2016年7月27日
勾配降下法の最適化アルゴリズムを概観する
本記事は、原著者の許諾のもとに翻訳・掲載しております。

(編注:2020/10/01、2016/07/29、いただいたフィードバックをもとに記事を修正いたしました。)
目次:
勾配降下法は、最適化のための最も知られたアルゴリズムの1つです。これまではニューラルネットワークを最適化するのに最も一般的な方法でした。また、最新のディープラーニングライブラリでは、どれも勾配降下法を最適化するさまざまなアルゴリズムの実装を含んでいます(例: lasagne 、 caffe 、 keras のドキュメンテーション)。ですが、こういったアルゴリズムは、その長所と短所の実質的な説明が入手しづらい、仕組みが分からないブラックボックスな最適化手法としてしばしば用いられてきました。
このブログの投稿では、実際にアルゴリズムを実行する際の助けとなるよう、勾配降下法を最適化する異なったアルゴリズムの動作についての洞察をしてみたいと思います。まずざっと異なるさまざまな勾配降下法を見ていきます。その後、簡単に訓練における課題について要約します。それから、これらの一般的な最適化アルゴリズムが、どのように課題を解決しようとしているのか、どのように更新規則を導き出しているのかを解説しながら紹介していきたいと思います。また、並列化・分散化された状況での勾配降下法の最適化のためのアルゴリズムとアーキテクチャについて少し触れます。最後に、勾配降下法の最適化について有効と思われる更なる戦略について考えていきます。
勾配降下法は、モデルのパラメータ\(\theta \in \mathbb{R}^d \)によってパラメータ化される目的関数\(J(\theta)\)を最小化するための方法であり、目的関数の勾配方向\(\nabla_\theta J(\theta)\)の逆方向にパラメータを更新することによって実現されます。学習率\(\eta\)は、(局所的)最小値に達するために、どれだけ大きなステップをとるかを決定します。言い換えれば、「目的関数によって作られる表面があるとする。これの谷間に到達するまで、表面の傾斜の下る方向に従って移動する」ということになります。もし勾配降下法になじみがない場合は、 ここ に、ニューラルネットワークの最適化に関する優れた入門編があります。
さまざまな勾配降下法
勾配降下法には3種類あります。その違いは目的関数の勾配を計算するのに使うデータ量によります。パラメータの更新の正確性と更新にかかる時間の兼ね合いをどう図るかは、データ量によります。
バッチ勾配降下法
ただの勾配降下法(別名:バッチ勾配降下法)は、トレーニングデータセット全体に対するパラメータ(\theta)について、コスト関数の勾配を計算します。
\(\theta = \theta – \eta \cdot \nabla_\theta J( \theta)\).
たった 1回 の更新を行うのにも全データセットに対して勾配を計算する必要があるので、バッチ勾配降下法はとても処理速度が遅く、メモリに収まらないデータセットに対して処理はできません。またバッチ勾配降下法は オンライン での更新、つまり新しい例を得ながらモデルを更新することができません。
コードにすると、バッチ勾配降下法は以下のようになります。
for i in range(nb_epochs):
params_grad = evaluate_gradient(loss_function, data, params)
params = params - learning_rate * params_gradあらかじめ定義されたエポック数だけ、最初に、パラメータベクトルである params に関する全データセットの損失関数の勾配ベクトル weights_grad を計算します。最新のディープラーニングライブラリでは、幾つかのパラメータに関する勾配を効率的に計算する自動微分が提供されていることを覚えておきましょう。もし、勾配を自分で計算する、勾配をチェックするのが望ましいでしょう(勾配の適切なチェック法のコツについては ここ を参照してください)。
それから、どれぐらいの規模で更新を行うかを決定する学習率を用いて、勾配方向にパラメータを更新します。バッチ勾配降下法は凸面の誤差に対して大域解に、非凸面に対し局所解に収束することを保証します。
確率的勾配降下法
確率的勾配降下法(SGD)は対照的に、 それぞれの 訓練例\(x^{(i)}\)とラベル\(y^{(i)}\)に対してパラメータの更新を行います。
\(\theta = \theta – \eta \cdot \nabla_\theta J( \theta; x^{(i)}; y^{(i)})\)
バッチ勾配降下法は大きなデータに対して冗長な計算を行います。というのも各パラメータの更新の前に類似の例の勾配を再計算するからです。SGDは1度につき1回の更新を行い、こうした冗長性を排除しました。それにより、通常はより処理速度が速く、オンラインでの学習でも使えます。
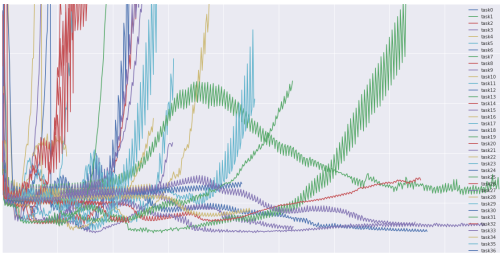
また、SGDは頻繁に更新を行いますが、図1のように目的関数を激しく変動させる高い可動性があります。

図1:SGDの変動(出典元: Wikipedia )
バッチ勾配降下法においてパラメータは設定された谷間の極小値へ収束しますが。その一方で、SGDではその変動によって、新たな、より適切な可能性のある局所解へ素早く移動することができます。しかしSGDでは、それを過剰に行い続けてしまうため、最終的には正確な極小値への収束が難しくなります。しかし、徐々に学習率を下げるようにすると、SGDはバッチ勾配降下法と同様の収束挙動を示していました。そしてほぼ確実に、それぞれ非凸最適化と凸最適化のための局所解か大域解へ収束します。
コード上では、単に訓練例に対してループを追加し、各例について勾配を評価するだけです。 このセクション で説明したように、エポック毎に訓練データをシャッフルすることに留意してください。
for i in range(nb_epochs):
np.random.shuffle(data)
for example in data:
params_grad = evaluate_gradient(loss_function, example, params)
params = params - learning_rate * params_gradミニバッチ勾配降下法
ミニバッチ勾配降下法では、最終的に両者の最良の部分を取って、\(n\)個の訓練例のミニバッチ毎に更新します。
\(\theta = \theta – \eta \cdot \nabla_\theta J( \theta; x^{(i:i+n)}; y^{(i:i+n)})\)
このように、 a) パラメータ更新の分散を減らし、より安定した収束へ導きます。そして、 b) ミニバッチに関する勾配の計算を効果的に行う、高度に最適化された行列最適化を活用することができます。これは最新のディープラーニングのライブラリには一般的なものです。一般的なミニバッチのサイズは50から256の範囲ですが、アプリケーションによって異なります。ミニバッチ勾配降下法は、ニューラルネットワークを訓練する際に選択される典型的なアルゴリズムです。そして通常、ミニバッチが使われる際にも、SGDという用語が用いられます。注意事項:この後本稿で触れるSGDの変更では、簡略化のため、パラメータ\(x^{(i:i+n)}; y^{(i:i+n)}\)を省略します。
コード上では、訓練例を何度も反復するのではなく、サイズ50のミニバッチを反復します。
for i in range(nb_epochs):
np.random.shuffle(data)
for batch in get_batches(data, batch_size=50):
params_grad = evaluate_gradient(loss_function, batch, params)
params = params - learning_rate * params_grad課題
通常のミニバッチ勾配降下法は、適切な収束を保証するものではありませんが、取り組むべき課題を幾つか与えてくれます。
-
適切な学習率の選択は難しいものです。学習率が小さ過ぎると、収束が非常に遅くなります。反対に大き過ぎると収束を妨げ、損失関数が極小値周辺で変動するようになったり、発散を引き起こしたりすることさえあります。
-
学習率のスケジュール ^(1) は、訓練中に学習率を調整しようとします。例えば、焼きなまし法、つまり、事前に決めたスケジュールに従って学習率を減らす場合や、エポック間での目的関数の変動が閾値以下に落ち込んだ場合などです。しかしこうしたスケジュールや閾値は、事前に決めておかなければならない上に、データセットの特性には適応できません ^(2) 。
-
更に、全てのパラメータ更新に同じ学習率を適用します。もしデータがスパースで、特徴の頻度がかなり異なる場合、全てを同程度まで更新したいとは思わず、あまり起こらない特徴のために、より大きな更新をしたいかもしれません。
-
ニューラルネットワークで一般的な、高度に非凸な誤差関数を最小化する上での、もう1つの鍵となる課題は、膨大な準最適の局所解に捕らわれるのを避けることです。Dauphinら ^(3) は、実際には局所解ではなく鞍点から問題が発生すると主張しています。鞍点とは、ある次元の勾配が上がる一方、別の勾配が下がる点のことです。これらの鞍点は通常、誤差が等しいグラフの平坦地帯に囲まれています。そのため、勾配が全ての次元においてゼロへ近づくにつれ、SGDはこの状況を回避することが非常に難しくなることが知られています。
勾配降下法の最適化アルゴリズム
これから、上述の課題を扱う幾つかのアルゴリズムについて概要を説明します。これらはディープラーニングのコミュニティで幅広く使われているものです。ここでは、高次元のデータセットを扱う上で実際には計算が不可能なアルゴリズム、例えば ニュートン法 のような二次的な方法については検討しません。
Momentum(慣性)
SGDには谷間をナビゲートする上で問題があります。谷間とはつまり、表面がカーブしているエリアのことで、ある次元では他の次元よりカーブがもっと急峻になっています ^(4) 。これは、局所的最適の周辺ではよくあることです。このようなシナリオでは、図2のように局所的最適に向かう谷底周辺ではSDGが遅々として進まず、SGDは谷間の傾斜を横切って行ったり来たりしています。
 |
 |
Momentum ^(5) とは、図3のように、関連性のある方向へSGDを加速させ振動を抑制する方法です。現在の更新ベクトルに、過去のタイムステップの更新ベクトルを\(\gamma\)の割合だけ加えることにより実現します。
\(v_t = \gamma v_{t-1} + \eta \nabla_\theta J( \theta)\)
\(\theta = \theta – v_t\)
注意事項:実装では、方程式の記号を置き換える場合があります。Momentumの項である\(\gamma\)には通常、0.9程度の値がセットされます。
基本的にMomentumを使う場合は、ボールを丘から転がします。ボールは丘を転がり落ちる際にMomentumを累積し、途中で加速して行きます(空気抵抗があれば、終速度に至るまで加速します。「空気抵抗がある」とは、つまり\(\gamma \< 1\)ということです)。同様のことがパラメータの更新でも起こります。つまり、Momentumの項は勾配が同じ方向に向いている次元に向けて増加します。そして、勾配が方向を変える次元に向けての更新を減少させます。結果的に収束が早まり、振動を抑制することができます。
Nesterovの加速勾配降下法
しかし丘を転がり落ちるボールは、斜面のなすがままになっているので、非常に不十分な状態と言えます。どこに向かっているのか分かる賢いボールなら、丘の斜面が再び上り坂になる前に速度を落とすことができます。
Nesterov accelerated gradient(NAG) ^(6) は、Momentumの項に対し、こういった予測ができる能力を与える方法です。パラメータ\(\theta\)を動かすために、Momentum項\(\gamma v_{t-1}\)を使いますね。そのため、\( \theta – \gamma v_{t-1} \)を計算すると、次のパラメータの位置の近似値(完全な更新には勾配が欠けています)が分かります。パラメータがどこへ向かうのか、おおよそのことが分かります。現在のパラメータ\(\theta\)に関する勾配を計算するのではなく、未来のパラメータの推定位置を計算することで、効果的に予測することができます。
\(v_t = \gamma v_{t-1} + \eta \nabla_\theta J( \theta – \gamma v_{t-1} )\)
\(\theta = \theta – v_t\)
もう一度、Momentum項\(\gamma\)の値を約0.9にセットします。Momentumが現在の勾配(図4の小さな青色のベクトル)を最初に計算し、更新された累積勾配(大きな青色のベクトル)の方向に大きく移動する間に、まずNAGは前の累積の勾配(茶色のベクトル)の方向に大きく移動し、勾配を計測し、訂正します(緑色のベクトル)。この先行の更新は速く進み過すぎるのを防ぎ、反応性を向上します。これにより、幾つかのタスクに関してRNNsのパフォーマンスがかなり向上しました ^(7) 。

図4:Nesterovの更新(出典元: G. Hinton氏の講演6c )
NAGに関する直観的な別の説明は こちら を参照してください。Ilya Sutskeverが彼の博士号論文でより詳細な概要を述べています。 ^(8)
更新を誤差関数の勾配に適応させ、SGDの速度を上げることができるようになりました。個々のパラメータの更新についても、その重要性に応じて更新をより大きくしたり小さくしたりして実行するよう適応させたいと思います。
Adagrad
Adagrad ^(9) は以下に示すような、勾配ベースの最適化アルゴリズムです。Adagradは学習率をパラメータに適応させます。そして、まれなパラメータに対してはより大きな更新を、頻出のパラメータに対してはより小さな更新を実行します。このような理由から、スパースなデータを扱うのに適しています。Deanら ^(10) が発見したのは、AdagradがSGDの頑強性を大幅に改善し、Googleでの大規模なニューラルネットワークの訓練、中でも YouTubeビデオの中の猫を認識する という訓練の際に使用したということでした。さらに、Penningtonら ^(11) は、まれな語が頻出な語よりもさらに大きな更新を必要とする時に、GloVeの語の埋め込みの訓練に際してAdagradを使いました。
ここまで、それぞれのパラメータ\(\theta_i\)が同じ学習率\(\eta\)を使うように、全てのパラメータ\(\theta\)を一度に更新していました。Adagradが各タイムステップ\(t\)で、それぞれのパラメータ\(\theta_i\)に対して異なる学習率を使うので、ここではまずAdagradのパラメータごとの更新を示したのち、それをベクトル化することにします。簡単化のために、タイムステップ\(t\)におけるパラメータ\(\theta_i\)に関する目的関数の勾配を\(g_{t, i}\)とします。
\(g_{t, i} = \nabla_\theta J( \theta_i )\)
すると、タイムステップ\(t\)ごとの、SDGが各パラメータ\(\theta_i\)に行う更新は、次のようになります。
\(\theta_{t+1, i} = \theta_{t, i} – \eta \cdot g_{t, i}\).
Adagradの更新規則は、タイムステップ\(t\)ごとに、\(\theta_i\)に対して計算されている過去の勾配に基づいて、各パラメータ\(\theta_i\)に対して一般的な学習率\(\eta\)を修正します。
\(\theta_{t+1, i} = \theta_{t, i} – \dfrac{\eta}{\sqrt{G_{t, ii} + \epsilon}} \cdot g_{t, i}\)
ここの\(G_{t} \in \mathbb{R}^{d \times d} \)は対角行列で、それぞれの対角成分\(i, i\)は、タイムステップ\(t\)までの、\(\theta_i\)に対する勾配の二乗和となります ^(12) 。\(\epsilon\)はゼロによる割り算を避ける平滑化項です(たいていは\(1e-8\)のオーダ)。興味深いことに、平方根の演算なしでは、アルゴリズムのパフォーマンスはとても悪くなります。
\(G_{t}\)は、その対角成分に沿って、全てのパラメータ\(\theta\)に関する過去の勾配の二乗和を含んでいるので、\(G_{t}\)と\(g_{t}\)の間で要素ごとに加算を行う行列ベクトルの掛け算\(\odot\)を実行することによって、以下の様に実装をベクトル化することができます。
\(\theta_{t+1} = \theta_{t} – \dfrac{\eta}{\sqrt{G_{t} + \epsilon}} \odot g_{t}\).
Adagradの主な利点の1つは、手動で学習率を調整することが不要であることです。大部分の実装ではデフォルトの0.01かその辺りにとどめた値を使います。
Adagradの主な弱点は、分母の二乗勾配の蓄積です。どの加算項も正の値なので、訓練の間、累積和は増加し続けます。このことは、次々に学習率が低下し、最終的に極めて小さくなります。その時点で、もはやアルゴリズムはさらなる知識を得ることができません。次に示すアルゴリズムはこの欠点を解決することを目指しています。
Adadelta
Adadelta ^(13) はAdagradの発展形で、急速かつ単調な学習率の低下を防ぐ手段を探るものです。Adadeltaでは、過去すべてのタイムステップにおける勾配の二乗を蓄積しておくのではなく、過去の勾配を蓄積する領域を、ある定数\(w\)に制限します。
前のタイムステップにおける勾配の二乗を\(w\)個保持しておくのは非効率的です。そこで代わりに、勾配の合計値を、過去のタイムステップ全ての勾配の二乗を減衰平均化し、再帰的に定義します。このためタイムステップ\(t\)時点における移動平均\(E[g^2]_t\)は、(Momentumと同様に、\(\gamma \)の割合で)その時点の勾配と過去の平均にのみ依存します。つまり次のような式になります。
\(E[g^2]_t = \gamma E[g^2]_{t-1} + (1 – \gamma) g^2_t \)
\(\gamma\)に、Momentum項と似た値を代入します。例えば0.9前後ですね。はっきり分かるように、パラメータ更新ベクトル\( \Delta \theta_t \)を使って通常のSGDの式を書き直してみましょう。
\(\Delta \theta_t = – \eta \cdot g_{t, i}\)
\(\theta_{t+1} = \theta_t + \Delta \theta_t \)
すると、以前に導出したAdagradのパラメータ更新ベクトルは以下のようになります。
\( \Delta \theta_t = – \dfrac{\eta}{\sqrt{G_{t} + \epsilon}} \odot g_{t}\)
今度は単純に、対角行列\(G_{t}\)を、過去の勾配の二乗の減衰平均\(E[g^2]_t\)で置換します。すると次のようになりますね。
\( \Delta \theta_t = – \dfrac{\eta}{\sqrt{E[g^2]_t + \epsilon}} g_{t}\)
分母は、勾配についての、ただのRMS(二乗平均平方根)誤差基準です。そこで、この基準値を省略して記載してみます。
\( \Delta \theta_t = – \dfrac{\eta}{RMS[g]_{t}}\)
この論文では、この更新において、単位が(SGDやMomentum、Adagradも同様に)一致しないということを警告しています。つまり、更新においては、パラメータと同じ単位を仮定的に持たなければなりません。そのために、この論文ではまず、指数関数的に減衰する別の減衰平均を定義しています。ここでは、勾配の二乗の減衰平均ではなく、パラメータ更新の二乗についての減衰平均です。
\(E[\Delta \theta^2]_t = \gamma E[\Delta \theta^2]_{t-1} + (1 – \gamma) \Delta \theta^2_t \)
すると、パラメータ更新のRMS誤差は以下のようになります。
\(RMS[\Delta \theta]_{t} = \sqrt{E[\Delta \theta^2]_t + \epsilon} \)
\(RMS[\Delta \theta]_{t}\)は未知ですので、前のタイムステップまでの、パラメータ更新のRMSDe近似します。先ほどの更新規則の、学習率\(\eta \)を\(RMS[\Delta \theta]_{t-1}\)と置換すると、ついにAdadeltaの式が導かれます。
\( \Delta \theta_t = – \dfrac{RMS[\Delta \theta]_{t-1}}{RMS[g]_{t}} g_{t}\).
\(\theta_{t+1} = \theta_t + \Delta \theta_t \).
Adadeltaによって、もはや学習率の初期値を設定する必要がなくなりました。学習率そのものが式から消え去ったからです。
RMSprop
RMSpropとは、適応的学習率の方式です。正式には論文化されていませんが、Geoff Hintonが Couseraの講義 6e 内で提案しました。
RMSpropとAdadeltaは、別々に編み出されました。しかしそれは同じ時期です。どちらとも、「Adagradは急速に学習率が低下する」という問題を解決する必要から開発されたのです。RMSpropは実際のところ、前述のAdadeltaの最初のベクトル更新と全く同じものです。
\(E[g^2]_t = 0.9 E[g^2]_{t-1} + 0.1 g^2_t \).
\(\theta_{t+1} = \theta_{t} – \dfrac{\eta}{\sqrt{E[g^2]_t + \epsilon}} g_{t}\).
さらに、RMSpropの場合、学習率は、勾配の二乗の指数関数的減衰平均の除算です。学習率\(\eta\)の初期値が0.001だと適している場合、Hintonは\(\gamma\)に0.9を代入することを推奨しています。
Adam
Adam(Adaptive Moment Estimation) ^(14) はまた別の方式で、それぞれのパラメータに対し学習率を計算し適応させていきます。AdadeltaやRMSpropでは、過去の勾配の二乗\(v_t\)の指数関数的減衰平均を蓄積していました。Adamではこれに加え、同じように過去の勾配\(m_t\)の指数関数的減数平均を保持します。Momentumと似た方法です。
\(m_t = \beta_1 m_{t-1} + (1 – \beta_1) g_t \).
\(v_t = \beta_2 v_{t-1} + (1 – \beta_2) g_t^2 \).
\(m_t\)と\(v_t\)はそれぞれ、勾配の一次モーメント(平均値)と二次モーメント(分散した平方偏差)の概算値です。これこそが、Adamという方式名の由来です。\(m_t\)と\(v_t\)が0のベクトルとして初期化されているように、Adamの論文では、0に偏らせることについて述べられています。特に、初期化時点のタイムステップと、減衰率が小さくなったとき(つまり\(\beta_1\)と\(\beta_2\)が1に近づいたとき)です。
一次モーメントと二次モーメントの偏りをバイアス補正した推定値を計算することによって、このような偏りを小さくしました。
\(\hat{m}_t = \dfrac{m_t}{1 – \beta^t_1} \).
\(\hat{v}_t = \dfrac{v_t}{1 – \beta^t_2} \).
そして、AdadeltaやRMSpropで検証してきたように、パラメータの更新に使うのです。これによって、Adamの式が導かれました。
\(\theta_{t+1} = \theta_{t} – \dfrac{\eta}{\sqrt{\hat{v}_t} + \epsilon} \hat{m}_t\).
論文では、\(\beta_1\)の初期値は0.9、\(\beta_2\)には0.999、\(\epsilon\)には\(10^{-8}\)を設定することを提案しています。また、Adamが訓練時にうまく動くこと、そして他の適応学習率のアルゴリズムと比べて優れている、という点について実証しています。
アルゴリズムの可視化
下記の2つのアニメーション(作者: Alec Radford )は上記の最適化アルゴリズムによる最適化の動きを直感的に示しています。
図5では、各アルゴリズムが時間の経過とともに勾配下降の等高線上をどのように動くかがわかります。次のことに注目して下さい。Adagrad,やAdadeltaや RMSpropがほとんど即座に向きを右方向へ変え、すぐに同じように収束していきますが、その一方で、Momentum とNAGはかなり外れた場所へ行き、丘の下へ転がっていくボールを思い起こさせます。しかし、NAGは先を予測することで反応性を高めたことによって自らの進む道を素早く修正することができ、最小化へ向かっていきます。
図6は鞍点、つまり、ある次元から見れば正の傾き、別の次元から見れば負の傾きの地点におけるアルゴリズムの動きを表しています。その地点では先に述べたようにSGDは停滞してしまいます。以下に注目して下さい。ここではSGD、Momentum、NAGのうち後者2つが最終的に鞍点をどうにか抜け出るものの、対称性を克服するのにかなりの時間を要しています。その一方で、Adagrad,、RMSprop、Adadeltaはすぐに負の傾きをたどります。
 |
 |
ご覧のように、学習率を適応させていく手法、つまりAdagrad、Adadelta、RMSprop、Adamは、上記の条件下で最適で最良の収束をします。
どのオプティマイザを使うべき?
では、どのオプティマイザを使うべきでしょうか?もし入力するデータがスパースなものでしたら、学習率を適応させていく手法のうちの1つを使えば、最良の結果に至るでしょう。これには、学習率を調節する必要がなく、デフォルト値で最良の結果が期待できるというメリットもあります。
要約すると、RMSpropは、劇的に減少する学習率に対処するAdagradの拡張だということです。これはAdadeltaと全く同じですが、Adadeltaが分子の書き換えルールにおいてRMSのパラメータの書き換えルールを使うという点が異なっています。Adamは最終的にRMSpropにバイアス補正とMomemtumを加えます。この点においては、RMSprop、Adadelta,、Adamは似た環境下で順調に動く、よく似たアルゴリズムです。Kingmaら ^(14) によれば、Adamはバイアス補正によって勾配が少なくなるのに従って最適化を目指すRMSpropよりも、ほんの少し優れているということです。Adamは全般的に最も良い選択かもしれません。
興味深いことに、最近の論文の多くはMomentumと簡単な学習率の焼きなましスケジュールなしに基本的なSGDを使っています。先に示したようにSGDは通常、最小値を見出しますが、いくつかのオプティマイザを伴うよりも顕著に時間を要するかもしれません。SGDは、しっかりとした初期化と焼きなましスケジュールの上で信頼性が高まるものであり、ある範囲内での最小値よりも鞍点において身動きが取れなくなるかもしれません。したがって、急速に収束させること、および、深くて複雑なニューラルネットワークを重視するならば、学習率を適応させていく手法から1つを選ぶべきです。
SGDの並列化と分散化
大規模な解がどこにでも存在し、低コモディティのクラスタが使えるとすれば、スピードアップを目指したSGDの分散化を選ぶべきです。
SGDそれ自体が元々シーケンシャルです。ステップバイステップで最小値へ向かって行きます。SGDを使えば優れた収束を得ますが、特に大きなデータセットにおいて処理が遅くなる可能性があります。対照的に、非同期的にSGDを実行すると処理が速くなりますが、ワーカ間のコミュニケーションが最適とは言えず、不十分な収束を招いてしまいます。さらに、大きなコンピュータのクラスタを必要とすることなしに1つのマシン上で、SGDを並行処理化することもできます。以下は並行処理化され、分散化されたSGDを最適化するために提案されたアルゴリズムとアーキテクチャです。
Hogwild!
Niuら ^(15) はHogwild!という名の更新処理のスキームを紹介しています。Hogwild!では、複数のCPU上でSGDの更新処理が並行処理で行われます。プロセッサはパラメータをロックすることなく共有メモリにアクセスできますが、これは入力データがスパースな場合のみ動作します。それぞれの更新処理が全てのパラメータのほんの一部を修正するだけだからです。この場合は、更新処理のスキームが収束へ向けてほぼ最適のレートで動きます。プロセッサが有用な情報を上書きしてしまうことが滅多に起きないからです。
Downpour SGD
Downpour SGDはSGDの非同期への変形です。Deanら ^(10) がGoogleにおいてDisbeliefのフレームワーク(TensorFlowの前身)で使いました。訓練データのサブセット上で並列的にモデルのレプリカをいくつも動かします。こういったモデルはパラメータのサーバに更新処理を送りますが、それが多くのマシンに分散されます。それぞれのマシンにあるのは、モデルのパラメータの一部を保管し更新処理するという役目です。しかし、レプリカ間にはお互いのやり取り(例えば重みや更新処理の共有など)がなく、パラメータには常に分散や収束の遅延というリスクが伴います。
SGDのための遅延耐性アルゴリズム
McMahan & Streeter ^(16) は、Adagradを並行処理のセッティングまで拡張しました。過去の勾配だけでなく更新処理の遅延にも適合させる遅延耐性アルゴリズムの開発によってです。これは実際にうまく動いています。
TensorFlow
TensorFlow ^(17) は、Googleが最近公開した、大規模機械学習モデルの実行とデプロイのためのオープンソースフレームワークです。DistBeliefでの経験に基づいており、Google内では、既に、大規模分散システムだけでなく、多くのモバイル機器上でも、計算処理に使われています。分散処理の実行では、計算グラフがデバイスごとのサブグラフに分割され、通信が送信/受信ノードペアを使って行われます。しかし、TensorFlowのオープンソースバージョンは、現在のところ、分散機能をサポートしていません( こちら を参照してください)。アップデート2016/4/13:TensorFlowの分散バージョンが リリースされました 。
Elastic Averaging SGD
Zhangら ^(18) が提唱しているElastic Averaging SGD (EASGD)は、非同期SGDのワーカのパラメータを、弾力、つまりパラメータサーバに格納されているセンター変数にリンクさせることにより、ローカル変数がセンター変数から変動することを許しています。これにより、理論的には、パラメータ空間のさらなる探索を可能とします。彼らは、探索能力の向上によって、新しい局所最適条件を見つけ、パフォーマンス改善につながることを実証しています。
SGD最適化の更なる戦略
最後に、SGDのパフォーマンスをさらに改善させるために、これまでに触れたアルゴリズムのいずれかと一緒に使うことのできる更なる戦略を紹介します。 ^(19) を見ていただければ、共通するコツのいくつかに関する分かりやすい説明があります。
シャッフルとカリキュラム学習
通常は、学習モデルに訓練例を意味ある順で提供するのは避けたいと考えます。なぜなら、それによって最適化アルゴリズムに偏りを与えてしまうかもしれないからです。そのため、エポックごとに訓練データをシャッフルすると良い場合が多いでしょう。
一方、どんどん難しくなる問題の解消を目的とするケースでは、訓練例を意味ある順で提供することで、実際にパフォーマンスが改善したり、より良く収束したりするかもしれません。この意味ある順を確立する方法をカリキュラム学習 ^(20) と言います。
Zarenba & Sutskever ^(21) は、LSTMにのみ、カリキュラム学習を使って簡単なプログラムを評価するよう訓練することに成功し、複数の戦略を組み合わせたり混ぜ合わせたりすることによって、単一の戦略よりも良い結果となり、ひいては難易度順に例をソートすることになると示しました。
バッチ正規化
学習を促進するために、一般的に、パラメータの初期値を平均0・分散1に初期化することによって正規化します。訓練が進み、パラメータを異なる範囲に更新するにつれ、この正規化は失われます。その結果、ネットワークが深くなっていくと、訓練速度が落ち、変化の幅が大きくなります。
バッチ正規化 ^(22) は、ミニバッチごとに再び正規化を行い、加えて、この処理によって変化が逆伝搬されます。正規化をモデルアーキテクチャの一部とすることにより、学習率を上げ、初期化パラメータにあまり注意を払わずに済みます。バッチ正規化は、正則化の機能も果たすので、Dropoutの必要性を減らします(時には全くなくすことさえあります)。
早期終了
Geoff Hintonの言葉に、「 早期終了は、美しいフリーランチです 」( NIPS2015のチュートリアルスライド 、スライド63)というものがあります。そのため、訓練中、検証用データセットの誤差を常に監視し、検証の誤差が十分に改善に結び付かない場合は、ある程度粘り強く対応した上で、終了すべきです。
勾配ノイズ
Neelakantanら ^(23) は、ガウス分布\(N(0, \sigma^2_t)\)に従うノイズを各勾配の更新に加えます。
\(g_{t, i} = g_{t, i} + N(0, \sigma^2_t)\)
以下のスケジュールに従って、分散の焼きなましを行います。
\( \sigma^2_t = \dfrac{\eta}{(1 + t)^\gamma} \)
このノイズを付加することにより、ネットワークの不十分な初期化に対するロバスト性が向上し、特に深く複雑なネットワークを訓練するのに役立つことを示しています。付加されたノイズによって、モデルが新しい極小値から抜け出したり見つけたりする機会を増やすのではないかと考えています。こういった機会は、深いモデルになるほど多いのです。
結論
このブログの投稿では、最初に3種類の勾配降下法を概観し、ミニバッチ勾配降下法が最もポピュラーであることを見てきました。そして、SGD最適化に最も一般的に使われるアルゴリズムである、Momentum、NAG、Adagrad、Adadelta、RMSProp、Adamを調査したのち、非同期SGDを最適化する複数のアルゴリズムも調査しました。最後に、シャッフル、カリキュラム学習、バッチ正規化、早期終了のような、SGDを改善するその他の戦略を検討しました。
このブログの投稿が、複数の最適化アルゴリズムを試す動機付けや、それらの動きの理解につながれば幸いです。何かここで触れ忘れた、SGDを改善できることが明らかなアルゴリズムはありますか?SGDで訓練を促進するのに実際に使っているコツは何ですか? 下のコメント欄で教えてください。
謝辞
本稿の草稿を読んでご意見をくださった Denny Britz氏 と Cesar Salgado氏 に感謝いたします。
参考文献
カバー写真: Karpathy’s beautiful loss functions tumblr (Karpathyの美しい喪失関数tumblr)
-
H. Robinds and S. Monro, “A stochastic approximation method” [確率論的近似法], Annals of Mathematical Statistics [数学的統計論文集], vol. 22, pp. 400–407, 1951. ↩
-
Darken, C., Chang, J., & Moody, J. (1992). Learning rate schedules for faster stochastic gradient search. [より早い確率勾配探索のための学習率]. Neural Networks for Signal Processing II Proceedings of the 1992 IEEE Workshop [信号処理のためのニューラルネットワーク2 1992年IEEEワークショップ発表論文集], (September), 1–11. http://doi.org/10.1109/NNSP.1992.253713 ↩
-
Dauphin, Y., Pascanu, R., Gulcehre, C., Cho, K., Ganguli, S., & Bengio, Y. (2014). Identifying and attacking the saddle point problem in high-dimensional non-convex optimization [高次元非凸最適化における鞍点問題の特定と取り組み]. arXiv, 1–14. Retrieved from http://arxiv.org/abs/1406.2572 ↩
-
Sutton, R. S. (1986). Two problems with backpropagation and other steepest-descent learning procedures for networks [逆伝播と最急降下法によるネットワーク学習プロシージャにおける2つの課題]. Proc. 8th Annual Conf. Cognitive Science Society [認知科学会 第8回年次大会発表論文集]. ↩
-
Qian, N. (1999). On the momentum term in gradient descent learning algorithms [勾配降下法による学習アルゴリズムにおけるMomentum項について]. Neural Networks : The Official Journal of the International Neural Network Society [ニューラルネットワーク:国際ニューラルネットワーク学会 学会誌], 12(1), 145–151. http://doi.org/10.1016/S0893-6080(98)00116-6 ↩
-
Nesterov, Y. (1983). A method for unconstrained convex minimization problem with the rate of convergence o(1/k2) [収束率o(1/k2)における非凸最小化問題への対応策]. Doklady ANSSSR (translated as Soviet.Math.Docl.), vol. 269, pp. 543– 547. ↩
-
Bengio, Y., Boulanger-Lewandowski, N., & Pascanu, R. (2012). Advances in Optimizing Recurrent Networks [リカレント・ネットワークの最適化における進歩]. Retrieved from http://arxiv.org/abs/1212.0901 ↩
-
Sutskever, I. (2013). Training Recurrent neural Networks. PhD Thesis [回帰的ニューラルネットワークの訓練 博士論文]. ↩
-
Duchi, J., Hazan, E., & Singer, Y. (2011). Adaptive Subgradient Methods for Online Learning and Stochastic Optimization [オンライン学習と確率論的最適化のための劣勾配適応メソッド]. Journal of Machine Learning Research [雑誌『機械学習研究』], 12, 2121–2159. Retrieved from http://jmlr.org/papers/v12/duchi11a.html ↩
-
Dean, J., Corrado, G. S., Monga, R., Chen, K., Devin, M., Le, Q. V, … Ng, A. Y. (2012). Large Scale Distributed Deep Networks [深層ネットワークの大規模分散]. NIPS 2012: Neural Information Processing Systems [NIPS 2012:ニューラル情報処理システム], 1–11. http://doi.org/10.1109/ICDAR.2011.95 ↩ ↩
-
Pennington, J., Socher, R., & Manning, C. D. (2014). Glove: Global Vectors for Word Representation [Glove:単語表現のためのグローバル・ベクトル]. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing [自然言語処理における実証的メソッドについての2014年度コンファレンス 発表論文集], 1532–1543. http://doi.org/10.3115/v1/D14-1162 ↩
-
Duchiら[^3]は、この行列を、過去の全ての勾配の外積を含む全行列に代わるものとして提示しています。その理由は、パラメータ\(d\)の適度な値に対してさえ行列平方根の計算を行えないためです。 ↩
-
Zeiler, M. D. (2012). ADADELTA: An Adaptive Learning Rate Method [ADADELTA:適応学習率メソッド]. Retrieved from http://arxiv.org/abs/1212.5701 ↩
-
Niu, F., Recht, B., Christopher, R., & Wright, S. J. (2011). Hogwild ! : A Lock-Free Approach to Parallelizing Stochastic Gradient Descent [Hogwild ! :確率的勾配降下法並列化のロックフリーアプローチ], 1–22. ↩
-
Mcmahan, H. B., & Streeter, M. (2014). Delay-Tolerant Algorithms for Asynchronous Distributed Online Learning. Advances in Neural Information Processing Systems (Proceedings of NIPS) [ニューラル情報処理システムにおける非同期的分散オンライン学習進展のための遅延耐性アルゴリズム(NIPS発表論文集)], 1–9. Retrieved from http://papers.nips.cc/paper/5242-delay-tolerant-algorithms-for-asynchronous-distributed-online-learning.pdf ↩
-
Abadi, M., Agarwal, A., Barham, P., Brevdo, E., Chen, Z., Citro, C., … Zheng, X. (2015). TensorFlow : Large-Scale Machine Learning on Heterogeneous Distributed Systems [TensorFlow:不均一な分散システム上の大規模機械学習]. ↩
-
Zhang, S., Choromanska, A., & LeCun, Y. (2015). Deep learning with Elastic Averaging SGD [弾力的平均化SGDによるディープラーニング]. Neural Information Processing Systems Conference [ニューラル情報処理システムコンファレンス](NIPS2015), 1–24. Retrieved from http://arxiv.org/abs/1412.6651 ↩
-
LeCun, Y., Bottou, L., Orr, G. B., & Müller, K. R. (1998). Efficient BackProp [効率的な逆伝搬]. Neural Networks: Tricks of the Trade [ニューラルネットワーク: 作業のコツ], 1524, 9–50. http://doi.org/10.1007/3-540-49430-8_2 ↩
-
16.Bengio, Y., Louradour, J., Collobert, R., & Weston, J. (2009).
Curriculum learning [カリキュラム学習]. Proceedings of the 26th Annual International Conference on Machine Learning [第26回機械学習における国際コンファレンス発表論文集], 41–48. http://doi.org/10.1145/1553374.1553380 ↩ -
Zaremba, W., & Sutskever, I. (2014). Learning to Execute [実行のための学習], 1–25. Retrieved from http://arxiv.org/abs/1410.4615 ↩
-
Ioffe, S., & Szegedy, C. (2015). Batch Normalization : Accelerating Deep Network Training by Reducing Internal Covariate Shift [バッチ正規化:内部共変量シフト削減による深層ネットワークトレーニングの促進]. arXiv Preprint arXiv:1502.03167v3. ↩
-
Neelakantan, A., Vilnis, L., Le, Q. V., Sutskever, I., Kaiser, L., Kurach, K., & Martens, J. (2015). Adding Gradient Noise Improves Learning for Very Deep Networks [勾配ノイズ付加が超深層ネットワークの学習を改善する], 1–11. Retrieved from http://arxiv.org/abs/1511.06807 ↩

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事