2016年5月5日
C++でブルームフィルタを実装する方法

(2016-04-11)by Michael Schmatz
本記事は、原著者の許諾のもとに翻訳・掲載しております。
ブルームフィルタとは、「ある要素が集合のメンバである可能性があるか、それとも確実に集合のメンバではないか」を効果的に確認することのできるデータ構造です。この記事では、C++でブルームフィルタを実装する簡単な方法をご紹介します。 ブルームフィルタとは何なのか 、また、 その背後にある多くの数学的要素 については紹介していませんので、ご了承ください。これらのトピックに関しては、素晴らしいリソースがあるので、そちらを参考にしてください。
インターフェイス
まずは、ブルームフィルタを定義していきましょう。ここでは、3つのパブリック関数を定義していきます。
- コンストラクタ
- ブルームフィルタにアイテムを追加する関数
- アイテムがブルームフィルタにある可能性を確認するためのクエリを行う関数
また、フィルタの状態を保持するビットの配列を含んだ、メンバ変数についても定義します。
#include <vector>
struct BloomFilter {
BloomFilter(uint64_t size, uint8_t numHashes);
void add(const uint8_t *data, std::size_t len);
bool possiblyContains(const uint8_t *data, std::size_t len) const;
private:
uint8_t m_numHashes;
std::vector<bool> m_bits;
};1つ覚えておいていただきたいのは、 std::vector<bool> は std::vector の空間効率性に特化したもので、1つの要素に対して1ビットしか必要としないことです(一方、通常の実装では1要素に1バイトが必要)。
アップデート:HNの nate_martin は、拡張としてこの構造体をテンプレート化することを勧めています。キーの型やハッシュ関数をハードコード化する代わりに、例えば以下のようなコードと一緒にクラスをテンプレート化することができます。
template< class Key, class Hash = std::hash<Key> >
struct BloomFilter {
...
};これにより、より複雑なデータ型にブルームフィルタを一般化することが可能になります。Nateありがとう!
ブルームフィルタのパラメータ
ブルームフィルタを構成する上で使われたパラメータは以下の2つです。
- フィルタサイズ(ビット数)
- 使用するハッシュ関数の数
フィルタサイズ m 、ハッシュ関数の数 k 、そして挿入された要素の数 n を基に、公式を使って、偽陽性によるエラー率 p を割り出すことができます ^(1) 。
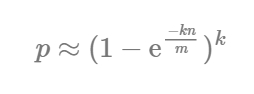
現在の形式のままでは、この公式は役に立ちません。与えられた推定集合濃度とエラー許容範囲を元に、望ましいフィルタサイズはどれぐらいか、使用するハッシュ関数がいくつなのかを知ることができる計算式にしたいと思います。これらのパラメータを計算するには2つの方程式を使うことができます。
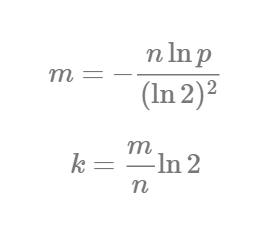
実装
もう1点だけ、必須の理論があります。ハッシュ関数 k は一体どう実装するのかと思われたかもしれません。偽陽性の確率に影響を与えることなく、 k のハッシュ値を生成するには、 ダブルハッシュ法 が使えます。これは以下の公式で表せます。 i が序数であるなら、 m はブルームフィルタのサイズで、 m はハッシュされる値です。
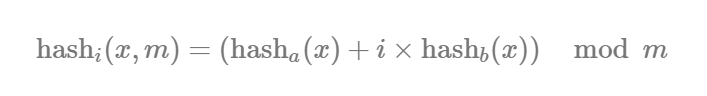
より詳しい証明は、 このペーパー を読んでください。
まず、コンストラクタを記述しましょう。単純にパラメータを記録し、ビット配列のサイズを変える役割があります。
#include "BloomFilter.h"
#include "MurmurHash3.h"
BloomFilter::BloomFilter(uint64_t size, uint8_t numHashes)
: m_bits(size),
m_numHashes(numHashes) {}次に、指定されたアイテムの128bitのハッシュを計算する関数を記述します。128bitのハッシュ関数で、パフォーマンス、分布、雪崩のふるまい、衝突耐性の間の最適なトレードオフを実現する MurmurHash3 を使います。この関数は128bitのハッシュ値を生成しますが、ここでは2つの64bitのハッシュが必要なので、ハッシュの戻り値を半分に分ければ 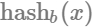 と
と 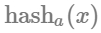 を取得できます。
を取得できます。
std::array<uint64_t, 2> hash(const uint8_t *data,
std::size_t len) {
std::array<uint64_t, 2> hashValue;
MurmurHash3_x64_128(data, len, 0, hashValue.data());
return hashValue;
}これでハッシュ値が得られますので、 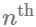 ハッシュ関数
ハッシュ関数
の出力を返すための関数を書く必要があります。
inline uint64_t nthHash(uint8_t n,
uint64_t hashA,
uint64_t hashB,
uint64_t filterSize) {
return (hashA + n * hashB) % filterSize;
}あとは、指定されたアイテムのビットを設定またはチェックする関数を記述するだけです。
void BloomFilter::add(const uint8_t *data, std::size_t len) {
auto hashValues = hash(data, len);
for (int n = 0; n < m_numHashes; n++) {
m_bits[nthHash(n, hashValues[0], hashValues[1], m_bits.size())] = true;
}
}
bool BloomFilter::possiblyContains(const uint8_t *data, std::size_t len) const {
auto hashValues = hash(data, len);
for (int n = 0; n < m_numHashes; n++) {
if (!m_bits[nthHash(n, hashValues[0], hashValues[1], m_bits.size())]) {
return false;
}
}
return true;
}結果
私のラップトップでは、4.3MBのブルームフィルタと13のハッシュ関数で、180万のアイテム挿入が1要素につきおよそ189ナノ秒でできました。偽陽性の確率も、理論上の値と適合しています。
より良い実装のアイデアがあれば、コメントを残すか、 メッセージを送ってください 。読んでくださってありがとうございます。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事