2015年6月30日
強固なデータ・インフラストラクチャを構築するためのログの活用(デュアル書き込みがダメな理由)PART 2
(2015-05-27)by Martin Kleppmann
本記事は、原著者の許諾のもとに翻訳・掲載しております。
PART 1.はこちら : 強固なデータ・インフラストラクチャを構築するためのログの活用(デュアル書き込みがダメな理由)PART 1.
ログが使われる場面について4つ説明したいと思います。まずデータベースストレージエンジンの内部です。
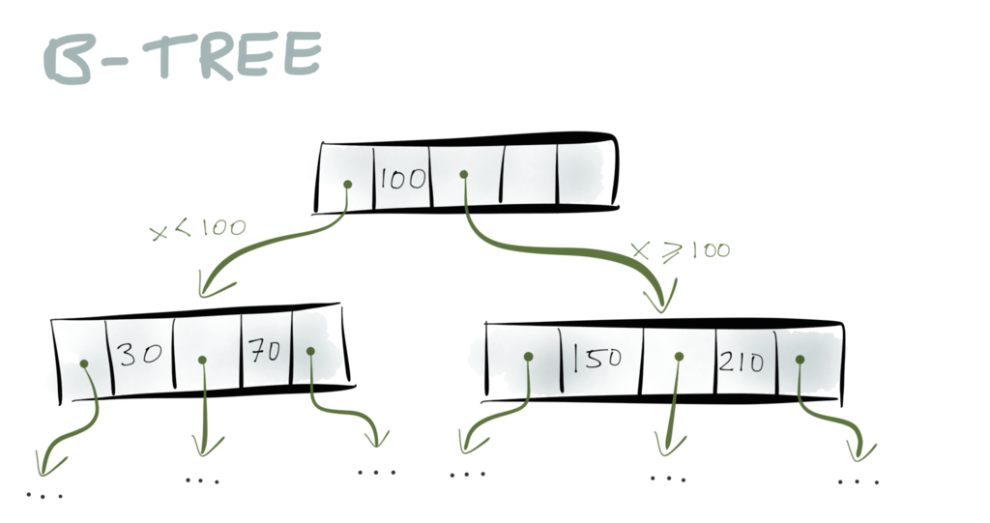
B-tree はアルゴリズムの授業で学びましたよね? ストレージエンジンに広く使われているデータ構造です。ほぼ全てのリレーショナルデータベースと、多くの非リレーショナルデータベースで使われています。
B-treeについて簡単に説明しましょう。B-treeは、ディスク上で固定長のブロックとなる ページ から構成されており、通常、その固定長は4KBか8KBです。ある特定のキーを探したい時は、まずtreeのルートにあるページから探索を始めます。そのページは他のページへのポインタを内包していて、各ポインタはキーのレンジ(範囲)にタグ付けられています。例えば、もしキーが0から100の間だったら最初のポインタに従い、キーが100から300の間なら2番目のポインタに従う、といった具合です。
ポインタがあなたを別のページへと導き、キーレンジをさらにサブレンジへと絞り込んでくれます。そして遂には、あなたの探していた特定のキーを含むページへとたどりつくのです。
さてB-treeに新たなキーと値のペアを挿入する必要がある場合はどうなのでしょうか。この場合は、挿入したいキーを含むキーレンジがあるページに挿入する必要があります。そのページに十分なスペースがあれば問題ありませんが、余裕がない場合はページを2つに分けなくてはなりません。
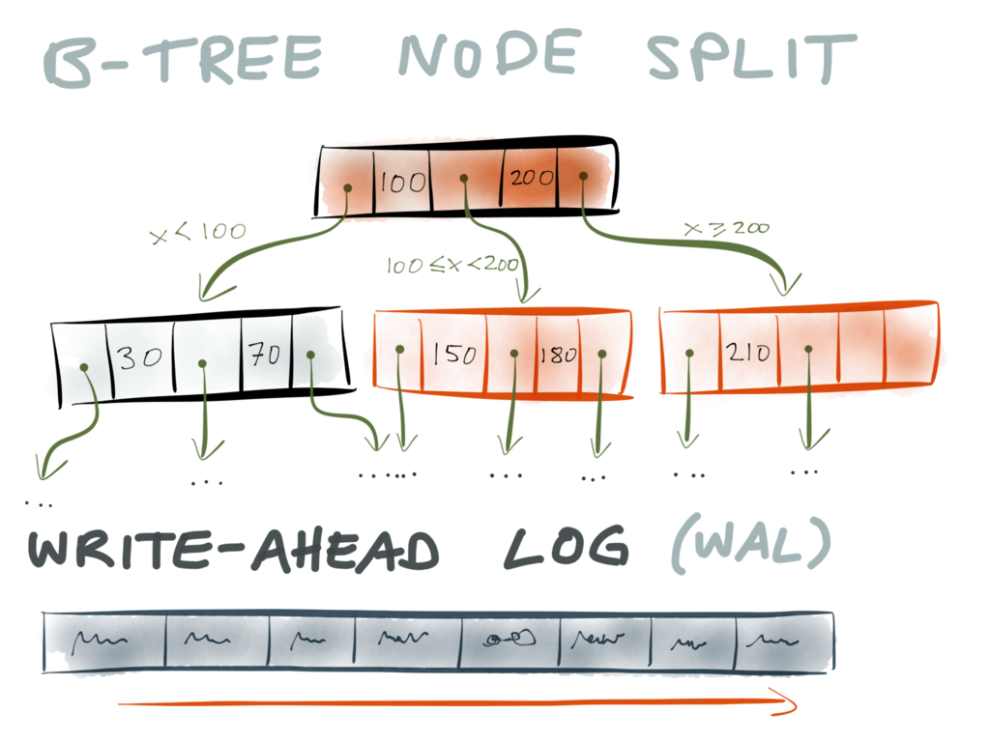
ページを分ける際、最低でも3ページをディスクに書き込む必要があります。分けた結果の2ページと、その親のページです(分けられたページへのポインタを更新するため)。しかし、これらのページはディスク上、別の箇所にバラバラに保存される可能性があります。
ここで問題が出てきました。もしも処理の途中、全てのページがディスクに書き込まれる前にデータベースがクラッシュしたら(または停電や他の問題があった場合)どうしたら良いのでしょうか。そういう場合、どこかのページには古い(分割前)データが残っていて、他のページには新しい(分割後)データが書き込まれているので、厄介なことになりそうです。ポインタやページがどこからも指し示されることなく、宙ぶらりんになってしまう可能性が高いですよね。別の言い方をすれば、インデックスが壊れているということになります。
さて、ストレージエンジンはこういうことに何十年も対応してきたはずですが、どうやってB-treeの信頼性を保っているのでしょうか。 ログ先行書き込み (WAL)を使うというのが答えです。
ログ先行書き込みとは、一種の特殊なログで、ディスク上の追加専用のファイルです。ストレージエンジンがB-treeに対して変更を加えたい時は、意図する変更を まず WALに書き込む必要があります。WALに書き込まれ、そしてしっかりとディスクに書き込まれた後で初めて、実際のB-treeを変更することが許可されるのです。
こうしてB-treeの信頼性が向上します。もしWALにデータを追加中、データベースがクラッシュしたとしても問題ありません。まだB-treeには手が付けられていないからです。B-treeが変更されている最中にクラッシュしたとしても、問題ありません。なぜならWALが予定されている変更についての情報を持っているからです。クラッシュの後、データベースが復活したら、WALを用いてB-treeを修復し、つじつまの合った状態に戻せばいいのです。
ログがなかなか優れた考え方だという最初の例をお見せしました。

さて、B-treeはストレージエンジンの働きを妨害しませんでした。賢い読者の方なら、こう気付いたのではないでしょうか。もし何もかもログに記録するのであれば、ログを一次的なストレージ媒体として使うことができるんじゃないか、と。これは ログ構造化方式 として知られていて、 HBase や Cassandra で使われており、 Riak でもその変種が登場しています。
ログ構造化ストレージでは、いつも同じファイルに追加し続けるわけではありません。それでは大きくなりすぎて、キーを捜すのが困難になってしまうからです。その代わりに、ログは セグメント に分割され、時々ストレージエンジンがセグメントをマージし、重複したキーを廃棄します。セグメントはキーによって内部的にソートされていることもあり、これにより、捜しているキーを見つけるのが容易になり、またマージしやすくなっています。しかし、これらのセグメントはログであることには変わりありません。順次的に書き込まれ、一度書き込まれたら変更不可能です。
このように、ログというのはストレージエンジンの中で重要な役割を果たしているのです。

注釈:ログはあらゆる場所にある
① DBストレージエンジン
② DBレプリケーション
③ 分散合意
④ Kafka
さて2番目は、データベースレプリケーションでのログの使用例です。
レプリケーションは多くのデータベースで使われている機能です。いくつかの違うノードに同じデータを複製して置いておくことができるというもので、負荷を分散するのに役立ちます。また、1つのノードが停止してしまった時に他のノードからフェイルオーバーできるということも意味しています。

レプリケーションを実装する方法はいくつかありますが、一般的なのは1つのノードを リーダー ( プライマリ や マスター とも言われる)とし、他のレプリカを フォロワー ( スタンバイ や スレーブ とも言われる)として指定することです。マスター/スレーブという用語は好きではないので、リーダー/フォロワーを使います。
クライアントがデータベースに何か書き込みたい時は、まずリーダーに通知します。リードオンリーのクライアントはリーダーまたはフォロワーを使うことができます(フォロワーは通常、非同期なので、もし最新の書き込みがまだ適用されていなければ、少し情報が古い可能性があります)。
クライアントがリーダーにデータを書き込んだ時、そのデータはどのようにしてフォロワーに伝わるのでしょうか。驚くことに、ここでもログが使われるのです。 レプリケーションログ というものが使われますが、これは実際には先行書き込みログと同じものである場合(例えばPostgresでのケース)も、または別のレプリケーションログの場合もあります(MySQLのケース)。

レプリケーションログは次のように機能します。リーダーに何らかのデータが書き込まれると、レプリケーションログに追加されます。フォロワーは書き込まれた順にログを読み出し、自分が持っているデータコピーに、それぞれの書き込みを追加します。結果的に各フォロワーはリーダーと同じ順番で同じ書き込みを処理し、それによって同じデータの複製を備えることとなります。
読み側で書き込みが同時に発生していたとしても、ログは全順序で書き込まれています。ですから、ログは実際には書き込みから同時性を 取り除いて います。つまり” 書き込みの流れから全ての非決定性を追い出すため “、フォロワーにとっては書き込まれた順番に関しては疑いようがないのです。
さて、前述したデュアル書き込みの競合状態についてはどうでしょうか。

リーダーベースのレプリケーションでは、競合状態は起こりません。クライアントが直接フォロワーに書き込むことはないからです。フォロワーによって処理される書き込みはレプリケーションログから受け取ったものに限られています。そしてログはこれらの書き込みの順番を固定化しているので、どれが最初に書き込まれたかということに関しては曖昧性がありません。

では前述のデュアル書き込みの2番目の問題はどうでしょうか。これは起こり得ます。フォロワーがトランザクションからの最初の書き込みの処理に成功した後、トランザクションからの2番目の書き込みに失敗してしまうことが考えられます(おそらくディスクに空がない、またはネットワークが中断されたなどの理由で)。

もしリーダーとフォロワー間のネットワークが中断されたら、レプリケーションログはリーダーからフォロワーへとデータを渡すことができません。こうして、前にも述べたように、不整合なレプリカができてしまう可能性があります。データベースレプリケーションでは、このようなエラーからどうやって回復し、不整合を防ぐのでしょうか。
ログには非常に素晴らしい特徴があります。リーダーのログは追加専用のため、ログの各レコードに対して、常に増加する連続番号(”ログ位置”または”オフセット”と呼ぶことができるでしょう)を付加できるという点です。また、フォロワーは順次的に(ログ位置の増加順に左から右へ)レコードを処理するため、フォロワーの現在の状態を単一の番号、つまり処理済みの最新レコードの位置で記述できるという点も挙げられます。
ログ内でのフォロワーの現在位置が分かれば、それ以前のレコードは処理済みで、それ以降のものは未処理だということが一目で分かりますよね。
これは素晴らしい特徴で、これによりエラーからのリカバリがとてもシンプルになります。仮にフォロワーがリーダーから切断された場合やクラッシュした場合でも、必要なのは処理済みのレプリケーションログの中から最新のログ位置を保存することだけです。そうしてフォロワーが回復した時にリーダーに再接続し、保存した最新のオフセットから開始するようレプリケーションログに要求を出せば、データの消失や重複なしに、切断中に記録されなかったデータを回復することができます。
ログが全順序で並べられているので、書き込みを個別に記録する場合よりも、リカバリがシンプルになるというわけです。

注釈:ログはあらゆる場所にある
① DBストレージエンジン
② DBレプリケーション
③ 分散合意
④ Kafka
3番目の例は前述の2例とは異なり、分散コンセンサスにおけるログの使用についてお話しします。

注釈:コンセンサス(合意)
“Where shall we have lunch?(どこで昼食を食べるか?)”
Douglas Adams著『The Restaurant at the End of the Univers(宇宙の果てのレストラン)』(1980年)
“どのノードがシャード8のリーダーなのか?”
(クラスタメンバーシップ、ロックマネージャ…)
合意の形成は、分散システムにおいて、たびたび話題に上るよく知られた問題の1つで、重要な反面、その解決は非常に困難です。
日常生活において合意が必要な例といえば、どこに昼食に行くかを友人グループ内で決めるといったような場合です。これは、 洗練された文明 の特徴的な側面であり、場合によっては非常に難しい問題となり得ます。例えば友人の1人が他のことで頭がいっぱいだったり(あるいは満足な回答をくれなかったり)、好き嫌いが多かったりする場合などがそうですね。
一方、コンピュータの領域では、分散データベースシステムにおいて合意を得たい場合がその一例と言えるでしょう。例えば、データベースの特定の部分(シャード)に対するリーダーはどのノードか、ということについては、データベース内の全てのノードが合意しなければなりません。
どのノードがリーダーかについて全ノードの合意を得ることは非常に重要です。もし2つの異なるノードが、それぞれをリーダーと認識した場合、双方ともにクライアントからの書き込みを受け入れることになります。その後、どちらか一方の間違いが判明し、リーダーではなかったことになると、受け入れた書き込み自体が消えてしまうこともあるのです。 スプリットブレイン として知られるこういった状況は、 厄介なデータ損失 につながる恐れもあります。

合意には、いくつかのアルゴリズムがあります。一番知られているのは Paxos かと思われますが、 Zab ( ZooKeeper が使用)や Raft 、また その他にも あります。これらのアルゴリズムは非常に複雑で、一見するだけでは分からない 巧妙 さがあります。そんなわけで、この講演ではRaftアルゴリズムについて、手短に触れるだけにします。
合意のシステムでは、特定の変数がどういう値であるべきかついての合意を管理するいくつかのノード(図では3つ)があります。例えば、クライアントがX=8(ノードXがシャード8のリーダーという意味)という値をRaftノードの1つに送って提案したとしましょう。すると、そのノードは他のノードから票を収集します。この際、もしノードの大半がX=8という値に合意すれば、最初のノードがその値をコミットすることが許可されるというわけです。
値がコミットされた時にはどうなるでしょうか。Raftでは、その値がログの最後尾に追加されます。すなわち、単にノードの間で特定の値の合意を得るというだけではなく、合意された値のログを経時的に構築するのです。Raftの全てのノードは、コミットされた値に関する全く同じシーケンスをログ内に持つことが保証されており、クライアントはこのログを用いることができます。

新たに合意された値が確定してログに追加され、他のノードにレプリケートされると、最初にX=8を提案したクライアントに対して、システムが合意に達しその値がRaftログに新規追加された、という旨が送られます。
(理論的な余談ですが、合意および アトミックブロードキャスト (1回だけの配信でログを作成する)の問題は、 互いに還元できる ということです。これは、Raftによるログの使用が単なる実行記録の便利な細目にとどまらず、懸案の合意の問題の基本的な特徴を反映していることを意味します。)

注釈:ログはあらゆる場所にある
① DBストレージエンジン
② DBレプリケーション
③ 分散合意
④ Kafka
さて、ここまで見てきて、ログというのが、ストレージエンジンやデータベースのレプリケーション、それに合意など、コンピューティングの広い分野で繰り返し使われているテーマだということがお分かりいただけたかと思います。そして、最後の4番目の例としてお話ししたいのが、ログのアイデアを中心にして構築された別のシステムである Apache Kafka についてです。Kafkaの興味深い点は、ログをあなたに対して隠蔽しないということでしょう。ログを実装の詳細として扱うのではなく、それを見えるようにし、中心に据えてアプリケーションを構築できるようにしています。
Kafkaについてはご存じの方もいらっしゃるのではないでしょうか。元はLinkedInで開発されたオープンソースプロジェクトですが、現在は多くのコントリビュータやユーザによるApacheの活発なプロジェクトとなっています。

Kafkaの代表的な使用例は、メッセージブローカ(メッセージキュー)です。そのため、ある意味ではAMQPやJMS、その他のメーセージシステムに相当すると言えるでしょう。Kafkaのクライアントタイプには、プロデューサ(Kafkaにメッセージを送信)とコンシューマ(Kafka内のメッセージストリームを取得)の2種類があります。
たとえて言うなら、プロデューサはWebサーバやモバイルアプリです。「どのユーザが、どのリンクを、どのタイミングでクリックした」というイベントのようなログ情報をKafkaに送信します。それに対してコンシューマは、発生している事柄を知る必要がある各種プロセスのことで、例えば分析の生成、異常活動の監視、各ユーザに最適化された推奨事項の生成などが挙げられます。
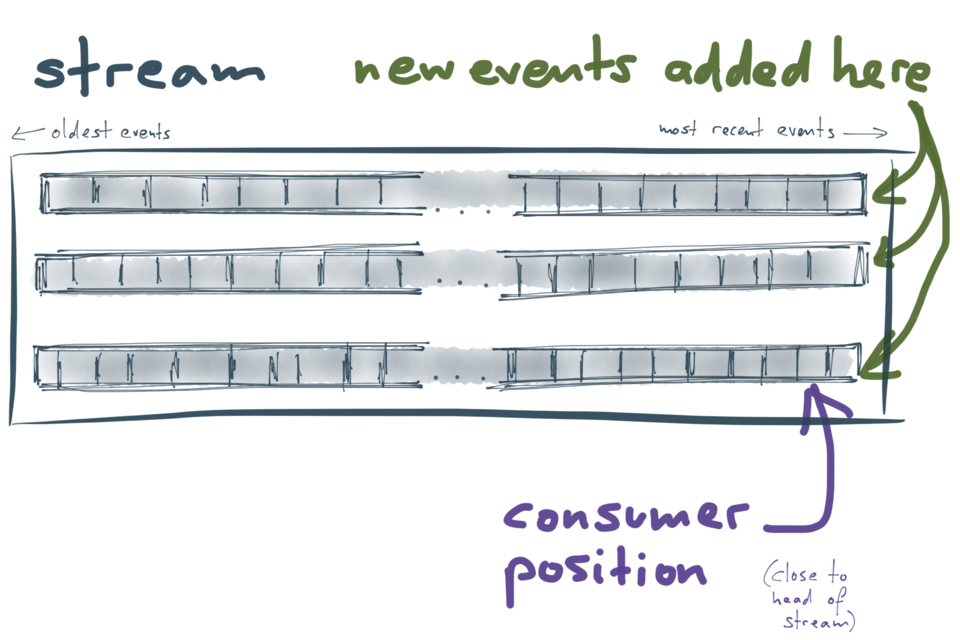
Kafkaと他のメッセージブローカとの興味深い相違点は、Kafkaがログとして構造化されており、実際に多くのログを有していることです。Kafkaではデータストリームはパーティションに分割され、各パーティションがログ(全順序で並べられたメッセージシーケンス)として機能します。それぞれが独立したパーティションのため、異なるパーティション間での順序付けの保証はありませんが、これにより、パーティションごとに別々のサーバで処理することが可能となります。これはKafkaのスケーラビリティにとって重要な点です。
各パーティションはディスクに保存され、複数のマシンに複製されるので、堅牢ですし、マシンの障害時でもデータの損失は避けられます。ログの生成と使用については、前述のデータベースレプリケーションの場合とほぼ同様です。
- Kafkaに送信される全てのメッセージは、パーティションの最後に追加されます。ログの最後尾への追加が、Kafkaがサポートする唯一の書き込み方法です。なお、過去のメッセージを変更することはできません。
- 各パーティション内のメッセージには、一方向的に増加する オフセット (ログ位置)が付加されています。クライアントがKafkaからメッセージを利用する際は、特定のオフセットからメッセージを順次読み取ります。オフセットを管理するのはコンシューマです。
ここで、冒頭のデータ統合の問題に立ち返ってみましょう。
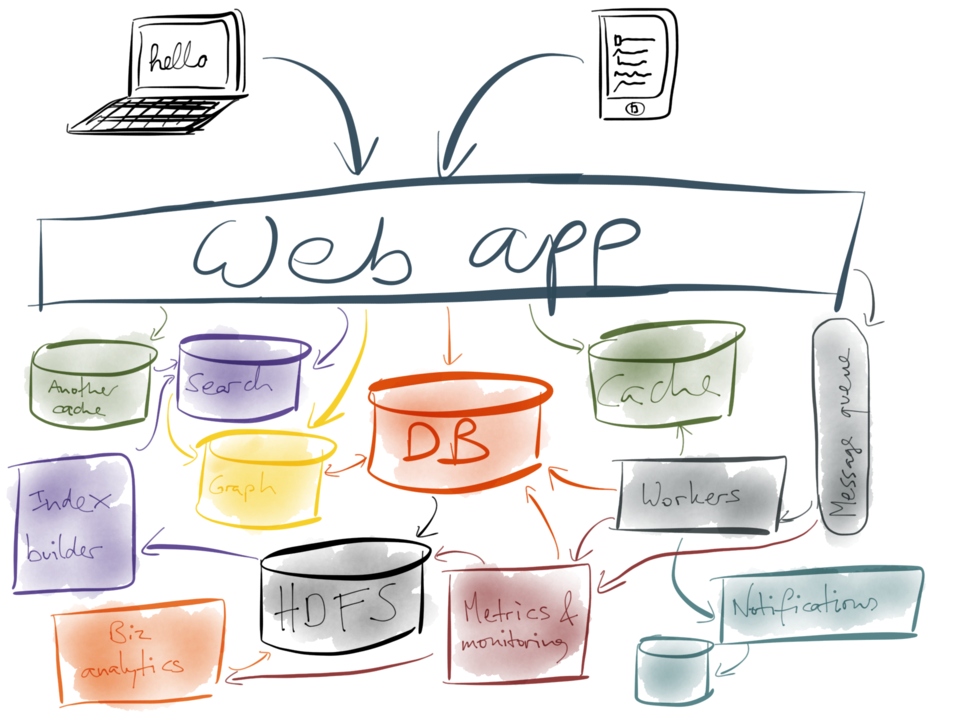
入り乱れた状態のデータストアやキャッシュ、それにインデックスを互いに同期させる必要があるとしましょう。私たちは、ここまでにログの実用的な応用例を数多く見てきましたよね。そこで、学んだことを通じて、これらのシステムをより良く構築する方法を見つけ出すことはできるでしょうか。
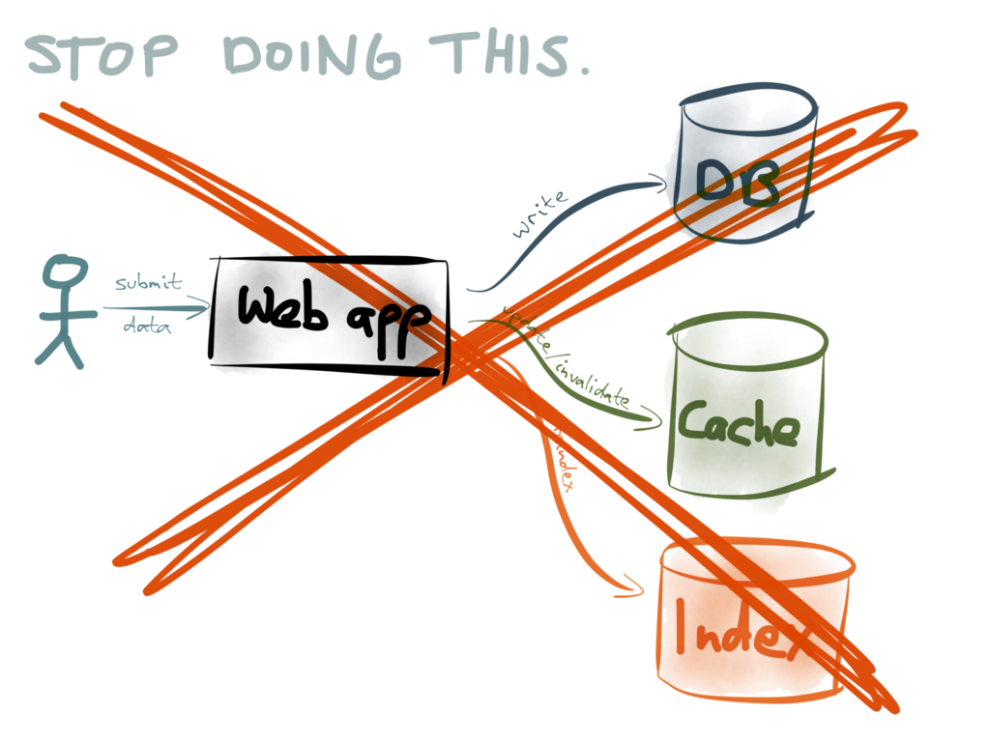
まず、デュアル書き込みは止めましょう。上で説明したように、アプリケーションで発生する潜在的な競合状態と部分的な障害について慎重に考慮していない限り、データの整合性に支障をきたす恐れが生じます。
この不整合は、非同期システムでしばしば引用される”結果整合性”といった類いのものではなく恒久的なものです。つまり、競合状態または部分的な障害により、2つの異なるデータストアに別々の値を書き込んだ場合、その違いは自律的には解決されないため、明示的なアクションでデータの不整合を検索する必要があります(が、データは絶えず変化しているので、それはなかなか難しいことです)。
異なるデータストアの同期を維持するためには、デュアル書き込みよりも優れたアプローチが必要となります。

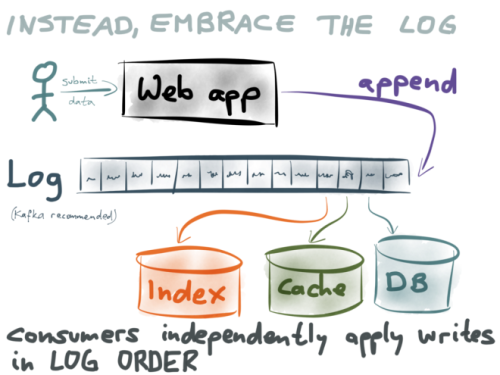
私の提案は、アプリケーションから各種データストアに直接書き込むのではなく、(Kafkaのように)ログにデータを追加するのみにとどめるというものです。このデータ(データベースや キャッシュ やインデックス)の個別の表示については、順番にログを利用することで構成されます。
同期が必要な各データストアは独立したログ・コンシューマです。全てのコンシューマは1レコードずつログのデータを取り、それ自体のデータストアに書き込みます。そしてログは、コンシューマが同じ順序でレコードを認識していることを保証します。同じ順序で書き込みを適用することで、競合状態の問題はなくなるのです。先に説明したデータベースレプリケーションの場合と非常に似通っていますよね。
では、部分的な障害の問題についてはどうでしょうか。もしデータストアの1つに問題が生じ、しばらくの間、書き込みができなくなった場合はどうなると思いますか。
この問題もまた、ログによって打開されます。各コンシューマは、自分がすでに処理した位置までのログを追跡しています。データストアに書き込んでいるコンシューマ内のエラーが解決されると、そのコンシューマは最後に処理した位置からログ内のレコードの処理を再開できます。このように、データストアは、しばらくオフラインになっても、最新情報を失うことはありません。このことは、システムを複数の部分に分離するときに非常に役立ちます。1つのデータストアに問題があっても、システムの残り部分は影響されずに済むのです。
ここでも、書き込みを全順序で記録するという単純なアイデアであるログは、非常に優れた手段になります。
それでも問題が1つあります。ログのコンシューマは皆、非同期でデータストアを更新するので、最終的には整合します。これらのデータストアからの読み出しは、データベースフォロワーからの読み出しに似ています。つまり、最新の書き込みより少し遅れるので、 read-your-wites(自分の書き込みの読み出し) は保証されません(もちろん、 linearizability(線形化能力) も保証されません)。
この問題は、ログの最上部に トランザクションプロトコル を重ねることで克服できるかもしれないと私は考えますが、まだ研究段階にあって、プロダクション段階のシステムに広く実装されてはいません。現在での良策は、データベースからログを引き出すことです。

この手法は、 change data capture と呼ばれ、私は最近 これに関する記事 を書き、 PostgreSQLに実装 しました。単一のデータベースだけに書き込んでいる(デュアルで書き込んでいない)限り、また、そのデータベースから(DBにコミットされた順序で)書き込みのログを取得している限り、この手法は、書き込みを直接ログに行っているのと同様に機能します。
ログの前にあるこのデータベースが同期して書き込みを適用するので、これを使って、「即時の整合性」(線形化能力)が必要な読み出しを行い、制約(例えば、勘定残高は負の値にならない、など)を課すことができます。データベースを介して業務を行うことは、ログを自分のレコードシステムとして信用する(新しい技術で実装されている場合は恐ろしい期待かもしれません)必要がないということを意味します。自分がよく知っていて気に入っている既存のデータベースがあり、そのデータベースから変更ログを引き出せるのなら、ログ指向アーキテクチャの利点も有効に活用できます。この話題については、 今後のカンファレンストーク でお話しします。
最後に、思考実験で締めくくりたいと思います。

私たちが扱うほとんどのAPIには、読み出しと書き込みの両方のエンドポイントがあります。REST的な用語では、GETは読み出し(つまり、副作用のない操作)、POST、PUT、DELETEは書き込みを意味します。これらの書き込みのエンドポイントは、書き込み先のシステムが1つだけの場合には支障ありませんが、複数のシステムがある場合は、すぐにデュアル書き込みになって、前述した問題がすべて発生してしまいます。
書き込みのためのエンドポイントをすべてなくしたAPIをもつシステムを考えてみてください。GET要求はすべて残しておくが、POST、PUT、DELETEを禁止すると考えます。その代わり、システムに書き込みを送る唯一の方法は、ログに書き込みを追加して、システムにログを使わせることです。(ログはシステムの外にあることが必要で、同一のログに複数のコンシューマを当てることができます。)
例えば、RESTのAPIを通じてドキュメントを書き込むことはできず、Kafkaに送ることによってのみドキュメントを書き込む、Elasticsearchの変種を考えます。Elasticsearchには、ドキュメントを取り、インデックスに追加するKafkaコンシューマが内蔵されているでしょう。このことにより、同時性の制御に配慮する必要がなくなるので、Elasticsearchの内部処理が実際に簡素化され、複製の実装が簡素化されます。そして、同じログを使う他のツールの隣にきちんと納まることでしょう。
このログ指向アーキテクチャの、私が好きな特徴は、新規に派生させたデータストアを構築したい場合に、ログの最初に新規コンシューマを開始して、すべての書き込みをデータストアに適用しながら頻繁にログの履歴の中を見ていくことができることです。最後まで来たら、データセットに新しいビューが得られ、ログを使い続けるだけで最新の状態を維持することができるのです。
このことにより、例えば別の方法でインデックス付けするなど、既存のデータを表現する新しい方法を試すことが非常に簡単になります。既存のどのデータにも干渉することなく、実験的な新しいインデックスやビューをデータに構築することが可能です。結果が良ければ、新しいビューから読み込むようにユーザを移行させることができるし、結果が悪ければ、使わずに捨てることもできます。この特徴によって、アプリケーションの実験と改造に非常に大きな自由が得られるのです。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事