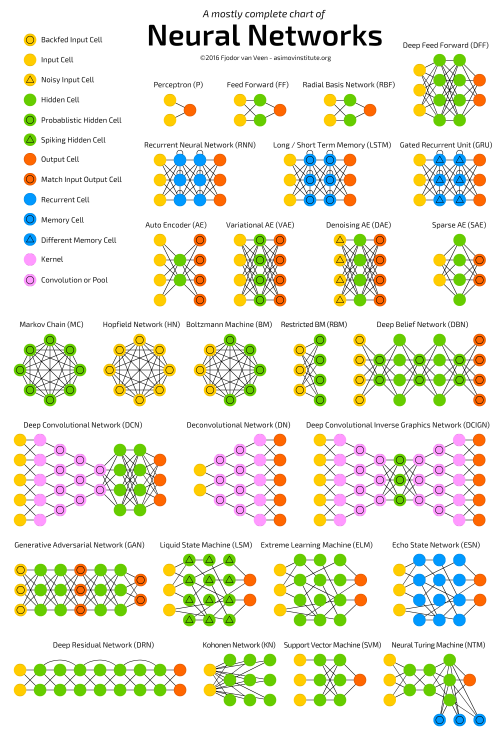
2014年6月17日
機械学習アルゴリズムへの招待

(2013-11-25)by Jason Brownlee
本記事は、原著者の許諾のもとに翻訳・掲載しております。
機械学習の問題 については以前に紹介したので、次はどんなデータを収集し、どんな機械学習アルゴリズムを使うことができるのかを見ていきましょう。本投稿では、現在よく使用されている代表的なアルゴリズムを紹介します。代表的なアルゴリズムを知ることで、どんな技法が使えるかという全体的なイメージもきっとつかめてくるはずですよ。
アルゴリズムには多くの種類があります。難しいのは、技法にも分類があり拡張性があるため、規範的なアルゴリズムを構成するものが何なのか判別するのが難しいということですね。ここでは、実際の現場でも目にする機会の多いアルゴリズムを例にとって、それらを検討して分類する2つの方法をご紹介したいと思います。
まず1つ目は、学習のスタイルによってアルゴリズムを分ける方法。そして2つ目は、形態や機能の類似性によって(例えば似た動物をまとめるように)分ける方法です。どちらのアプローチも非常に実用的だと思います。
学習スタイル
アルゴリズムが、入力データ(経験や環境と呼んでもいいし、その他の呼び方もあるかと思います)との相互作用をベースに問題をモデル化する方法にはいくつかの方法があります。機械学習や人工知能の参考書でよく言われるのは、まずはアルゴリズムの持つ学習スタイルを考えてみましょう、ということです。
アルゴリズムの主な学習スタイル(あるいは学習モデル)は、ほんの数種類しかありません。以下に、それらの学習スタイルを、それぞれにマッチしたアルゴリズムと問題タイプの例と共にご紹介したいと思います。機械学習アルゴリズムをこのように組織的に分類する方法はとても有用です。入力データの役割やモデル生成プロセスについて考えることにつながるし、問題に対してベストな結果を得るために何が最適な方法なのかを選択する手助けにもなりますよ。
-
教師あり学習法: 入力データは訓練データと呼ばれ、ラベル付けされているか、あるいは既知の結果(例えば“スパム/非スパム“やある時点での株価など)を有しています。モデルは訓練プロセスで予測をしながら生成され、その過程で予測に間違いがあれば都度訂正されていきます。この訓練プロセスは、訓練データが十分に収集されモデルの正確性が満足のいくレベルになるまで続けられます。問題の例として挙げられるのは分類や回帰などですね。アルゴリズムの例としてはロジック回帰、バックプロパゲーション・ニューラルネットワークが挙げられるでしょう。
-
教師なし学習法: 入力データはラベル付けされておらず、既知の結果も有していません。モデルは入力データに存在する構造を抽出して生成されます。問題の例としては相関ルール学習やクラスタリング。アルゴリズムの例としてはアプリオリ・アルゴリズムやK平均法が挙げられます。
-
半教師あり学習: 入力データはラベル付きの例とラベルなしの例が混在しています。モデルは予測すべき問題がある一方で、ラベルなしのデータを新たに組織化し学習して、予測に反映させなければなりません。問題の例は分類や回帰、そしてアルゴリズムの例としては、ラベルなしのデータをモデル化する方法について仮定を立てる別種の柔軟な技法の拡張といったところでしょうか。
-
強化学習: 入力データは一種の刺激として、環境からモデルに対して供給されます。この時、モデルは環境に回答・反応しなければなりません。フィードバックは、教師あり学習法のような訓練プロセスからではなく、環境から報酬・罰則という形で与えられます。問題の例としてはシステムやロボット制御、アルゴリズムの例としてはQ学習やTD学習が挙げられます。
一般的に、データを通してビジネス上の決定事項をモデル化するなら教師あり学習法や教師なし学習法が向いているでしょう。一方で、その時点の最大の関心事が対象であれば、半教師あり学習がいいと思います。例えば、ラベル付きの例が限られた非常に大きなデータセットを扱う画像分類のような場合ですね。強化学習については、ロボット制御やその他の制御システム開発などの分野で広く使われています。
アルゴリズムの類似性
アルゴリズムが機能や形式の観点から類似しているグループに分類されているのをよく目にしますね。例えば木構造やニューラルネットワークなどです。なかなか便利な分類方法ですが、完璧とは言えません。アルゴリズムによっては簡単に複数のグループに分類されてしまう場合もあるからです。例えば「学習ベクトル量子化法(LVQ)」はニューラルネットワークにも、インスタンスベース法にも分類できます。またグループによっては1つの名称が、問題そのものとアルゴリズムのクラス両方を指す場合があります。「回帰」や「クラスタリング」などがそうです。ですから、どのソースを見るかによってアルゴリズムのグループ分けにも様々なバリエーションがあります。機械学習アルゴリズム自体にも、完璧なモデルというのはなく、まあ十分と言えるようなモデルしかないのと同じことです。
この項では機械学習アルゴリズムのポピュラーなものを直観的に分類して記載します。グループもアルゴリズムも全てが網羅されているわけではありません。しかし代表的なものばかりですし、現状を把握するには役立つのではないかと思います。もしご存知のアルゴリズムやグループが入っていなかったら、ぜひコメント欄でお知らせくだい。では始めましょう。
回帰法
回帰とは、2つの変数間の関係をモデル化し、誤差の測度を用いて繰り返し精度を上げていく手法です。回帰法は統計の分野でよく使われており、統計的機械学習にも取り入れられてきました。ややこしいのですが「回帰」は問題のクラスのことも、アルゴリズムのクラスのことも指します。実際のところ回帰とはプロセスです。いくつか回帰法に分類されるアルゴリズムの例を挙げます。
- 最小二乗法(OLS)
- ロジスティック回帰
- ステップワイズ回帰
- 多変量適応回帰スプライン(MARS)
- LOESS
インスタンスベースの方法
インスタンスベースの学習モデルは、重要または必要とみなされる訓練データのインスタンスや例を用いた決定問題です。よく用いられる手法としては実例データのデータベースを構築し、類似性速度を用いて新しいデータとの比較を行います。こうして最適な適合を見つけ予測を行います。このため、インスタンスベース学習は勝者総取りの方法とか、メモリベースの学習などとも呼ばれることがあります。格納されたインスタンスの表現とインスタンス間で使用される類似性速度とに焦点が置かれています。
- K近傍法(k-NN)
- 学習ベクトル量子化(LVQ)
- 自己組織化マップ(SOM)
正則化法
他の方法(主に回帰法)を拡張した手法です。複雑なモデルに罰金項を課し、シンプルで一般化しやすいモデルを支持します。正則化法をリストに加えたのは、人気も高く有用で、他の方法に対してシンプルな変更を加えたものばかりだからです。
- リッジ回帰
- LASSO
- エラスティックネット
決定木学習
決定木ではデータ属性の実価に基づいた決定モデルを構築します。特定のレコードに対して予測判定が下されるまで、木構造の中で決定が分岐していきます。決定木は、分類と回帰のデータを対象とします。
- 分類木と回帰木(CART)
- ID3
- C4.5
- CHAID
- 決定株
- ランダムフォレスト
- 多変量適応回帰スプライン(MARS)
- 勾配ブースティングマシン(GBM)
ベイズ法
ベイズ法はその名前の通り、分類や回帰問題などのためにベイズの定理を適用している手法です。
- ナイーブベイズ
- AODE
- ベイジアン信念ネットワーク(BBN)
カーネル法
カーネル法は、サポートベクターマシンと良く組み合わされることで知られています。サポートベクターマシン自体が一連の手法です。カーネル法では分類問題や回帰問題がよりモデル化しやすいよう、データを高次元のベクトル空間上へ写像します。
- サポートベクターマシン(SVM)
- 放射基底関数(RBF)
- 線形判別分析(LDA)
クラスタリング手法
回帰法もそうでしたが、クラスタリングも問題のクラスと手法のクラス両方を指します。クラスタリング手法は一般的にモデル化アプローチ、つまり重心法や階層的手法などによって分類されています。すべての手法はデータの内在構造を用い、類似度ごとのグループにデータを分類します。
- K-平均法
- 期待値最大化(EM)
相関ルール学習
相関ルール学習とは、あるデータの変数の関係性に最もあてはまるルールを抽出する方法です。これらのルールを用いることにより、巨大な多次元のデータセットの中から、重要で商用にも役立つような関連性を発見することができます。
- アプリオリアルゴリズム
- eclatアルゴリズム
人工ニューラルネットワーク
人工ニューラルネットワークは生物の神経回路の構造や機能に触発されたモデルです。回帰と分類問題によく利用されるパターンマッチングのクラスですが、実際には、あらゆる問題タイプのバリエーションと何百ものアルゴリズムから成る巨大な部分体です。昔から人気の高い定番の手法を次に挙げます(深層学習は別の項目にしたので含めていません)。
- パーセプトロン
- バックプロパゲーション
- ホップフィールド・ネットワーク
- 自己組織化マップ(SOM)
- 学習ベクトル量子化(LVQ)
深層学習
人工ニューラルネットワークに更新を加えて、潤沢で低価格なコンピュータによる計算を活用しているのが深層学習です。さらに広大で複雑なニューラルネットワークを構築します。膨大なデータセットに対してラベル付きデータしか少ししか含まれない時などに、半教師あり学習問題で利用されています。
- 制限付きボルツマンマシン(RBM)
- ディープビリーフネット(DBN)
- 畳み込みネットワーク
- Stackedオートエンコーダ
次元削減
次元削減法はクラスタリング手法と同じようにデータの内在構造を探して活用します。この場合は教師なし学習や、より少ない情報でデータを表現したり要約したりするのに用いられます。寸法諸元を画像化しデータを単純化するのに有用で、そのケースでは教師あり学習にも用いることができます。
- 主成分分析(PCA)
- 部分最小二乗回帰(PLS)
- サモンマッピング
- 多次元尺度法(MDS)
- 射影追跡
アンサンブル法
アンサンブル法は、独立して訓練されている複数の弱い学習モデルを組み合わせて、個々の予測を統合して全体予測とする手法です。どのタイプの弱学習器をどのように統合するかという点に注力されています。とても効果が高い学習モデルですから非常によく利用されています。
- ブースティング
- バギング
- エイダブースト
- Stacked Generalization(blending)
- 勾配ブースティングマシン(GBM)
- ランダムフォレスト

アンサンブル法の最良適合のグラフの例。弱学習器はグレー、統合予測は赤で示されている。気温とオゾンのデータが表示され、LOESSによって用意したモデルがプロットされている。
画像はパブリックドメインで、Wikipediaより引用しています。
参考資料
この記事では、機械学習アルゴリズムの概要とこの先必要になるかもしれないツールについてざっと触れてきました。
参考資料として機械学習アルゴリズムの膨大なリストを他にもご紹介しましょう。想定内かもしれませんが、うんざりしないでくださいね。多くのアルゴリズムについて知っている方がもちろん便利ですが、効果的に数種類の重要な手法について深い知識を持っていることも、非常に有用なことです。
- 機械学習アルゴリズムのリスト :Wikipedia(英語版)です。かなり大規模ですが、このリストやアルゴリズムの整理法は取り立てて有用ではなさそうです。
- 機械学習アルゴリズムカテゴリ :これもWikipedia(英語版)です。上記の立派なリストよりは少しだけ使えそうです。アルファベット順にアルゴリズムが整理されています。
- CRANタスクビュー:機械学習と統計学習 :Rの機械学習パッケージがサポートする全パッケージとアルゴリズムのリストです。普段分析者がどのようなものを使っているのか、実勢などについてしっかりした感覚が得られると思います。
- データマイニングのアルゴリズムトップ10 :こちらは 記事 。そして最近 本 (アフィリエイトリンクに飛びます)も出版されました。データマイニングで最も人気のあるアルゴリズムをリストしています。内容が確かで情報量も適度なので手を付けやすく、深い知識が身に付くでしょう。
記事はいかがでしたか。お役に立てばいいのですが。アルゴリズムを分類する他の良い方法や、もっとすてきな機械学習アルゴリズムのリストをご存知でしたら、ぜひコメントを残してください。
お知らせ: HackerNewsのディスカッション と reddit でご意見をどうぞ。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事