2016年9月5日
NoSQLデータベース:調査と決定のガイダンス(その1)

(2016-08-15)by Felix Gessert
本記事は、原著者の許諾のもとに翻訳・掲載しております。
(訳注:2016/10/1、頂きましたフィードバックを元に記事を修正いたしました。)
先月、ハンブルク大学の同僚たちと一緒に SummerSOC 2016 でNoSQLの状況についての講演をしました。メンバーは、 Felix Gessert 、 Wolfram Wingerath 、 Steffen Friedrich 、 Norbert Ritter でした。今回はその講演の要点を記事にまとめました。 Baqend を設立して集めた、私たちのNoSQLの濃厚な知識が皆さんに伝われば幸いです。

要約
現在、データはかつてない規模で生み出され、消費されています。増え続けるデータ量とリクエスト負荷に対応するために、「NoSQL」データベースシステムという用語で包括されるスケーラブルなデータマネジメントの新しい方法が産み出されてきました。しかし、数多く存在するシステムは、不均一で多様性があるので、アプリケーションのコンテキストに適したデータストアを正確に選択するのは難しくなっています。したがって、この記事ではこの分野に関して俯瞰的に説明していこうと思います。つまり、実装の例を詳細にそれぞれ比べていくのではなく、NoSQLデータベースで採用されている技術やアルゴリズムを機能要件/非機能要件に関連付ける相対的な分類モデルを提議していきます。このNoSQLツールボックスによって、実行者や研究者は中心となるアプリケーション要件をもとに使えそうなシステムの候補を選び出す意思決定のルールを得られるでしょう。
1. イントロダクション
従来的なリレーショナルデータベース管理システム(RDBMS)は、強力な一貫性とトランザクション保証のもと、構造化データの格納/クエリのための強力なメカニズムを有しています。さらに、何十年に及ぶ発展を経て、無類の信頼性、安定性と、サポートも築き上げてきました。しかしここ数年では、一部の分野のアプリケーションで、使えるデータが莫大な量になり過ぎて、従来のデータベース・ソリューションでは格納/処理がしきれなくなりました。ソーシャルネットワーク内でユーザーが生成したコンテンツや、巨大なセンサーネットワークから取り出されたデータは、一般的に ビッグデータ と言われるものの中の一例です。ビッグデータを扱うことのできる新しいデータストレージシステムのうち、ある一部のものは NoSQLデータベース という用語で総称されます。NoSQLデータベースの多くは、クエリの性能や一貫性の保証を犠牲にする代わりに、水平スケーラビリティや、リレーショナルデータベースより高い可用性を提供しています。これらのトレードオフは、サービス指向コンピューティングやAs-a-Serviceのモデルには非常に重要です。なぜなら、あらゆるステートフルなサービスのスケーラビリティや耐障害性は、使っているデータストアのそれ以上にはならないからです。
NoSQLデータベースのシステムは山ほどあり、それぞれの長所・短所・違いなどをすべて見ていくのは困難です。実装の詳細はすぐに変化しますし、機能は時間と共に進化していくからです。ですから、この記事では、システムの特異性を説明していくのではなく、採用されているコンセプトを検討することでNoSQLの地平を俯瞰していきます。また、NoSQLデータベースのシステムに求められる一般的な要件を探っていき、そのの要件を満たす技術や、その過程で発生するトレードオフについても探っていきます。今回焦点を当てていくのは、key-valueとドキュメント、ワイドカラムストアの3つです。なぜなら、NoSQLにおけるこの3つの区分は、スケーラブルなデータ管理の設計空間に最も強く関連する技術/設計上の決定事項だからです。
セクション2では、「データモデルがkey-valueストア/ドキュメントストア/ワイドカラムストアのどれであるか」「設計における安全性/活性のトレードオフ(CAPやPACELC)」によってNoSQLデータベースシステムをカテゴライズする、最も一般的で高次元なアプローチを説明します。そしてセクション3では、一般的に使われている技術をより詳細に概説し、さらに、要件と技術がどのように関係しているのかというモデルを議論していきます。次のセクション4では、私たちのモデルを使って、いくつかの優れたデータベースシステムの概観を示していきます。最後のセクション5では、アプリケーション要件をもとに適切なNoSQLシステムの選択を限定する、シンプルで抽象的な決定モデルを説明して締めくくります。
2. 高次元なシステムの分類
各NoSQLシステムの実装の詳細を抽出するために、高次元な分類基準を使って、類似したデータストアをジャンル分けしていくことができます。このセクションでは、最も優れた2つのアプローチを紹介していきます。データモデルと、CAP定理です。
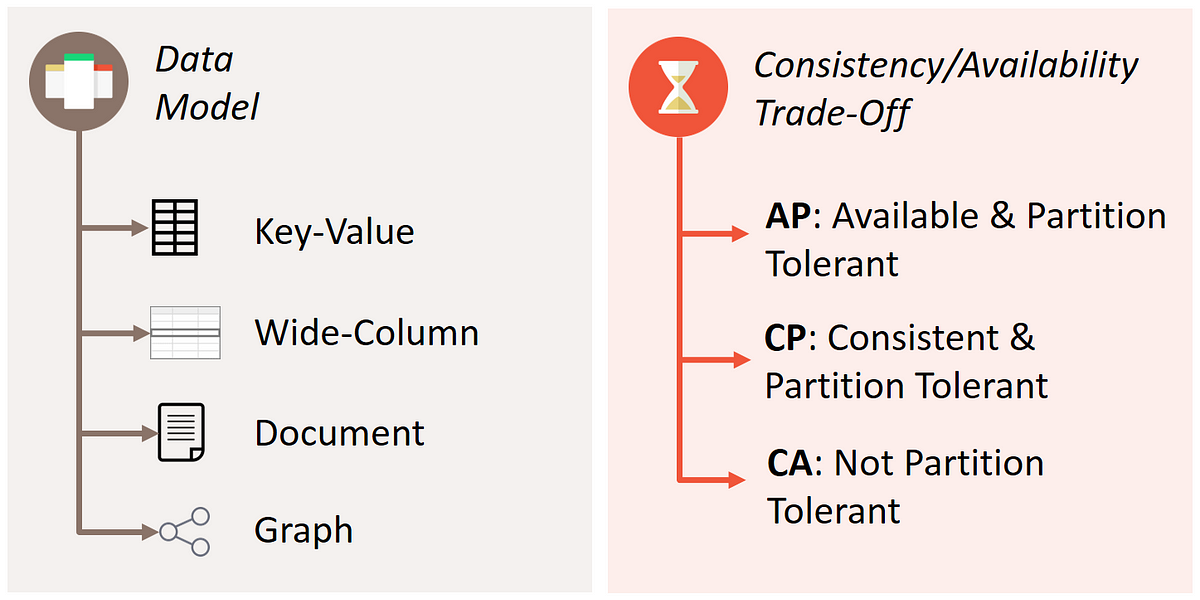
*注釈:
右の図
一貫性と可用性の犠牲
– AP:可用性+分断耐性
– CP:一貫性+分断耐性
– CA:分断耐性ではない
*
2.1 様々なデータモデル
各NoSQLデータベース間の最も一般的な違いは、格納の仕方と、データへのアクセスの許可の仕方です。この記事で扱う各システムは、key-valueストア、ドキュメントストア、ワイドカラムストアのいずれかに分類されます。
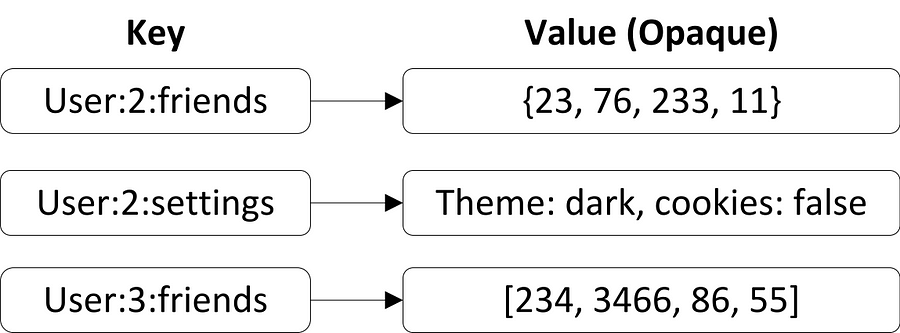
図1:key-valueストアは、効率的なストレージを持ち、任意の値を検索できる。
2.1.1 key-valueストア
key-valueストアは、固有のキーを持つkey-valueのペアで構成されています。このようなシンプルな構造のため、書き込みと読み出しの動作しかサポートされていません。格納されている値はデータベースに対して透過的なので、純粋なkey-valueストアは、シンプルなCRUD(Create作成、Read読み出し、update更新、Delete削除)以上の動作はサポートしていません。それゆえ、key-valueストアはしばしば スキーマレス と言われます。つまり、格納されたデータの構造に関するどんな前提も、暗黙のうちにアプリケーションロジックでエンコードされ( Schema on Read )、データ定義言語を介して明確には定義されません( Schema on Write )。
このデータモデルの明らかな利点は、シンプルであるということです。非常にシンプルな抽象化なので、データを簡単に分割/クエリすることができます。ですから、このデータベースシステムは低いレイテンシと高いスループットを獲得できています。しかし、アプリケーションがより複雑な動作を要求する場合は(例えば、範囲クエリ)、このデータモデルでは力不足です。 図1 は、ユーザアカウントのデータと設定がkey-valueストアにどのように格納されるかの一例を示しています。シンプルな検索よりも複雑なクエリはサポートされないので、例えば「cookieがサポートされているか?」などの情報を引き出すためには、アプリケーションコード内でデータに対して非効率的な解析を行わなければなりません。
3.1.2 ドキュメントストア
ドキュメントストアは、JSONドキュメントのような半構造化のフォーマットにvalueを限定するkey-valueストアです。key-valueストアに比べてドキュメントストアにはこの限定があるためで、データへのアクセスの柔軟性が高くなります。IDによってドキュメント全体を取得できるようになるだけでなく、ドキュメントの一部だけを読み出すことや(例えば顧客の年齢)、問い合わせを実行することができます(例えば、アグリゲーション、例示による問い合わせ、全文検索さえもできます)。

図2:ドキュメントストアは、格納されているエンティティの内部構造を認識しているので、クエリをサポートできる。
3.1.3 ワイドカラムストア
「データがまばらな列を多く持つ関係テーブル」といった、基本的なデータモデルを説明するためにしばしば使われるイメージから名づけられたのがワイドカラムストアです。しかし、細かく言うと、ワイドカラムストアというのは、分散型のマルチレベルのソート済みマップに近いです。第一レベルのキーは、それ自身key-valueのペアで構成されている列を定めます。第一レベルのキーのことを 行キー と言い、第二レベルのキーを 列キー と言います。このストレージスキームにおいては、対応する値がない場合は列キーもないので、任意に多くの列があるテーブルに適しています。したがって、NULL値は、スペースのオーバーヘッドなしに格納することができます。すべての列の集合体は 列ファミリ と呼ばれる単位に区切られ、通常一緒にアクセスされるカラムをディスク上の同じ場所に配置します。ディスク上では、ワイドカラムストアは各行からのすべてのデータを同じ場所に配置せず、代わりに同じ行の同じ列ファミリの値を配置します。したがって、ドキュメントストアのようにエンティティ(行)を1つの検索で読み出すことができず、すべての列ファミリの列を結合させる必要があります。しかし、このストレージのレイアウトは通常、高効率のデータ圧縮を可能にし、エンティティの一部だけを非常に効率よく読み出せます。データはキーの辞書式順序で格納されているので、注意深いキーデザインがされていれば、一緒にアクセスされるデータは物理的に同じ場所に配列されます。すべての行が、様々な tabletサーバ の中の隣接する範囲( tablet と呼ばれる)に分散されるので、行のスキャンは少数のサーバしか含まず、非常に効率的なのです。
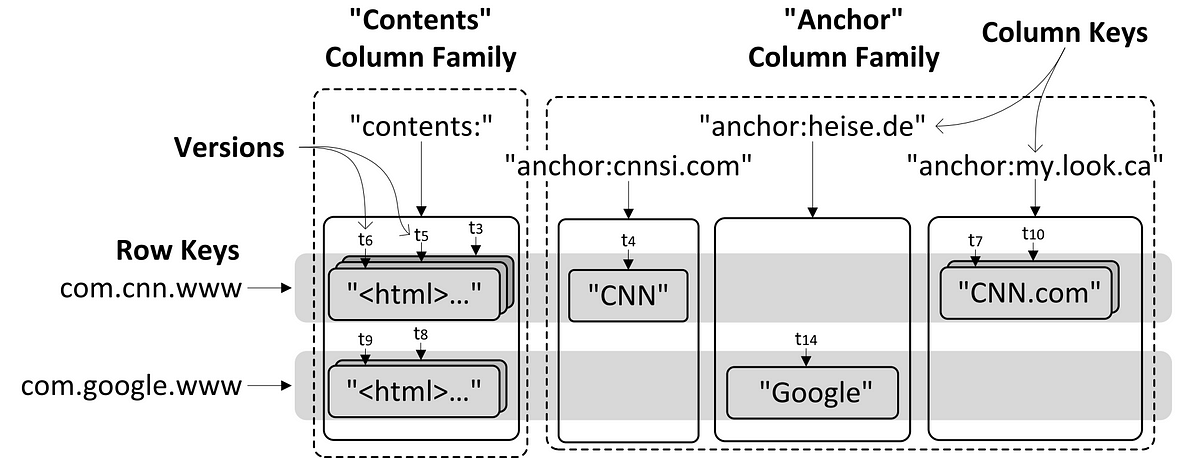
図3:ワイドカラムストアの中のデータ
ワイドカラムモデルの先駆けである Bigtable は、 図3 で示したように、特に大量のWebページを格納するために開発されました。Webページのテーブル上の各行が、1つのWebページに対応しています。行キーは、URLコンポーネントを逆の順序で連結したもので、すべての列キーは、列ファミリ名と列修飾子で構成され、この2つはコロンで区切られています。列ファミリには2種類あります。実際のWebページを持っているたった1つの列がある”contents”列ファミリと、各Webページのリンクを持っている”anchor”列ファミリです(リンクは個別の列になっています)。テーブルのすべてのセル(言い換えれば、行キーと列キーの組み合わせによってアクセスできる値)はタイムスタンプかバージョン番号でバージョン化されています。エンティティの情報のほとんどは値だけではなくキー上に存在する、ということは重要なポイントです。
2.2 一貫性と可用性のトレードオフ:CAPとPACELC
データがどう格納/アクセスされるかとは別の、データベースの決定的な特性は、提供されている一貫性のレベルです。データベースの中には、強力な一貫性やシリアライズ可能性( ACID )を保証しているもの、他にも可用性( BASE )を得意とするものもあります。このトレードオフは、それぞれの分散型データベースシステムの固有のもので、様々な種類のNoSQLシステムを見ると、その2つのパラダイムの間には幅広い範囲があることが分かります。続いては、2つの定理、CAPとPACELCについて、どのデータベースシステムが範囲内のそれぞれの場所によって分類されるのかに従って説明します。
CAP。 有名な FLP定理 のように、 CAP定理 (Eric Brewer氏が2000年のPODCで発表し、後に Gilbert氏とLynch氏 によって証明された)は、分散コンピューティングの分野における、本当に影響力のある不可能性についての成果の1つです。なぜなら、CAP定理は、分散システムによって達成することのできる上限を定めているからです。この定理の意味するところは、「結局のところ、すべてのリクエストに返答する、シーケンシャルで一貫性のあるread/write処理は、ネットワーク分断の傾向がある非同期のシステムでは実現することはできない」ということです。つまり、次の3つの属性のうち同時に保証することができるのは最大で2つということです。
- __一貫性(C):__read/writeは、常に不可分性(atomicity)をもって実行され、完全に一貫性がある( 線形化可能 )。別に書き込みをしても、すべてのクライアントは、どんな時も、データ上は同じ見た目になる。
- 可用性(A): システムのダウンしてないすべてのノードが、クライアントからの、read/writeリクエストを常に受け取り、最終的に意味のある応答(つまり、エラーメッセージを含まない)を返す。
- 分断耐性(P): システムが、ノード間、もしくは部分的なシステム障害などによるメッセージ損失に対して、前述の一貫性の保証と可用性を維持する。
Brewer氏は「通常の動作では可用性と一貫性を同時に保てるが、システム分断があると不可能になる」と論じています。つまり、システムは分断されたにも関わらず動作し続けた場合、他のノードとの連絡が途絶えたがダウンしてないノードがいくつか存在することになり、それゆえ「可用性を維持するためにクライアントのリクエストを処理し続ける(AP、 結果整合性システム )」か「一貫性の保証を保つためにクライアントのリクエストを拒否する(CP)」かを決めなければなりません。1つ目の選択肢は、一貫性を犠牲にしています。なぜなら、古いデータの読み出しや矛盾する書き込みを発生させる可能性があるからです。一方で2つ目の選択肢は可用性を犠牲にしています。また、可用性と一貫性を併せ持つシステムもあります。しかしこれは分断があると完全に障害が起きます(CA)。例えば、単一ノードシステムなどがそうです。CAP定理は、少なくとも因果一貫性以上に強力なあらゆる一貫性の性質に対して成立することがわかっています。この性質には、データに許容される古さの時間的境界を含みます( Δ-atomicity )。 トランザクション分離の正当性基準としてのシリアライズ可能性は、強力な一貫性を求めません。しかし、一貫性と同じように、 シリアライズ可能性もネットワーク分断下では成り立ちません 。
AP、CP、CAというNoSQLシステムの分類は、漠然とそれぞれのシステムの機能を反映しており、それゆえ、高次元での比較の手法として広く受け入れられています。しかし、気を付けなければいけないのは、実際、CAP定理は通常の動作のことは何も言っていないということです。システムが ネットワーク分断に直面したときに 、可用性か一貫性のどちらを優先しているか、ということを言っているだけなのです。FLP定理と比べると、CAP定理は「任意のメッセージの欠落や順番の入れ替り、遅延が無制限に起こりうる」という故障モデルを前提としているのです。通信回線の信頼性に関するより弱い仮定(つまり、「メッセージは常に到達しますが、到達は非同期的であり、入れ替わることもありうる」)のもとでは、CAPシステムは実際のところ、ノードの大半が稼働している限り Attiya氏、Bar-Noy氏、Dolev氏のアルゴリズム を使って動作し続けることができます。(それゆえ、ネイティブに(例えば Megastore で)、もしくはChubbyや Zookeeper のような協調サービスを利用して、NoSQLシステムの多くを協調させるのに使われるコンセンサスでは、強力な一貫性よりも高い可用性を達成するほうが難しいのです。 FLP定理 をご覧ください。)
PACELC : このCAP定理の欠陥点については、 Daniel Abadi氏の記事 で書かれています。彼は記事内で「CAP定理は、 通常の動作時 においてレイテンシと一貫性の間に発生するトレードオフについて説明していない。このトレードオフが、不具合が起きた時の可用性+一貫性のトレードオフよりも分散システムの設計上のほうにいっそう影響すると判明しているにも関わらずだ。」と主張しています。Abadi氏は両方のトレードオフを一元化するPACELCを考案し、分散システムの設計空間をさらに正確に説明しました。PACELCから、分断された場合( P )には可用性( A )と一貫性( C )のトレードオフがあること、そうでないとき( E )、つまり通常の動作時にはレイテンシ( L )と一貫性( C )のトレードオフがある、ということを学ぶことができます。
この分類は、基本的には分断状況における2つの選択肢を提供してくれますし(A/C)、さらに通常動作時も2つの選択肢(L/C)があります。それゆえ、CAPの分類法よりも明確なものになっています。しかし、多くのシステムは1つのPACELCクラスだけには割り当てることができません。そして、4つのPACELCクラスの中の1つ、すなわちPC/ELは、どのシステムにも割り当てることがほとんどできません。
