2015年5月13日
MapReduceは楽しい:巨大なデータセットのサンプリング
(2015-03-23)by Chou-han Yang
本記事は、原著者の許諾のもとに翻訳・掲載しております。
この記事はBloomReachの主席エンジニア、Chou-han Yangによるものです。
MapReduceの最大の利点は、非常に高い演算性能と巨大なストレージを瞬時に手に入れられることです。これは、子供が前から大好きだった遊びに、新しいおもちゃを加えられないか、と考えるようなものだと私は思います。長い間楽しんできた遊びに対して、新しい遊び方を思いついたとしたら、とても興奮しますよね。
このことから私は、シングルプロセスのプログラムを書く時によくやることを改めて思い出します。つまり、MapReduceフレームワークに合わせるにはプロセス全体を徹底的に調査しなければならないということです。特にHadoopは、スムーズに実行するために慎重な調整が必要となるからです。
この記事では、簡単な例を見てみましょう。サイズが不明の非常に大きなデータセットからn個の要素をサンプリングします。非MapReduceからMapReduceまで様々な方法をご紹介して、利点と欠点を見ていきたいと思います。初めに、サンプリングのプロセスに偏りがないことを確かめます。すなわち、ある要素がサンプルデータセットに抽出される確率は、全ての要素で同じでなければなりません。この見直しによって、ステップ数と記憶領域の改善を実現しようとしています。
方法1(非MapReduce):カードをシャッフルする
全てのデータセットをスキャンすると、mという要素数を取得でき、そして0からm-1までの数字をランダムに生成できます。これで、最初のサンプルを選択できる状態になりました。乱数ジェネレータが0からm-1の全ての数字を同じ確率で生成すると仮定すれば、結果に偏りはありません。そして、その要素を取り除き、m-1というサイズのデータセットでもう一度同じことをします。

ここで問題になるのは処理実行前にデータセットのサイズを把握していなければならないという点です。また、データセット全体をメモリにロードできるかどうかに関係なく、どの要素にもランダムアクセスが可能な状態にしなければなりません。
方法2(非MapReduce):レザボアサンプリング(Reservoir Sampling)
方法1で指摘した問題を踏まえて、エンジニアたちはサンプルデータをオンラインで抽出する、新たな方式を開発しました。ここで生まれる疑問は、現在対象としているデータのサイズ(個数)をmとする時、その次の要素m+1がサンプルセットの中に含まれる確率を決定することができるか、ということです。

注釈
Buffer of Samples:サンプルのバッファ
probability to be sampled:サンプルとして抽出される確率
この答えは明らかにイエスです。新しい要素を読み込むと、データセットのサイズは増大するので、その新しい要素がサンプルとして抽出される確率は、既に読み込んでいたデータセットのサイズに応じて比例的に下がります。そこでレザボアサンプリングを使うと、新しい要素を全てスキャンするのと並行して、非常に大規模なデータセットをスキャンして、オンラインのサンプルを取得することができます。
この技法は、大規模なデータセットに限らず、データストリームに対しても有効です。ただし改めて指摘しますが、この技法には、データを全て単一のスレッドまたはプロセス内で処理しなければならないという短所があります。これでは、より強力なMapReduceフレームワークに移行しても効果が表れないかもしれません。
なお、レザボアサンプリングの詳細は、 Wikipediaの記事 を参照してください。
方法3(MapReduce):レザボアサンプリングからMapReduceフレームワークへの移行の試み
今やビッグデータの時代となり、誰もがMapReduceを使いまくっています。その際にまず思いつくのは必然的に、昔と同じレザボアサンプリングの技法を適用することです。サイズの大きなデータセットをメモリに長く保持したくはないからです。言うまでもなくMapReduceフレームワークは、ストリーミングモデルとの適合性が向上しています。従ってMapperやReducerでは、1回の処理で要素を1つずつ取得します。
ではMapperとReducerの両方でレザボアサンプリングを試しに実行してみましょう。余裕でできそうに思えますよね。ところが実際には、処理は思うようには進みません。ここで発生する問題は、Mapperが取得する要素の数が、サンプリングを実行するたびに変わる可能性があるということです。つまり、規模の小さいスプリットに含まれている要素ほどサンプルとして抽出される確率が高くなります。

訳注
Higher chance to be sampled:サンプルに抽出される確率が上がる
Small Split:小さいスプリット
Large Split:大きいスプリット
identity mapperを使って1つのReduce内に全てをぶちこめば、レザボアサンプリングを実行することはできるでしょうが、理想とはほど遠いやり方です。全てのワークロードを1つのReducerに集めるのでは、MapReduceを使う効果が出なくなるからです。この方式では本質的に、全てのデータを1つのノードの中で処理しているのと同じことになります。
スプリットごとの要素の数を制御する、または何か数学的な手法を使って、Reducer内の確率の偏りを排除する、ということができれば、この問題を回避できるかもしれません。ただしどちらも、非常に複雑な処理になります。
方法4(MapReduce):データのシャッフルに立ち戻る?
そこで、最初に戻ります。MapReduceジョブの場合でも、データセットをスキャンすることで、その中にある要素の総数を確実に取得できます。すると、2パス目には要素をランダムに抽出できます。この方法で処理は可能なのですが、データセットを2回スキャンしなければならないので、やはりあまり効率的ではありません。
それでは、カードのシャッフルとはどのような処理なのかを再び考えてみましょう。まず、カードをシャッフルします。これはランダム化の処理です。次に、上からn枚のカードをサンプルセットとして抽出します。これは、ある順序での上位n個の要素を単純に選ぶということです。
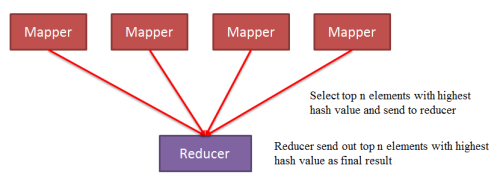
では、データのシャッフルを、実際のデータを移動させずに行うことは可能でしょうか? 答えはイエスです。ハッシュ関数を要素に適用すればいいのです。そうすれば、各要素についてランダムな順序が得られます。一見、このやり方では問題を単純化することにはならないように思えます。サンプリングの問題をシャッフルの問題に転換しているだけですからね。でも、上位n個の要素を選ぶという2番目の段階が、ヒープを持つMapperによって容易に実行できるようになることを考えてみてください。

訳注
sort with hash value:ハッシュ値でソート
Select top n elements for samples:上位n個の要素をサンプルに抽出
つまり、全ての要素について各Mapperへのハッシュを実行して、ランダムな順序を取得します。そして、各Mapタスクのスプリットにおいて、その要素をヒープに保持するかどうかをハッシュ値によって判断するのです。Mapタスクが完了したら、ヒープの内容を丸ごとReducerへ送ります。

訳注
Select top n elements with highest hash value and send to reducer:ハッシュ値の大きな上位n個の要素を選んで、Reducerへ送る
Reducer send out top n elements with highest hash value as final result:Reducerは、ハッシュ値の大きな上位n個の要素を最終結果として出力する
従ってこの場合、Reducerはやはり1つしかありませんが、そのReducerへ送られる要素数は激減します。Reducerへ送られる要素の実際の数は、Mapper数のn倍となります。
結論
新しいフレームワークのように、昔からの問題に対する最適なアプローチを考え直すというのは面白い作業です。MapReduceは、もっと複雑な機能を持つ構造体にも基本的に使うことができます。フレームワークの力をフル活用するためには、従来の方法を”やめる”ことも時には必要かもしれません。まだ発見されていない、もっと優れた解決法だってあるかもしれないのです。ぜひ皆さんの考えを聞かせてください。そして、MapReduceを活用してみてください。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事