2016年3月11日
IPFS入門 : 新たなP2Pハイパーメディア分散プロトコル

本記事は、原著者の許諾のもとに翻訳・掲載しております。

提供:Bogdan Burcea
IPFS があれば、他の全てのものが一定のやり方で見えるようになり、全てをすっかり置き換えられることに気づく – Juan Benet
IPFSへのあまり技術的でないアプローチ
執筆:John Lilic
本稿の後半では、同僚のChristian Lundkvist博士が 踏み込んだ技術的概要 を紹介していますので、その導入となる大まかな考え方をこのセクションでお話ししたいと思います。
IPFSは、バージョン管理された科学的データを巡回する高速システムの構築を目的として、Juan Benetの取り組みによって始まりました。 バージョン管理 が行われていると、ソフトウェアの変更履歴を追跡できるのです( Gitのような仕組み )。その後、IPFSは 分散された永続的なWeb として考えられるようになりました。「 IPFSとは、あらゆる端末を同じファイルシステムに接続することを意図した分散ファイルシステムです。 ある点でこれはWebの本来の目的と似ていますが、実はIPFSは、Gitオブジェクトを交換する単一のBitTorrentスウォームの方にもっと似ています。IPFSはインターネットの新たな主要サブシステムになるかもしれません。適切に構築されれば、HTTPやそれ以上のものを補完したり、置き換えたりできる可能性もあります。途方もない考えのように思えますが、まさに途方もないシステムです」[ 1 ]
IPFSの中核はバージョン管理されたファイルシステムであり、ファイルを受け取って管理し、どこかに保管も行って、バージョン履歴を追跡することができます。IPFSでは、各ファイルのネットワークでの動きも分かりますから、分散ファイルシステムでもあるのです。
IPFSでは、データやコンテンツがネットワークをどう動くかについて、BitTorrentと性質的に似たルールがあります。IPFSのファイルシステムのレイヤには、以下のような非常に興味深い特性があります。
- 完全に分散化されたWebサイト
- 元サーバがないWebサイト
- 完全にクライアント側のブラウザで動作するWebサイト
- どのサーバとも通信しないWebサイト
コンテンツ・アドレッシング
IPFSは、オブジェクト(画像、記事、映像)を参照する時にどのサーバに保管されているかを調べるのではなく、全ての参照においてファイルのハッシュを使います。考え方としては、ブラウザで特定のページにアクセスしたい場合、IPFSはネットワーク全体に対して「このハッシュに対応するこのファイルを持っているか?」と問い合わせを行い、該当するIPFSのノードがファイルを返すことで、ページにアクセス可能になるという仕組みです。
IPFSはHTTPレイヤでコンテンツ・アドレッシングを使っています。これは、「コンテンツをlocationで指定する識別子を生成するのではなく、コンテンツ自体の表現でコンテンツを指定します」、と宣言するやり方です。つまり、コンテンツがアドレスを決定するのです。IPFSにファイルが追加されると、それを暗号化したハッシュが生成されるという仕組みなので、ファイルの表現は非常に小さく安全なものとなります。従って、同じハッシュを持つ別のファイルを誰かが偶然見つけてそれをアドレスとして使うようなことはできません。IPFSでは、ファイルのアドレスは通常、ルートオブジェクトを識別するハッシュで始まり、走査するパスが次に続きます。サーバではなく特定のオブジェクトと通信して、そのオブジェクト内のパスを調べるのです。
ファイル探索におけるHTTPとIPFSの比較
HTTPには、識別子に所在が含まれているという便利な特性があるので、ファイルを提供しているコンピュータを見つけてそれと通信することは簡単です。これは便利な性質であり大抵は問題ないのですが、オフラインの場合や、ネットワークの負荷をできる限り少なくしたい大規模分散環境では、うまい方法とは言えません。
IPFSでは、このステップは以下の2つに分かれています。
- コンテンツアドレッシングでファイルを識別する
- 問い合わせと発見:ハッシュを得たら、自身がつながっているネットワークに対して「このコンテンツを持っているノードは?(ハッシュ)」という問い合わせを行い、該当するノードに接続してダウンロードを実行する
その結果、IPFSは、高速なルーティングが可能なPeer-to-Peer(P2P)型のオーバーレイとなっています。
詳細については、 アルファ版のデモ映像 をご覧ください。
例で見るIPFS
執筆:Christian Lundkvist博士
技術的に見ると、 IPFS (InterPlanetary File System:惑星間ファイルシステム)は、 分散ハッシュテーブル や Git バージョン管理システム、 BitTorrent といった実績のあるインターネットテクノロジの統合体です。IPFSではP2Pスウォームが生成され、 IPFSオブジェクト の交換ができるようになっています。IPFSオブジェクトの総体は、 Merkle DAG として知られる暗号化認証されたデータ構造を形成し、このデータ構造を基にして他の多くのデータ構造が作られます。以下ではIPFSオブジェクトとMerkle DAGについて紹介し、IPFSを使って作られる構造の例を見ていきます。
IPFSオブジェクト
IPFS は本質的に、 IPFSオブジェクト を検索し共有するためのP2Pシステムです。IPFSオブジェクトとは、以下2つのフィールドをもつデータ構造です。
- Data :サイズが256kBより小さい構造化されていないバイナリデータの塊。
- Links :Link構造体の配列。他のIPFSオブジェクトへのリンク。
Link構造体には、以下3つのフィールドがあります。
- Name :Linkの名前。
- Hash :リンクされたIPFSオブジェクトのハッシュ。
- Size :リンクされたIPFSオブジェクトの累積サイズ。リンクの追跡を含む。
Size フィールドは、主にP2Pネットワーキングを最適化するために使用されますが、概念上は、論理構造に必要なものではないため、本稿では特に扱いません。
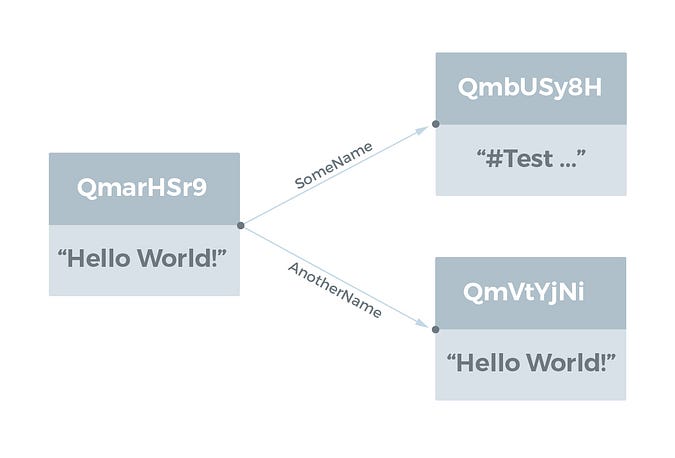
IPFSオブジェクトは通常、Base58でエンコードされたハッシュによって参照されます。例えば、 QmarHSr9aSNaPSR6G9KFPbuLV9aEqJfTk1y9B8pdwqK4Rq というハッシュを持つIPFSオブジェクトを、IPFSコマンドラインツールで見てみましょう(これは自宅で試してくださいね)。
> ipfs object get QmarHSr9aSNaPSR6G9KFPbuLV9aEqJfTk1y9B8pdwqK4Rq
{“Links”: [{
“Name”: “AnotherName”,
“Hash”: “QmVtYjNij3KeyGmcgg7yVXWskLaBtov3UYL9pgcGK3MCWu”,
“Size”: 18},
{“Name”: “SomeName”,
“Hash”: “QmbUSy8HCn8J4TMDRRdxCbK2uCCtkQyZtY6XYv3y7kLgDC”,
“Size”: 58}],
“Data”: “Hello World!”}全てのハッシュが「Qm」で始まっていることにお気づきでしょうか。その理由は、このハッシュが実は multihash の形式であるからです。つまり、ハッシュの先頭2バイトで、ハッシュ自体がハッシュ関数とハッシュの長さを示しているのです。上記の例では、先頭2バイトを16進数で表すと 1220 となりますが、 12 はこれがSHA-256ハッシュ関数であること、 20 はハッシュの長さが32バイトであることを意味しています。
データと、名前付きのリンクがあることで、IPFSオブジェクトの集合は Merkle DAG の構造を取ります。 DAG は有向非巡回グラフを意味し、 Merkle はこれが暗号化認証されたデータ構造であり、コンテンツのアドレス指定に暗号化ハッシュを用いていることを示しています。このグラフで閉路を持つことができない理由について考えるのは、皆さんの練習問題としておきましょう。
このグラフ構造を目に見えるようにするため、IPFSオブジェクトを視覚化してみたいと思います。グラフでは、ノードにDataがあり、Linksは他のIPFSオブジェクトへ向かう有向グラフのエッジ、LinkのNameはグラフのエッジに付けられたラベルとなります。以下の図は、上記の例を視覚化したものです。
それでは、IPFSオブジェクトで表すことのできる様々なデータ構造の例を見ていきましょう。
ファイルシステム
IPFSは、ファイルとディレクトリから構成されるファイルシステムを簡単に表すことができます。
小さなファイル
小さなファイル(< 256kB)をIPFSオブジェクトで表すと、 data がファイルのコンテンツ(および小さなヘッダとフッタ)で、リンクがないため links は空配列となります。ファイル名がIPFSオブジェクトの一部ではないことに注意してください。つまり、コンテンツが同じで名前の異なる2つのファイルは、IPFSオブジェクトの表現が同じになるため、生成されるハッシュも同一なのです。
ipfs add というコマンドを使うと、IPFSに小さなファイルを追加することができます。
chris@chris-VBox:~/tmp$ ipfs add test_dir/hello.txt
added QmfM2r8seH2GiRaC4esTjeraXEachRt8ZsSeGaWTPLyMoG test_dir/hello.txtipfs cat を使えば、上記IPFSオブジェクトのファイルのコンテンツを見ることができます。
chris@chris-VBox:~/tmp$ ipfs cat QmfM2r8seH2GiRaC4esTjeraXEachRt8ZsSeGaWTPLyMoG
Hello World!ipfs object get で基本構造を見てみましょう。
chris@chris-VBox:~/tmp$ ipfs object get QmfM2r8seH2GiRaC4esTjeraXEachRt8ZsSeGaWTPLyMoG
{“Links”: [],
“Data”: “\u0008\u0002\u0012\rHello World!\n\u0018\r”}このファイルを視覚化すると、以下のようになります。

大きなファイル
大きなファイル(> 256kB)は、256kBより小さいファイルの塊に対するリンクのリストと、このオブジェクトが大きなファイルの表現であることを示す最小限の Data で表されます。ファイルの塊に対するリンクは、名前として空文字列を持っています。
chris@chris-VBox:~/tmp$ ipfs add test_dir/bigfile.js
added QmR45FmbVVrixReBwJkhEKde2qwHYaQzGxu4ZoDeswuF9w test_dir/bigfile.js
chris@chris-VBox:~/tmp$ ipfs object get QmR45FmbVVrixReBwJkhEKde2qwHYaQzGxu4ZoDeswuF9w
{“Links”: [{
“Name”: “”,
“Hash”: “QmYSK2JyM3RyDyB52caZCTKFR3HKniEcMnNJYdk8DQ6KKB”,
“Size”: 262158},
{“Name”: “”,
“Hash”: “QmQeUqdjFmaxuJewStqCLUoKrR9khqb4Edw9TfRQQdfWz3”,
“Size”: 262158},
{“Name”: “”,
“Hash”: “Qma98bk1hjiRZDTmYmfiUXDj8hXXt7uGA5roU5mfUb3sVG”,
“Size”: 178947}],
“Data”: “\u0008\u0002\u0018* \u0010 \u0010 \n”}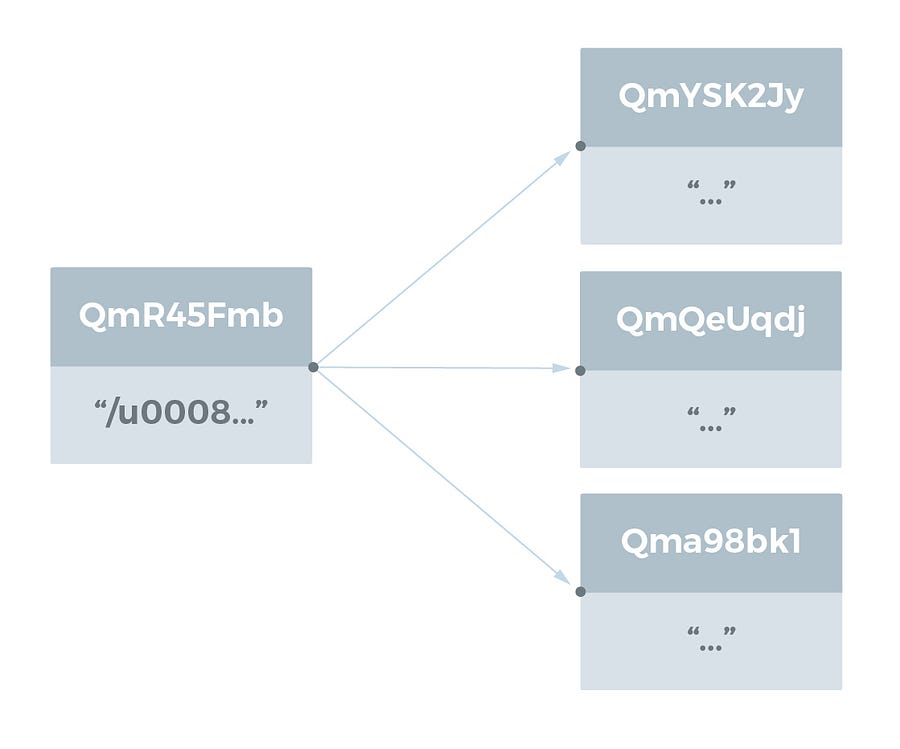
ディレクトリ構造
ディレクトリは、ファイルや他のディレクトリを表すIPFSオブジェクトへのリンクのリストで表されます。リンク名は、ファイル名やディレクトリ名です。例えば、次のようなディレクトリ test_dir のディレクトリ構造を考えてみてください。
chris@chris-VBox:~/tmp$ ls -R test_dir
test_dir:
bigfile.js hello.txt my_dir
test_dir/my_dir:
my_file.txt testing.txthello.txt と my_file.txt というファイルの両方に文字列 Hello World!\n が含まれ、 testing.txt というファイルには文字列 Testing 123\n が含まれています。
このディレクトリ構造をIPFSオブジェクトとして表すと、以下のようになります。
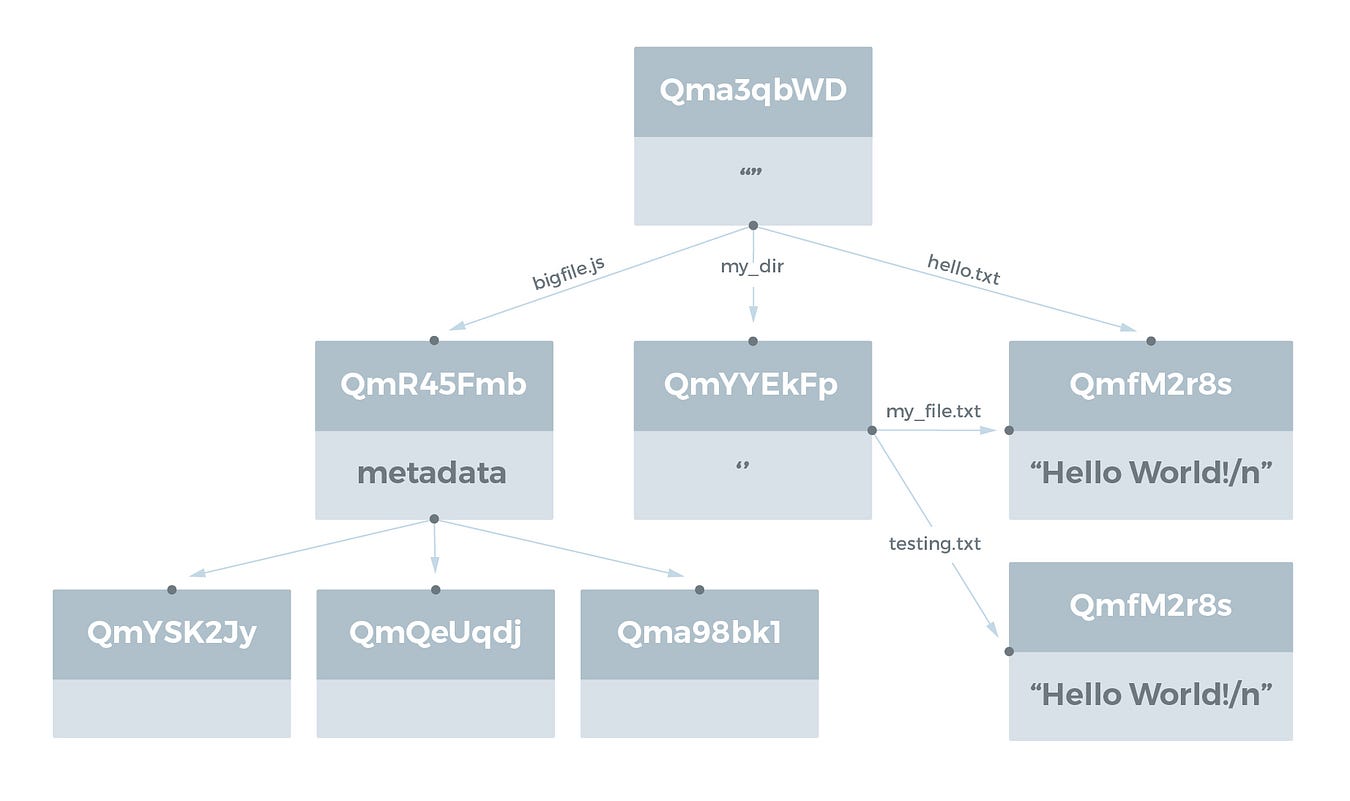
Hello World!\n を含むファイルの自動重複排除に注意してください。このファイル内のデータはIPFS内の1つの論理的な場所に格納されているだけ(ハッシュによるアドレス指定)です。
IPFSコマンドラインツールを使えば、シームレスにディレクトリのリンク名を追って、ファイルシステムを横断できます。
chris@chris-VBox:~/tmp$ ipfs cat Qma3qbWDGJc6he3syLUTaRkJD3vAq1k5569tNMbUtjAZjf/my_dir/my_file.txt
Hello World!バージョン管理されたファイルシステム
IPFSは、Gitで使われているデータ構造を表して、バージョン管理されたファイルシステムを実現可能にします。Gitコミットオブジェクトについては、 Git Book に説明があります。IPFSコミットオブジェクトの構造は、本稿の執筆時点では完全には規定されておらず、 議論が続いています 。
コミットオブジェクトの主な特性は、前のコミットを指す parent0、parent1 などといった名前の1つ以上のリンクと、 object (Gitでは tree と呼ばれます)というリンク名の、コミットによって参照されるファイルシステム構造を指す1つのリンクを持つということです。
一例として、従来のファイルシステムのディレクトリ構造を2つのコミットと共にご紹介しましょう。1つ目のコミットは元の構造です。2つ目のコミットでは、もともとの Hello World! ではなく Another World! と表示されるように、ファイル my_file.txt が更新されています。
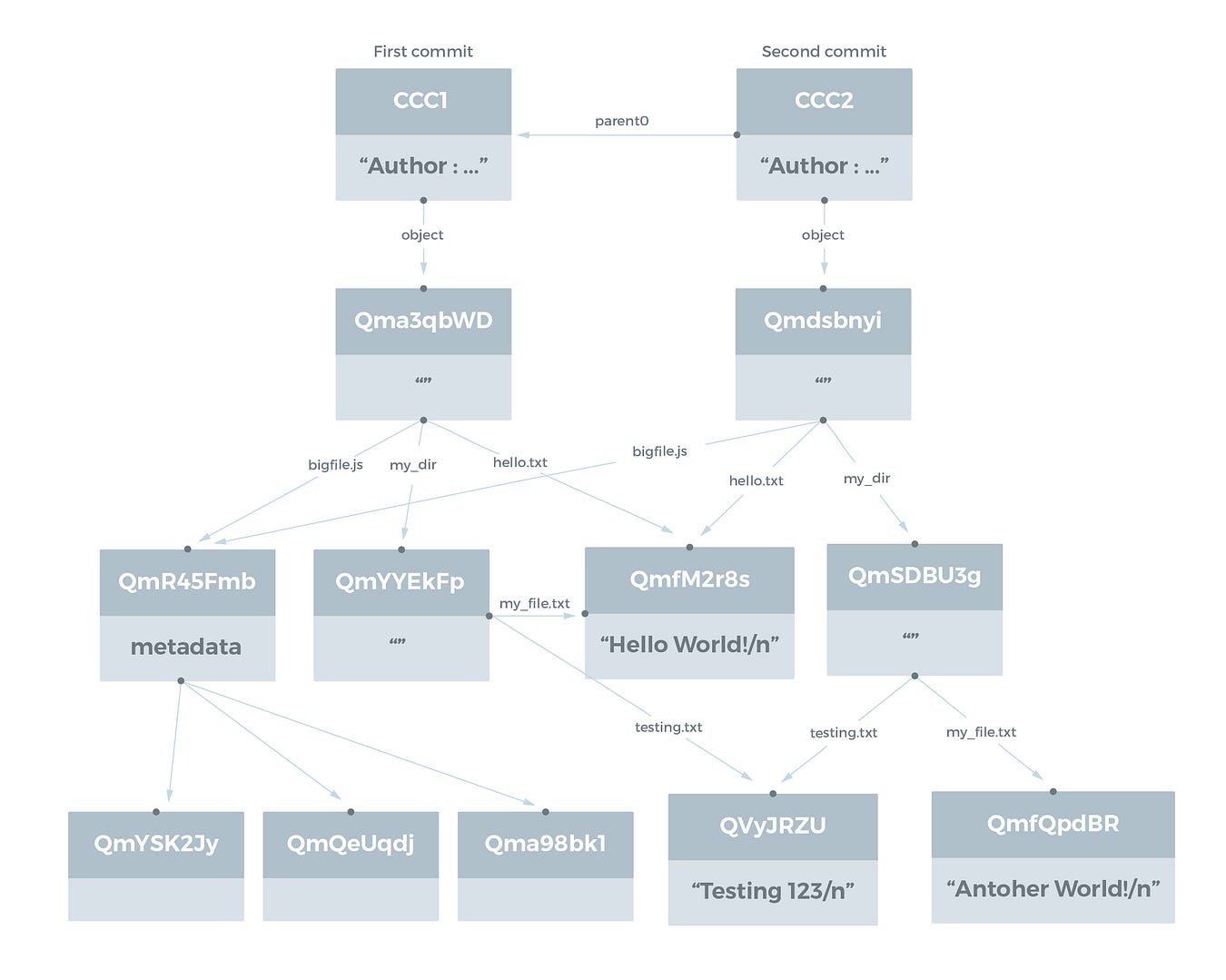
自動重複排除機能があるので、2つ目のコミットの新しいオブジェクトは、メインディレクトリ、新しいディレクトリ my_dir 、そして更新されたファイル my_file.txt だけだということにも気を付けてください。
ブロックチェーン
これはIPFSで最も面白いユースケースの1つです。ブロックチェーンには自然なDAG構造があり、過去のブロックはハッシュによって後のブロックと常にリンクされています。 Ethereum で使われているような高度なブロックチェーンも関連づけられた状態データベースを持っており、そのデータベースは Merkle-Patricia tree 構造で、IPFSオブジェクトを使ってエミュレートすることもできます。
前提としているのはブロックチェーンの単純すぎるモデルで、各ブロックが含んでいるデータは以下のとおりです。
- トランザクションオブジェクトのリスト
- 前のブロックへのリンク
- 状態のツリー/データベースのハッシュ
それから、このブロックチェーンは次のようにIPFSでモデル化することができます。
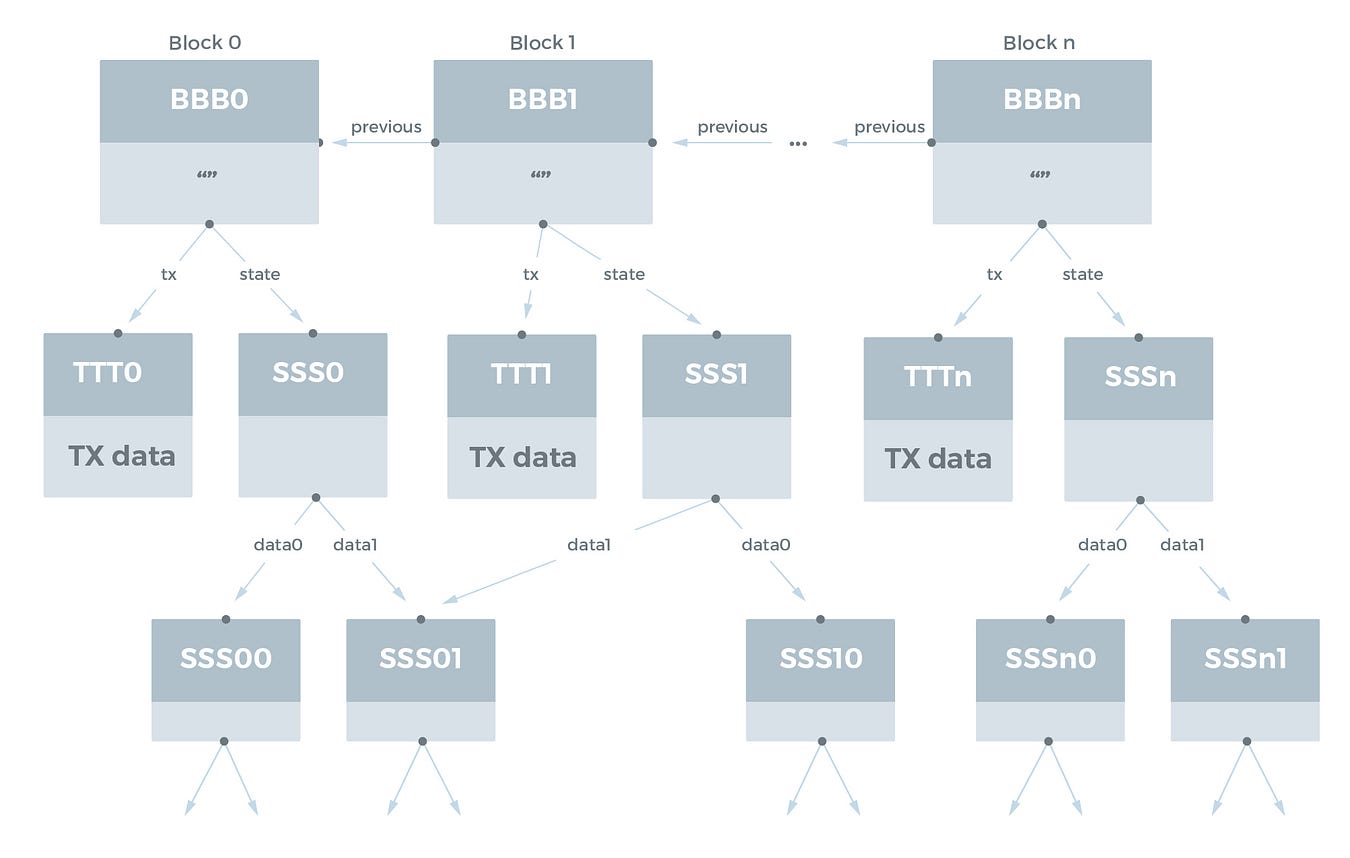
状態データベースをIPFSに配置する際に得る重複排除機能が見られます。2つのブロック間には変更された状態のエントリのみが明示的に格納されなくてはなりません。
ここで興味深い点は、ブロックチェーン上にデータを格納することと、ブロックチェーン上にデータのハッシュを格納することとの違いです。Ethereumプラットフォームでは、関連づけられた状態データベースにデータを格納するためにかなりのコストがかかります。状態データベースの肥大化(”ブロックチェーンの肥大化”)を最小限に抑えるためです。そのため、大きめのデータは、データそのものではなく、データのIPFSハッシュを状態データベースに格納するのが一般的なデザインパターンです。
関連づけられた状態データベースを持つブロックチェーンが既にIPFSで表されている場合、ブロックチェーン上にハッシュを格納することとブロックチェーン上にデータを格納することとの違いは、やや不鮮明になります。とにかく全てがIPFSに格納されているので、ブロックのハッシュに必要なのは、状態データベースのハッシュだけです。この場合、IPFSリンクがブロックチェーンに格納されていれば、シームレスにそのリンクをたどって、まるでデータがブロックチェーン自体に格納されているかのように、データにアクセスできます。
しかし、それでもオンチェーンとオフチェーンのデータストレージを見分けることができます。新しいブロックを作る際にマイナーが処理しなければならないものを見て、区別します。現在のEthereumネットワークでは、状態データベースを更新するトランザクションをマイナーが処理する必要があります。それを行うため、どこが変更されても更新できるように、マイナーには完全な状態データベースへのアクセスが必要です。
従って、IPFSで表されるブロックチェーンの状態データベース内で、やはりデータに”オンチェーン”か”オフチェーン”かのタグを付けなければならないでしょう。”オンチェーン”データは、マイニングを行うためにマイナーがローカルに保持する必要があり、このデータは直接トランザクションの影響を受けます。”オフチェーン”データは、ユーザが更新しなければならず、従ってマイナーがこれに触れる必要はありません。
