2015年12月16日
Spotifyのモニタリング part 2:Heroicの紹介
(2015-11-17)by John-John Tedro
本記事は、原著者の許諾のもとに翻訳・掲載しております。

この記事はSpotifyのモニタリングについての第2弾です。 前回の投稿 では運用のモニタリングの経緯について書きました。今回はHeroicについて解説します。これは当社のスケーラブルな時系列データベースで、現在はフリーソフトウェアになっています。
当社ではHeroicを社内用の時系列データベースとして使っています。Heroicを構築した背景には、私たちが直面していた、ほぼリアルタイムなデータ収集と大規模プレゼンテーションといった問題への取り組みがあります。これには主に、CassandraとElasticsearchの2つのテクノロジを使用しています。メインのストレージとしてCassandraを、Elasticsearchはその全データをインデックスするのに用います。現在、いくつかのクラスタに分けて200以上のCassandraのノードを運用していて、世界中で5000万の異なる時系列を処理しています。
Elasticsearchはデータの安全性に関して評判が悪い ことは承知していたので、データパイプラインまたはCassandraからインデックスを迅速かつ完全に再構築できる機能を搭載し、全面的な障害に対して保護しています。
Heroicの主要な機能はグローバルなフェデレーションです。複数のクラスタが個別に運用でき、グローバルインターフェースを形成するためにクエリを互いにデリゲートすることができます。1つのゾーンが障害を起こしても、使用不可になるのは同一ゾーンでホストされているデータだけです。クラスタは複数ゾーンにまたがってより高い稼働性を提供しています。

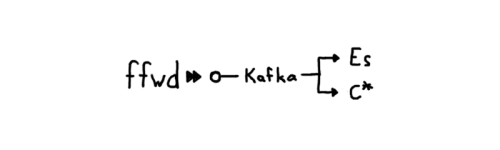
当社のインフラにある全てのホストでは、メトリクスの受信と転送を行うエージェント、 ffwd が稼働しています。そしてメトリクスをエクスポートするプロセスが、エージェントにメトリクスを送信しています。これによって当社のエンジニアは、いずれのホストで実行されているどんなものでも簡単に利用することができています。ライブラリ側では「ホスト上でエージェントが利用可能であり、しかもほとんど設定を必要としない」と想定することが可能です。エージェントが近接しているとレイテンシが最小になるので、不適切に書かれたクライアントの悪影響を低減してくれます。集められたメトリクスは、ffwdによって各ゾーンの Kafka クラスタに送り込まれます。
この設定によって、迅速にサービス・トポロジを試すことができます。Kafkaは、CassandraやElasticsearchがうまく機能しない場合にゆとりとなるバッファを提供してくれ、全てのコンポーネントは要求に応じてスケールアップやスケールダウンすることができます。
バックエンドでは、エージェントに提供されたのと同じように全てが保存されます。何かしらのダウンサンプリングが必要であれば、 Dropwizardメトリクス のようなライブラリを使うことによって、エージェントの 前に 実行されます。エンジニアは、Heroic APIを通して保存されたデータに対し、追加のアグリーゲーションを行うことができますが、私たちはエージェントからの適当なサンプリング密度に依存しています。30秒毎(もしくはそれ以上)に各時系列に対して1つのサンプルが一般的で、このアプローチで遅延や複雑性を回避しています。これは通常、過密したパイプラインのプロセスに関係しています。
Heroicを使うことで、カスタム・ダッシュボードや同じインターフェースを活用するアラートシステムを構築することができています。これによって、同じUI内にグラフに基づいたアラートを定義できるようになり、エンジニアにとっても、設定が簡単になります。しかし、Riemannが近いうちになくなってしまうわけではありません。当社のインフラの特定部分を監視することができる二次的な方法を持つことに価値を見出しました。さらに可視的なアラートシステムに移行していくことを、長期的な目的としています。
Heroicの全てのパーツはフリーソフトウェアですので、 Github からコードを自由に入手することができます。プロジェクトに関する資料や情報は オフィシャルプロジェクトサイト をご覧ください。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事