2016年8月18日
Pythonパッケージ間の共起関係を可視化してみる
本記事は、原著者の許諾のもとに翻訳・掲載しております。
はじめに
私は、 BigQueryのGitHubデータ を使って、GitHubリポジトリにある上位3,500個のPythonパッケージの共起を抽出し、 速度ベルレ積分を使ってd3のForceレイアウト を可視化してみました。また、 python-igraph にあるアルゴリズムを使ってグラフをクラスタ化し、 http://graphistry.com/ にアップデートしました。
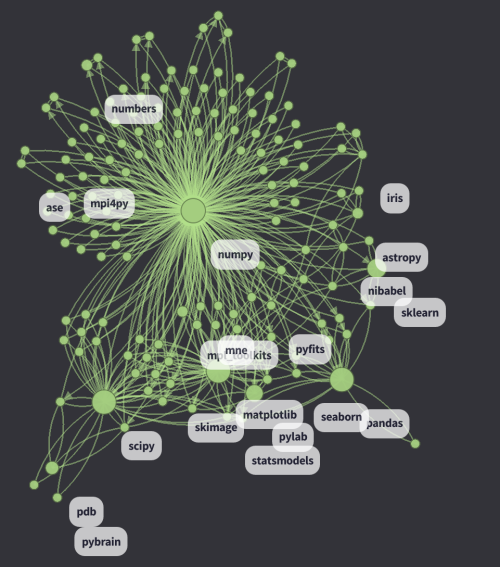
以下のスクリーンショットは、d3の可視化にあるNumPyのクラスタです(画像をクリックするとライブ版をご覧いただけます)。
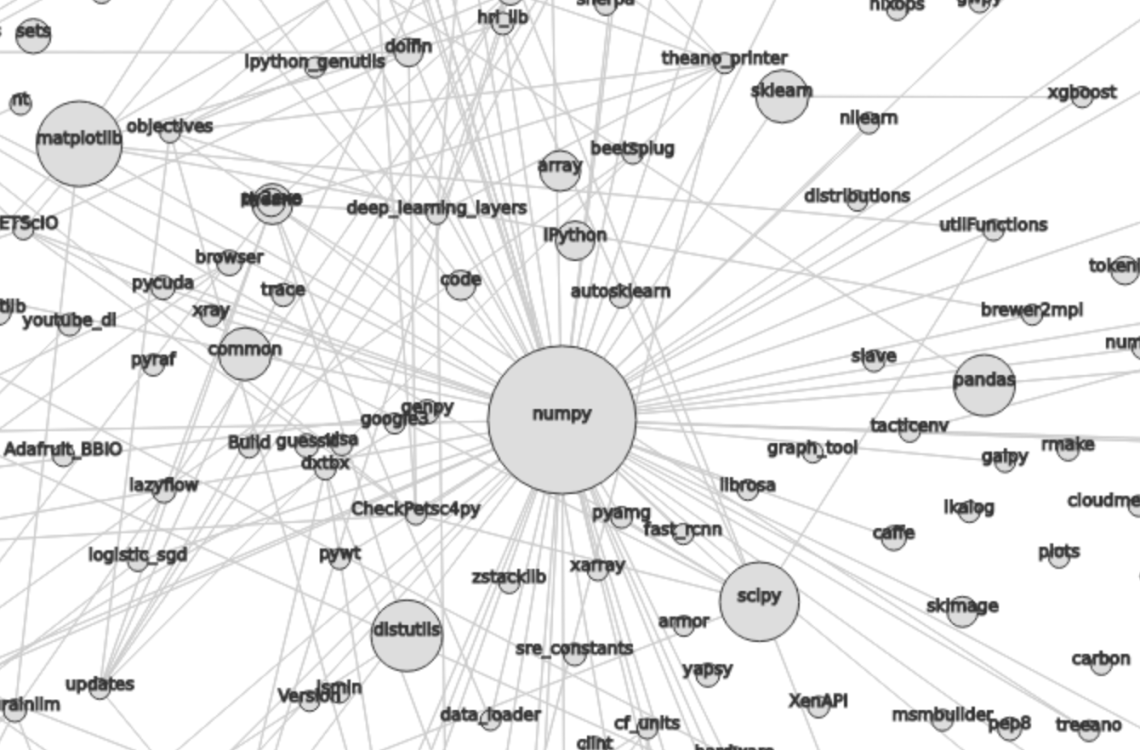
以下は、graphistrynによって抽出されたNumPyのクラスタです(画像をクリックするとライブ版をご覧いただけます)。 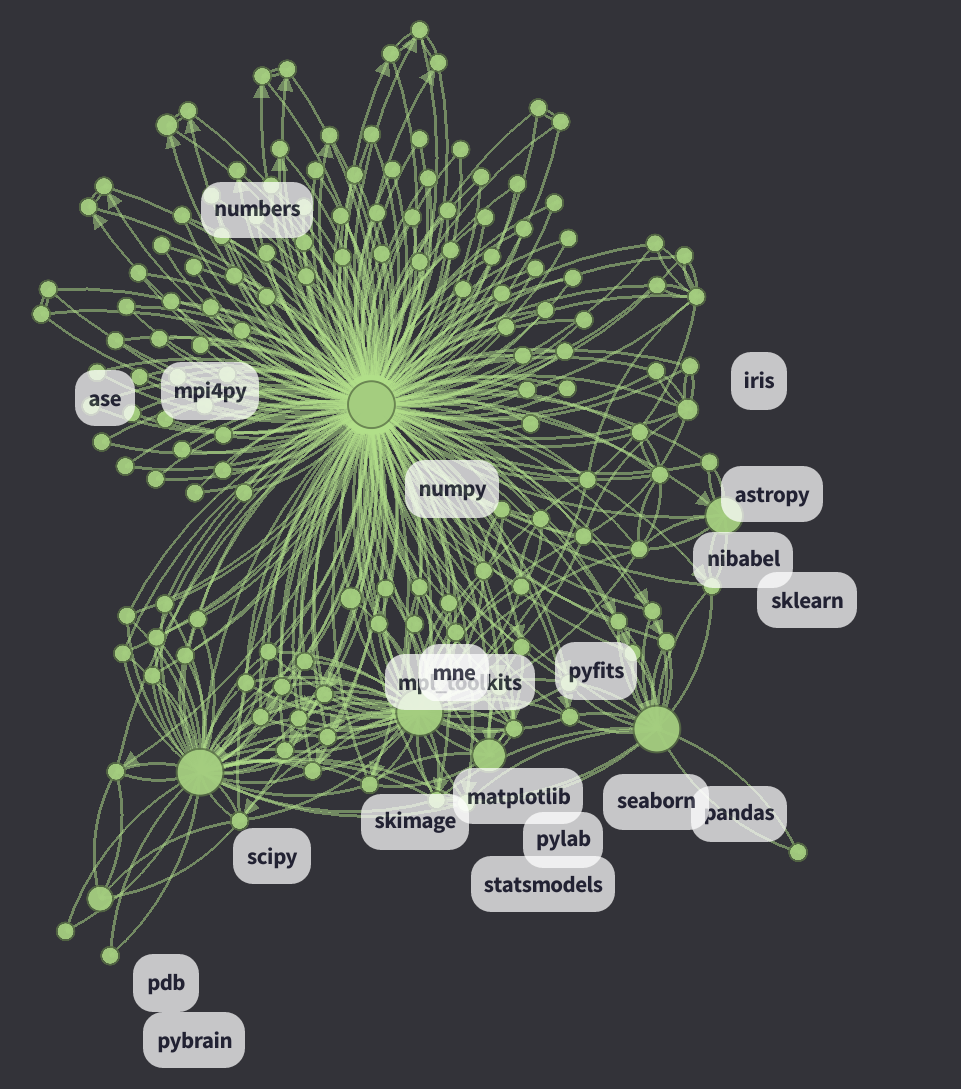
グラフの特徴:
- 各ノードは、GitHubで見つけることのできる、それぞれのPythonパッケージです。半径は、 ノードのDataFrame セクションで計算されています。
- AとBの2つのパッケージ間において、エッジの重みは
で、
は同じファイル内にあるパッケージAとBの発生頻度を現しています。BigQueryを使って計算することは困難なので、これをすぐに Normalized Pointwise Mutual Information (npmi) に移行します。
- 0.1よりも小さい重みのエッジは、削除します。
- d3のアルゴリズムは、 シミュレーションパラメータ に従って、速度ベルレ積分により最小限のエネルギー状態を検索します。
私のアプリケーションは、 http://clustering.kozikow.com/?center=numpy でご覧いただくことができます。以下のことが可能です。
- URL内で、クエリの引数として異なるパッケージ名を渡すことができる。
- ページを上下左右にスクロールすることができる。
- ノードをクリックしてPyPIを開くことができます。ただし、全てのパッケージがPyPIにあるわけではない。
graphistryのビューで興味深いものについては、次のセクションである 特定のクラスタの分析 でご紹介します。
グラフの可視化は、見た目が恰好いいということを除いては、時に実用的な洞察を得られないこともあります。使用できる実用的な洞察は以下のとおりです。
- 使用している他のパッケージの近くにある、認識できていないパッケージを見つける。
- サイズや採択、ライブラリ化ができるかどうかによって、異なるWeb開発フレームワークを評価する(例えば Flask 対 django )。
- roboticのクラスタ といったような、面白いPythonのユースケースを見つける。
この投稿の編集履歴はgithubで閲覧可能 であり、これは org mode になっています。
特定のクラスタの分析
d3の可視化結果に加え、更に python-igraph にある community_infomap().membership を使ってデータをクラスタ化し、それをgraphistryにアップロードしました。クラスタによる除外機能やフィルタ機能は、とても便利です。
科学計算クラスタ
当然のことですが、それはNumPyが中心です。面白いことに、統計学とマシンラーニングでは相違が見られます。
Webフレームワークのクラスタ
Webフレームワークは興味深い機能群です。
d3のリンク
- sqlalchemy は、Webフレームワークの中心と言うことができるでしょう。
- 近くには、 django に向かう、比重が大きくて巨大なクラスタがあります。
- 近くには、 flask と pyramid に向かう、より小さなクラスタがあります。
- djangoとsqlalchemyの間には、それ自身のクラスタが欠けている pylons があります。
- sqlachemyの近くにも、 zope に向かう、小さなクラスタがあります。
- 真ん中には、標準ライブラリの大きなクラスタによって吸収された tornado がありますが、依然として他のWebフレームワークに隣接しています。
- gluon(web2py) や turbo gears といった小さなWebフレームワークは、最終的にgyangoの近くで終了していますが、それらのクラスタなしでは、はっきりと確認することができません。
興味深いgraphistryのクラスタ
その他の興味深いクラスタ
クラスタ化のアルゴリズムの結果を見てみると、”中間サイズ”のクラスタだけに興味を引き付けられます。真っ先に目を引くことが明らかなものを挙げると、osやsysのようなパッケージが多数を占めるクラスタです。クラスタが非常に小さいと、これに興味を引き付けられることはありません。 こちらの図は、サイズが5~30のクラスを表示させたものです 。
以下にその他のクラスタを記載しておきました。
- テストのクラスタ: d3のリンク 、 graphistryのクラスタ
- OpenStackのクラスタ: d3のリンク 、 graphistryのリンク
- 文字列の構文解析とフォーマットのクラスタ
- Robotics
- ゲーミングのクラスタ
- ディープラーニングのクラスタ
更なる分析の可能性
他のプログラミング言語
今回のコードの大部分は、Phytonに特化したものではありません。最初のステップである パッケージでテーブルを作成する だけがPhytonに特化したコードです。
グラフの見栄えが良くなるように、 シミュレーションパラメータ でパラメータを調整するのに相当な時間を費やしました。各言語のグラフは、異なる特徴を持っているので、恐らく、他の各言語に対しても同様の適合を行う必要があるのでしょう。
この次にはJavaとScalaの分析を行おうと思います。
seaborn対bokehなど、”パッケージXに対する代替え案”の探索
例えば、Pythonの可視化データパッケージを全て一緒にクラスタ化したら面白いのではないでしょうか。
直観的に、このようなパッケージは似たようなコンテキストで使用されますが、一緒に使用されることはあまりありません。「グラフはNpmiの同時発生行列Mで表現される」と仮定すると、パッケージxとyにおいては、ベクトルxとyの相関性は高くなりますが、M[x][y]は低くなるでしょう。
あるいは、 M^2 /. M にも可能性があるかもしれません。 /. は要素ごとの商で、 M^2 は、グラフ上で”2つのホップ”を大まかに表現しています。
隣同士の重みだけでも相関性は高いのですが、直接的なエッジは低くなります。
これは、多くの状況で機能しますが、うまく機能しない場合もあります。以下がその例です。
- sqalchemyはdjangoのビルトインORMの代替
- django ORMはdjangoだけで使われている
- django ORMがflaskのような他のWebフレームワークの使用に適していない
- 他のWebフレームワークがflask ORMを乱用していて、djangoのビルトインORMではない
従って、django ORMとsqlalchemyは近隣の重み付けが相関されることはありません。私はあまりWeb開発を行わないので、ORMの詳細が間違っている可能性はあります。
また、 node2ved の実験や、隣接行列の2乗を行う予定です。
リポジトリの関連性
現在、私は同じファイル内でのインポートだけを見ています。”同じリポジトリ内”の関連性を使って構築した同じグラフを見たり、”同じリポジトリ内”と”同じファイル内”の関連性を体系的に比較してみたりするのも面白いと思います。
PyPIとの連結
PyPIダウンロードとGitHub上の使用量を比較しても面白いでしょう。 PyPIはBigQueryからもアクセスが可能です 。
データ
- d3によって使用されたJSONの後処理データ
- 一般公開されている全てのデータのBigQueryテーブル 。各テーブルがどのように生成されているかは、再作成のセクションをご覧ください。
再作成するステップ
BigQueryからのデータ抽出
パッケージを使用したテーブル作成
以下のコードを、wide-silo-135723:github_clustering.packages_in_file_pyに保存します。
SELECT
id,
NEST(UNIQUE(COALESCE(
REGEXP_EXTRACT(line, r"^from ([a-zA-Z0-9_-]+).*import"),
REGEXP_EXTRACT(line, r"^import ([a-zA-Z0-9_-]+)")))) AS package
FROM (
SELECT
id AS id,
LTRIM(SPLIT(content, "\n")) AS line,
FROM
[fh-bigquery:github_extracts.contents_py]
HAVING
line CONTAINS "import")
GROUP BY id
HAVING LENGTH(package) > 0;このSQLにより生成されるテーブルは、2つのフィールドを持ちます。つまり、ファイルを示すidと、1つのファイル内にあるパッケージによる繰り返しのフィールドです。繰り返しのフィールドは、配列に似ています。 このページに、繰り返しのフィールドのベストな表現を見付けました 。
このステップのみpython特有のものです。
packages_in_file_pyのテーブルを実証
いくつか ファイルを無作為に選び 、インポートがここまで正しくパースされているか確認してください。
SELECT
GROUP_CONCAT(package, ", ") AS packages,
COUNT(package) AS count
FROM [wide-silo-135723:github_clustering.packages_in_file_py]
WHERE id == "009e3877f01393ae7a4e495015c0e73b5aa48ea7"| packages | count |
|---|---|
| distutils, itertools, numpy, decimal, pandas, csv, warnings, future , IPython, math, locale, sys | 12 |
人気のないパッケージをフィルタリング
SELECT
COUNT(DISTINCT(package))
FROM (SELECT
package,
count(id) AS count
FROM [wide-silo-135723:github_clustering.packages_in_file_py]
GROUP BY 1)
WHERE count > 200;少なくとも200回出現するパッケージが3,501個あり、そこで頭打ちとなるようです。フィルタリングされたテーブル、wide-silo-135723:github_clustering.packages_in_file_top_pyを作成します。
SELECT
id,
NEST(package) AS package
FROM (SELECT
package,
count(id) AS count,
NEST(id) AS id
FROM [wide-silo-135723:github_clustering.packages_in_file_py]
GROUP BY 1)
WHERE count > 200
GROUP BY id;結果は、「wide-silo-135723:github_clustering.packages_in_file_top_py」に格納されます。
SELECT
COUNT(DISTINCT(package))
FROM [wide-silo-135723:github_clustering.packages_in_file_top_py];3501グラフのエッジを生成
では、エッジを生成してテーブル「wide-silo-135723:github_clustering.packages_in_file_edges_py」に保存します。
SELECT
p1.package AS package1,
p2.package AS package2,
COUNT(*) AS count
FROM (SELECT
id,
package
FROM FLATTEN([wide-silo-135723:github_clustering.packages_in_file_top_py], package)) AS p1
JOIN
(SELECT
id,
package
FROM [wide-silo-135723:github_clustering.packages_in_file_top_py]) AS p2
ON (p1.id == p2.id)
GROUP BY 1,2
ORDER BY count DESC;上位10個のエッジは以下のSQLで求められます。
SELECT
package1,
package2,
count AS count
FROM [wide-silo-135723:github_clustering.packages_in_file_edges_py]
WHERE package1 < package2
ORDER BY count DESC
LIMIT 10;| package1 | package2 | count |
|---|---|---|
| os | sys | 393311 |
| os | re | 156765 |
| os | time | 156320 |
| logging | os | 134478 |
| sys | time | 133396 |
| re | sys | 122375 |
| __future__ | django | 119335 |
| __future__ | os | 109319 |
| os | subprocess | 106862 |
| datetime | django | 94111 |
必要の無いエッジをフィルタリング
エッジの重みの分位は以下のように求めます。
SELECT
GROUP_CONCAT(STRING(QUANTILES(count, 11)), ", ")
FROM [wide-silo-135723:github_clustering.packages_in_file_edges_py];1, 1, 1, 2, 3, 4, 7, 12, 24, 70, 1005020最初の実行時には、全てのカウントに基づいてエッジをフィルタリングしました。これは良いアプローチではありませんでした。極端に小さいパッケージ間にある強い関連性よりも、大きなパッケージ2つの間にある弱い関連性の方が、残ってしまう傾向があるためです。
wide-silo-135723:github_clustering.packages_in_file_nodes_pyを作成します。
SELECT
package AS package,
COUNT(id) AS count
FROM [github_clustering.packages_in_file_top_py]
GROUP BY 1;| package | count |
|---|---|
| os | 1005020 |
| sys | 784379 |
| django | 618941 |
| __future__ | 445335 |
| time | 359073 |
| re | 349309 |
テーブルpackages_in_file_edges_top_pyを作成します。
SELECT
edges.package1 AS package1,
edges.package2 AS package2,
# WordPress gets confused by less than sign after nodes1.count
edges.count / IF(nodes1.count nodes2.count,
nodes1.count,
nodes2.count) AS strength,
edges.count AS count
FROM [wide-silo-135723:github_clustering.packages_in_file_edges_py] AS edges
JOIN [wide-silo-135723:github_clustering.packages_in_file_nodes_py] AS nodes1
ON edges.package1 == nodes1.package
JOIN [wide-silo-135723:github_clustering.packages_in_file_nodes_py] AS nodes2
ON edges.package2 == nodes2.package
HAVING strength > 0.33
AND package1 <= package2;googleドキュメントに全ての結果を保存しておきました 。
Pandasからjsonへのデータ処理
csvのロードと、pandasによるエッジの実証
import pandas as pd
import math
df = pd.read_csv("edges.csv")
pd_df = df[( df.package1 == "pandas" ) | ( df.package2 == "pandas" )]
pd_df.loc[pd_df.package1 == "pandas", "other_package"] = pd_df[pd_df.package1 == "pandas"].package2
pd_df.loc[pd_df.package2 == "pandas", "other_package"] = pd_df[pd_df.package2 == "pandas"].package1
df_to_org(pd_df.loc[:,["other_package", "count"]])
print "\n", len(pd_df), "total edges with pandas"| other_package | count |
|---|---|
| pandas | 33846 |
| numpy | 21813 |
| statsmodels | 1355 |
| seaborn | 1164 |
| zipline | 684 |
| 他11行 |
Pandasによって、合計16個のエッジが求められました。
ノードによるDataFrame
nodes_df = df[df.package1 == df.package2].reset_index().loc[:, ["package1", "count"]].copy()
nodes_df["label"] = nodes_df.package1
nodes_df["id"] = nodes_df.index
nodes_df["r"] = (nodes_df["count"] / nodes_df["count"].min()).apply(math.sqrt) + 5
nodes_df["count"].apply(lambda s: str(s) + " total usages\n")
df_to_org(nodes_df)| package1 | count | label | id | r |
|---|---|---|---|---|
| os | 1005020 | os | 0 | 75.711381704 |
| sys | 784379 | sys | 1 | 67.4690570169 |
| django | 618941 | django | 2 | 60.4915169887 |
| __future__ | 445335 | __future__ | 3 | 52.0701286903 |
| time | 359073 | time | 4 | 47.2662138808 |
| 他3460行 |
ノード名 -> idのマッピングを生成
id_map = nodes_df.reset_index().set_index("package1").to_dict()["index"]
print pd.Series(id_map).sort_values()[:5]os 0
sys 1
django 2
__future__ 3
time 4
dtype: int64エッジのデータフレームを生成
edges_df = df.copy()
edges_df["source"] = edges_df.package1.apply(lambda p: id_map[p])
edges_df["target"] = edges_df.package2.apply(lambda p: id_map[p])
edges_df = edges_df.merge(nodes_df[["id", "count"]], left_on="source", right_on="id", how="left")
edges_df = edges_df.merge(nodes_df[["id", "count"]], left_on="target", right_on="id", how="left")
df_to_org(edges_df)
print "\ndf and edges_df should be the same length: ", len(df), len(edges_df)| package1 | package2 | strength | count_x | source | target | id_x | count_y | id_y | count |
|---|---|---|---|---|---|---|---|---|---|
| os | os | 1.0 | 1005020 | 0 | 0 | 0 | 1005020 | 0 | 1005020 |
| sys | sys | 1.0 | 784379 | 1 | 1 | 1 | 784379 | 1 | 784379 |
| django | django | 1.0 | 618941 | 2 | 2 | 2 | 618941 | 2 | 618941 |
| __future__ | __future__ | 1.0 | 445335 | 3 | 3 | 3 | 445335 | 3 | 445335 |
| os | sys | 0.501429793505 | 393311 | 0 | 1 | 0 | 1005020 | 1 | 784379 |
| 他11117行 |
dfとedges_dfは、同じ長さになるはずです。つまり、11122と11122です。
逆方向のエッジを追加
edges_rev_df = edges_df.copy()
edges_rev_df.loc[:,["source", "target"]] = edges_rev_df.loc[:,["target", "source"]].values
edges_df = edges_df.append(edges_rev_df)
df_to_org(edges_df)| package1 | package2 | strength | count_x | source | target | id_x | count_y | id_y | count |
|---|---|---|---|---|---|---|---|---|---|
| os | os | 1.0 | 1005020 | 0 | 0 | 0 | 1005020 | 0 | 1005020 |
| sys | sys | 1.0 | 784379 | 1 | 1 | 1 | 784379 | 1 | 784379 |
| django | django | 1.0 | 618941 | 2 | 2 | 2 | 618941 | 2 | 618941 |
| __future__ | __future__ | 1.0 | 445335 | 3 | 3 | 3 | 445335 | 3 | 445335 |
| os | sys | 0.501429793505 | 393311 | 0 | 1 | 0 | 1005020 | 1 | 784379 |
| 他22239行 |
エッジDataFrameの切り捨て
edges_df = edges_df[["source", "target", "strength"]]
df_to_org(edges_df)| source | target | strength |
|---|---|---|
| 0.0 | 0.0 | 1.0 |
| 1.0 | 1.0 | 1.0 |
| 2.0 | 2.0 | 1.0 |
| 3.0 | 3.0 | 1.0 |
| 0.0 | 1.0 | 0.501429793505 |
| 他22239行 |
ブラウザ上でシミュレーションを実行した後、座標を保存
全体のシミュレーションは、安定するまで1分かかります。単純に画像をダウンロードすることは出来ますが、その場合はノードを押すとPyPIを開くといったような、追加の機能はありません。
次のコードで、javascriptコンソールからシミュレーション後のすべての座標をダウンロードします。
var positions = nodes.map(function bar (n) { return [n.id, n.x, n.y]; })
JSON.stringify()座標xとyをエッジのデータフレームに結合すると、d3に渡すことができます。
pos_df = pd.read_json("fixed-positions.json")
pos_df.columns = ["id", "x", "y"]
nodes_df = nodes_df.merge(pos_df, on="id")ノードDataFrameの切り捨て
# cは、衝突の強度。ラベルの重複を防ぐ。
nodes_df["c"] = pd.DataFrame([nodes_df.label.str.len() * 1.8, nodes_df.r]).max() + 5
nodes_df = nodes_df[["id", "r", "label", "c", "x", "y"]]
df_to_org(nodes_df)| id | r | label | c | x | y |
|---|---|---|---|---|---|
| 0 | 75.711381704 | os | 80.711381704 | 158.70817237 | 396.074393369 |
| 1 | 67.4690570169 | sys | 72.4690570169 | 362.371142521 | -292.138913114 |
| 2 | 60.4915169887 | django | 65.4915169887 | 526.471326062 | 1607.83507287 |
| 3 | 52.0701286903 | __future__ | 57.0701286903 | 1354.91212894 | 680.325432179 |
| 4 | 47.2662138808 | time | 52.2662138808 | 419.407448663 | 439.872927665 |
| 他3460行 |
jsonにファイルを保存
# カラムの切り捨て
with open("graph.js", "w") as f:
f.write("var nodes = {}\n\n".format(nodes_df.to_dict(orient="records")))
f.write("var nodeIds = {}\n".format(id_map))
f.write("var links = {}\n\n".format(edges_df.to_dict(orient="records")))新しいd3の速度ベルレ積分アルゴリズムを使ったグラフの描画
物理的シミュレーションSimulationは、 d3のバージョン4.0で新しく速度ベルレ積分のforce graph を利用しています。Simulationは安定するまで大体1分ほどかかります。このためグラフを表示させる目的の場合は、私は自分のマシン上でシミュレーションを実行した後で、ノードの座標をハードコードしています。
シミュレーションのコアコンポーネントは、以下の通りです。
var simulation = d3.forceSimulation(nodes)
.force("charge", d3.forceManyBody().strength(-400))
.force("link", d3.forceLink(links).distance(30).strength(function (d) {
return d.strength * d.strength;
}))
.force("collide", d3.forceCollide().radius(function(d) {
return d.c;
}).strength(5))
.force("x", d3.forceX().strength(0.1))
.force("y", d3.forceY().strength(0.1))
.on("tick", ticked);シミュレーションを再実行する場合は、以下の手順が必要です。
- pandasの処理ステップの1つ に追加された、固定の座標を削除
- javascriptファイル 内の”forces”のコメントアウト
シミュレーションパラメータ
しばらくシミュレーションパラメータを微調整してみました。かなり密度の高いグラフの”中心”では、グラフのエッジ上でクラスタ間が衝突しています。
最新のグラフからも分かるように、中心のノードはたまに重複しています。これは、グラフのエッジにおけるノード間の距離が大きいためです。
出来る限り衝突パラメータを求めさらに増加させてみましたが、それは得策ではありませんでした。潜在的には、中心に向かって重みは増します。しかしそのため、いくつかの価値ある”クラスタ”が、グラフのエッジから中心の大きな”核”に向かって集中していったのです。
複数の大きなクラスタを分離してプロットすることは、この課題を解決するのに役立ちます。
- 引力
- パッケージA、B間のエッジの重み:
- 中心に向かう重力:0.1
- パッケージA、B間のエッジの重み:
- 反発力
- ノード間の反発:-400
- ノード衝突の強度:5
その他の投稿
興味がありましたら、GitHubのデータを分析した他の記事も読んでみてください。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事







