2017年12月5日
ディープラーニングにおけるセマンティックセグメンテーションのガイド2017年版
本記事は、原著者�の許諾のもとに翻訳・掲載しております。
Qureでは、私たちは通常、セグメンテーションとオブジェクト検出の問題に取り組んでいます。そのため、最先端技術の動向について検討することに関心があります。
本稿では、セマンティックセグメンテーションに関する論文を検討します。セマンティックセグメンテーションの研究の多くは、自然界・現実世界の画像データセットを使用します。その結果を医療用画像に直接適用できるわけではありませんが、現実世界の画像に関する研究は医療用画像のものよりもずっと成熟しているので、これらの論文を見直してみたいと思います。
本稿は、以下のような構成です。最初に セマンティックセグメンテーションの問題を説明 し、 アプローチ方法に関する概略 を述べます。最後に いくつかの興味深い論文を要約します。
今後の記事で、医療用画像が現実世界の画像となぜ異なるのかを説明する予定です。更に、今回の再検討から得たアプローチが、医療用画像の代表的なデータセットに対してどの程度効果があるのか検証したいと思います。
セマンティックセグメンテーションとは一体何か。
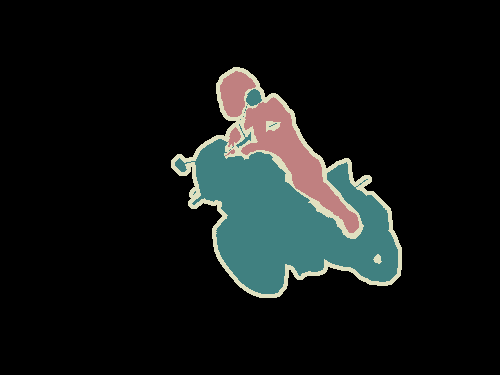
セマンティックセグメンテーションとは、画像を画素レベルで把握することです。つまり、画像内の各画素をオブジェクトクラスに割り当てようとすることです。例を挙げましょう。以下の画像を見てください。

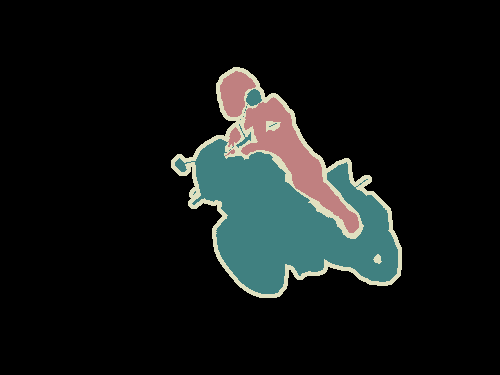
Left : Input image. Right : It’s semantic segmentation. Source.
左: 入力画像。 右: これがセマンティックセグメンテーションです。 出典
オートバイと、それに乗車している人物を分けて識別し、更に各オブジェクトの境界を示す輪郭線を描く必要があります。そのため、クラス分類とは異なり、モデルから画素単位の高密度な予測をしなくてはなりません。
VOC2012 と MSCOCO は、セマンティックセグメンテーションにおいて最も重要なデータセットです。
他にはどのようなアプローチがあるのか。
ディープラーニングがコンピュータビジョンを引き受ける以前は、セマンティックセグメンテーションの際には テクストンフォレスト や ランダムフォレストに基づく分類器 のようなものを使用していました。画像の分類と同様に、畳み込みニューラルネットワーク(CNN)はセグメンテーションに関する課題に多くの成果を収めてきました。
初期のディープラーニングの一般的なアプローチの1つに、 パッチ分類 があります。これは、周囲の画像を用いて各画素が各クラスに個別に分類されるものです。パッチを使う主な理由は、通常、分類ネットワークには全結合層があるので、固定サイズの画像が必要だからです。
バークレーのLongらによる、2014年の論文、 全層畳み込みネットワーク(FCN) により、高密度な予測のために、全結合層を使わないCNNアーキテクチャが普及しました。これにより、あらゆるサイズの画像でセグメンテーションマップが生成できるようになりました。更に、パッチ分類アプローチに比べて処理が非常に高速です。それ以降、セマンティックセグメンテーションに対するほぼ全ての最先端のアプローチは、このパラダイムを取り入れました。
全結合層以外にも、セグメンテーションのためにCNNを使う際の主要な問題の1つに、 プーリング層 があります。プーリング層によって視野が増大し、コンテキストを集約することができますが、”位置”情報は破棄されます。しかし、セマンティックセグメンテーションは正確なクラスマップの配置を必要とするので、”位置”情報の保存が必要になります。この問題に取り組むため、論文では、2つの異なるアーキテクチャのクラスが進化を遂げました。
1つ目は、エンコーダ・デコーダアーキテクチャです。エンコーダはプーリング層を用いて空間的な次元を徐々に減少させます。デコーダはオブジェクトの詳細と空間的な次元を徐々に復元します。通常、デコーダがオブジェクトの詳細を復元しやすくするような、エンコーダからデコーダへのショートカット接続があります。 U-Net はこのクラスの一般的なアーキテクチャです。
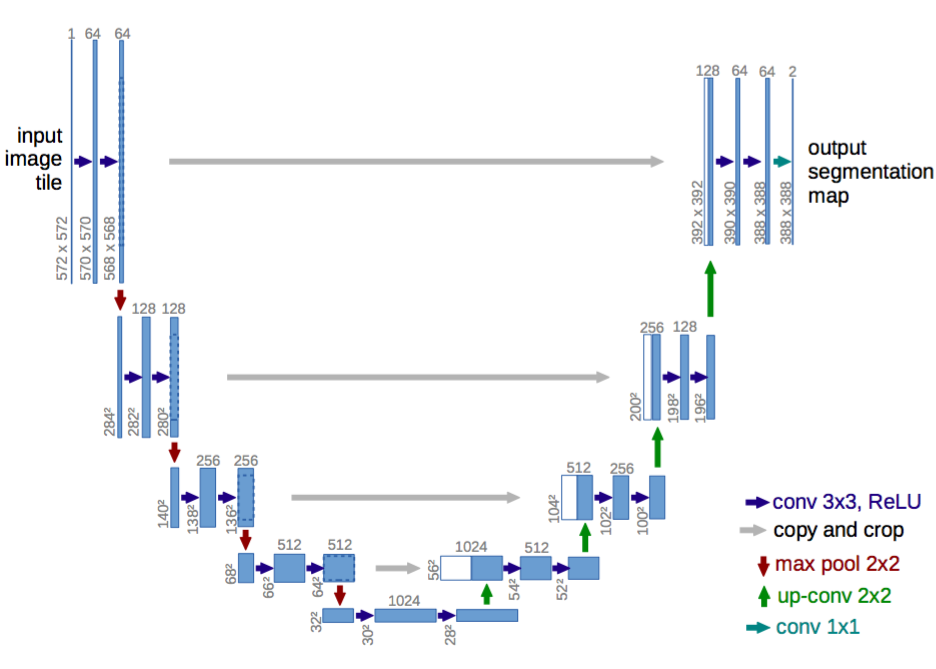
U-Net:エンコーダ・デコーダアーキテクチャ。 出典
2つ目のクラスのアーキテクチャが使用しているのは Dilated/Atrous畳み込み と呼ばれるもので、プーリング層を使用しません。
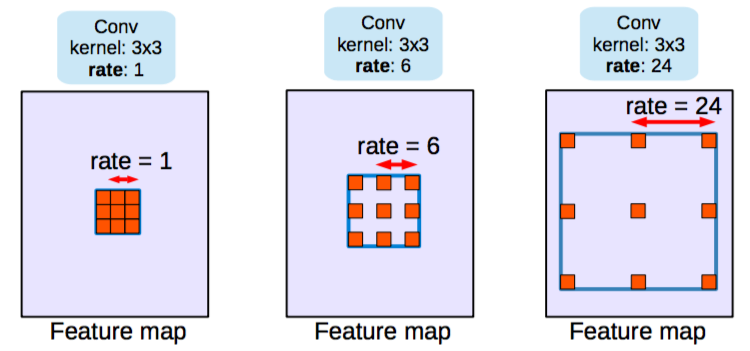
Dilated/Atrous畳み込み。比率=1は通常の畳み込みと同じ。 出典
条件付き確率場(CRF)後処理 は、通常、セグメンテーションを改善するために用いられます。CRFはグラフィカルモデルであり、その”円滑な”セグメンテーションは、下層の画像の明度に基づいています。明度の似た画素は、同じクラスにラベル付けされる傾向があるという観察に基づいて処理を行います。CRFによってスコアは1%から2%高くなります。
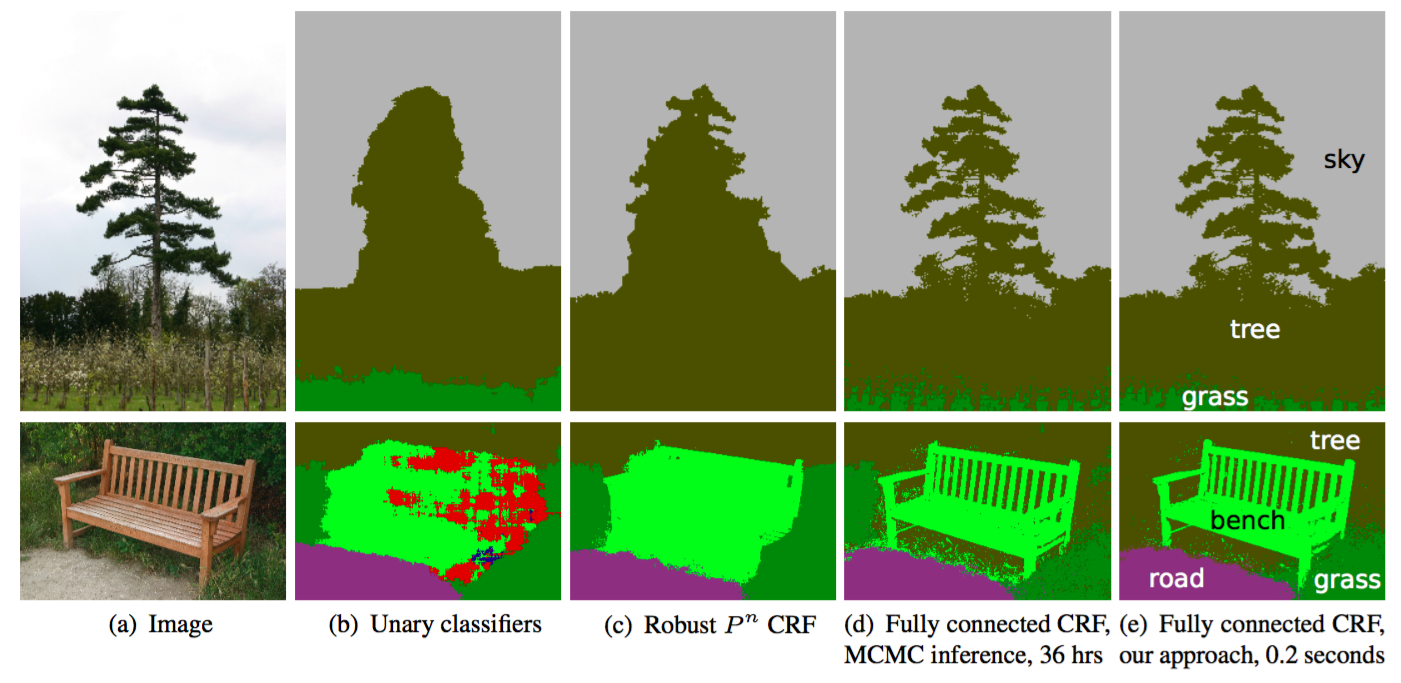
CRFのイラスト。(b)の単項の分類器は、CRFへ入力するセグメンテーションです。(c、d、e)はCRFの変型で、(e)はそれを広範囲に用いたものです。 出典
次のセクションでは、セグメンテーションのアーキテクチャの進化を代表する、いくつかの論文を要約します。最初に取り上げるのはFCNです。これら全てのアーキテクチャについて、 VOC2012評価サーバ によってベンチマークを行いました。
要約
以下の論文を要約しています(年代順)。
各文献について、重要事項を一覧にして解説しています。また、VOC2012テストデータセットにおけるベンチマークのスコア(Mean IoU)を掲載しています。
FCN(全層畳み込みネットワーク)
セマンティックセグメンテーションのための全層畳み込みネットワーク
2014年11月14日提出
ArXivのリンク
重要事項:
-
エンドツーエンドの畳み込みネットワークをセマンティックセグメンテーションに使用することを普及させた。
-
セグメンテーションのために、事前学習済みネットワークのイメージネットを別な目的で使用する。
-
逆畳み込み 層を用いたアップサンプリング。
-
アップサンプリングした対象のきめの粗さを改善する、スキップ接続の導入。
解説:
この論文における重要な観察結果は、分類ネットワークにおける全結合層を、カーネルを用いて畳み込みとして見ることができ、これが入力領域の全体をカバーするものであるということです。これは重なり合う入力パッチに基づいて本来の分類ネットワークを評価するのと同等ですが、パッチの重なり合う領域で計算が共有されるため、ずっと効率的です。こうした観察結果は当論文に特有なものではありませんが(
overfeat や この記事 をご覧ください)、VOC2012に関する最先端の技術を著しく向上させるものでした。
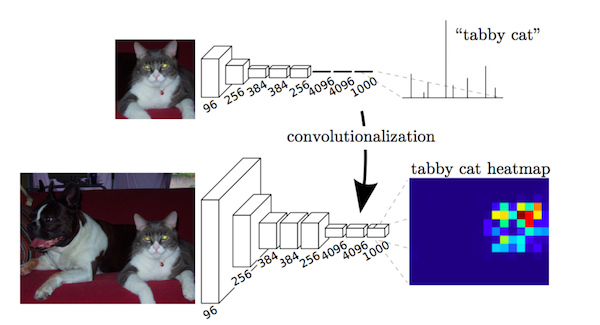
畳み込みとしての全結合層。 出典
VGGのように、事前学習済みネットワークのイメージネットで全結合層を畳み込みした後でも、CNNのプーリング処理のために特徴マップのアップサンプリングが必要です。単純なバイリニア補間を用いるのではなく、 逆畳み込み層 が補間を学習します。この層は、upconvolution、full convolution(全畳み込み)、transposed convolution(転置畳み込み)、fractionally-strided convolutionとしても知られています。
しかし、アップサンプリングは(たとえ逆畳み込み層を用いたとしても)、プーリング中の情報ロスのために、粗いセグメンテーションマップを生成します。そのため、ショートカット/スキップ接続は、高解像度の特徴マップから導入されています。
ベンチマーク(VOC2012):
| スコア | Comment | 出展 |
|---|---|---|
| 62.2 | – | スコアボード |
| 67.2 | より勢いがある。論文では触れられていない。 | スコアボード |
私のコメント:
- これは重要な貢献をしましたが、現在では、最先端技術は更に向上しました。
SegNet
SegNet:画像セグメンテーションのための深層畳み込みエンコーダ・デコーダアーキテクチャ
2015年11月2日提出
ArXivのリンク
重要事項:
- セグメンテーションの解像度を上げるために、maxpoolingインデックスがデコーダへ転移される。
解説:
FCNは、逆畳み込み層と、いくつかのショートカット接続であるにもかかわらず、粗いセグメンテーションマップを生成します。そのため、より多くのショートカット接続が導入されています。しかし、FCNのように、エンコーダの特徴をコピーするのではなく、maxpoolingからインデックスがコピーされます。これにより、SegNetはFCNよりメモリが効率的になります。
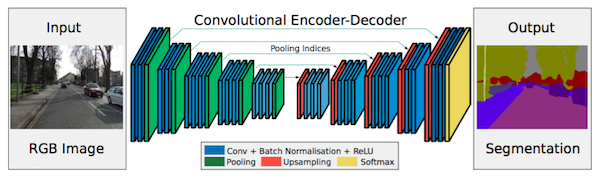
SegNetのアーキテクチャ。 出典
ベンチマーク(VOC2012):
| スコア | コメント | 出展 |
|---|---|---|
| 59.9 | – | スコアボード |
私のコメント:
-
FCNとSegNetは、初期のエンコーダ・デコーダアーキテクチャの1つです。
-
SegNetのベンチマークは、今はもう使用するには十分なスコアとは言えません。
Dilated畳み込み
Dilated畳み込みによるマルチスケールのコンテキスト集約
2015年11月23日提出
ArXivのリンク
重要事項:
-
Dilated畳み込みの使用と、高密度の予測のための畳み込み層。
-
マルチスケールな集約のためにDilated畳み込みを用いる”コンテキストモジュール”を提案。
解説:
プーリングは、分類ネットワークにおいて受容野が増えるので、役立ちます。しかし、プーリングは解像度を下げてしまうので、セグメンテーションにとって最適とは言えません。そうした理由から、著者は、以下のような処理を行う Dilated畳み込み 層を用います。
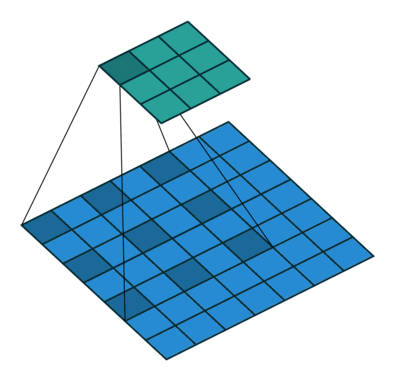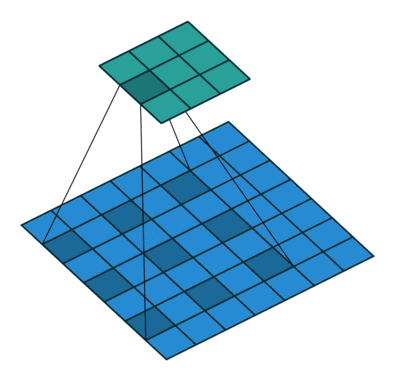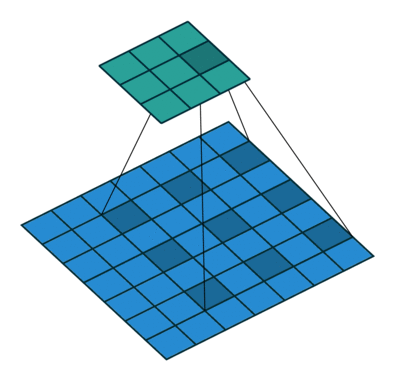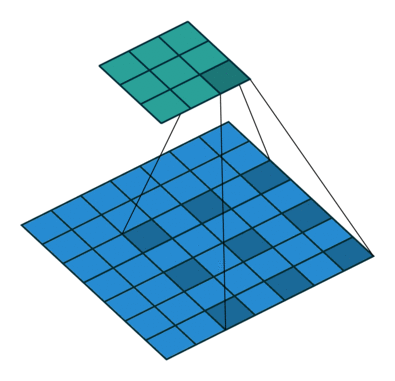
Dilated/Atrous畳み込み。 出典
Dilated畳み込み層( DeepLab ではAtrous畳み込みとも呼ばれています)を使うと、空間的な次元を減らすことなく、視野を指数関数的に増大することができます。
事前学習済みの分類ネットワーク(ここではVGG)の最後の2つのプーリング層は取り除かれ、それに続く畳み込み層がDilated畳み込みに置き換えられます。特に、プール3とプール4の間の畳みこみはdilationが2で、プール4以後の畳み込みはdilationが4です。このモジュールにより(論文では フロントエンドモジュール と呼ばれています)、パラメータの数を増やすことなく、高密度の予測が可能になります。
モジュール(論文では コンテキストモジュール と呼ばれています)は別途、フロントエンドモジュールの出力を入力値として学習されます。このモジュールは、様々なdilationのDilated畳み込みが連鎖したものなので、マルチスケールなコンテキストが集約され、フロントエンドの予測が改善されます。
ベンチ―マーク(VOC2012):
| スコア | コメント | 出展 |
|---|---|---|
| 71.3 | フロントエンド | 論文中に記載 |
| 73.5 | フロントエンド+コンテキスト | 論文中に記載 |
| 74.7 | フロントエンド+コンテキスト+CRF | 論文中に記載 |
| 75.3 | フロントエンド+コンテキスト+CRF-RNN | 論文中に記載 |
私のコメント:
- 予測されたセグメンテーションマップのサイズは画像の8分の1であることに留意してください。ほとんど全てのアプローチでこのケースとなります。これらは、最終的なセグメンテーションマップを取得するために補間されます。
DeepLab (v1とv2)
v1: 深層畳み込みネットと完全接続CRFを用いた画像のセマンティックセグメンテーション
2014年12月提出
ArXivのリンク
v2: DeepLab:深層畳み込みネット、Atrous畳み込み、完全接続CRFを用いた画像のセマンティックセグメンテーション
2016年6月2日提出
ArXivのリンク
重要事項:
-
Atrous/Dilated畳み込みの使用。
-
atrous空間ピラミッド型プーリング(ASPP)の提案。
-
完全接続CRFの使用。
解説:
Atrous/Dilated畳み込みによって、パラメータの数を増やすことなく視野は増大します。ネットは、 Dilated畳み込みの論文 のように改変されます。
マルチスケール処理は、元の画像の多重拡大縮小版を並列CNNブランチに渡すこと(イメージピラミッド)によって行われます。そして(または)、様々なサンプリングレートを用いた多重並列Atrous畳み込み層によっても行われます(ASPP)。
構造化予測は、完全接続CRFによって行われます。処理の前段階で別途、CRFは事前学習が済み、調整されています。
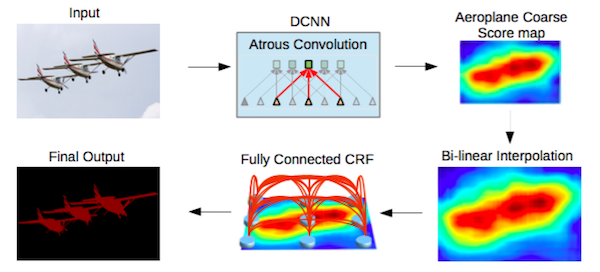
*注釈:(矢印の順番に)
入力
DCNN
飛行機の荒いスコアマップ
バイリニア補間
完全接続CRF
最終的出力結果
*
DeepLab2パイプライン。 出典
ベンチマーク(VOC2012):
| スコア | コメント | 出展 |
|---|---|---|
| 79.7 | ResNet-101+Atrous畳み込み+ASPP+CRF | スコアボード |
RefineNet
RefineNet:高解像度なセマンティックセグメンテーションのためにマルチパスに改良したネットワーク
2016年11月20日提出
ArXivのリンク
重要事項:
-
考え抜かれたデコーダブロックを用いたエンコーダ・デコーダアーキテクチャ
-
全てのコンポーネントが残差接続型の設計に従う
解説:
Dilated/Atrous畳み込みを使用するという手法は、欠点がないというわけではありません。Dilated畳み込みは、数多くの高解像度の特徴マップを利用しなければならないので、計算量が多く、多くのメモリを必要とします。このことが、高解像度の予測の計算の邪魔になります。 DeepLab の予測は、例えば元の入力の1/8の大きさになります。
そこで、この論文はエンコーダ・デコーダアーキテクチャの使用を提案しています。エンコーダ部分にはResNet-101ブロックを、デコーダ部分にはRefineNetブロックを使います。RefineNetブロックはエンコーダからの高解像度の特徴と前のRefineNetブロックからの低解像度の特徴とを、連結したり融合したりするものです。
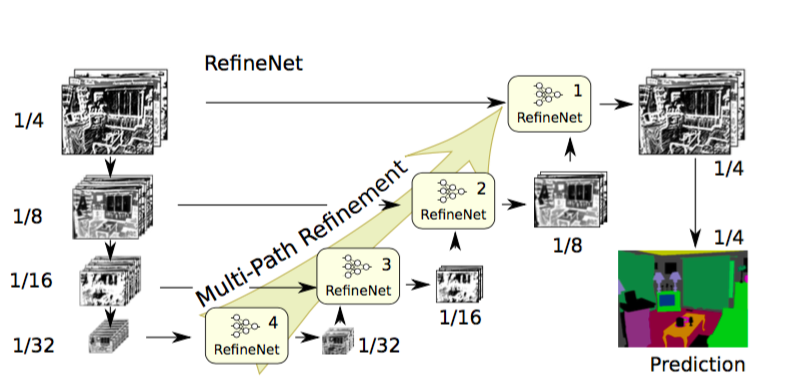
RefineNetアーキテクチャ。 出典
それぞれのRefineNetブロックは、低解像度の特徴をアップサンプリングすることにより複数の解像度の特徴を融合させる構成要素と、何回か繰り返される5 x 5でstride 1のプーリング層に基づくコンテキストをキャプチャするコンポーネントを持っています。これらのコンポーネントはそれぞれ、下のようなアイデンティマップのマインドセットに続く残差接続の設計を採用しています。
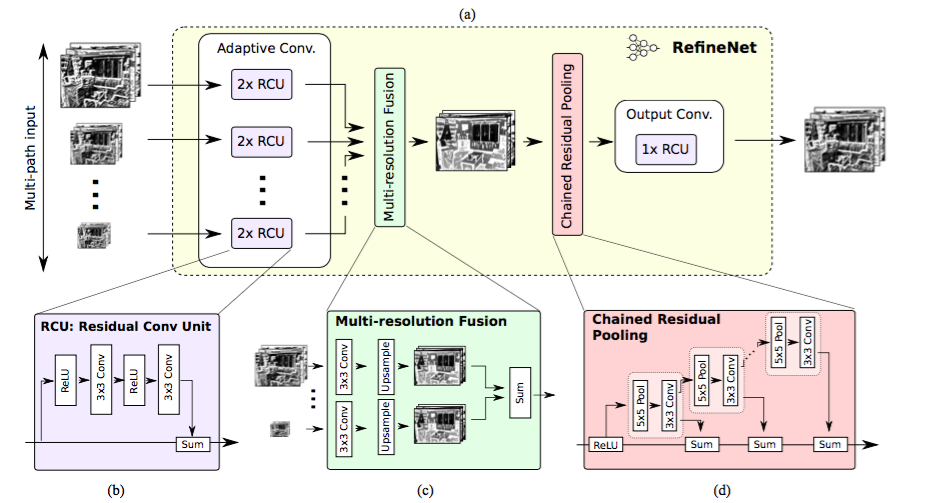
RefineNetブロック。 出典
ベンチマーク(VOC2012)
| スコア | コメント | 出展 |
|---|---|---|
| 84.2 | CRF使用、マルチスケール入力、COCO事前学習 | スコアボード |
PSPNet
Pyramid Scene Parsing Network
2016年12月4日提出
arXivのリンク
主要事項:
-
コンテキストを集約するためにピラミッド型プーリングモジュールを提案。
-
補助的ロスの使用。
解説:
グローバルシーンカテゴリは、セグメンテーションクラスの分配の情報を与えてくれるので重要です。ピラミッド型プーリングモジュールは、大規模カーネルのプーリング層を用いることにより、この情報をキャプチャします。
Dilated畳み込みは、ResNetを変更するために Dilated畳み込みの論文 の中と同じように使われており、そこにピラミッド型プーリングモジュールが追加されています。このモジュールは、画像の全て、半分、小さな部分をカバーするカーネルを使って、ResNetからの特徴マップと並列プーリング層のアップサンプリングされた出力とを連結します。
補助的ロスは、メインブランチに付加されるロスのことで、ResNetの第4ステージ後に適用されます(つまり、ピラミッド型プーリングモジュールへの入力のこと)。この考え方は、他の所では中間の監視とも呼ばれています。
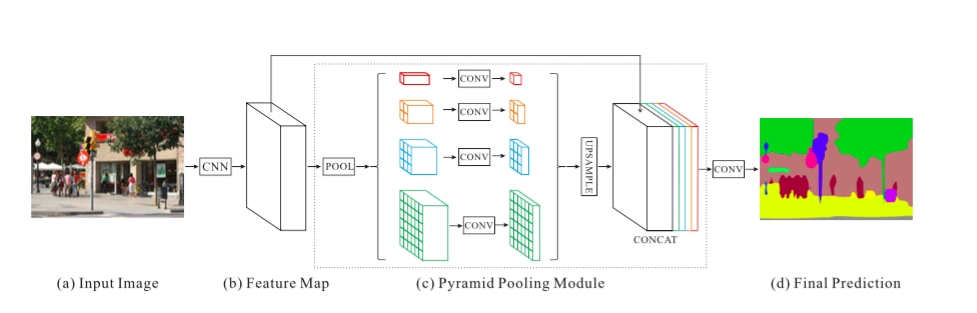
PSPNetアーキテクチャ。 出典
ベンチマーク(VOC2012)
| スコア | コメント | 出展 |
|---|---|---|
| 85.4 | MSCOCO事前学習、マルチスケール入力、CRFなし | スコアボード |
| 82.6 | MSCOCO事前学習なし、マルチスケール入力、CRFなし | 論文中に記載 |
Large Kernel Matters
Large Kernel Matters、グローバル畳み込みネットワークによるセマンティックセグメンテーションの改善
2017年3月8日提出
arXivのリンク
主要事項:
- 大規模カーネルの畳み込みを有する、エンコーダ・デコーダアーキテクチャを提案。
解説:
セマンティックセグメンテーションではセグメント化されたオブジェクトのセグメンテーションとクラス分類の両方が必要です。全結合層はセグメンテーションアーキテクチャに存在することはできないので、代わりに大規模カーネルの畳み込みが用いられます。
大規模カーネルを採用する別の理由は、ResNetのようなより深いネットワークはとても大きな受容野を持っているからです。 研究 によるとネットワークはずっと小さい範囲から情報を集める傾向があるということが分かっています(有効受容野)。
大規模カーネルは計算量が多く、パラメータがたくさんあります。その結果k x k畳み込みは、1 x k + k x 1とk x 1と1 x k畳み込みの和に近いものになります。このモジュールは論文中で、 Global Convolutional Network (GCN、グローバル畳み込みネットワーク)と呼ばれています。
アーキテクチャということになると、(いかなるDilated畳み込みも用いない)ResNetはアーキテクチャのエンコーダ部分を形成し、一方、GCNと逆畳み込みはデコーダ部分を形成します。*Boundary Refinement *(BR)と呼ばれている簡単な残余ブロックも使用されています。
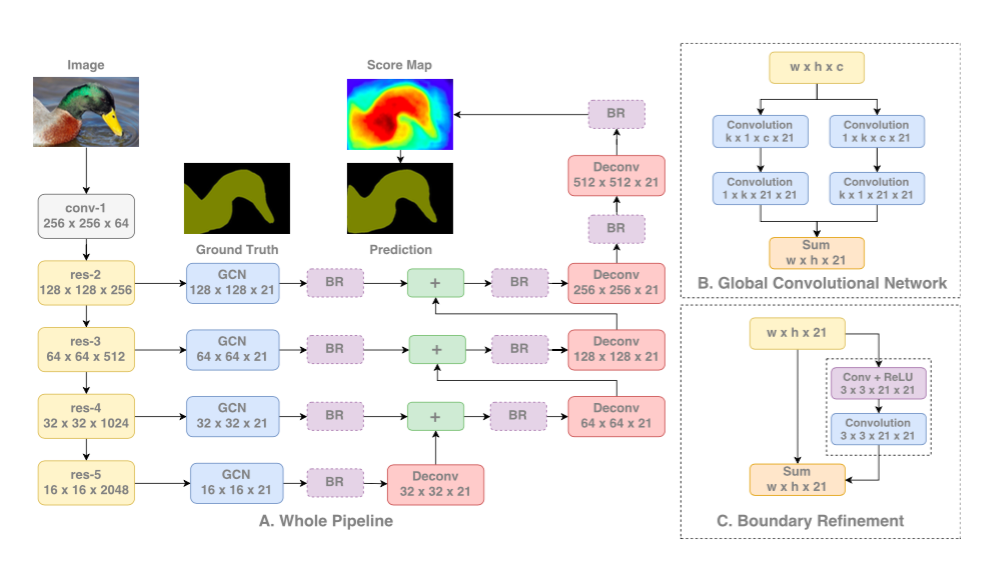
GCNアーキテクチャ。 出典
ベンチマーク(VOC2012)
| スコア | コメント | 出展 |
|---|---|---|
| 82.2 | – | 論文中に記載 |
| 83.6 | 改善された学習、論文で説明なし | スコアボード |
DeepLab v3
セマンティック画像セグメンテーショのためのAtrous畳み込みの再考
2017年6月17日提出
arXivのリンク
主要事項:
-
改善型atrous空間ピラミッド型プーリング(ASPP)。
-
連鎖したAtrous畳み込みを採用するモジュール。
解説:
ResNetモデルは DeepLabv2 と Dilated畳み込み のように、Dilated/Atrous畳み込みを使うように変更されています。改善型ASPPはイメージレベルの特徴と1つの1×1の畳み込み、3つの異なる比率の3×3のAtrous畳み込みの連結を含みます。各並列畳み込み層の後で、バッチの正規化が使われます。
コンポーネントの畳み込み層がさまざまな比率のAtrousで作成されているということを除けば、カスケードモジュールはResNetブロックです。このモジュールは Dilated畳み込みの論文 で用いられているコンテキストモジュールとよく似ています。しかし、これはビリーフマップの代わりに中間特徴マップ上で直接用いられます(ビリーフマップはクラス数と同じチャネルを持つ最終的なCNN特徴マップです)。
提案されたモデルのどちらも個々に評価され、両者を組み合わせようとしても、パフォーマンスは改善しませんでした。両方ともVALセット上で、とてもよく似た動きをしていましたが、ASPPの方が少し優れています。CRFは使われていません。
このモデルのどちらも、 DeepLabv2 の中の最良のモデルよりも優れています。著者はバッチ正規化とマルチスケールコンテキストのエンコードのよりよい方法で改善できたことに着目しています。
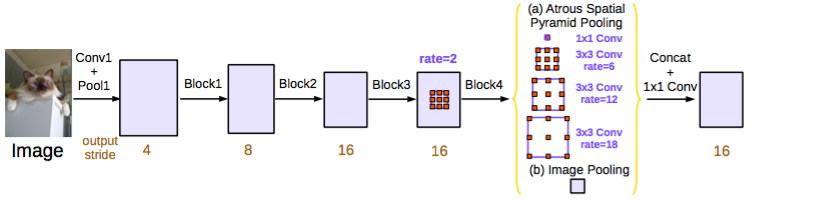
DeepLabv3 ASPP(提案として使用されたもの)。 出典
(VOC2012)
| スコア | コメント | 出展 |
|---|---|---|
| 85.7 | ASPPを使用 (カスケードモデルなし) | スコアボード |

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事