2016年9月6日
NoSQLデータベース:調査と決定のガイダンス(その2)

(2016-08-15)by Felix Gessert
本記事は、原著者の許諾のもとに翻訳・掲載しております。
(訳注:2016/10/3、頂きましたフィードバックを元に記事を修正いたしました。)
3. 技術
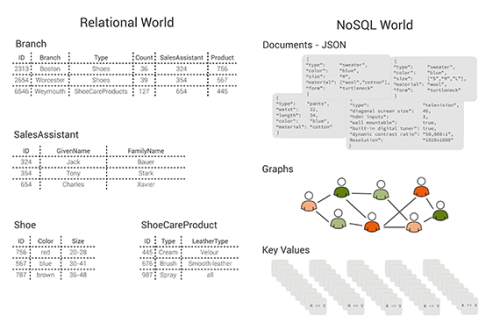
大きな成功を収めているデータベースはいずれも、特定の種類のアプリケーション向けに設計されているか、望ましいシステムの性質の特定の組み合わせを実現するよう設計されています。これほど様々なデータベースが存在するシンプルな理由は、「どんなシステムも、望ましい性質全てを一度に実現することはできないから」です。PostgreSQLのような従来のSQLデータベースは、包括的な機能を提供するために構築されてきました。包括的な機能とはつまり、極めて柔軟なデータモデルや、結合を含む洗練されたクエリ機能、グローバルな整合性制約やトランザクションの保証などです。それとは対照的な設計として、Dynamoのようなkey-valueストアもあり、データ量やリクエスト量に応じてスケールし、高いスループットで読み書きを行うとともに、遅延も小さいです。しかし、どんな機能であれ、シンプルな検索機能から切り離すことはほとんどできません。
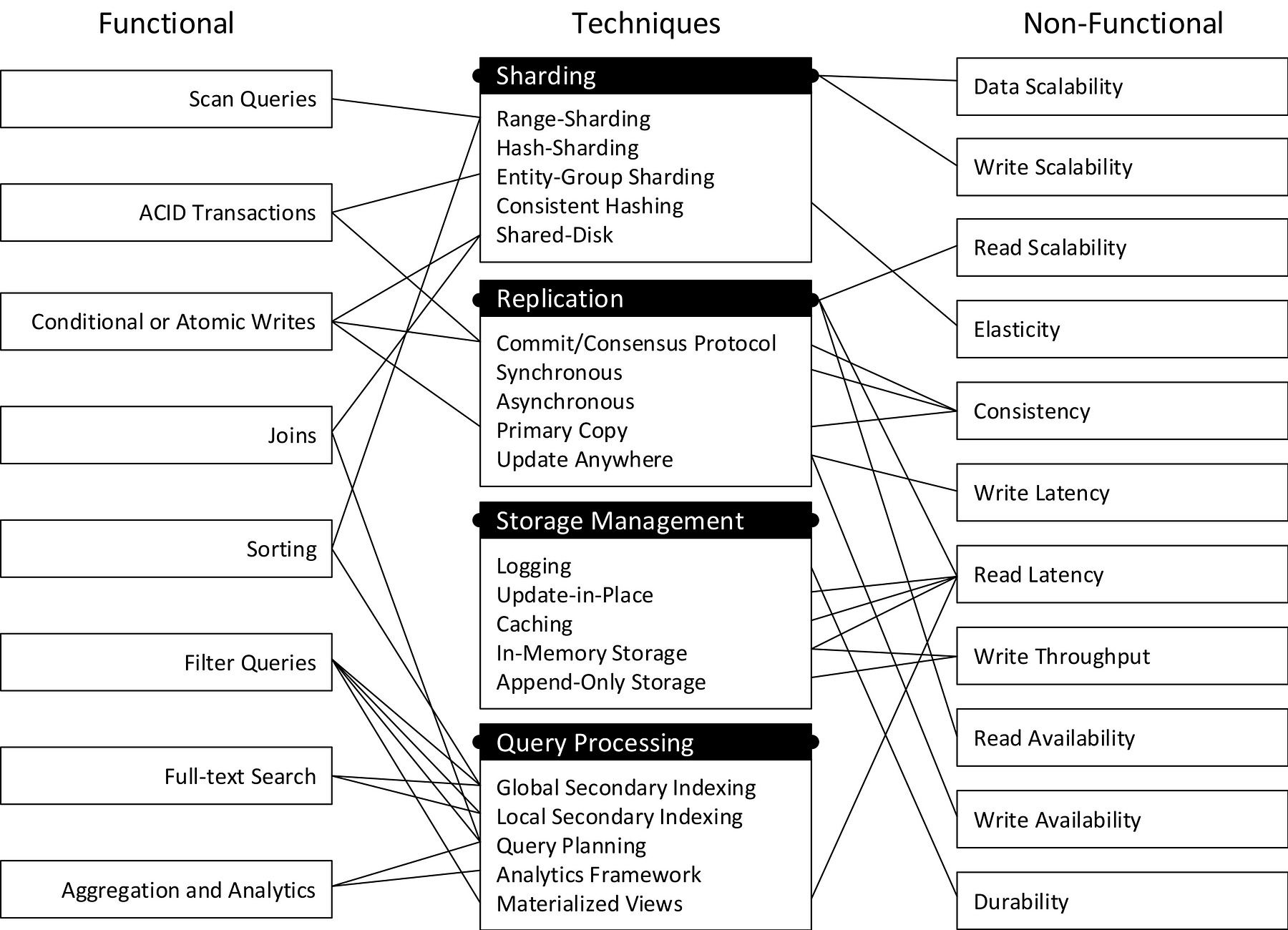
このセクションでは、分散型データベースシステムの設計空間を取り上げ、シャーディング、レプリケーション、ストレージマネジメントやクエリ処理を中心に見ていきます。使える技術を概観し、データマネジメントシステムの様々な機能要件や非機能要件(目標)との関連について検討します。それぞれの機能要件の実現に適した技術を示すために、 NoSQLツールボックス ( 図4 )を以下に図示します。この図では、それぞれの技術と、その技術によって可能となる機能要件や非機能要件を関連付けています(ポジティブな関係のみを線として図示)。
注釈:
(左列)
機能要件(Functional)
スキャンクエリ(Scan Queries)
ACIDトランザクション(ACID Transactions)
条件付きまたはアトミックな書き込み(Conditional or Atomic Writes)
結合(Joins)
ソート(Sorting)
フィルタクエリ(Filter Queries)
全文検索(Full-text Search)
集約と解析(Aggregation and Analystics)
(中央列)
技術(Techniques)
シャーディング(Sharding)
レンジシャーディング(Range-Sharding)
ハッシュシャーディング(hasyu-sharding)
エンティティグループシャーディング(Entitiy-Group Sharding)
コンシステントハッシュ法(Consistent Hahing)
共有ディスク(Shared-Disk)
レプリケーション(Replication)
コミット/コンセンサスプロトコル(Commit/Consensus Protocol)
同期性(Synchronous)
非同期性(Asynchronous)
プライマリコピー(primary Copy)
Update Anywhere(Update Anywhere)
ストレージマネジメント(Storage Management)
ロギング(Logging)
Update-in-Place(Update-in-Place)
キャッシング(Cashing)
インメモリストレージ(In-memory-Storage)
Append-onlyストレージ(Append-Only Storage)
クエリ処理(Query Processing)
グローバルセカンダリインデックス(Global Secondary Indexing)
ローカルセカンダリインデックス(Local Secondary Indexing)
クエリプランニング(Query Planning)
分析フレームワーク(Analytics Framework)
マテリアライズドビュー(Materialized Views)
(右列)
非機能要件(Non-Functional)
データスケーラビリティ(Data Scalability)
書き込みスケーラビリティ(Write Scalability)
読み取りスケーラビリティ(Read Scalability)
弾力性(Elasticity)
一貫性(Consistency)
書き込みレイテンシ(Write Latency)
読み取りレイテンシ(Read Latency)
書き込みスループット(Write Throughput)
読み取りの可用性(Read Availability)
書き込みの可用性(Write Availability)
耐久性(Durability)
図4:NoSQLツールボックス:NoSQLデータベースの技術と、その技術がサポートする、望ましい機能的・非機能的システム要件を関連付けています。
3.1 シャーディング
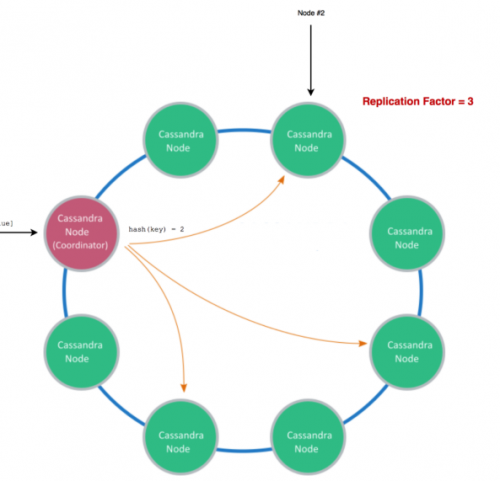
Oracle RACやIBM DB2 pureScaleのようないくつかの分散型リレーショナルデータベースは、 共有ディスク型アーキテクチャ に依存しています。このアーキテクチャでは、全てのデータベースのノードが同一のセントラルデータリポジトリにアクセスします(例えば、NASや SANなど)。従って、これらのシステムは常にデータの一貫性を提供するものの、本質的にスケールが困難です。それに対して、本稿で取り上げている(NoSQLの)データベースシステムは、 シェアード-ナッシングアーキテクチャ に基づいて構築されています。これは、各システムが独立したメモリと独立したディスクを備えた複数のサーバから構成され、互いにネットワークを通じて接続されています。このように、スループットとデータ量における高いスケーラビリティは、システム内の異なるノード( シャード )全体に渡るデータの シャーディング (パーティショニング)により実現されています。基本的な分散技術は3つです。レンジシャーディング、ハッシュシャーディング、エンティティグループシャーディングです。効果的なスキャンができるように、データは レンジシャーディング によって順番に連続的な値の範囲に分割されます。しかしこのアプローチでは、割り当てを管理するマスタを通してちょっとした調整が必要です。弾力性を確保するために、システムは自動でホットスポットを検知・解決しなければならず、これは負担の高いシャードをさらに分割することによって行われます。
レンジシャーディングは BigTable やHBase、Hypertableのようなワイドカラムストア、そしてMongoDBやRethinkDB、 Espresso 、 DocumentDB といったドキュメントストアによってサポートされています。複数のマシンに渡ってデータを分割する方法には、この他に ハッシュシャーディング があります。これは、「全てのデータアイテムが、プライマリキーから構築されたハッシュ値によってサーバのシャードに割り当てられる」というものです。このアプローチは調整役を必要とせず、使用されているハッシュ関数が均等に分布している限りは、シャード全体に渡るデータの均等な分割が保証されます。しかし、このアプローチで可能なのは検索だけであり、スキャンの実行ができないという明らかな欠点があります。ハッシュシャーディングはkey-valueストアで使用されます。また、 Cassandra や Azure Tables のように、ワイドカラムストアでも使用されることがあります。
例えば、レコードを管理するシャードサーバは、「(サーバID)=hash(ID) % (サーバ個数)」という式で決定することができます。しかしこのハッシュ化の方式では、新たにサーバが結合もしくは削除された場合、全てのレコードの再割り当てが必要です。というのも、シャードサーバの個数が変わるからです。つまり、オンデマンドでリソースが追加されたり不要時に削除されたりするDynamoやRiakやCassandraのような弾力性のあるシステムでの使用は不可能です。高い柔軟性に対処するため、弾力性のあるシステムは一般的に コンシステントハッシュ を用います。この方法ではレコードは直接サーバに割り当てられず、後で全ての共有サーバに分散されるロジカルパーティションに割り当てられます。すると、システムのトポロジーの変更時、割り当て直す必要のあるデータは一部のみとなります。例えば、弾力性のあるシステムをダウンサイジングすることを考えましょう。ダウンサイジングは、特定のサーバ上に存在する全てのロジカルパーティションを他の複数サーバにオフロードし、現在使われていないマシンをシャットダウンすることによって行うことができます。NoSQLにおけるコンシステントハッシュの詳しい使用方法については、 Dynamoの論文 をご覧ください。
エンティティグループシャーディング は、「コロケートされたデータにおける、単一パーティションのトランザクションを可能にする」ということを目的としたデータパーティショニングの方式です。このパーティションはエンティティグループと呼ばれ、( G-Store や MegaStore のように)アプリケーションによって明確に宣言されるか、( Relational Cloud や Cloud SQL Server のように)トランザクションのアクセスパターンから派生します。トランザクションが複数グループに渡るデータにアクセスする場合、データの所有権はエンティティグループ間で移行されることがあります。もしくは、トランザクションの管理者は、よりコストのかかるマルチノードトランザクションプロトコルにフォールバックしなければなりません。
3.2 レプリケーション
CAPの観点では、従来のRDBMSはシングルサーバモードで稼働するCAシステムになる場合がよくあります。つまり、システム全体がマシンの障害時に使用できなくなってしまいます。そのため、システムオペレータはデータの統合性と可用性を、費用はかかりますが信頼性の高いハイエンドなハードウェアを通じて確保します。それとは対照的に、DynamoやBigTable、CassandraのようなNoSQLシステムは、1台の単独マシンでは扱えないようなデータ量とリクエスト量に対処できるよう設計されています。そのためNoSQLシステムは何千ものサーバから構成されるクラスタ上で稼働します(ハイエンドなハードウェアに比べてかなり費用効率が高いため、ローエンドのハードウェアが使われます)。 どのような大規模な分散システムでも障害は不可避で、頻繁に発生する ので、ソフトウェアは日常的に障害に対処しなければなりません。Googleのフェローである Jeff Deanの2009年の発表 によると、Googleにおける従来型の新たなクラスタは、最初の年だけで、何千ものハードドライブ障害、1,000の単一マシン障害、20のラック障害や、想定内・想定外の状況に起因するいくつかのネットワーク分断に直面しました。大規模なクラウドデータセンタにおける ネットワーク分断と機能停止に関する最近の事例が数多く 報告されています。レプリケーションでは、こうした障害の際にシステムの可用性と耐久性が維持できます。しかしクラスタ内の異なるマシン上( レプリカサーバ )で同一のレコードを保存することにより、マシン間の同期の問題が起きます。このように、一方における一貫性と、もう一方におけるレイテンシと可用性との間にはトレードオフの関係があるのです。
Garyらが執筆したこちらの論文 では、「 いつ アップデートがレプリカに伝播されるか」「 どこ でアップデートが受け入られるのか」という異なるレプリケーション戦略による2段階の分類を提案しています。段階1(”いつ”)には2つの選択肢があります。1つ目は eager ( 同期性 )レプリケーションで、これは、全てのレプリカに対して入ってきた変更をコミットがクライアントに戻される前に同時に伝播するものです。2つ目の lazy ( 非同期性 )レプリケーションは、レプリカを受け取った時だけ非同期的に変更を行い、受け渡すものです。 Eager レプリケーションの最大の利点は、レプリカ同士に一貫性があることですが、他のレプリカや障害があるかどうかの確認を待たなくてはならないので、書き込みレイテンシが長くなるというマイナス面があります。一方、レプリカを分岐することができる lazy レプリケーションの書き込みは速いのですが、結果として、古いデータを返してしまう可能性があります。段階2(”どこ”)の場合も同じく2つの異なるアプローチが考えられます。 マスター/スレーブ方式 ( プライマリコピー )は、1つのレプリカ(マスター)によって変更が受け入れられる場合にのみ追跡が行われ、 update anywhere ( マルチマスター )のアプローチでは、各レプリカが書き込みを受け入れることができます。 マスター/スレーブ方式 のプロトコルの並列処理制御は、レプリカのない分散システムよりも容易ですが、マスターが機能しなくなるとすぐに、レプリカ一式が利用できなくなってしまいます。マルチマスタープロトコルでは、防止または検出、相反する変更の調整に対する複雑なメカニズムが必要とされます。これらの目的に使われる一般的な技術が、バージョニング、ベクトルクロック、ゴシップ、リードリペア(例えば Dynamo での使用)、 収束的、または相互的なデータ型 (例えばRiakでの使用)です。
基本的に、2段階の分類からなる4つの組み合わせ全てが実現可能です。分散型リレーショナルデータベースでは、通常、強力な一貫性を維持するために、 マスター/スレーブ の eager レプリケーションを実行します。例えば、Google Megastoreに登場する update anywhere の eager レプリケーションは、同期によって生成される大量のコミュニケーションのオーバーヘッドに悩まされています。またこれは分散デッドロックを引き起こす原因にもなり、検出に犠牲を払うことになります。NoSQLデータベースは、一般的にマスター/スレーブ(CPシステム、例えばHBaseやMongoDB)、またはupdate anywhereアプローチ(APシステム、例えばDynamoやCassandra)との組み合わせで lazy レプリケーションを行っています。多くのNoSQLデータベースは、レイテンシまたは一貫性かの選択をクライアントに委ねています。つまり、全てのリクエストに対して、クライアントは最低限のレイテンシでいいようにレプリカからの返事を待つのか、古いデータが残るのを防ぐために、常に(レプリカの大多数、もしくはマスターからの)一貫性のある返事を待つのか、ということです。
この2段階の分類でカバーされていないレプリケーションの側面が、レプリカ間の距離です。お互いのレプリカを近くに置くことによる明らかな利点は、レイテンシの短さですが、可用性に対する好影響を減少させることにもなりかねません。例えば、同じデータアイテムの2つのレプリカが同じラックに置かれた場合、レプリケーションしてあるにもかかわらず、ラックでの障害が起こった場合にはデータアイテムが利用できなくなります。しかし、単に一時的に利用できない可能性だけではなく、レプリカ同士を近くに置くことで、最悪の場合、全てのコピーを一度に失ってしまう危険性もあります。レイテンシを削減する別の技術は Orestes で使用されています。Orestesでは、Webのキャッシュ機能の基盤やキャッシュコヒーレンスプロトコルを使っているアプリケーションに近い方法でデータがキャッシュされます。
Geoレプリケーションでは、システムが全データを失ってしまわないように保護したり、クライアントからの分散アクセスのために、読み取りレイテンシを向上させたりすることができます。 Megastore や Spanner 、 MDCC 、 Mencius で実装されている eager geoレプリケーション は、書き込みにより長いレイテンシ(平均的に100ミリ秒から600ミリ秒)を費やすことで、強力な一貫性を実現しています。一方、 PNTUS や Walter 、 COPS 、Cassandra、BigTableで実装されている lazy geo レプリケーション では、最近の変更が失われる可能性がありますが、この場合、システムのパフォーマンスは向上し、分断されている間でも利用可能となります。 Charron-Bostらよって執筆されたこちらの書籍(第12章) や、 ÖszuとValduriezによって執筆されたこちらの書籍(第13章) には、データベースレプリケーションの網羅的な議論が紹介されています。
3.3 ストレージマネジメント
最適なパフォーマンスを実現するために、データベースシステムは、データの提供/維持に使用するストレージメディアに対して最適化される必要があります。一般的には、メインメモリ(RAM)、半導体ドライブ(SSDs)、そしてハードディスクドライブ(HDDs)があり、これらはどのような組み合わせでも使用することができます。企業に配置されるRDBMSとは異なり、分散型NoSQLデータベースは、特殊化した共有ディスクのアーキテクチャを避け、コモディティなサーバ(コモディティなストレージメディアの使用)をベースとした、シェアード-ナッシングクラスタを好んで使用しています。ストレージデバイスは一般的に”ピラミッド型ストレージ”( 図5 または Hellersteinらが執筆した論文 )をご覧ください)のように可視化されます。そこには透過的なキャッシュもあります(例えば、図には示されていない、L1-L3 CPUキャッシュとディスクバッファ)。これは、技術的に優れたデータベースのアルゴリズムを介して暗黙的にに利用されており、データの局所性を高めています。RAM、SSD、HDDストレージのコストやパフォーマンスの特質、そしてそれらの強みを生かす戦略(ストレージマネジメント)には様々なものがありますが、これらの違いがNoSQLデータベースの多様性の原因の一つになっています。ストレージマネジメントは、空間次元(どこにデータを保存するか)と時間次元(いつデータを保存するか)の2つの次元を持っています。Update-in-placeとappend-only-I/Oの2つは、データを体系化する補助的な空間的な技術です。In-Memoryはデータの場所としてRAMを指定します。また、ロギングは、メインメモリや永続記憶装置を切り離す時間的なテクニックで、結果として、データを実際に永続化するタイミングの制御が可能になります。
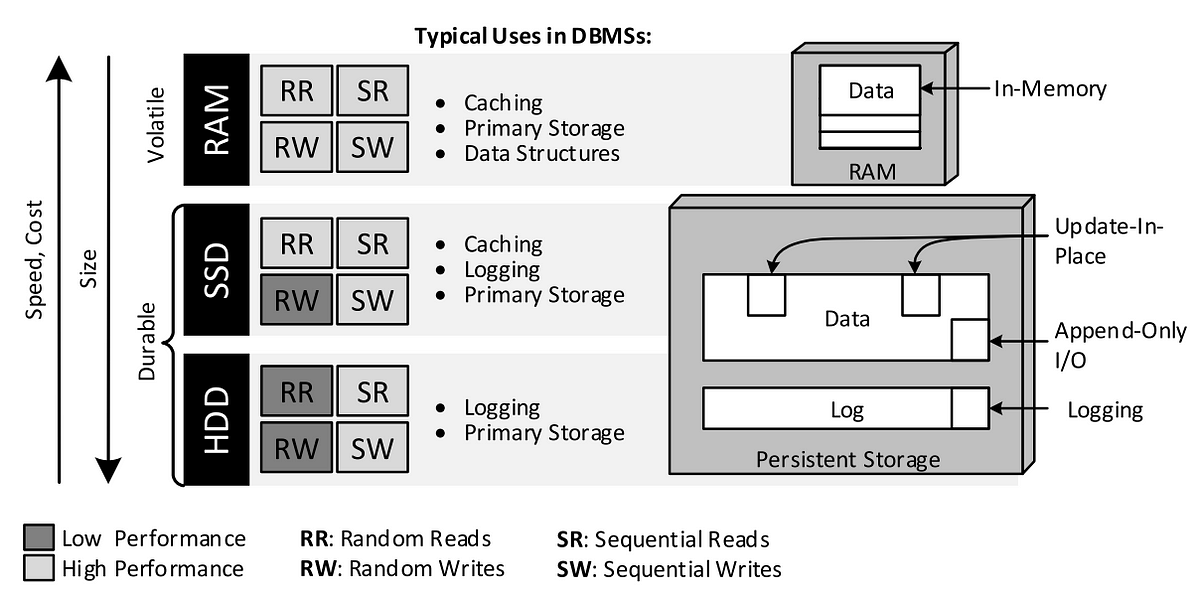
注釈:DBMSでの典型的な使用方法(Typical Uses in DBMSs)
速度、コスト(Speed, Cost)
サイズ(Size)
揮発性(Volatil)
耐久性(Durable)
キャッシュ(Caching)
プライマリストレージ(Primary Storage)
データ構造(Deta Structures)
キャッシュ(Caching)
ロギング(Logging)
プライマリストレージ(Primary Storage)
ロギング(Logging)
プライマリストレージ(Primary Storage)
データ(Data)
RAM
データ(Data)
ログ(Log)
永続記憶装置(Persistent Storage)
インメモリ(In-Memory)
Update-In-Place
Append-Only-I/O
ロギング(Logging)
低パフォーマンス(Low Performance)
高パフォーマンス(High Performance)
RR: ランダムな読み取り(Random Reads)
RW: ランダムな書き込み(Random Writes)
SR: シーケンシャルな読み取り(Sequential Reads)
SW: シーケンシャルな書き込み(Sequential Writes)
図5: ピラミッド型ストレージとNoSQLシステムにおけるその役割
大きな影響力を与えた論文、『 The End of Architctural Era 』を執筆したStonebrakerらは、一般的なRDBMSでは、「役立つ作業」に費やされている実行時間はたった6.6%であることを明らかにしました。その他は、以下のようなことに費やされています。
- バッファマネジメント(34.6%)。例えば、低速なディスクアクセスを軽減するためにキャッシュをする。
- ラッチ(14.2%)。マルチスレッドによって引き起こされる競合状態から、共有データ構造を保護する。
- ロック(16.3%)。トランザクションの論理的な分離を保証する。
- ロギング(1.9%)。障害時の耐久性を保証する。
- ハンドコーディングの最適化(16.2%)
RAMがプライマリストレージとして使われているの( インメモリデータベース )であれば、大きなパフォーマンスの向上が期待できる、というモチベーションになり得ます。しかし、高いストレージコストと耐久性の欠如というマイナス面があります。ちょっとした停電でもデータベースの状態を壊しかねません。これの解決策には、「n-1個のシングルノード障害に対応するため、n個のインメモリのサーバノードにわたってレプリケーションを行う(例えば、 Hstore やVoltDB)」「耐久性のあるストレージに ロギング する(例えば、RedisやSAP Hana)」の2つの方式があります。ロギングにおいて、ランダムな書き込みのアクセスパターンは、受け取り操作とそれらに関連するプロパティ(例えば、redo情報)から成るシーケンシャルなアクセスへと変換することができます。ほとんどのNoSQLシステムでは、「全ての書き込み操作について、正常にログが取られるとともに、永続記憶装置にログがフラッシュされる」というロギングのコミットルールが遵守されます。個々に各操作をロギングすることで発生する、HDDの回転待ち時間を避けるために、ログフラッシュは一緒のバッチにまとめることができ(グループコミット)、個々の書き込みレイテンシがわずかに長くなるものの、スループットが劇的に向上します。
SSDや、より広い意味でNANDフラッシュメモリに基づいた全てのストレージデバイスは、HDDとは様々な面で大きく異なります。その異なる側面とは、「(1) 読み取り/書き込み操作の非対称な速度、(2) In-placeの上書きがない。つまりブロックにあるページを上書きする前に全てのブロックを削除しなくてはならないこと、そして(3) 制限されたプログラム/削除サイクル」( Minらが2012年に発表した論文から抜粋 )です。このように、データベースシステムのストレージマネジメントにおいては、わずかに遅い永続的RAMと同様にSSDやHDDを扱ってはいけません。なぜなら、SSDへのランダムな書き込みは、シーケンシャルな書き込みよりも約1桁も遅くなるからです。一方、ランダム読み取りはパフォーマンスのペナルティなく実行することができます。これらSSDのパフォーマンスの性質に明確に特化して設計されたいくつかのデータベースシステムもあります(例えば、Oracle ExadataやAerospike)。HDDでは、ランダムな読み取りと書き込みのどちらも、シーケンシャルアクセスよりも10から100倍遅くなります。従って、ロギングはSSDとHDDの強みを生かすのに適しており、シーケンシャルの書き込みでは、どちらも著しく高いスループットを提供しています。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事