2016年8月10日
iOS 10とMac OSにおけるニューラルネットワーク
(2016-06-29)by Bolot Kerimbaev
本記事は、原著者の許諾のもとに翻訳・掲載しております。
Appleは、長年、自社製品に機械学習を使っています。例えば、Siriは、あなたの質問に答え、楽しませてくれます。iPhotoは、写真の中の顔を認識します。メールアプリは、スパムメッセージを検知します。アプリ開発者なら、 顔認証 のようにAppleのAPIで公開されている機能の幾つかを利用できます。iOS 10から始めて、音声認識やSiriKit用のハイレベルAPIを入手しましょう。
時々、プラットフォームに内蔵されているAPIの狭い領域を超えて、独自のものを作りたいと思うこともあるでしょう。多くの場合は機械学習を始動させますが、その際、たくさんの既成のライブラリのうちの1つを使ったり、高速計算能力を持つAccelerateやMetalの上に直接組み上げたりして実現します。
例えば、私の同僚が構築したオフィス入室システムは、iPadを使って顔認証を行い、SlackにGIF画像を投稿して、ユーザの入力するカスタムコマンドでドアを開錠します。

しかし、ついに私たちは、ニューラルネットワークに関する開発元のサポートを得ました。WWDC2016において、Appleは、1つではなく、2つのニューラルネットワークAPIを紹介したのです。Basic Neural Network Subroutines (BNNS)とConvolutional Neural Networks (CNN)です。
機械学習とニューラルネットワーク
人工知能のパイオニア Arthur Samuel は、 機械学習 を「明確なプログラムがなくても学習する能力をコンピュータに与える研究分野」と定義しました。機械学習システムは、従来のモデルが簡単に当てはめられないデータを解明するのに頻繁に使われています。
例えば、全ての部屋とその他の空間の寸法と形が分かれば、家の面積を計算するプログラムを書くのは簡単です。しかし、家の価値を計算するのは、公式に当てはめられるものではありません。一方、機械学習システムは、このような問題に最適です。市場価値、家の寸法、寝室の数など、既に分かっている現実のデータをシステムに入力することによって、価格を予想する訓練ができるのです。
ニューラルネットワークは、機械学習システム構築で最も一般的なモデルの1つです。ニューラルネットワークの数学的基礎は、半世紀以上前の1940年代に研究が進みましたが、並列計算でニューラルネットワークがより実現可能になったのは1980年代で、2000年代に入って ディープラーニング に関心が集まったことにより、ニューラルネットワークが再び注目されるようになりました。
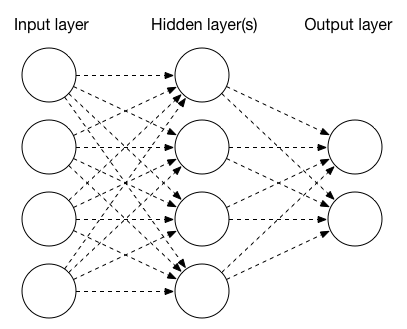
ニューラルネットワークは、多層構造をしており、各層は、1つ以上のノードで構成されています。最もシンプルなニューラルネットワークは、入力層、隠れ層、出力層という3層構造です。入力層ノードは、例えば、画像の個々のピクセルやその他のパラメータです。出力層ノードは、多くの場合、分類の結果で、写真の中の被写体を自動認識しようとする場合の「犬」か「猫」かというようなものです。隠れ層ノードは、入力データを処理するか、活性化関数を適用するよう設定されています。

層のタイプ
層には3つのよく知られたタイプがあります。プーリング層、畳み込み層、全結合層です。
プーリング層はデータを集め、一般的に入力データの最大値または平均値を用いて容量を減らしています。一連の畳み込み層とプーリング層はつなぎ合わせることができ、写真から特徴を少しずつ抽出し、極めて高次な特徴量のコレクションにしていきます。
畳み込み層では、画像の各ピクセルに畳み込み行列を適用して画像を変換します。PixelmatorやPhotoshopのフィルターを使ったことがあるのであれば、畳み込み行列を使ったことがある可能性が高いでしょう。畳み込み行列は通常3×3か5×5の行列で、入力された画像のピクセルに適用され、出力する画像の新たなピクセル値を計算します。通常、出力するピクセル値を得るには、オリジナルの画像のピクセル値を掛け合わせて平均値を計算します。
例えば、下記の畳み込み行列は画像をぼかします。
1 1 1
1 1 1
1 1 1一方、こちらは画像をシャープにするものです。
0 -1 0
-1 5 -1
0 -1 0ニューラルネットワークにおける畳み込み層は、畳み込み行列を使い、入力データを処理して次の層に渡すデータを生成します。例えば、画像のエッジといった新たな特徴を抜き出します。
全結合層は、オリジナルの画像とフィルタのサイズが同じである畳み込み層として考えることができます。言い換えると、全結合層は「個々のピクセルに重みを割り当て、その結果の平均値を算出して、1つの出力値を得る」機能と考えることができるのです。
訓練と推論
いずれの層も適切なパラメータが設定される必要があります。例えば、畳み込み層では、入力画像と出力画像の情報(次元やチャンネルの数など)や、畳み込み層のパラメータ(カーネルのサイズ、行列など)が必要です。全結合層は、入出力のベクトル、活性化関数、重みによって定義されます。
これらのパラメータを得るためには、ニューラルネットワークを訓練しなければなりません。これは、入力データをニューラルネットワークに通し、出力データを決定し、誤差を測定し(つまり、予想した結果と実際の結果がどれほど違うかを測り)、さらにバックプロパゲーションを経て、重みを調整して達成されるものです。ニューラルネットワークの訓練には数百、数千、あるいは数百万ものサンプルが必要になることもあります。
今のところ、Appleの新しい機械学習のAPIは、推論のみのニューラルネットワーク構築に使えるもので、訓練はできません。幸いにも Big Nerd Reachでやっています。
Accelerate:BNNS
1つ目の新しいAPIはAccelerateフレームワークの一部であり、名称をBNNSと言い、 Basic Neural Network Subroutines を略したものです。BNNSはBLAS(Basic Linear Algebra Subroutines)を補完するもので、いくつかのサードパーティの機械学習アプリケーションとして使われました。
BNNSは BNNSFilter のクラスにおいて層を定義します。Accelerateは3つのタイプの層、つまり、畳み込み層( BNNSFilterCreateConvolutionLayer 関数で生成)、全結合層( BNNSFilterCreateFullyConnectedLayer )、プーリング層( BNNSFilterCreatePoolingLayer )をサポートします。
MNISTデータベース は、数万枚の手書きの数字をスキャンし、20×20ピクセルの画像にサイズ変更した有名なデータセットです。
画像データを処理する手法の1つは、画像をベクトルに変換し、全結合層に通すことです。MNISTデータの場合、1つの20×20ピクセルの画像は、400個の値のベクトルとなります。ここで、手書きの数字「1」がどのようにベクトルに変換されるかを説明します。

以下は、サイズ400のベクトルを入力し、シグモイド活性化関数を使用して、サイズ25のベクトルを出力する全結合層を設定するためのサンプルコードです。
// input layer descriptor
BNNSVectorDescriptor i_desc = {
.size = 400,
.data_type = BNNSDataTypeFloat32,
.data_scale = 0,
.data_bias = 0,
};
// hidden layer descriptor
BNNSVectorDescriptor h_desc = {
.size = 25,
.data_type = BNNSDataTypeFloat32,
.data_scale = 0,
.data_bias = 0,
};
// activation function
BNNSActivation activation = {
.function = BNNSActivationFunctionSigmoid,
.alpha = 0,
.beta = 0,
};
BNNSFullyConnectedLayerParameters in_layer_params = {
.in_size = i_desc.size,
.out_size = h_desc.size,
.activation = activation,
.weights.data = theta1,
.weights.data_type = BNNSDataTypeFloat32,
.bias.data_type = BNNSDataTypeFloat32,
};
// Common filter parameters
BNNSFilterParameters filter_params = {
.version = BNNSAPIVersion_1_0; // API version is mandatory
};
// Create a new fully connected layer filter (ih = input-to-hidden)
BNNSFilter ih_filter = BNNSFilterCreateFullyConnectedLayer(&i_desc, &h_desc, &in_layer_params, &filter_params);
float * i_stack = bir; // (float *)calloc(i_desc.size, sizeof(float));
float * h_stack = (float *)calloc(h_desc.size, sizeof(float));
float * o_stack = (float *)calloc(o_desc.size, sizeof(float));
int ih_status = BNNSFilterApply(ih_filter, i_stack, h_stack);Metal!
これ以上、メタルな(素晴らしい)ものは他にあるでしょうか? 実は、あるのです。なぜなら、2番目のニューラルネットワークAPIはMetal Performance Shaders (MPS)フレームワークの一部だからです。AccelerateがCPUで高速計算を行うためのフレームワークなのに対して、MetalはGPUのパフォーマンスを限界まで押し上げます。Metalの特徴は、CNN、すなわち 畳み込みニューラルネットワーク と呼ばれるものです。
MPSには、Accelerateと同様のAPI群が用意されています。畳み込み層を作成するには、 MPSCNNConvolutionDescriptor と MPSCNNConvolution 関数を使用する必要があります。プーリング層の場合は、 MPSCNNPoolingMax が、パラメータを与えることになります。全結合層は MPSCNNFullyConnected 関数によって作成されます。活性化関数は MPSCNNNeuron のサブクラスである MPSCNNNeuronLinear 、 MPSCNNNeuronReLU 、 MPSCNNNeuronSigmoid 、 MPSCNNNeuronTanH 、 MPSCNNNeuronAbsolute で定義されています。
BNNSとCNNの比較
下表は、AccelerateとMetalの活性化関数の一覧です。
| Accelerate/BNNS | Metal Performance Shaders/CNN |
|---|---|
| BNNSActivationFunctionIdentity | |
| BNNSActivationFunctionRectifiedLinear | MPSCNNNeuronReLU |
| MPSCNNNeuronLinear | |
| BNNSActivationFunctionLeakyRectifiedLinear | |
| BNNSActivationFunctionSigmoid | MPSCNNNeuronSigmoid |
| BNNSActivationFunctionTanh | MPSCNNNeuronTanH |
| BNNSActivationFunctionScaledTanh | |
| BNNSActivationFunctionAbs | MPSCNNNeuronAbsolute |
下表は、プーリング関数の一覧です。
| Accelerate/BNNS | Metal Performance Shaders/CNN |
|---|---|
| BNNSPoolingFunctionMax | MPSCNNPoolingMax |
| BNNSPoolingFunctionAverage | MPSCNNPoolingAverage |
AccelerateとMetalは、非常によく似たニューラルネットワーク関数群を提供しているので、どちらを選択するかは、各アプリケーションに依存します。GPUは、通常、機械学習に必要な種類の計算には望ましい反面、データの局所性によって、Metal CNNのパフォーマンスが、Accelerate BNNSバージョンより劣る場合があります。GPUにロードされた画像上でニューラルネットワークを動かす場合、例えば、 MPSImage と新しい MPSTemporaryImage を使うと、Metalの方が明らかにパフォーマンスが上です。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事