2014年6月17日
Clojureで学ぶデータ構造:ハッシュテーブル
本記事は、原著者の許諾のもとに翻訳・掲載しております。
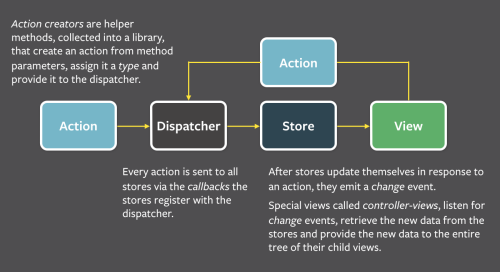
前回のおさらい
前回の記事 では連結リストについてお話ししました。具体的には、ミュータブルな片方向リストの実装方法を検証しましたね。片方向リストを選んだ理由についても、すでに説明済みです。ここで覚えておいてほしいのは、一般的にClojureではイミュータブルなデータ構造が用いられるということです。しかしミュータブルなデータ構造を利用した方が、アルゴリズムがよりシンプルで高速になるケースがあります。実際にClojureでプログラムを組む時はClojureのデータ構造を使いますが、このシリーズではClojureとデータ構造についての理解を深めるため、あえて違うアプローチをとります。他ではあまり深く掘り下げられることのない definterface と deftype を詳しく説明するためです。
今回は、前回作った連結リストをベースに、連想配列や辞書に代表される抽象データ型の機能を備えたデータ構造を構築します。具体的には、ハッシュテーブルを実装することになります。
ハッシュテーブルを実装する時は、ハッシュ衝突を回避しつつランタイムパフォーマンスを保証する必要があります。両者のバランスをとりながら実装を進めていきましょう。最終的に完成する構造体の実装はJavaやClojureのクラスの実装にはかないませんが、コーディングを通してあらゆる言語のデータ構造に共通する普遍的な本質を見ることができるはずです。それはミュータブルであってもイミュータブルであっても変わることのない原理です。
ハッシュテーブル
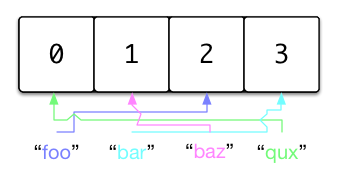
抽象データ型 である 連想配列 を実装したものには、 ハッシュテーブル やハッシュマップがあります。連想配列の主な機能は、キーを使った値の挿入、検索、削除です。例えば、値 "bar" を格納する時に、キー "foo" を指定することができます。こうしておけば、後からキー "foo" を使ってハッシュテーブルから値 "bar" を取り出すことができます。それでは実際にキー "foo" と値 "bar" を関連づけるデータ構造を構築していきましょう。
上で説明した連想マップのようなデータ構造は、多くの言語で使われています。例えばPythonのプログラマは辞書を、Clojureのプログラマはハッシュマップをよく使います。今から構築するハッシュテーブルはこれらのデータ構造とよく似た動きをしますが、重要な違いがあります。それは、私たちが実装する連想配列がミュータブル、つまり可変だということです。
パフォーマンスの特徴
高いパフォーマンスを保証できるというのが、ハッシュテーブルの持つ重要な特徴です。ハッシュテーブルにおける挿入、検索、削除の実行速度は平均するとΟ(1)になります。連結リストでも、リストの先頭にある要素にはΟ(1)の速さでアクセスすることができます。しかしリスト内の他の要素を検索する時は実行速度がΟ(n)になり、かなりの時間を費やすことになります。なぜなら検索時に、リスト内にある全要素を1つずつ参照する必要があるからです。
ハッシュテーブルにおいても、実質的なパフォーマンスは、キャッシュの局所性、インデックスの値を決めるハッシュ関数、連鎖法や開番地法などの衝突処理に左右されます。とはいえパフォーマンスに関する限り、ハッシュテーブルが連結リストに勝るのは間違いないでしょう。
実装の詳細
これから実装するハッシュテーブルには「バケット」という配列を利用します。バケットは、すべてのデータが格納されるデータ構造の基礎となる要素です。ハッシュテーブルを、このバケット配列をラップするインデクサーだと言い換えてもいいでしょう。実際は、インデックスはNodeに保持されます。前回構築した連結リストを思い出してみてください。ノードは次のノードへと連鎖していましたね。このような構造を連鎖法と呼びます。
仕組みを説明しましょう。簡単な配列を思い浮かべてください。今から実装するハッシュテーブルにキーと値を渡すと、そのキーと値はそれぞれ下位のバケット配列のあるインデックスに格納されます。詳細は後で説明しますので、今のところは、このデータ構造を使えばバケット配列のどの位置にキーと値のペアが格納されたのかが分かる、つまりインデックスがつけられていると理解しておいてください。

作業を簡略化するために前回実装したコードに手を加えて、3つのフィールド key 、 value 、 next を持つ新しいNodeクラスを作ります。前回のクラスをそのまま使うこともできますが、修正を加えることでキーと値の設定と参照をよりシンプルにすることができます。
基本の実装
HashTableクラス
それでは前回実装した連結リストのコードをベースに、 HashTable と呼ばれる新しいクラスを導入しましょう。 Node クラスと同じように、使用する関数群をインターフェースを使って定義します。 コードは次のようになります。
(definterface INode
(getKey [])
(setKey [k])
(getVal [])
(setVal [v])
(getNext [])
(setNext [n]))
(deftype Node
[^:volatile-mutable key
^:volatile-mutable val
^:volatile-mutable next]
INode
(getKey [this] key)
(setKey [this k] (set! key k))
(getVal [this] val)
(setVal [this v] (set! val v))
(getNext [this] next)
(setNext [this n] (set! next n)))
(definterface IHashTable
(insert [k v]))
(deftype HashTable
[buckets size]
IHashTable
(insert [this k v]))先ほど述べたとおり、前回の連結リストのコードに少し手を加えました。ハッシュテーブルの型と insert メソッドはまだきちんと実装されていませんが、これについては後でカバーしますね。本格的な実装に入る前にまず、 buckets 配列を用いてキーと値のペアを正確に関連づける方法を詳しく見てみましょう。
キーと値のペアは、連結リストの一部としてそれぞれノードの中に格納されます。これは後で説明する衝突処理の項で重要になりますから、よく覚えておいてください。これらのノードは buckets 配列のインデックスにマップされます。配列の中から特定のノードに紐づいたインデックスを見つけるには、キーとなる文字列をハッシュします。”ハッシュテーブル”を”ハッシュ”するわけですね。ハッシュ値を有効なインデックスに確実に対応させるには、バケット配列の要素数とハッシュ値の数の両方が足りていなければなりません。そうすれば、常に有効なインデックスを用意することができます。
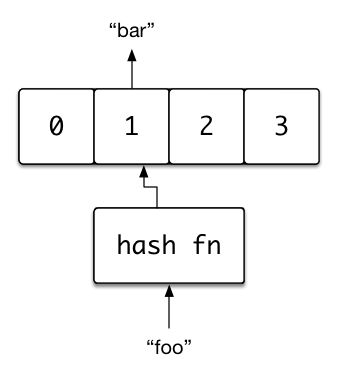
ここまではいいですね。では、 insert メソッドの実装に進みましょう。
(definterface IHashTable
(bucketIdx [k])
(setBucket [k v])
(insert [k v]))
(deftype HashTable
[buckets size]
IHashTable
(bucketIdx [_ k] (mod (hash k) size))
(setBucket [this k v] (aset buckets (.bucketIdx this k) v))
(insert [this k v]
(.setBucket this k (Node. k v nil)))) aset は、配列のインデックスに値をセットするClojure特有の関数です。Javaの配列をClojureで使うことはめったにありませんが、Javaとの連携を効率化するために aset 、 aget 、 alength などのメソッドは用意されています。今回はこれらのメソッドを使ってバケット配列を操作します。
これで、キーと値をバケット配列に挿入する準備ができました。このHashTableクラスは次のように使います。
=> (def hash-table
(let [size 4]
(HashTable. (make-array INode size) size)))
#'user/hash-table
=> (.insert hash-table "foo" "bar")
#<Node user.Node@2753d864>これでハッシュテーブルが定義できました。 size でサイズを指定した INode を格納した配列が、引数として渡されていますね。ハッシュテーブルのサイズも、 size の値で指定されています。おっと、ハッシュテーブルの中身を参照するメソッドを忘れていました。それでは、先に進む前に lookup メソッドを実装してみましょう。
(definterface IHashTable
(bucketIdx [k])
(getBucket [k])
(setBucket [k v])
(insert [k v])
(lookup [k]))
(deftype HashTable
[buckets size]
IHashTable
(bucketIdx [_ k] (mod (hash k) size))
(getBucket [this k] (aget buckets (.bucketIdx this k)))
(setBucket [this k v] (aset buckets (.bucketIdx this k) v))
(insert [this k v]
(.setBucket this k (Node. k v nil)))
(lookup [this k]
(when-let [node (.getBucket this k)]
(.getVal node))))できました。これでキーと値のペアを取り出すことができます。
=> (.lookup hash-table "foo")
"bar"ハッシュテーブルを定義する時、sizeの値を使って4としました。なぜこの処理が重要なのでしょう。これは、バケット配列の要素数にも同じsizeの値を指定することで、ハッシュテーブルをバケット配列の長さで固定するためです。下部配列が一杯になるまでは、この設計で問題ありません。でも、その後はどうなるのでしょうか?
衝突
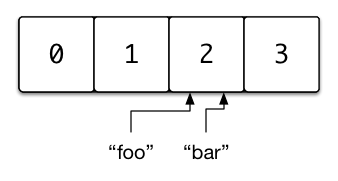
2つのキーが同じインデックスにハッシュされた状態を 衝突 と言います。ハッシュテーブルを扱う場合、衝突を回避する処理は避けて通れません。今回の実装では 連鎖法 と呼ばれる手法を用いますが、代わりに 開番地法 を採用することも可能です。これら2つをベースにした他の手法もありますが、この記事では扱いません。
現状では、2つのキーがハッシュテーブルで衝突を起こすと、ノードは上書きされて古いキーと値のペアは失われてしまいます。これは避けたい事態です。しかし実は、バケットに格納する値として連結リストを選んだのはこの問題への布石だったのです。
連結リストを使うと、なぜ衝突が回避できるのでしょうか。それは、衝突が起こると分かった時点で同じバケット上に新しいノードを追加できるからです。連結リストなら簡単にプリペンドできますからね。つまり、バケットにすでにノードが格納されている場合は、 cons 関数を用いてそのバケットに新しいノードを構成すればいいのです。この変更にともない lookup メソッドの処理も少し変え、指定されたバケット内のノードを1つずつ参照するように修正する必要があります。
では実際にコードを修正してみましょう。
(definterface IHashTable
(findNode [k])
(insert [k v])
(lookup [k]))
(deftype HashTable
[buckets size]
IHashTable
...
(findNode [this k]
(when-let [bucket (.getBucket this k)]
(loop [node bucket prev nil]
(if (or (nil? node) (= (.getKey node) k))
(vector prev node)
(recur (.getNext node) node)))))
(insert [this k v]
(let [[prev node] (.findNode this k)]
(cond
;; 1. bucket contains a linked list but not our key,
;; set the next node
(and prev (nil? node)) (.setNext prev (Node. k v nil))
;; 2. bucket contains a linked list and our key, reset
;; value
node (.setVal node v)
;; 3. bucket is empty, create a new node and set the
;; bucket
:else (.setBucket this k (Node. k v nil)))))
(lookup [this k]
(let [[_ node] (.findNode this k)]
(when node
(.getVal node)))))これでハッシュの衝突を回避できました。 cons 関数を使ってバケットに新しいノードを構成するというアイデアがきちんと実装できています。また、 findNode というヘルパーメソッドも追加されました。このメソッドは、あるキーを指定するとバケット配列の中からそのキーを探しにいきます。もし該当があれば、そのキーを含んだノードと、存在すれば1つ前のノードを返します。こうして得た「1つ前のノード」と「キーを含むノード」の組み合わせから、 insert メソッドのスコープ内で、以下のどのケースに該当するかを判別します。
-
前ノードがあってノードがない場合。バケットは占有されているが指定したキーは存在していないということが分かります。この場合
cons関数を用いて、バケットに新しいノードを構成します。 -
ノードがある場合。これは、バケットの連結リストの中にキーがすでに存在しているということなので、ノードの中の値を更新します。
-
バケットが空で、キーが存在していない場合。キーと値を含んだ新しいノードをバケットに設定して、次ノードにポイントします。
ここまでの実装にはまだ問題があります。この実装の続きは 原文 からどうぞ。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事