2016年9月7日
NoSQLデータベース:調査と決定のガイダンス(その3)

(2016-08-15)by Felix Gessert
本記事は、原著者の許諾のもとに翻訳・掲載しております。
追記専用 ストレージ(ログ構造化ストレージとも呼ばれます)は、順次書き込みをすることでスループットの最大化を実現しようとします。ログ構造化ファイルシステムの研究の歴史は長いものの、追記専用入出力がデータベースに関して普及したのは、BigtableでLSM(Log-Structured Merge)ツリーが使用されたからです。このLSMツリーは、インメモリキャッシュ、ハードディスク保存ログ、不揮発性メモリおよび定期的に書き込みされるストレージファイルで構成されています。LSMツリーや変種のSAM(Sorted Array Merge)ツリー、COLA(Cache-Oblivious Look-ahead Arrays)は多くのNoSQLシステムに導入されています(Cassandra, CouchDB, LevelDB, Bitcask, RethinkDB, WiredTiger, RocksDB, InfluxDB, TokuDB)。「常にログに書き込むことで書き込みパフォーマンスの最大化を実現する」という設計はシンプルですが、難しいのは高速な読み取りをランダム/シーケンシャルの両方で実現することです。これには、適切なインデックス構造を必要とし、書き換え時にコピーするコピーオンライト(COW)データ構造(例、CouchDBのコピーオンライトBツリー)にするか、定期的に保存される永続データ構造(例、Bigtableスタイルのシステム)にする必要があります。どのログ構造のアプローチにも、「更新または削除されたアイテムのスペースを再利用する際のガベージコレクション(コンパクション)が高コストになる」という問題を抱えています。
IaaSクラウドコンピューティングサービスのように仮想化された環境においては、議論されている根本的なストレージレイヤの特性は見えていません。
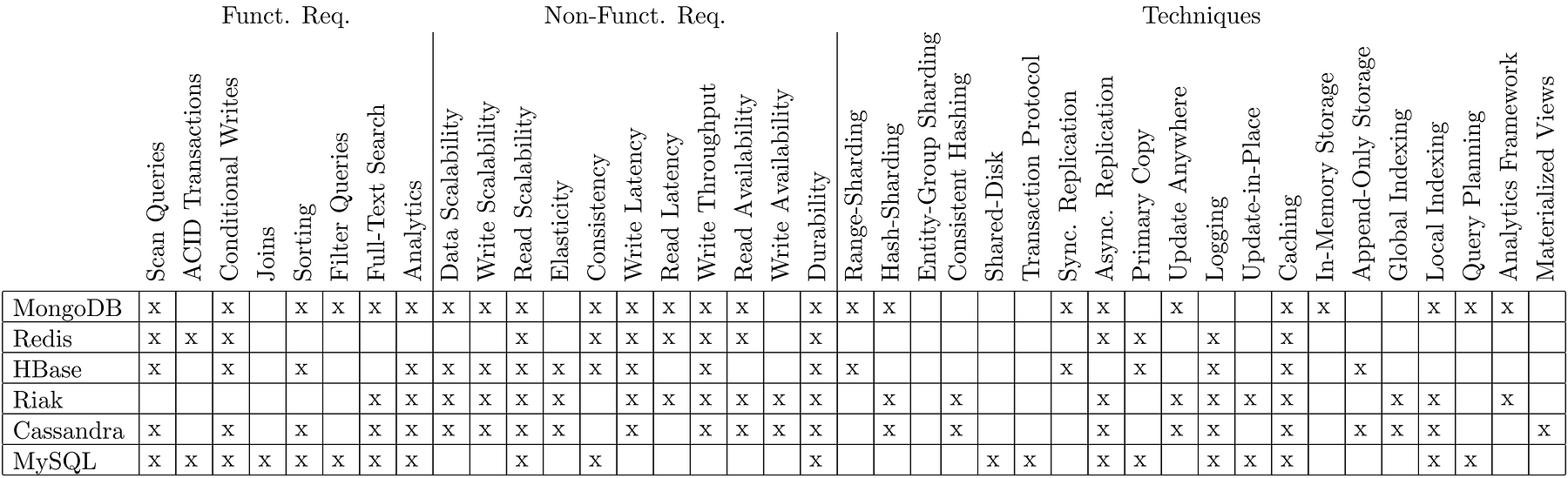
表1:MongoDB、Redis、HBase、Riak、Cassandra、MySQLの機能要件、非機能要件、そして実装技術を我々のNoSQLのツールボックス用いて比較。
3.4 クエリ処理
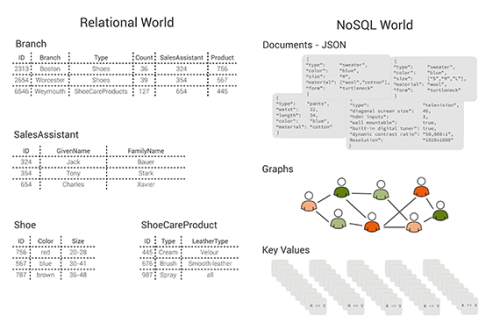
NoSQLデータベースのクエリ機能は、主に独自の分散モデルや一貫性の保証、データモデルによって得られています。例えば特殊なIDでデータ項目を取り出すことのできる プライマリキールックアップ は、レンジ及びハッシュパーティションに対応しているため、すべてのNoSQLシステムによってサポートされています。 フィルタクエリ は、1つのテーブルからデータ項目のプロパティ上で指定された述語を満たすすべての項目(あるいは投影)を返します。最も単純な形態のものは、 フィルタされた全表スキャン として機能します。ハッシュパーティション化されたデータベースにおいては、これは スキャッタギャザ 処理に似ており、パーティションの間でフィルタ述語の実行、結果の統合を行います。レンジパーティション化されたデータベースにとっては、パーティションを選択する際にレンジ属性のどの条件も役立てることができます。
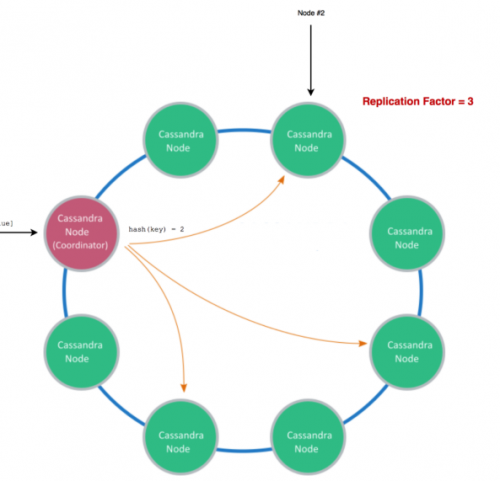
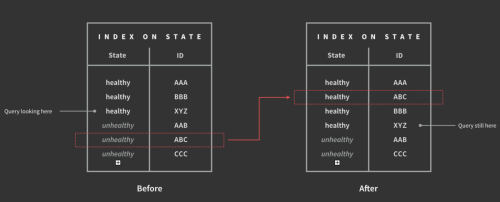
O(n)スキャンの非効率性を回避するために、二次インデックスを用いることができます。それぞれのパーティションで管理されている ローカル二次インデックス か、すべてのパーティションのデータをインデックスする グローバル二次インデックス を用いることになります。グローバル二次インデックスの場合は、複数のパーティションに分散されていなければならないため、一貫性のある二次インデックスを保持するには、遅く存在していないかもしれないコミットプロトコルが必要となります。そのため、実際多くのシステムではこれらのインデックス(例:Megasore、Google AppEngine Datastore、DyanamoDB)に対する結果整合性のみをサポートしているか、あるいは全くサポートしていません(例:HBase、Azure Table)。ローカル二次インデックス上でグローバルクエリを実行する場合、クエリ述語とパーティションルールが重なっていれば、パーティションのサブセットのみに的を絞ることができます。そうでなければ、結果はスキャッタギャザ処理で統合しなければなりません。例えば、年齢でレンジパーティションされたユーザテーブルを考えます。この場合、年齢に関する等価条件を持つクエリに対しては1つのパーティションから結果を返せばいいのですが、名前に対するクエリがあった場合は、それぞれのパーティションを評価する必要があります。グローバル二次インデックスの特例が、全文検索です。選択されたフィールドや全データ項目が、データベースの転置インデックス(例:MongoDB)へ入力されるか、ElasticSearchやSolr(Riak Search、DataStax Cassandra)などの外部の検索プラットフォームに入力されます。
クエリプランニング とは、実行コストを抑えるためにクエリ実行プランを最適化する作業です。集約や結合をするクエリは、効率が悪く、アプリケーションコードを実装するのが難しいため、このような場合にクエリプランニングは不可欠となります。最近のNoSQLシステムは、2つの理由からリレーショナルクエリ処理に関する豊富な文献や結果を度外視しています。まず、key-valueとワイドカラムモデルは、プライマリキーに対するCRUDとスキャン操作を中心としているため、クエリの最適化を実現するだけの余裕がほとんどありません。次に、分散クエリ処理においては、レイテンシよりもスループットを優先するOLAP(オンライン分析処理)ワークロードが関心を集めています。それに比べると、シングルノードクエリの最適化はパーティションしたデータベースやレプリカしたデータベースに適用するのは簡単ではありません。それでも、特に文書データベースという意味では、多くの適用可能なクエリ最適化技術を一般化するための研究はまだ課題として取り組む余地があります(現在のところ、RethinkDBでのみ一般的なΘ結合の実行が可能です。MongoDBの集約フレームワークでは、左外部の等結合をサポートし、CouchDBでは宣言される前のMapReduceビューの結合が可能です)。
インデータベース分析 はネイティブに実行する(例:MongoDB、Riak、CouchDB)か、HadoopやSpark、Flinkなどの外部の分析プラットフォーム(例:Cassandra、HBase)を使用して実行することができます。NoSQLシステムによって公開され、普及したネイティブバッチ処理の抽象化が MapReduce になります(MapReduceの代わりとなるのが、 一般化されたデータ処理パイプライン で、複数の宣言型クエリ言語をベースにデータの流れやコンピューティングの局所性などを最適化しようとします。例:MongoDBの集約フレームワーク)。入出力が原因で通信オーバーヘッドや限定的実行計画の最適化、バッチやマイクロバッチ指向の処理などの応答時間が長くなってしまいます。 マテリアライズドビュー は、クエリ応答時間の短い代替手段となります。デザイン時に宣言され、変更操作のたびに継続的に更新されます(例:CouchDB、Cassandra)。しかし、グローバル二次インデックスのように、システム分散時に、高速で高可用性の書き込みが優先されるため、ビューの一貫性は犠牲となります。無制限のデータストリームの取り込みやクエリをサポートする機能を内蔵したデータベースシステムは少ないため、 ほぼリアルタイム分析 のパイプラインは、一般的に Lambdaアーキテクチャ か Kappaアーキテクチャ のどちらかを実装しています。Lambdaアーキテクチャは、Hadoop MapReduceのようなバッチ処理フレームワークをStormなどのストリームプロセッサで補足することができます( Summingbird を例として参照してください)。Kappaアーキテクチャは、ストリーム処理のみに頼り、バッチ処理は完全に諦めています。
4. システムのケーススタディ
このセクションでは、key-valueストア、ドキュメントストア、ワイドカラムストアの定性的に比べています。比較結果を凝縮した形で提示し、詳細についてはそれぞれのシステムのドキュメントを参照しています。ここで提案しているNoSQLツールボックス( 図4 を参照)を抽象化の手法とし、機能要件、非機能要件、そして実装技術の3つの側面からデータベースシステムを分類しています。この分類によって多くのデータベースシステムをうまく特徴付けることができたため、異なるデータシステムの対比が意義深いものになったと断言できます。表1では、MongoDB、Redis、HBase、Riak、Cassandra、MySQLをデフォルト構成状態で比較しました。さらに中央システムのプロパティの詳細な比較を行い、記事の最後の表2に表示しました。
特定のシステムプロパティを特定する際に使用した手法は、一般的に入手可能なマニュアルや文献を用いてシステムを詳細に分析して作成しました。さらに、オープンソースコードごとに調査したり、開発者に直接問い合わせしたりし、また実践に基づいたメタ分析レポートやベンチマークを見たりしなければ評価できなかったプロパティも中にはありました。
詳しくは ICDE 2016チュートリアル のスライドを参照してください。ここでは、異なるNoSQLシステムを詳細に説明しています。
NoSQL Data Stores in Research and Practice – ICDE 2016 Tutorial – Extended Version from Felix Gessert
比較することでSQLとNoSQLのデータベースは非常に異なる需要を満たすようにデザインされていることを明らかにしています。RDBMSが並ぶもののなりレベルの機能を備えているのに対し、NoSQLデータベースはスケーラビリティと可用性、低いレイテンシ、高いスループットなど優れた非機能的側面を持っています。しかし、それぞれのNoSQLデータベースには大きな違いもあります。例えば、RiakとCassandraは多くの非機能要件を満たすことができる反面、結果整合性のみを持ちデータ分析以外の機能はあまり考慮されていません。Cassandraに関して言えば、条件的更新機能も考慮されています。その一方でMongoDBとHBaseは、強力な一貫性やクエリでスキャンするような洗練された機能を実現しています。MongoDBのみにフィルタクエリ機能がありますが、パーティション化の時の読み込みや書き込みの可用性を維持せず、高い読み取りレイテンシを表示する傾向にあります。MySQL以外で唯一パーティション化していないシステムであるRedisは、インメモリデータ構造と非同期のマスタースレーブ型レプリケーションを使用して低いレイテンシで非常に高いスループットを維持することを優先するための犠牲を払っています。
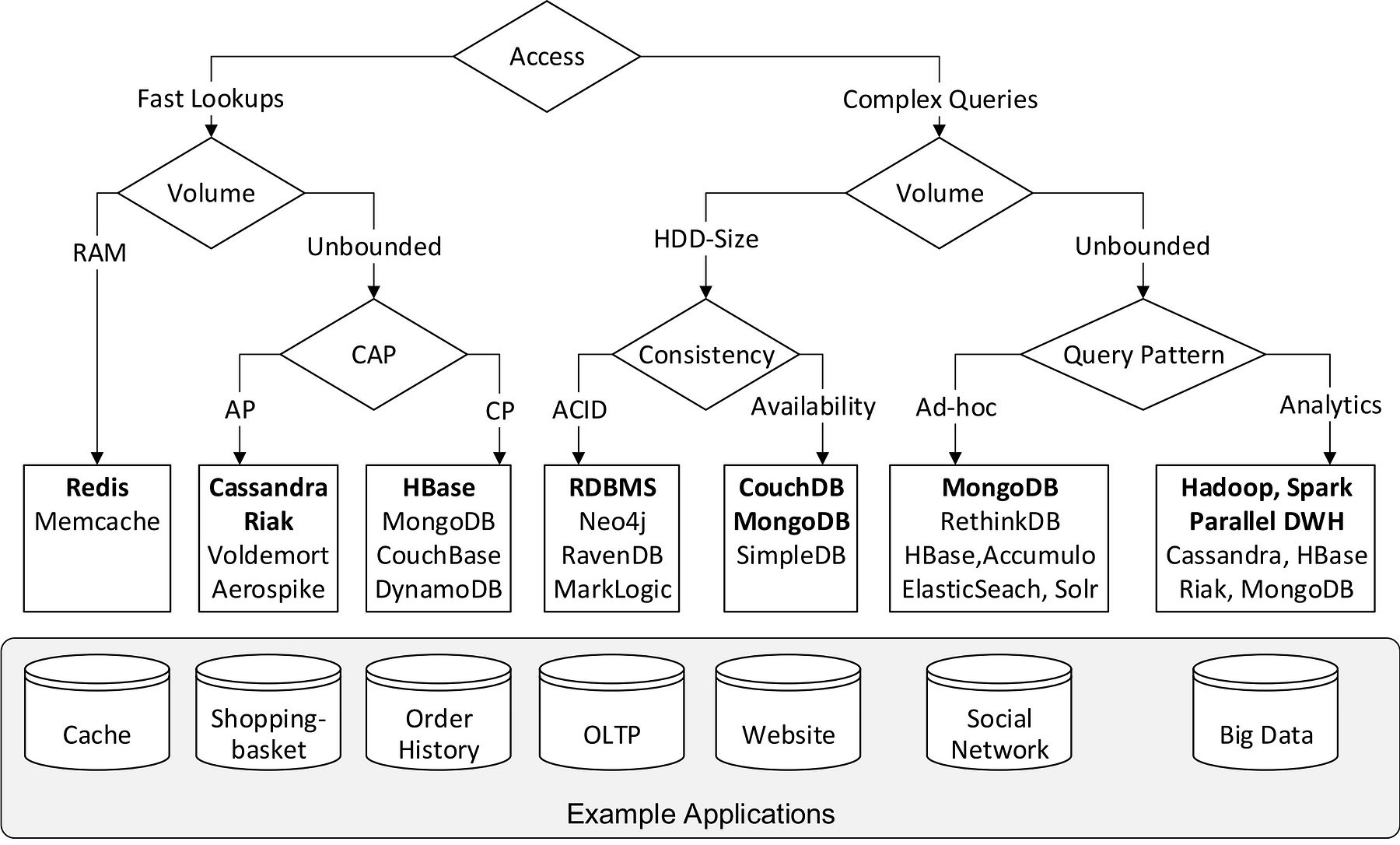
図6: (NoSQL) データベースシステムに要件をマッピングするためのデシジョンツリー。
5. 結論
データベースシステムを選ぶということは、欲しい性質のセットを1つに絞らなければならないということです。この難しい選択を簡単にするために、 図6 の二分決定図で、アプリケーションを例に決断に必要な犠牲と適していると思われるデータベースシステムをマッピングしています。簡単なキャッシング(左)からビッグデータ分析(右)までのアプリケーションの範囲を葉ノードは対象としています。当然、問題空間に関する観点は十分とは言えませんが、特定のデータ管理問題の解決策の方向性を漠然と示しています。
最初の分岐はアプリケーションのアクセスパターンに基づいています。高速ルックアップのみ(左半分)に頼っているかさらに複雑なクエリ能力(右半分)を必要とするかのどちらかです。高速ルックアップアプリケーションは処理するデータ量によってさらに違いが分かります。もし、すべてのデータを1つのマシンのメインメモリで保持することができる場合、シングルノードシステムのRedis(機能重視)かMemcashe(簡潔重視)を用途に応じて選択するのが最善策でしょう。もしデータ量がRAMの許容量を超えているか超える予定がある、または、無制限である場合、水平スケーラビリティのあるマルチノードシステムの方が適しているでしょう。ここで最も重要となる決断は、前述のCAP定理で説明した可用性(AP)と一貫性(CP)のどちらを優先するのかです。CassandraやRiakのようなシステムは常時接続を実現し、HBaseやMongoDB、DynamoDBは強力な一貫性を実現しています。
デシジョンツリーの右半分では、簡単なルックアップではなくさらに複雑なクエリを必要とするアプリケーションを対象にしています。ここでもまず、処理するデータ量でシステムを区別し、シングルノードシステムで実現可能なのか(HDDの大きさ)、それとも分散を必要とするのか(無制限)を考慮しています。データ量がやや多い一般的なOLTP(オンライントランザクション処理)ワークロードでは、ACID特性を持っている従来のRDBMSあるいはNeo4Jのようなグラフデータベースが最適です。しかし、可用性を重要視する場合は分散システムであるMongoDB、CouchDB、DocumentDBのいずれかがいいでしょう。
データ量がマシン単体の許容範囲を超えた場合、どのシステムを選ぶかは一般的なクエリパターンに左右されます。例えば、SNSアプリケーションにおいて、レイテンシのために複雑なクエリを最適化しなければならない場合、表現力のあるアドホッククエリが使用できるMongoDBは非常に魅力的でしょう。同じような場面でHBaseやCassandraも役に立つでしょう。しかし、Hadoopと組み合わせるとスループットを最適化したビッグデータ分析を得意とします。
要約すると、提案したトップダウンモデルは、主要な要件に基づいた膨大な数のNoSQLデータベースシステムを効果的にフィルタすることで、決断を手伝ってくれると信じています。さらにNoSQLツールボックスは機能要件と非機能的要件を共通の実装技術にマッピングし、進化しつつあるNoSQLスペースを分類してくれます。
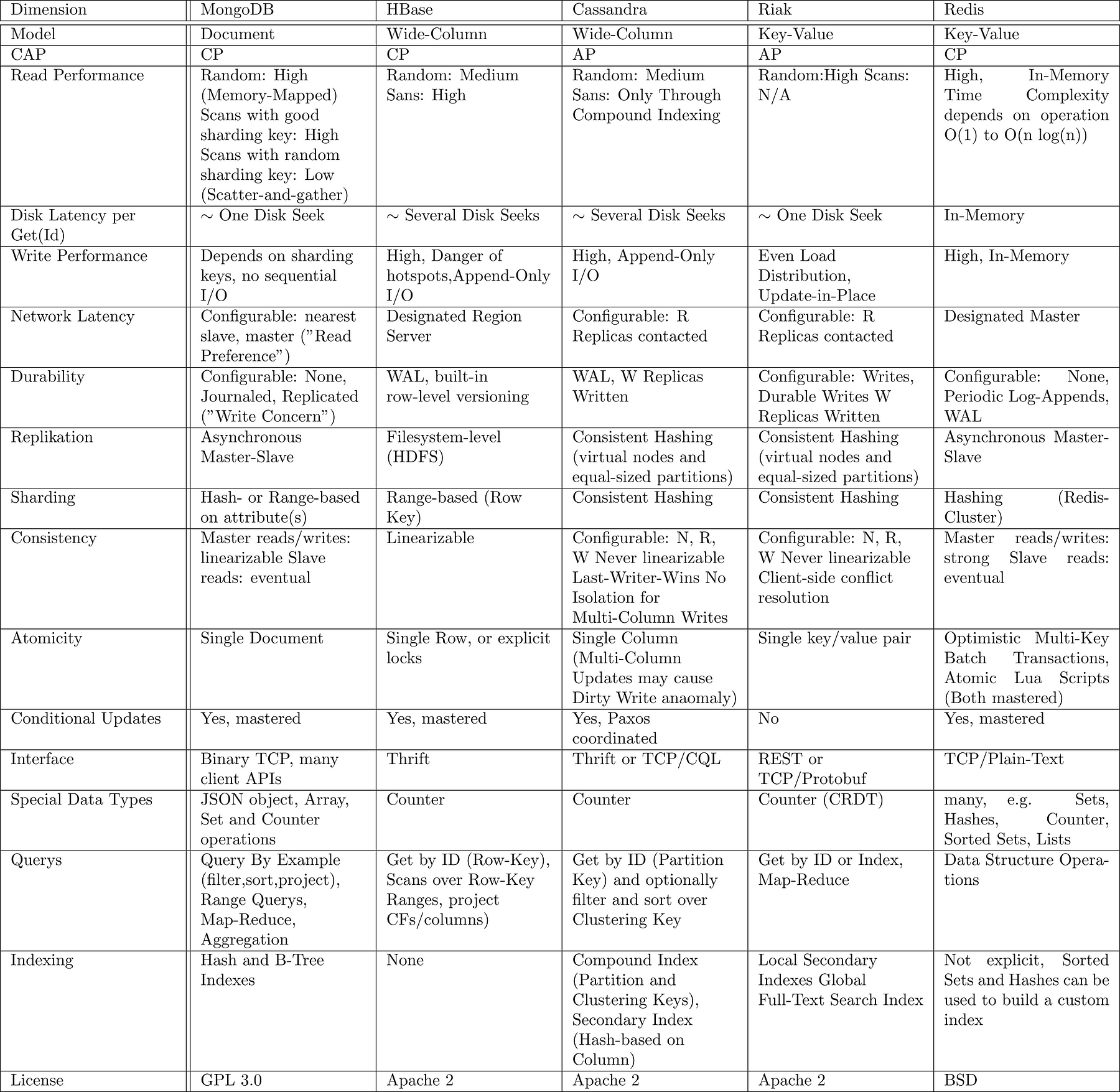
表2: MongoDB、Redis、HBase、Riak、Cassandra、MySQLの定性的比較

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事