2015年6月29日
強固なデータ・インフラストラクチャを構築するためのログの活用(デュアル書き込みがダメな理由)PART 1.

(2015-05-27)by Martin Kleppmann
本記事は、原著者の許諾のもとに翻訳・掲載しております。
これは Craft Conference 2015 で私が行った 講演 を編集して記事にしたものです。その時の 動画 と スライド もご覧頂けます。
あなたのデータベースは、どのようにして確実にデータをディスクに保存しているのでしょう? ログを使っているのです。
データベースのレプリカは、どのようにして他のレプリカと同期するのでしょう? ログを使っているのです。
Raft などの分散アルゴリズムはどのようにして合意を取っているのでしょう? ログを使っているのです。
Apache Kafka などのシステムでは、アクティビティデータはどのように記録されるのでしょう? ログを使っているのです。
あなたのアプリケーションのデータ・インフラストラクチャはどのように規模相応の堅牢性を保つのでしょうか? 答えは・・・
ログは至るところにあります。私はプレーンテキストのログファイル(syslogやlog4jのようなもの)の話をしているのではありません。追加専用の、完全に順序立った一連のレコードのことを言っているのです。これは非常にシンプルな構造なのですが、通常のデータベースに慣れている人にとっては、最初は少し変な感じがするでしょう。しかし、一度ログという視点で考えることを学んでしまえば、信頼性が高くスケーラブルで保守しやすい大規模データシステムを作ろうとした時に、多くの問題がとたんに扱いやすいものになるのです。
私はLinkedInやその他のスタートアップでスケーラブルなシステムを構築してきました。その経験に基づいて、この講演ではなぜログが良い考え方なのかを掘り下げていきたいと思います。ログを使うことで、検索インデックスやキャッシュの保守が簡単になり、不具合に直面した際にアプリケーションをよりスケーラブルで強固なものにでき、データをより豊富な分析に使えるようになります。また、競合状態や不整合などの困った問題を回避できるのです。*

注釈:強固なデータ・インフラストラクチャを構築するためのログの活用
こんにちは。 Martin Kleppmann です。私は、大規模データシステム、特にインターネット企業で見るような類いのシステムの構築に従事しています。以前はLinkedInで働いていて、 Samza というオープンソースのストリーム・プロセッシング・システムに携わっていました。
この仕事をする中で、同僚たちと私は、操作に強く、信頼性が高く、パフォーマンスの高いアプリケーションを構築する方法を1つ2つ学びました。特に、私は Jay Kreps や Chris Riccomini 、 Neha Narkhede といった素晴らしい人物たちと仕事をするようになったのですが、彼らはアプリケーションの特有のアーキテクチャ・スタイルに目をつけました。ログに基づいたスタイルで、これが素晴らしくうまくいったのです。この講演ではそのアプローチについて説明し、どのようにして多様なコンピューティングの分野で似たようなパターンが発生するのかをお見せしたいと思います。
これから私がお話しすることは、決して新しいことではありません。ずっと前からこのアイデアをご存知の方もいらっしゃるでしょう。しかしまだ十分ではなく、もっと広く知られるべき考え方だと思うのです。ある程度の規模の、複数のデータベースを使用するようなアプリケーションを作る際には、このアイデアは非常に役立つと感じて頂けると思います。

現在私はO’Reillyから出版する『 Designing Data-Intensive Applications 』という本の執筆のために長期休暇を取っています。この本は、この数十年で私たちが学んできたデータシステムについての基礎となる重要な項目を集めたもので、データベースやキャッシュ、インデックス、バッチ処理、ストリームプロセッシングなどのアーキテクチャをカバーしています。
この本は何か特定のデータベースやツールについての本ではありません。実際に使われている、あらゆるツールやアルゴリズム、それらのトレードオフや長所と短所について広範に述べたものです。この講演では、私がこの本を書くに当たって行った調査に基づいてお話しする部分もありますので、もし興味を持ってくださった方はこの本で詳細や背景について調べることが可能です。最初の7章は 初期リリース版 でご覧頂けます。
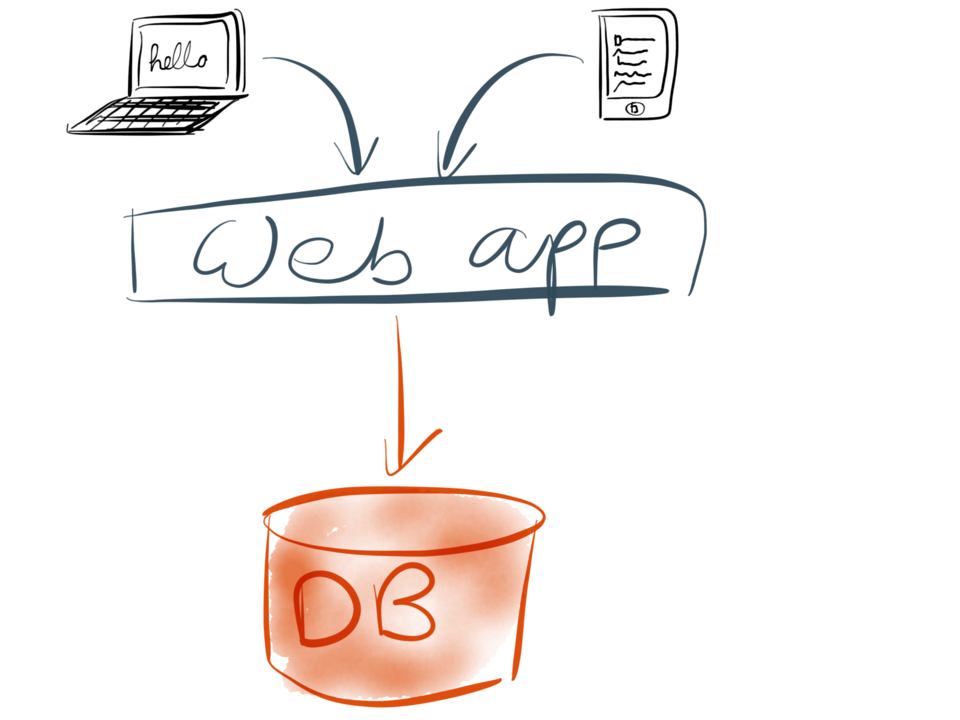
さて、話の続きです。今あなたはWebアプリケーションを構築しようとしているとしましょう。最もシンプルなケースとすると、このアプリケーションは三層アーキテクチャでしょう。つまりいくつかのクライアント(Webブラウザやモバイルアプリ、またはその両方)を持ち、それがあなたのサーバ上で走っているWebアプリケーションにリクエストを送るのです。このWebアプリケーションこそ、あなたのアプリケーションコードつまり”ビジネスのロジック”が生きてくるところです。
将来アプリケーションが何かを記憶する際には、必ずそれをデータベースに保存します。そしてアプリケーションが以前保存した何かを探す際には、必ずデータベースを検索します。このアプローチは理解が容易ですし、非常にうまくいきます。

しかし、物事はそんなに単純な状態が続くものではありません。おそらくより多くのユーザを獲得しリクエストが増えるとデータベースの処理速度が低下してしまい、スピードアップのためmemcachedやRedisか何かのキャッシュを追加することになるでしょう。もしかしたら全文検索機能を追加する必要があるかもしれません。データベースに組み込まれている基本の検索機能では不十分で、別途ElasticsearchやSolrといったインデックスサービスを設定することになるかもしれません。
もしかしたら、リレーショナルデータベースやドキュメントデータベース上では非効率な、何かしらのグラフ演算をする必要が出てくるかもしれません。例えばソーシャル機能やオススメに使いたい時などです。そこで別途グラフインデックスをシステムに追加します。ことによるとコストのかかる操作をWebのリクエストフローから非同期のバックグラウンド処理に移す必要が出てくるかもしれません。そうなれば、ジョブをバックグラウンドに送信できるようにするためメッセージキューを追加するでしょう。
そしてどんどん大変なことに…
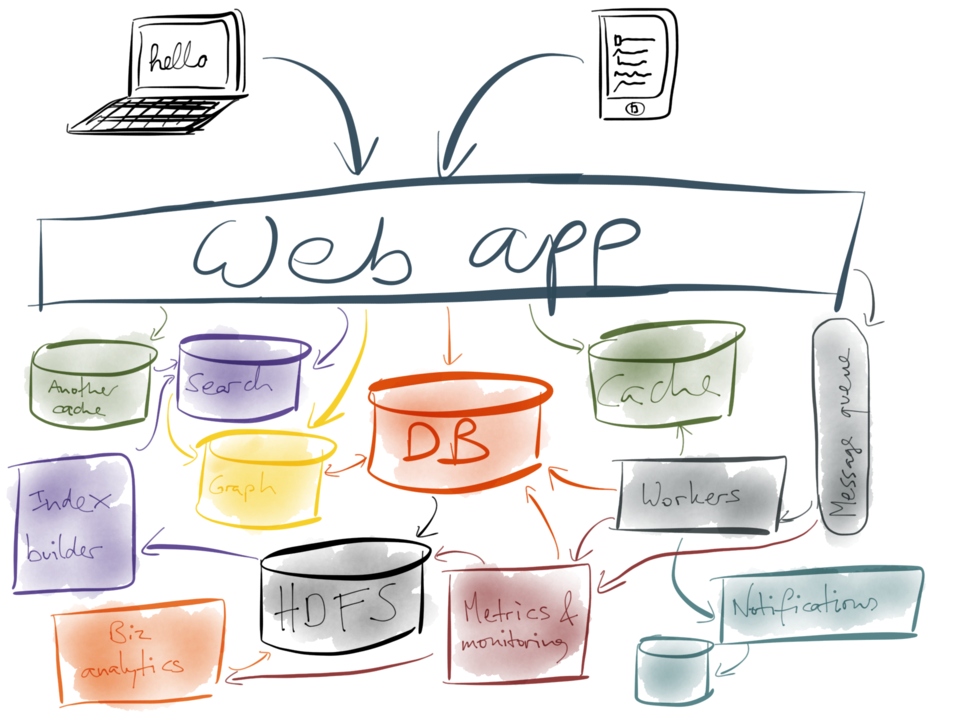
ここまでの間に、システムの他の部分の処理速度はまた遅くなってきているでしょう。ですからさらにキャッシュを追加します。キャッシュが多ければ、必ず処理は早くなりますよね? しかし今やたくさんのシステムとサービスを抱えていますから、メトリクスとモニタリングを追加して、実際にきちんと動作しているかを確認できるようにする必要があります。このメトリクスシステムもまた、更に別個の独立したシステムです。
今度はユーザにメールやプッシュ通知などの通知を送りたいと思ったとします。そこでバックグラウンドワーカに送るジョブキューに並べて通知システムをつなぎます。そうなると、状況をきちんと追うため何かしら独自のデータベースが必要になるでしょう。しかし今やあなたは分析しなければならないたくさんのデータを生成していて、ビジネスアナリストにメインのデータベースでコストのかかるクエリを実行させるわけにはいきません。そこで、Hadoopやデータウェアハウスを追加して、そこにデータベースからデータを読み込むことにします。
ビジネスアナリティクスが稼働した今、あなたはこの検索システムが複雑化しすぎて維持できなくなりつつあることに気づきます。しかし全てのデータをHDFSに入れてしまっていますから、実際問題Hadoop内に検索インデックスを構築して検索サーバに出力せざるを得ません。こうしてシステムはどんどん複雑さを増していくばかりです。
最終的には、完全にとんでもないことになってしまいます。

どうしてこのような状況になってしまったのでしょう? なぜあらゆるシステムが互いを呼び出し合って、誰も状況が把握できないような状態に陥ってしまったのでしょう?
何か特定の決断が間違っていたということではありません。アプリケーションの全ての要求に応えられるデータベースやツールなどありません。多様な機能を持ったアプリケーションが様々なツールの使用を必要とする中で、私たちはそれらのアプリケーションや対応すべきジョブに合わせて、ベストなツールを使うだけです。
また、システムが大きくなってきたら、運用のしやすさを保つためにより小さなコンポーネントに分割する手段が必要になります。それがマイクロサービスです。しかしコンポーネントが相互依存によって無秩序に絡み合っているようでは、結局そのシステムは運用しやすくはなりません。

単に多くの異なったストレージシステムを持つこと自体は問題ではありません。システムがそれぞれ互いに独立していれば、大したことはないのです。本当に大変なのは、ストレージシステムの多くが同じまたは関連するデータを持っていながら、形式が異なっているという場合です。
例えば、全文検索インデックスの中のドキュメントは、通常はデータベースにも保存されます。検索インデックスは記録用のシステムとして用いられることを想定していませんからね。キャッシュの中のデータは、何かしらのデータベース内のデータの複製です(おそらく他のデータと一緒になっているものか、HTMLにレンダリングされているものか何かです)。これがキャッシュの定義です。
また非正規化も、形式は違いますがキャッシュと同様データの複製です。何かの値が、読み込みの際の再計算にコストがかかりすぎる場合、その値をどこかに保存しておくことができます。しかし基になるデータの変更を行う時には、それを最新の状態にしなければなりません。レコード集合のcountやsum、averageといった具体的な集計結果(よくメトリクスやアナリティクスシステムで得るもの)も、冗長データから得たものです。
私はデータの冗長化が悪いと言っているわけでは全くありません。キャッシュ、インデックスやその他の形式の冗長データが、読み込みの際に高いパフォーマンスを得るのに重要な役割を果たすことがよくあります。しかし、これらの様々な表現やストレージシステムの間で、データの同期を取るのはとても難しいことです。
*注釈:
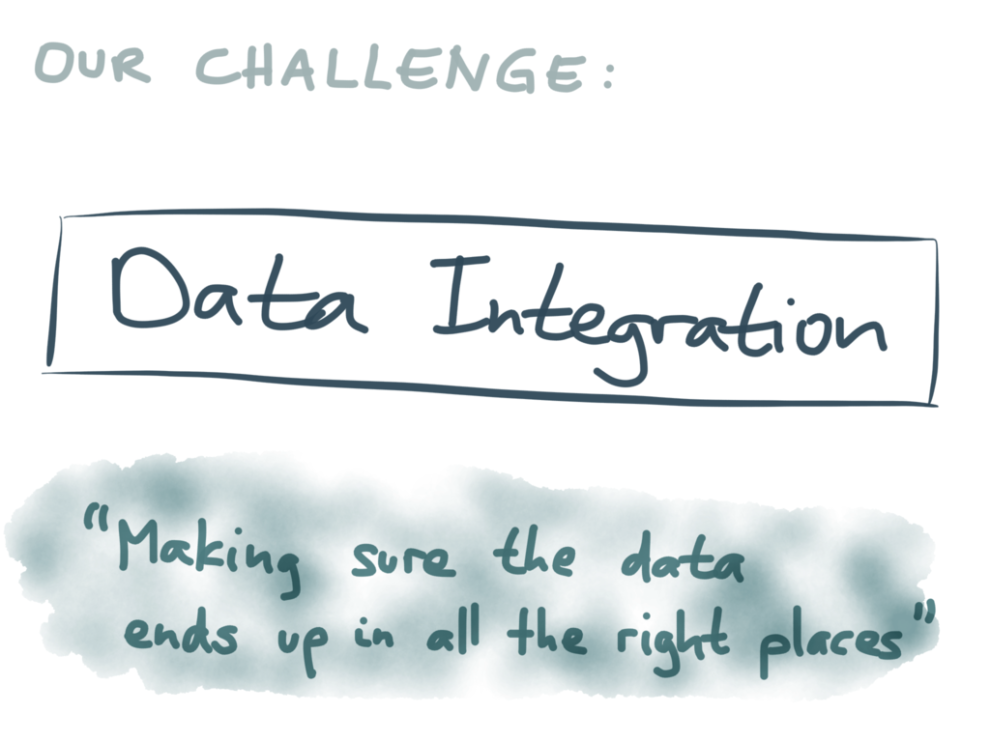
私たちの課題 : データ統合
最終的には確実にデータが適切に格納されるようにすること
良い表現が見つからないのですが、私はこれを”データ統合”の問題と呼ぶことにします。何が言いたいかというと、 “最終的には確実にデータが適切な場所に格納されるようにする” ということです。1つの場所で1つのデータを変更したら、そのデータの複製や派生データがある他の全ての場所でも、必ず同じように変更する必要があるのです。
それでは、このような異なるデータシステムの同期をどのように取ればよいのでしょうか。それにはいくつかの手法があります。
一般的な手法として、 デュアル書き込み と呼ばれる方法があります。
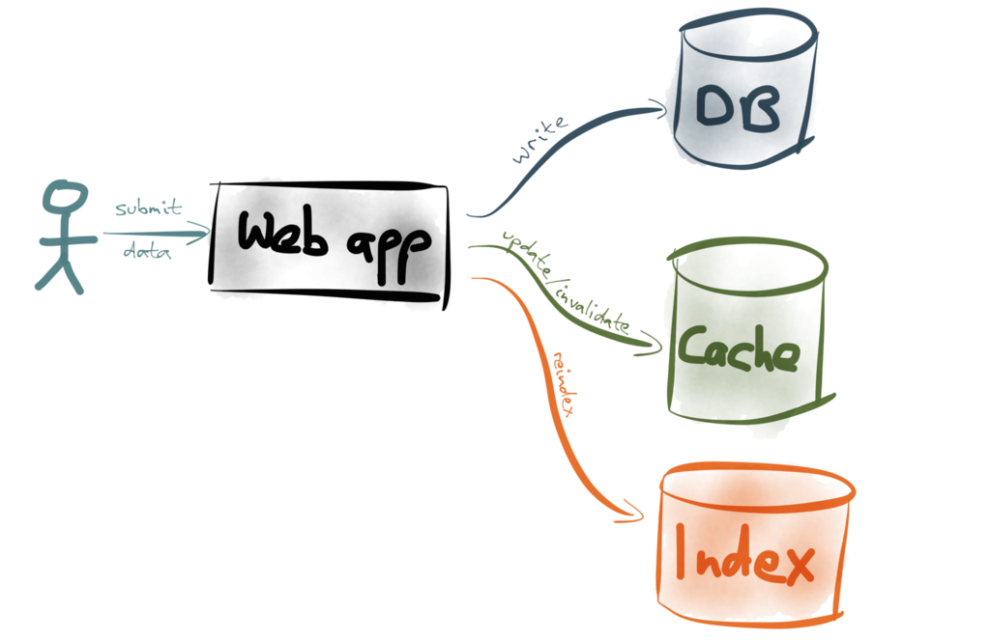
デュアル書き込みは単純な方法です。適切な場所にある全データの更新を担うのは、あなたのアプリケーションのコードです。例えば、ユーザがあなたのWebアプリにデータを送信したとします。そのWebアプリには、次のようなコードが記述されています。まずデータをデータベースに書き込み、次に適切なキャッシュエントリを無効化やリフレッシュし、次に全文検索インデックス内のインデックスを再作成する、などの内容です(または、これらを並列で処理するかもしれませんが、どちらにせよ、私たちの目的には影響がありません)。
デュアル書き込みの方式は構築が簡単で、程度の差こそあれ最初は機能するので、よく使われます。しかし、この方法には根本的な問題があるので、良いアイデアとは言えません。まず問題として挙げられるのは、競合状態です。
次の図は、2人のクライアントが2つのデータストアにデュアル書き込みを行っている様子を表したものです。左から右へ、黒い矢印の方向へ時間が経過しています。

ここで、最初のクライアント(青色)はキーXに値Aをセットしています。クライアントは、まず、1つ目のデータストアに要求を出します。このデータストアは、おそらくデータベースでしょう。そしてX=Aをセットします。データストアは、書き込み成功のステータスを返します。次に青のクライアントは、2つ目のデータストアに要求を出します。2つ目のデータストアは、例えば、検索インデックスでしょう。こちらにも、X=Aをセットします。
この処理と同時に、もう一人のクライアント(赤色)もデータストアにアクセスしています。同一のキーXに、異なる値Bをセットしようとします。赤のクライアントも同じように処理を進めます。1つ目のデータストアにX=Bを送信し、次に2つ目のデータストアにもX=Bを送信します。
これらの書き込みは全て成功しますが、最終的に、各データベースにはどんな値が格納されたのか見てみましょう。

1つ目のデータストアには、最初に青のクライアントがAをセットし、次に赤のクライアントがBをセットしたので、最終的な値はBです。
2つ目のデータストアは、1つ目とは異なる順序で要求を受け付けました。最初にBがセットされ、次にAがセットされたので、最終的な値はAです。結局、2つのデータストアは互いに不整合となり、いつか誰かが再度Xを上書きするまで、永久に不整合のままです。
最悪なのは、自分のデータベースと検索インデックスが不整合を起こしているということに、おそらく、気付きさえしないことです。なぜなら、エラーは起きなかったからです。きっと半年後に、全然違う処理をしている時に、データベースとインデックスがマッチしないことに気が付くでしょう。ところが、どうしてそんなことになったのか、全く思い当たる節がないのです。
これだけでも、デュアル書き込みの方式を採用しない十分な理由となります。しかし、更にこんな理由もあります。

ここでは、非正規データについて考えてみましょう。例えば、ユーザが互いにメッセージやメールを送れるアプリケーションがあるとします。ユーザはそれぞれ受信箱を持っています。新しいメッセージが送られると、2つの処理が発生します。まず、ユーザの受信箱のメッセージリストに、新しいメッセージを追加する処理、次に、未読メッセージのカウンタを1つカウントアップする処理です。
ユーザ・インターフェースには常にカウンタを表示させておく必要があるので、もう1つの独立したカウンタを持っています。数を表示する必要が生じる度に、メッセージリストを全てスキャンして未読メッセージの数を問い合わせるのでは、表示に時間がかかり過ぎます。しかし、このカウンタの情報は非正規データです。つまり、受信箱にある実際のメッセージを基にカウントした情報であり、メッセージがいつ更新されても、その状況に応じてカウンタを更新する必要があります。
もっと単純に、1人のユーザと1つのデータベースについて考えてみましょう。最終的にどうなるでしょうか。最初に、ユーザは相手の受信箱に新しいメッセージを送信します。次にユーザは、未読メッセージカウンタを1つカウントアップする要求を出します。

しかしその瞬間に、不具合が発生します。データベースが落ちたり、プロセスがクラッシュしたり、ネットワークが遮断されたり、誰かが間違ってネットワークケーブルを引き抜いてしまったりといった不具合です。理由は何であれ、未読メッセージカウンタの更新は失敗します。
その結果、データベースは不整合となります。受信箱にメッセージは届いているのに、カウンタはまだ更新されていません。定期的に、全てのカウンタの値を最初から計算し直すか、メッセージが届いたという処理を取り消さない限り、永遠に不整合のままです。
もちろん、こんな問題は、 トランザクション によって数十年前に解決済みだと言う人もいるでしょう。”ACID”の”A”、Atomicity(原子性)は、複数の変更を1つのトランザクションで行おうとした場合、全ての処理が実行されるか、何も処理が行われないかのどちらかになることを意味します。原子性の目的は、まさにこの問題を解決することにあります。もし書き込みの最中に不具合が発生しても、中途半端な更新のためにデータが不整合になる心配はありません。

2つの書き込み処理を1つのトランザクションに包括するという従来のアプローチは、この方式をサポートしているデータベースではうまく機能します。しかし、新世代の多くのデータベースは従来の方式をサポートしていないので、自力で何とかしなくてはなりません。
また、非正規化された情報が、異なるデータベースに格納されている場合はどうでしょう。例えば、メールはデータベースに保存されるけれども、未読カウンタはRedisに保存される場合などです。1つのトランザクションで一度に書き込めなくなってしまいます。片方の書き込みが成功し、もう一方が失敗した場合、不整合を正すのに手間取ることになるでしょう。
分散トランザクションをサポートしているシステムもあります。例えば、 2フェーズコミット です。しかし、最近では、多くのデータストアはこの方式をサポートしていません。もしサポートしていても、そもそも分散トランザクションが良い考えなのか、 明らかだとは言えません 。ですからデュアル書き込み方式を採用した場合、アプリケーションは、部分的障害という難しい対応を迫られることを覚悟する必要があります。
*注釈:
私たちの課題 : データ統合
最終的には確実にデータが適切に格納されるようにすること
それでは、最初の質問に戻りましょう。データが確実に、適切な場所に格納されるようにするには、どうしたらよいのでしょうか。複数の異なるストレージシステム上にある同じデータのコピーをどのように取ったらよいのでしょうか。そして、データの変更時に、どうやって同期させ、整合性を保てばよいのでしょうか。
これまで見てきたように、デュアル書き込みは解決策にはなりません。競合状態や部分的な障害のために、不整合を起こしかねないからです。それでは、もっと良い方法はあるのでしょうか。

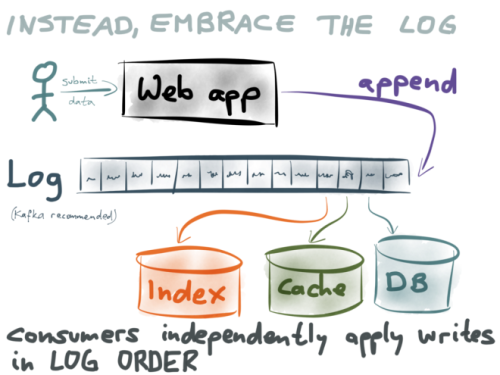
私は、バカバカしいほどに単純な方法が大好きです。単純な解決策の素晴らしいところは、その方法を理解し、正しいと確信することができる点です。今回のケースで、私が考えつく最も単純な解決策は、決まった順序でデータの書き込みをし、決まった順序で格納することです。
並行処理をせずに、所定の順序で全ての書き込みを行えば、競合状態を招く可能性を排除できます。更に、書き込みを行った順序を書き出しておけば、部分的な障害が発生した時にリカバリがずっと楽になります。これは後でお見せしましょう。
私が提案する非常に単純な解決策は、次のようなものです。ユーザがデータを書き込む際は、その書き込みをレコードの並びの最後に追加します。この並びは完全に順序立っており、追加専用(決して既存のレコードを変更しません。最後尾に新しいレコードを追加するだけです)で、不変です(ディスク上に永久に保存します)。
上の図は、そのようなデータ構造を表したものです。左から右に移動していきます。最初の書き込みであるX=5を記録し、次にY=8を記録し、次にX=6を記録する、といった具合です。

このデータ構造には名前がついています。私たちはこれを ログ と呼んでいます。
ログの面白い点は、コンピュータのあらゆる分野に出現するということです。あまりに単純な考えで、うまくいくとは思えないかもしれませんが、実際には、信じられないほど強力に機能することが分かっています。

“ログ”と言うと、Log4jやsyslogで取得されるテキスト形式のアプリケーションログを想像するかもしれません。例えば、上のテキストは、nginxサーバのアクセスログの一部で、あるIPアドレスが、特定の時間に、特定のファイルを要求したという内容を表しています。その他にも、リファラやユーザエージェント、レスポンスコードなどの情報も含まれています。
確かに、これもログの一種です。しかし、私がお伝えしているログは、もっと一般的なものを指しています。完全に順序立ったレコードから成る、あらゆる種類のデータ構造は、追加専用で不変であるということを意味しています。どんな種類の追加専用のファイルも同様です。
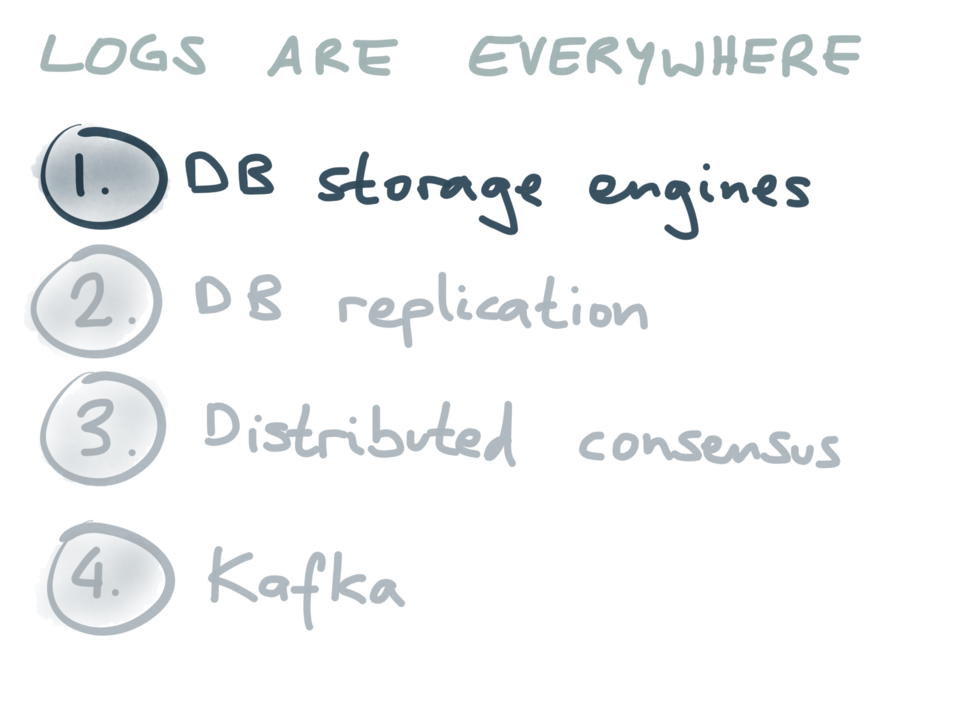
注釈:ログはあらゆる場所にある
① DBストレージエンジン
② DBレプリケーション
③ 分散合意
④ Kafka
この後、実際にログがどのように使われているのか、いくつかの例をお見せしたいと思います。毎日使っているデータベースやシステムの中に、ログは既に存在するということが分かると思います。様々なシステムでログがどのように利用されているのかが分かれば、データ統合の問題を解決する上でログがいかに役立つか、理解しやすくなるでしょう。
PART 2.はこちら : 強固なデータ・インフラストラクチャを構築するためのログの活用(デュアル書き込みがダメな理由)PART 2.

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事