ドキュメント、チュートリアルなど。
- The Glasgow Haskell Compiler(GHC) 。GHCは、Haskellを多様なプラットフォームで使うためのサポートが充実しています。
- Kathleen Fisherのスライド は、スタンフォード大学での講義向けに作成されたもので、Haskellの入門資料として有用。
- 『 Real World Haskell 』。書名に示されているように、この本はコンパイラやインタプリタ、プログラムアナライザに限らず、Haskellを実際のアプリケーション(例えばWebプログラミング)のために使うことに重点を置いています。

(邦訳書『 Real World Haskell―実戦で学ぶ関数型言語プログラミング 』)
Scala
Scala は、堅固で表現力に富んだ、Javaの厳密な上位互換言語です。私は、WebサーバやIRCクライアントを書くような時にScalaを使っています。オブジェクト指向システムを継ぎ足した関数型言語OCamlに比べると、Scalaはむしろ真のハイブリッドという感じです。すなわち、オブジェクト指向のプログラマは、関数型的な部分は必要なものだけ選びながらでも、すぐにScalaの使用を始めるべきです。
私は2006年のPOPLで Martin Odersky が行った招待講演で、Scalaのことを知りました。私は当時、関数型プログラミングがオブジェクト指向プログラミングの厳密な上位互換であると考えていたので、関数型プログラミングとオブジェクト指向プログラミングを融合させた言語の必要性を感じていませんでした(おそらく当時の私が、コンパイラやインタプリタ、静的アナライザばかり書いていたせいでしょう)。
私が初めてScalaの必要性を感じたのは、 yaplet (訳注:リンク切れ)向けのロングポーリングAJAXをサポートするために、並行HTTPDをゼロから書いた時でした。マルチコアサポートを実現するため、最初のバージョンはJavaで書きました。Javaはそれほど悪くないと思いますし、巧みに出来ているオブジェクト指向プログラミングの良さも経験しています。しかし、関数型プログラマとしては、関数型プログラミングの機能(高階関数など)が簡潔にサポートされていないことに不満を覚えたため、Scalaを試してみることにしました。
ScalaはJVM上で動くので、既存のプロジェクトを徐々にScalaへ移植することができました。また、Scalaにはかなり 大規模なライブラリ がありますが、それに加えてJavaの全ライブラリにもアクセスできるということですので、Scalaは実用的なプログラミングに使えるのです。
Scalaを使い始めてみると、関数型の世界とオブジェクト指向の世界が非常に緊密に連携していることに感動しました。特に、Scalaには強力なケースクラス/パターンマッチングシステムがありますが、これは私がStandard MLやOCaml、Haskellを使っていた時に経験した厄介な問題を解消してくれるものです。つまり、(必ず全フィールドにマッチしてしまうのではなく)プログラマがオブジェクトのどのフィールドをマッチ対象とするかを決めることができ、可変アリティの引数が認められているのです。それどころか、Scalaではプログラマ定義のパターンさえ使うことができます。
私は抽象構文ノード上に作用する関数をよく書きますが、アノテーションやソースコードの場所を無視して構文上の子だけにマッチさせることができるので、良いです。
ケースクラスシステムによって、代数的データ型の定義を複数ファイルまたは同一ファイルの複数パートに分割することができます。またScalaは、トレイトと呼ばれるクラスに似た構造体を通じて、明確に定義された多重継承もサポートしています。そして、Scalaでは演算子のオーバーロードが可能で、さらには関数適用やコレクション更新のオーバーロードもできます。これをうまく使うことで、私のScalaプログラムはより理解しやすく簡潔なものになっています。
Haskellで型クラスがコードの短縮に役立つのと同様、implicitの機能で多くのコードを省けることが分かりました。implicitは、型チェッカーのエラー修復フェーズに対するAPIであると考えることができます。簡単に言えば、型チェッカーがXを求めているのにYを得た場合、型チェッカーはスコープ内にimplicitと記述された、YをXに変換する関数があるか探します。見つかった場合、型チェッカーは自動的にそのimplicit関数を適用して型エラーを修復します。
implicitを使うと、限られたスコープに対して型の機能を拡張するのと似たようなことが可能になります。例えば、 escapeHTML() メソッドを型 String に “追加” したいとしましょう。 String の定義を変えることはできませんが、implicitを使うと、型チェックが myString.escapeHTML() でエラーになった場合に、 escapeHTML() メソッドをサポートする型に String オブジェクトを変換できるimplicit関数がスコープ内にあるか探すようにすることができます。
またimplicitによって、Scalaのリテラル( 3 や "while" など)をドメイン固有埋め込み言語(DSEL)のリテラルに透過的にマップできるようになるので、ScalaでDSELがより読みやすく記述できるようになります。
好きな特徴
- JVM のサポート
- インテリジェントな 演算子オーバーロード
- 広範なライブラリ
- ケースクラス/パターンマッチング
- 拡張性のあるパターンマッチング
- トレイトを通じた多重継承
- 豊富で柔軟性のあるオブジェクトコンストラクタ
- 暗黙の型変換
- 遅延評価を行うフィールドと引数
関連ブログ記事
- 少しずつ学ぶScala
- Scalaにおける遅延評価の例(ストリームを使用)
- ScalaによるOkasaki赤黒木
- Scalaでノンブロッキングレキサを書くためのDSEL
- コルーチンに基づいた、ScalaによるノンブロッキングWebサーバ
参考資料
- scala-lang.org 。ダウンロード、ドキュメント、チュートリアルなど。
- Martin Odersky(Scala創始者)、Lex Spoon、Bill Vennersの著書『 Programming in Scala 』(邦訳書『 Scalaスケーラブルプログラミング 』)は、入門書としても参考書としても優れています。
Standard MLとOCaml
ML系言語は、言語設計空間におけるスイートスポットです。厳格で、副作用があり、Hindley/Milner型推論を行うことを特徴としているからです。このためML系言語は、高性能 かつ 正確さをより強く保証することが必要な実際のプロジェクトに役立ちます。ML系言語は、航空宇宙エンジニア(バグのないコードのサポートが理由)や金融業界のプログラマ(同じ理由)の注目を集めています。Standard MLは私がじっくり学んだ最初の関数型言語だったので、その表現力に衝撃を受けたことはいまだに覚えています。
現在、勉強するMLとしてはOCamlが人気のようですが、SMLを支持すべき理由が少なくとも1つあります。 MLton です。MLtonは、関数型言語は最適化において格好の条件を備えているという主張を見事に実現しています。プログラム全体を最適化するコンパイラとして、これほど性能に優れたものは他に知りません。私は以前、3Dグラフィックを扱うためMLton向けにOpenGLのバインディングを作成したことがあるのですが、出来上がったプログラムは、参照用として使っていたC++ベースのモデルと比べて、コードはわずか10%の分量となり、実行速度が速くなりました。
SMLのファンクタシステムは、Haskellの型クラスシステムより冗長なものの、柔軟性は高くなっています。Haskellで種/型 k に対して型クラス T をいったんインスタンス化すると、その種/型に対してその型クラスを再びインスタンス化することはできません。しかしファンクタを使うと、各インスタンスは独自の名前を得られるので、同じ型に対して特定ファンクタのインスタンスを複数持つことができます。そのような表現力が必要になるケースはまれですが、必要になった場合には助かっています。
ML言語の別のモダンな方言OCamlは、大規模なコミュニティがあり多くのライブラリが利用できますので、知っていて損はありません。OCamlのツールチェーンも豊富で、インタプリタや最適化コンパイラ、バイトコードコンパイラが開発者に提供されています。
ML言語は、どの主流言語よりも表現力がありながら副作用を認めているので、Haskellを学ぶ途上で役に立つ言語です。Haskellでは、関数型のプログラム設計にまだ精通していないプログラマは、コーディングの際に、必要なモナドにアクセスできないという問題を繰り返し経験するかもしれません。一方MLでは、不完全な設計を修正するための”逃げ道”として副作用が認められていますので、プロジェクトが突如として「リファクタリングかアボートか」という予期せぬ決断に迫られるような事態を防ぐことができます。プログラムの開発が進むにつれて設計は必然的に変化するものですから、言語を評価する際に1つ有用な基準となるのは、ソフトウェアシステムにとって不適切な設計や不完全な設計に対しどれほど耐性があるかということでしょう。この点では、MLは依然としてHaskellより優位にあります。
好きな特徴
- Flex record(SMLのみ)
- パターンマッチング
- ストラクチャとファンクタ
参考資料
- smlnj.org と mlton.org 。SMLのダウンロード、ドキュメントとチュートリアル。
- caml.inria.fr 。OCamlのダウンロード、ドキュメントとチュートリアル。
- SMLとOCamlの比較表 。
- 『 ML for the Working Programmer(職業プログラマのためのML) 』は、SMLの優れた入門用および参照用テキストとして使えます。

これは私が学んだ本です。(Haskellを含む)ML系言語のプログラミングにおける思考プロセスの優れた入門書です。また、SMLライブラリでは提供されていない重要な関数型データ構造(木構造やマップ)を実装する方法も取り上げられています。
Scheme
Schemeは、純粋なコア(ラムダ計算とリスト理論)と表現の自由を最大化する設計要求を持つ言語です。型がないので、Webベースのプログラミングやラピッドプロトタイピングに最適です。Schemeは、Lispを継承しているので、人工知能にも大変向いています。
Schemeはまた、任意精度数値をサポートしているので、暗号アルゴリズムを実装する際は私の最初の選択肢でもあります(Schemeで実装した RSA および フェルマーとSolovay-Strassenの素数判定法 の短い例を、ご覧ください)。
Schemeを使用する圧倒的に大きな理由は、そのマクロシステムです。Schemeで利用可能なマクロシステムは、標準的な syntax-rules と syntax-case システムも含めて、全てチューリング等価です。
その結果、プログラマは、言語と目の前のタスクとの間のインピーダンスミスマッチを減らすためにSchemeを再構成することができます。一級継続のサポートと組み合わせると、(論理プログラミングのような)代替プログラミングパラダイムを埋め込むことさえ可能です。
例えば、次のようなコードを書くことができます。
(let ((x (amb 3 4 5))
(y (amb 6 7 8 )))
(assert (= (+ x y) 12))
(display x)
(display y))これは、直後の assert 文が真になるような正しい引数を”選択する” amb マクロです(このプログラムは、4と8を出力します)。
Schemeでは、計算のどの時点の間でも、プログラムはその時の継続をプロシージャとして保存することができます。このプロシージャを呼び出すと、プログラムは継続が保存された時に存在していた評価コンテキストに戻ります。継続を用いたプログラミングは、時間を行ったり来たりしたり、パラレルワールドを移動したりするような感じです。
結局のところ、Schemeは、機能を最小限に抑え拡張性を持たせた言語なので、あまり語ることはありません。ただし1つだけ言いたいのは、Schemeは、プログラマが組み込んでもいいと思っているどんな機能も、Scheme自身から導き出せるということです。
好きな特徴
関連ブログ記事
- Schemeで7行のプログラミング言語を実装する
- フラットなクロージャ変換でSchemeをCにコンパイルする
- Schemeを直接Javaへコンパイルする
- Meta-circular評価とファーストクラスマクロ
- 継続を用いたプログラミング
- Schemeによるチャーチエンコーディング
- マクロを定義するマクロによる高速でリフレクティブなベクトル構造体
- 導関数による正規表現マッチング
参考資料
- Racket (旧称PLT Scheme)は、”バッテリーが同梱された”Scheme処理系で、十分テストされたIDE、コンパイラやインタプリタなどが含まれています。さらに重要なことは、Racketライブラリは計り知れないということです。そのライブラリには、言語に型システムを追加するモジュール、パターンマッチングを追加するモジュール、OpenGLプログラミング用のモジュール、継続ベースのWebサーバ用のモジュールがあります。Racketには、まさにほとんど全てのモジュールが既にあります。
- 私が今までに見た中で最高のRacketに関する書籍は、『 Realm of Racket(Racketの世界) 』です。ゲームプログラミングを通して言語の機能が紹介されています。

- Chicken Scheme は、プログラマに分かりやすいSchemeの実装です。
- Gambit Scheme は、iPhoneやiPadプログラミングなど、Schemeの下位レベルのプログラミングで人気があります。
- R6RS 。現在のSchemeの標準です。
- 全てのSchemeプログラマに、 Guy Steele (訳注:リンク切れ)の『 Common LISP: The Language 』を1冊手元に置いておくようお勧めします。Guy Steeleは、プログラミング言語としてラムダ計算の最小限の表現であるSchemeを開発した後、プログラミング言語としてラムダ計算の最大限の表現であるCommon Lispを設計しました。

長年にわたって、Scheme用のマクロやライブラリとして多くのCommon Lispの機能が実装されてきました。私はSchemeの不足を見つけるたびに、Common Lispではどうしているかを確認し、Scheme用の即席バージョンを動かします。Common Lispオブジェクトシステム(CLOS)は、オブジェクト指向プログラミング言語設計の見事な例です。
・『 Structure and Interpretation of Computer Programs 』(邦訳書『 計算機プログラムの構造と解釈 』)は古典です。最近まで、これはMITの初級レベルのコンピュータサイエンスの教科書でした。これは、インタプリタを実装する方法を学生に教えることで、コンピュータサイエンスを教えています。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事