2017年2月24日
私たちはいかにして環状線で”悪さをする列車”を捕まえたか
本記事は、原著者の許諾のもとに翻訳・掲載しております。
文:Daniel Sim 分析:Lee Shangqian、Daniel Sim、Clarence Ng
ここ数ヶ月、シンガポールのMRT環状線では列車が何度も止まるものの、その原因が分からないため、通勤客の大きな混乱や心配の種となっていました。
私も多くの同僚と同じように環状線を使ってワンノースのオフィスに通っています。そのため、11月5日に列車が止まる原因を調査する依頼がチームに来た時は、ためらうことなく業務に携わることを志願しました。
鉄道運営会社SMRTと陸上交通庁(LTA)による事前調査から、いくつかの電車の信号を消失させる信号の干渉があり、それがインシデントを引き起こすことが既に分かっていました。信号が消失すると列車の安全機能である緊急ブレーキが作動するため、不規則に電車が止まる原因となります。
しかし8月に初めて発生した今回のインシデントは、不規則に起こっているように見えるため、調査チームが正確な原因を指定することは困難でした。
私たちには、以下の情報を含むSMRTのまとめたデータセットが提供されました。
- それぞれのインシデントが発生した日付と時間
- インシデントの発生した場所
- 関与した列車のID
- 列車の行き先
私たちはデータのクリーニングから始めました。使ったツールは、Pythonコードのプログラミングや文書化によく使われる Jupyter Notebook です。
いつもと同じように、最初に便利なPythonライブラリをいくつかインポートしました。
import math
import xlrd
import itertools as it
import numpy as np
import pandas as pd
from datetime import datetimeスニペット1 Gist
次に、生データから使える部分を抜き出しました。
dfincidents_0 = pd.read_excel('CCL EVAC E-brake occurrences hourly update_mod.xlsx', sheetname='Aug Sep')
dfincidents_1 = pd.read_excel('CCL EVAC E-brake occurrences hourly update_mod.xlsx', sheetname='Nov')
# Incident data for Nov had different format
dfincidents_1['Time'] = dfincidents_1['Time'].str.strip('hrs').str.strip(' ')
dfincidents_1['Time'] = pd.to_datetime(dfincidents_1['Time'], format='%H%M').dt.time
dfincidents = pd.concat([dfincidents_0, dfincidents_1])
# Reset the index because they were concatenated from two data sources
dfincidents.reset_index(inplace=True, drop=True)スニペット2 Gist
日付と時間の列を1つの列にまとめ、データを可視化しやすくしました。
def datetime_from_date_and_time(row):
"""
Combines the date column and time column into a single column
"""
d = row['Date']
t = row['Time']
return datetime(
d.year, d.month, d.day,
t.hour, t.minute, t.second
)
# Add DateTime to the data for easier visualization
dfincidents['DateTime'] = dfincidents.apply(datetime_from_date_and_time, axis=1)スニペット3 Gist
以下のようになりました。
スクリーンショット1:最初の処理で得られた表
最初の可視化では明確な答えを得られなかった
下のグラフからも分かる通り、最初の予備解析では、はっきりとした答えを確認できませんでした。
- インシデントは1日を通して発生し、日毎の発生件数は利用動向のピークとオフピークにあわせて増減していました。
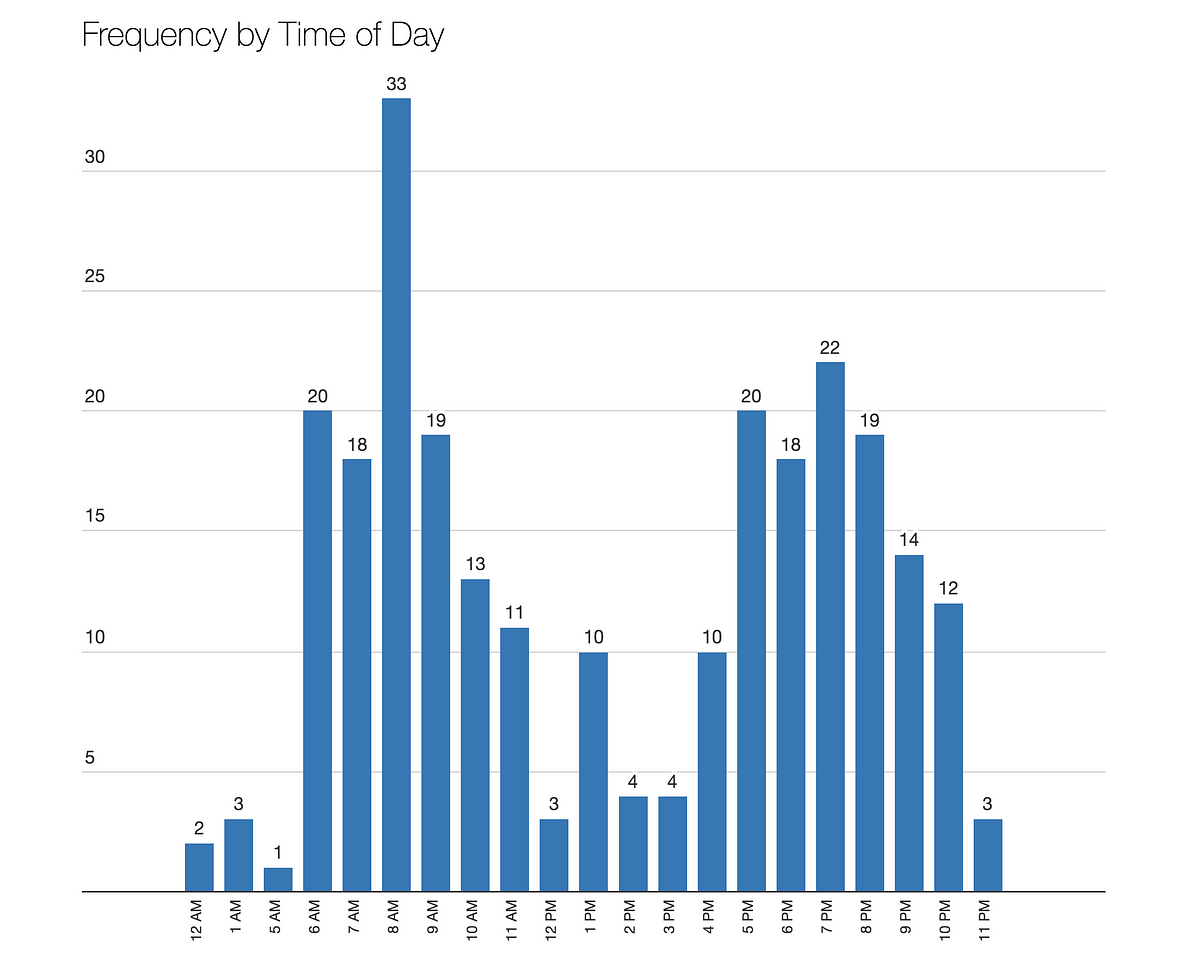
図1:発生件数は利用動向のピークとオフピークを反映
- インシデントは環状線内の様々な場所で発生し、発生件数は西部がわずかに多めでした。
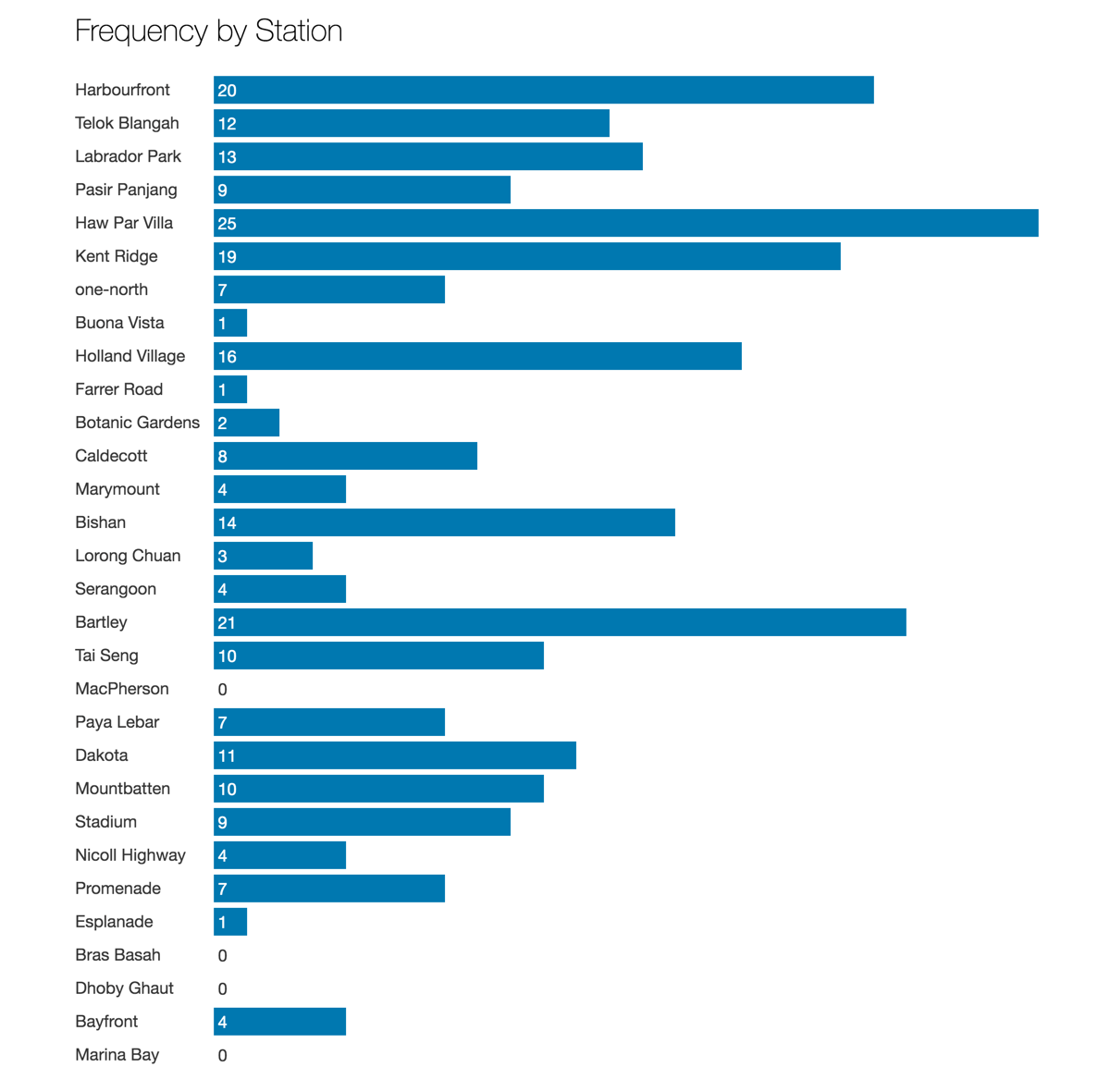
図2:干渉の原因は地域的な要因ではないと予想される
- 信号干渉の影響は1~2台の列車だけでなく、環状線上を走る多くの列車に及びました。下のグラフにおける「PV」は「旅客車両(Passenger Vehicle)」のことです。

図3:異なる60の車両が信号干渉の影響を受けた
マレーチャート:時間、場所、行き先を可視化する
私たちの次の試みは、複数の特性を取り入れて予備解析を行うことでした。
私たちが影響を受けたマレーチャートは、Edward Tufteが1983年に書いた『 The Visual Display of Quantitative Information(定量的な情報の可視化) 』の中で取り上げられています。また最近では、Mike BarryとBrian Cardがボストンの地下鉄のシステムを 広範囲に渡って可視化したプロジェクト にも使われていました。
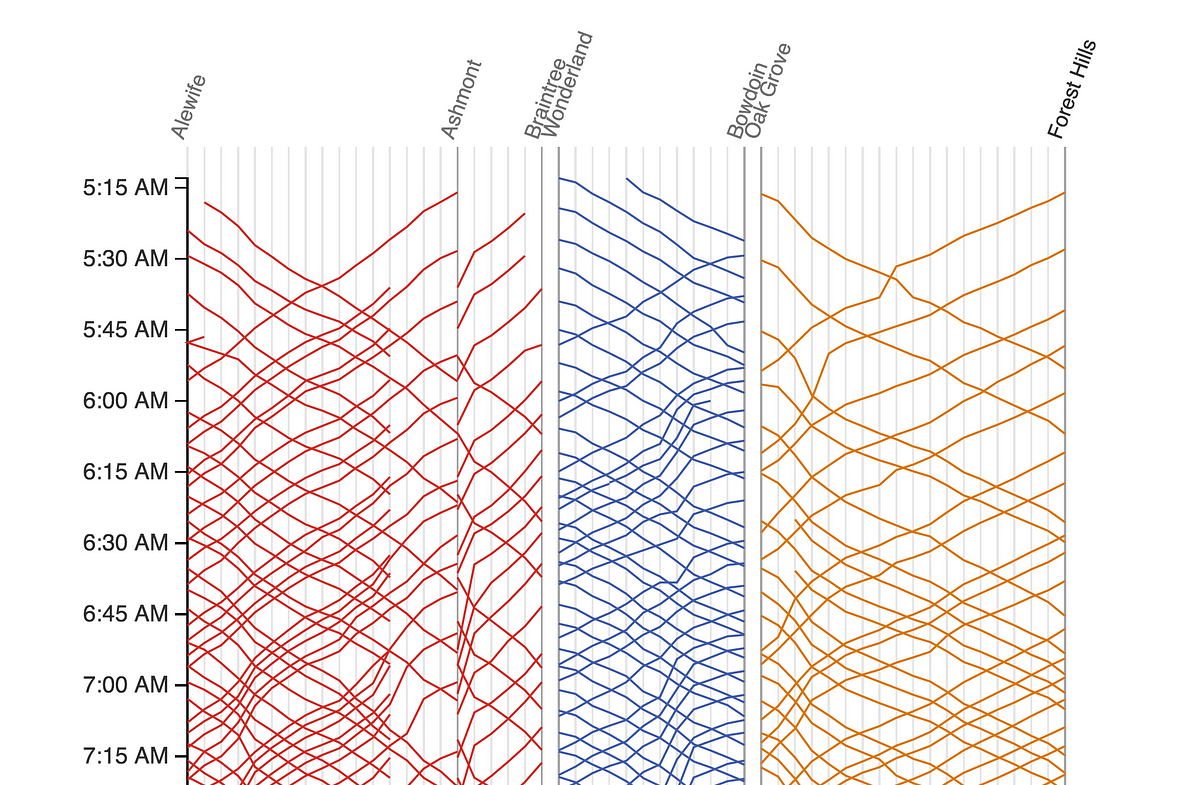
スクリーンショット2:http://mbtaviz.github.io/から引用
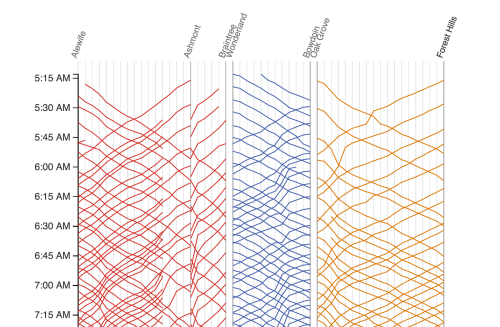
この表では縦軸が時間を表し、上から下へと時間が進んでいきます。また横軸は路線の駅を、斜めに横切る線は列車の動きを示します。
MRT環状線バージョンのマレーチャートを作るために、まず軸を描いてみました。

図4:環状線バージョンの未記入のマレーチャート
ハーバーフロント駅とドビー・ゴート駅の間を走る列車は、通常、下の表のように直線的な変位で移動し、片道を走るのに1時間と少しかかります。
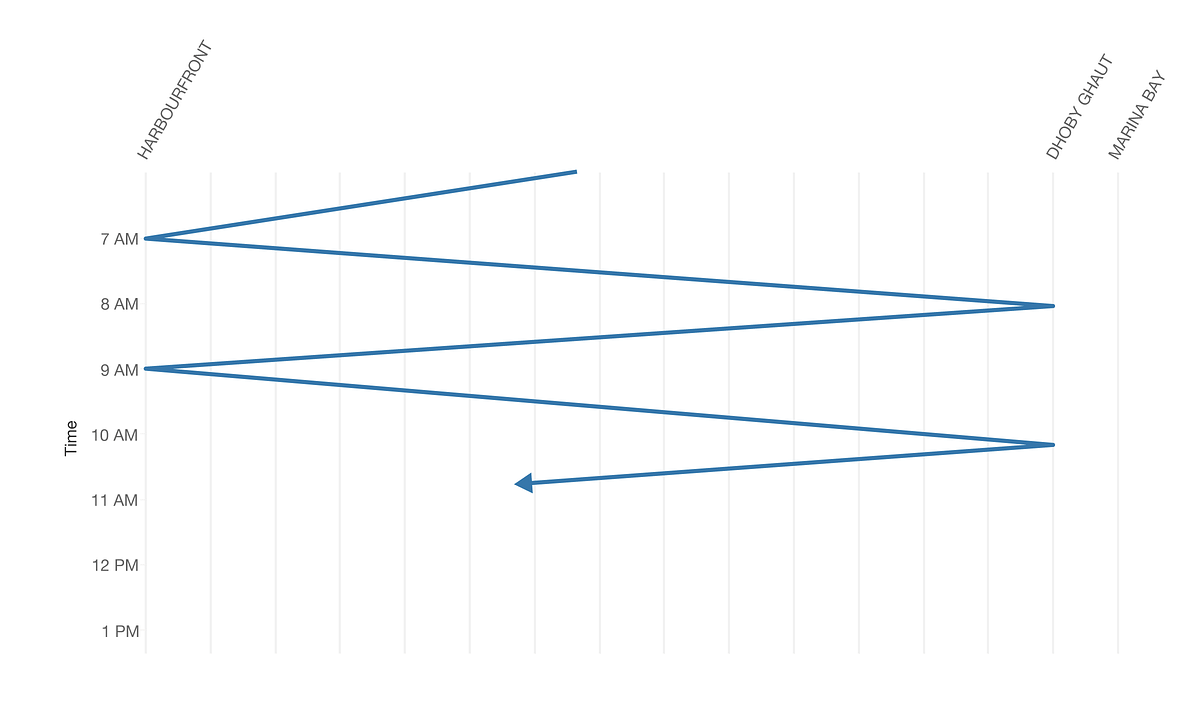
図5:定型化された環状線の列車の反復的な動き
私たちはインシデントを線で表現せず、点でグラフ上に書き込もうと考えました。
可視化のためのデータの準備
まず、駅を示す3文字のコードを数字に変換しました。
-
マリーナ・ベイ駅からプロムナード駅の前まで:0~1.5
-
ドビー・ゴート駅からハーバーフロント駅まで:2~29
インシデントが駅と駅の間で発生した場合は、2つの駅の内、数字の小さい方に0.5を加えて示します。例えば、ハーバーフロント駅(数字は29)とテロック・ブランガ駅(数字は28)の間でインシデントが発生した場合、位置は”28.5″となります。こうすることで、水平軸に沿って点をプロットすることが容易になります。
stations=("MRB,BFT,DBG,BBS,EPN,PMN,NCH,SDM,MBT,DKT,PYL,MPS,TSG,BLY,SER,"
"LRC,BSH,MRM,CDT,BTN,FRR,HLV,BNV,ONH,KRG,HPV,PPJ,LBD,TLB,HBF").split(',')
def loc_id(station1, station2 = None):
"""
Translates a 3-letter station code to a number,
or a pair of 3-letter station codes to a number.
Single stations are represented as whole numbers.
Locations between stations are represented with a .5.
Example:
loc_id('MRB') # 0 (Marina Bay)
loc_id('MRB', 'BFT') # 0.5 (Between Marina Bay and Bayfront)
loc_id('DBG') # 2 (Dhoby Ghaut)
loc_id('HBF') # 29
loc_id('HBF', 'TLB') # 28.5 (Between Harbourfront and Telok Blangah)
loc_id('HBF', 'DBG') # throws and error, because these stations are not adjacent
"""
if station2 == None or station2 == 'nan' or (type(station2) is float and math.isnan(station2)):
# Single stations
return stations.index(station1)
else: # Pairs of stations -- take the average to get the 0.5
stn1_index = stations.index(station1)
stn2_index = stations.index(station2)
# Handle the branch at Promenade
if (set(['PMN', 'EPN']) == set([station1, station2])):
return float(stations.index('EPN')) + 0.5
elif set(['PMN', 'BFT']) == set([station1, station2]):
return float(stations.index('BFT')) + 0.5
else:
# Require station pairs to be adjacent stations
assert(math.fabs(stn1_index - stn2_index) == 1)
return float(stn1_index + stn2_index) / 2スニペット4 Gist
そして、数値的な位置IDを計算しました。
def loc_id_from_stations(row):
try:
# This handles entries with both "Station from" and "Station to"
# and entries with only "Station from"
return loc_id(row['Station from'], str(row['Station to']))
except ValueError:
# Some entries only have "Station to" but no
# "Station from"
return loc_id(row['Station to'])スニペット5 Gist
それから、以下をデータセットに追加しました。
# Select only some columns that we are interested in
sel_dfincidents = dfincidents[['DateTime', 'PV', 'Bound', 'Station from', 'Station to', 'Event', 'Remarks']]
# Add the location ID into the dataset
sel_dfincidents['LocID'] = sel_dfincidents.apply(loc_id_from_stations, axis=1)スニペット6 Gist
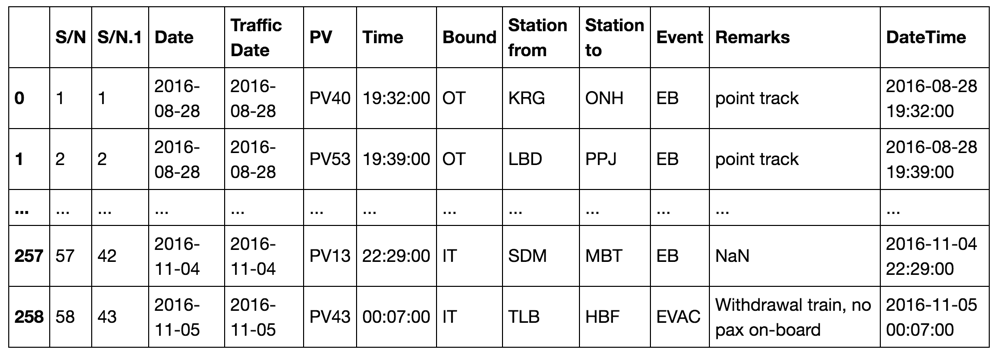
その結果が下の表です。

スクリーンショット3:位置IDを加えた後に出力された表
データ処理をすることで、緊急ブレーキが作動するインシデントを全てプロットした散布図を作ることができました。それぞれの点がインシデントを示しています。しかし、この方法でもインシデントが発生するパターンを明らかにすることはできませんでした。
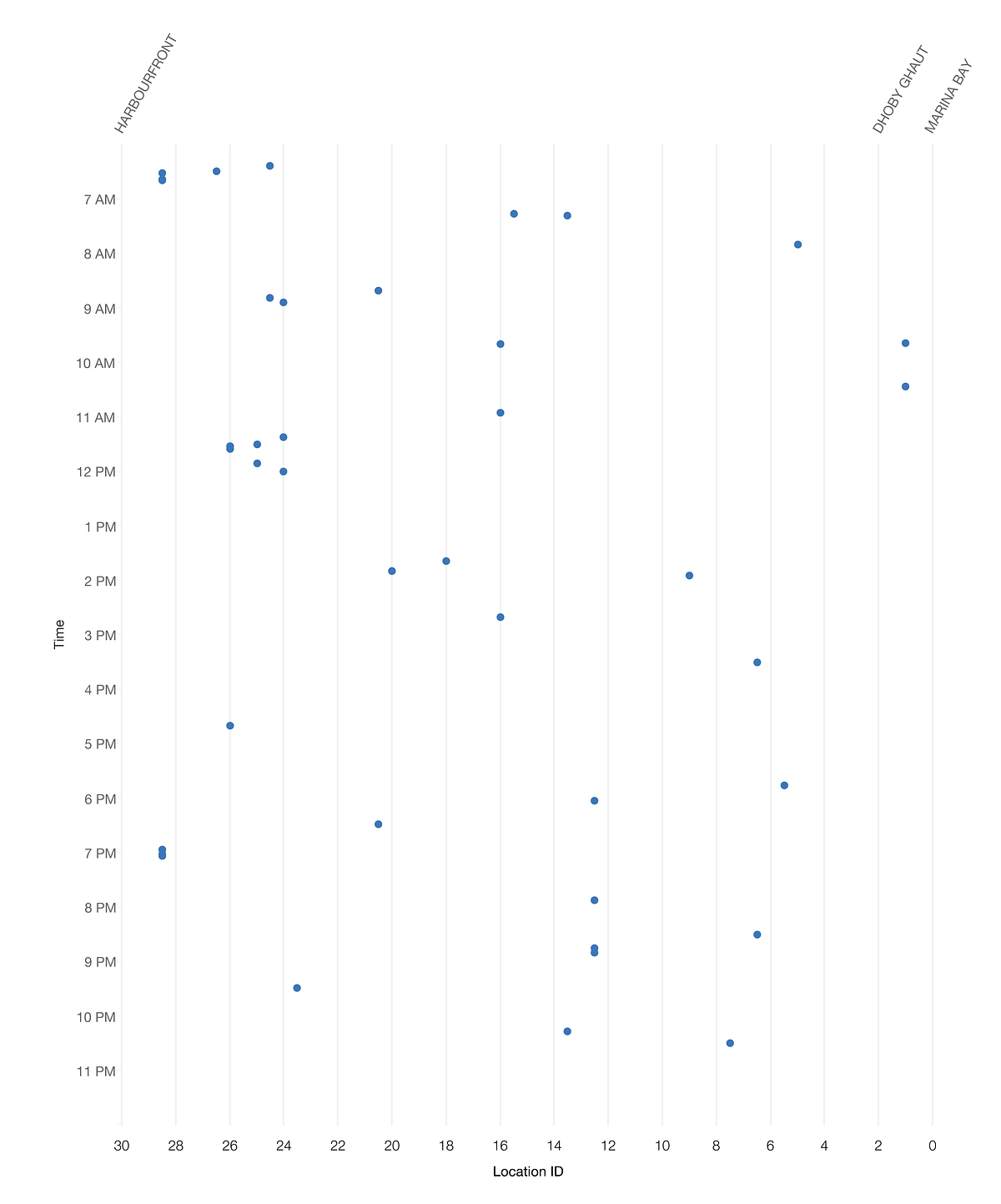
図6:散布図で示された信号干渉のインシデント
次に、点ではなく左向きと右向きの三角形を使ってインシデントの位置を示すことで、列車の進行方向をグラフに加えました。
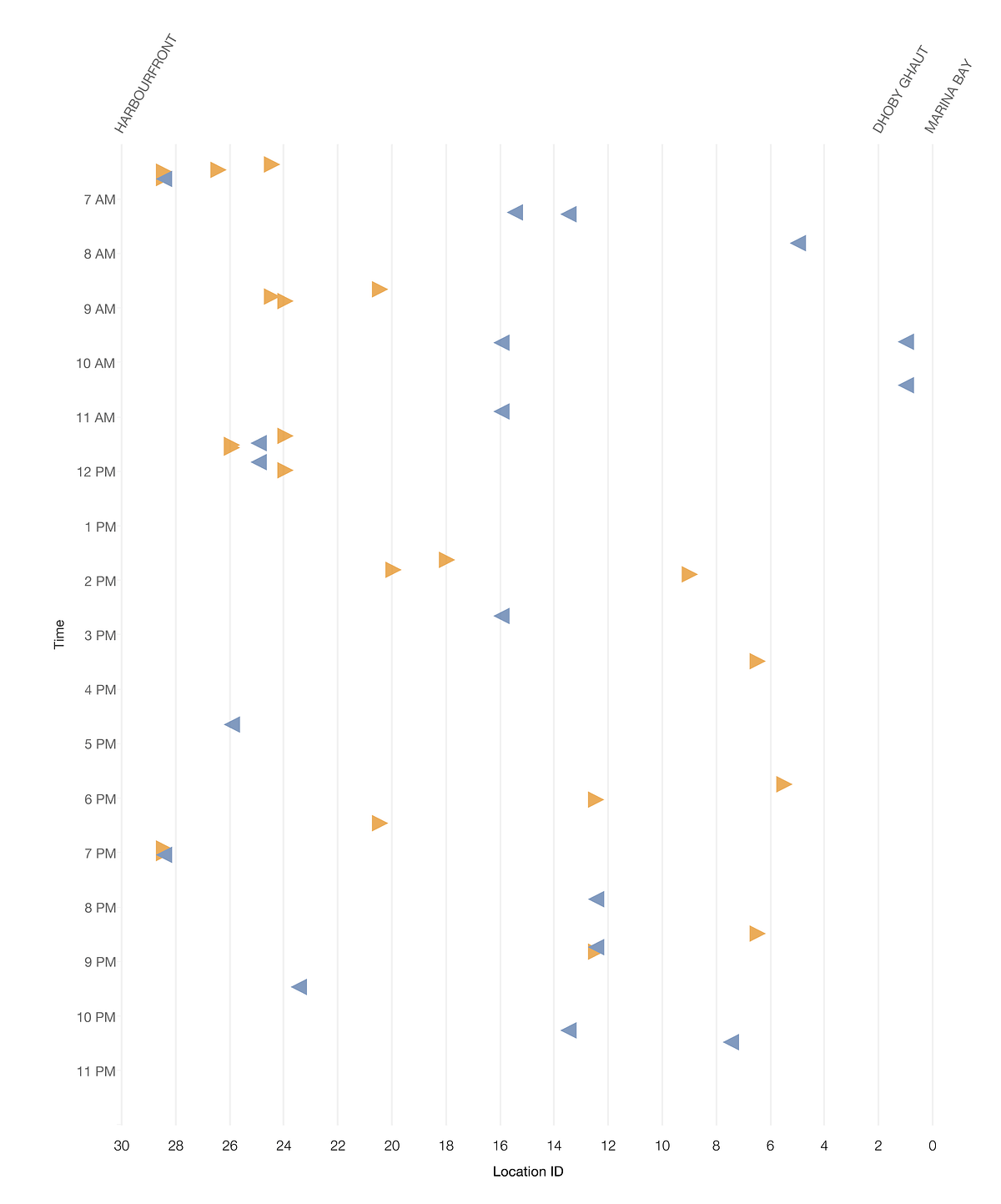
図7:列車の進行方向を矢印と色で示す
非常に不規則に見えますが、グラフを拡大するとパターンが浮き上ってくるように見えます。
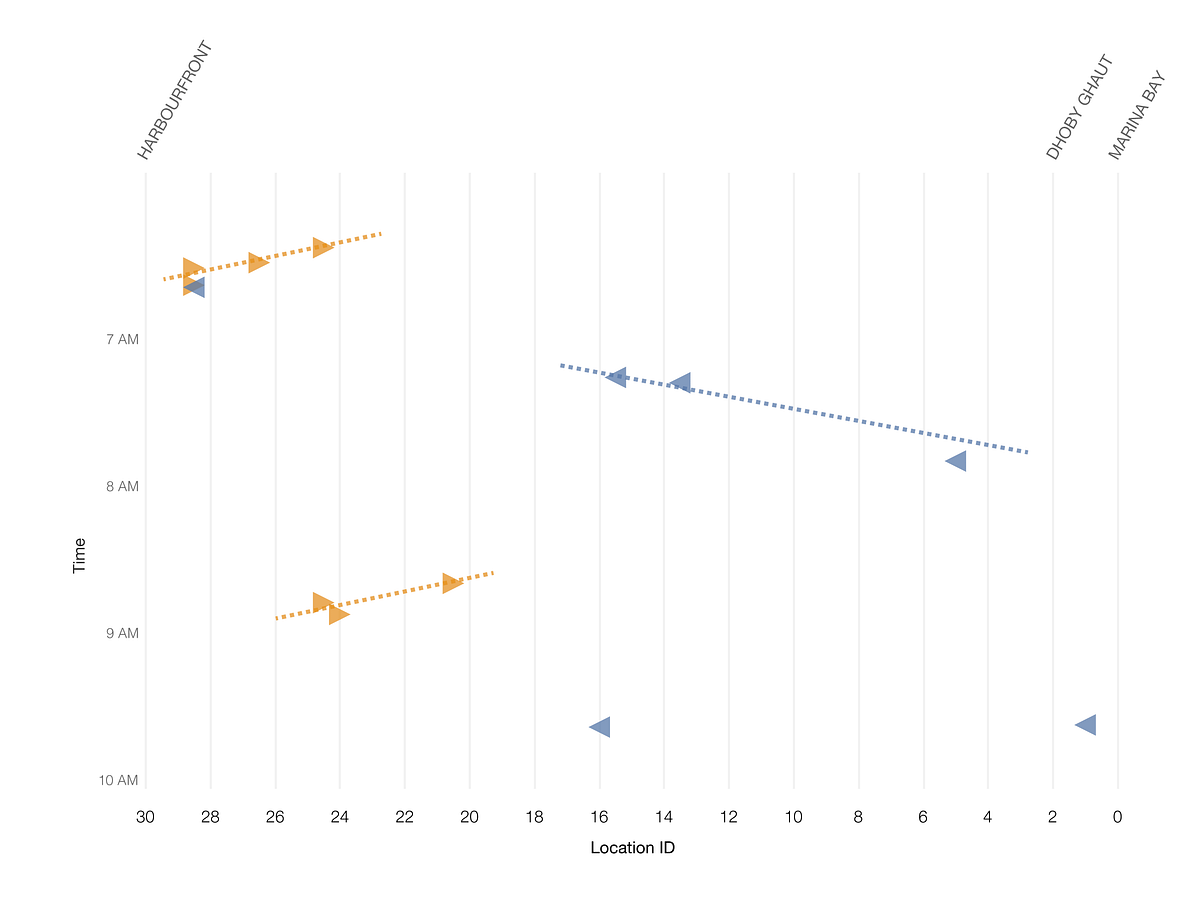
図8:午前6時から午前10時の間に発生したインシデント
グラフを注意深く観察すると、 順番に インシデントが発生していることに気が付くでしょう。ある列車が信号干渉の影響を受けると、同じ進行方向の 後続 列車も、少し経ってから干渉の影響を受けています。
信号干渉は、どうして地下鉄の端から端まで移動できるのか?
この段階では1台の列車が犯人なのかどうかは、はっきりと分かっていませんでした。
私たちが立証したのは、時間と場所でパターンがあるようだということです。インシデントが発生すると、次のインシデントは逆の進行方向で続けて発生しています。まるで”破壊の跡”があるかのようでした。 インシデントの原因は、私たちのデータセットに含まれない何かなのでしょうか?
実際、インシデント同士をつなぐ架空の線は、不気味なほどマレーチャートの線と似ています(スクリーンショット2)。 信号の干渉を起こす原因は、逆方向に走る列車なのでしょうか?
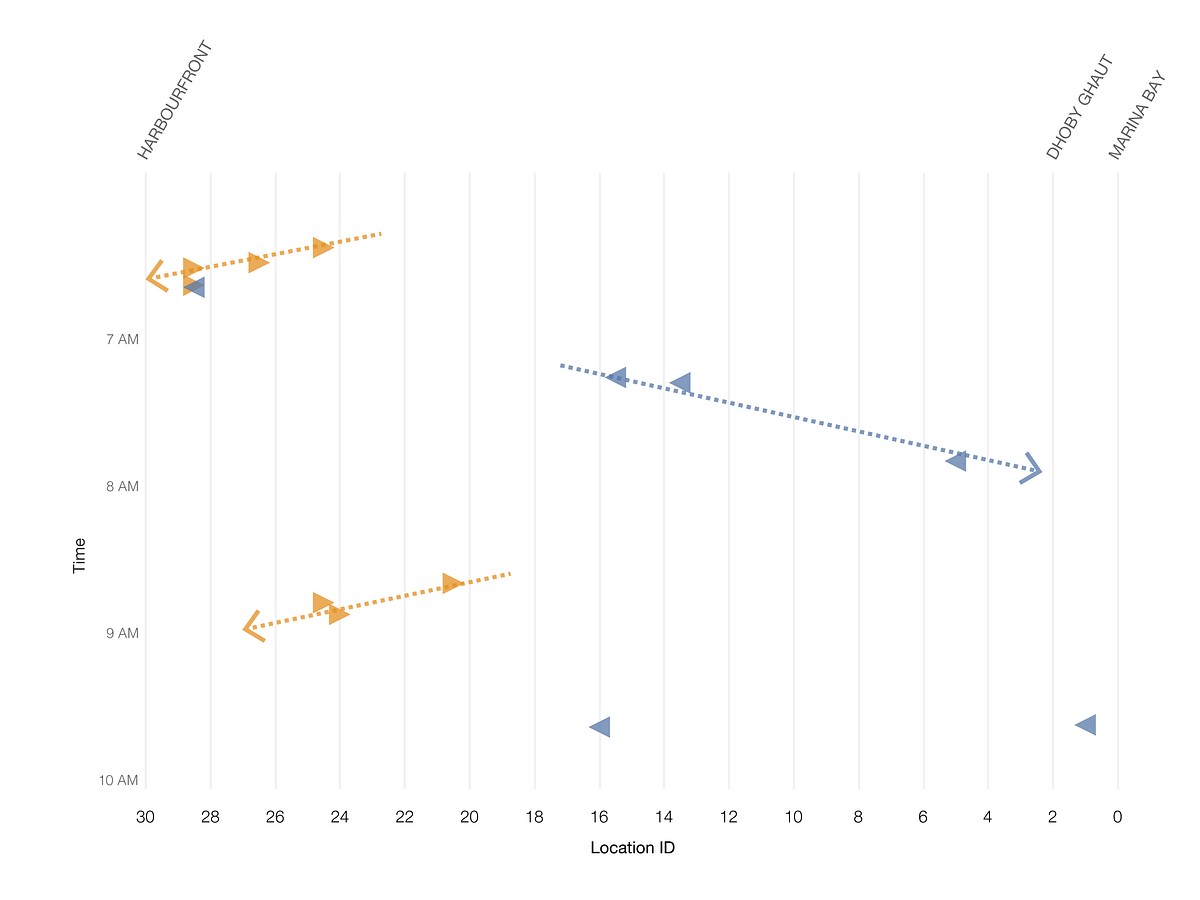
図9:逆方向に走る列車が原因か?
私たちは、この”悪さをする列車”の仮説について検証することにしました。
環状線の駅間の走行時間は2~4分だと分かっていたので、4分以内に作動した緊急ブレーキは全て同じグループにまとめることができました。
def same_cascade(i, j):
"""
Given a pair of incidents (i,j), returns true if:
t <= d * 4 mins
where t is the time difference between occurrences
and d is the distance (measured by difference in location ID).
Moreover, we consider the track direction, and only consider
incidents that are "moving backwards".
"""
# If trains are not travelling in the same direction
# they cannot be due to the same "backward moving" interference
# source.
# (Note: This was the hypothesis when this code was written.
# It turned out that the rogue train could affect all
# trains in the vicinity, not just in the opposite track)
if i["Bound"] != j["Bound"] or \
i["Bound"] not in ['IT', 'OT']:
return False
# time difference in minutes
time_difference = (i["DateTime"] - j["DateTime"]) / np.timedelta64(1, 'm')
location_difference = i["LocID"] - j["LocID"]
if location_difference == 0:
return False
ratio = time_difference / location_difference
if i["Bound"] == 'OT':
return ratio > 0 and ratio < 4
elif i["Bound"] == 'IT':
return ratio < 0 and ratio > -4スニペット7 Gist
この条件を満たす全てのインシデントの組み合わせを探しました。
incidents = sel_dfincidents.to_records()
# (a, b, c, d, ...) --> ((a,b), (a,c), (a,d), ..., (b,c), (b,d), ..., (c,d), ...)
incident_pairs = list(it.combinations(incidents, 2))
related_pairs = [ip for ip in incident_pairs if same_cascade(*ip)]
related_pairs = [(i[0], j[0]) for i,j in related_pairs]スニペット8 Gist
それから、 素集合データ構造 を使い、関連する全てのインシデントの組み合わせを、大きなセットにグループ分けしました。これにより、同じ”悪さをする列車”に関係するインシデントをひとまとめにすることができました。
def pairs_to_clusters(pairs):
"""
A quick-and-dirty disjoint-set data structure. But this works fast enough for 200+ records
Could be better.
Example input:
(1,2), (2,3), (4,5)
Output:
1: {1,2,3}
2: {1,2,3}
3: {1,2,3}
4: {4,5}
5: {4,5}
"""
the_clusters = dict()
for i,j in pairs:
if i not in the_clusters:
if j in the_clusters:
the_clusters[j].add(i)
the_clusters[i] = the_clusters[j]
else:
the_clusters[i] = set(list([i, j]))
the_clusters[j] = the_clusters[i]
else:
if j in the_clusters:
if the_clusters[i] is not the_clusters[j]: # union the two sets
for k in the_clusters[j]:
the_clusters[i].add(k)
the_clusters[k] = the_clusters[i]
else: # they are already in the same set
pass
else:
the_clusters[i].add(j)
the_clusters[j] = the_clusters[i]
return the_clustersスニペット9 Gist
そして、私たちのアルゴリズムをデータに適用しました。
clusters = pairs_to_clusters(related_pairs)
# Show each set only once
clusters = [v for k,v in clusters.items() if min(v) == k]
clusters[0:10]
view rawスニペット10 Gist
以下は、私たちが確認したクラスタの例です。
[{0, 1},
{2, 4},
{5, 6, 7},
{8, 9},
{18, 19, 20},
{21, 22, 24, 26, 27},
{28, 29, 30, 31, 32, 33, 34},
{42, 44, 45},
{47, 48},
{51, 52, 53, 56}]次に、私たちのクラスタリングのアルゴリズムで説明可能なインシデントが発生する確率を計算しました。
# count % of incidents occurring in a cluster
all_clustered_incidents = set()
for i,clust in enumerate(clusters):
all_clustered_incidents |= clust
(len(all_clustered_incidents),
len(incidents),
float(len(all_clustered_incidents)) / len(incidents))スニペット11 Gist
結果は以下となりました。
(189, 259, 0.7297297297297297)これは、 データセットに含まれる259件の緊急ブレーキが作動したインシデントの内、189ケース、もしくは73パーセントが”悪さをする列車”の仮説で説明できる ということです。私たちは、正しい方向に分析を進めていると思いました。
クラスタリングの結果を基に、インシデントのグラフを色分けしてみました。同じ色の三角形が同じクラスタに属します。
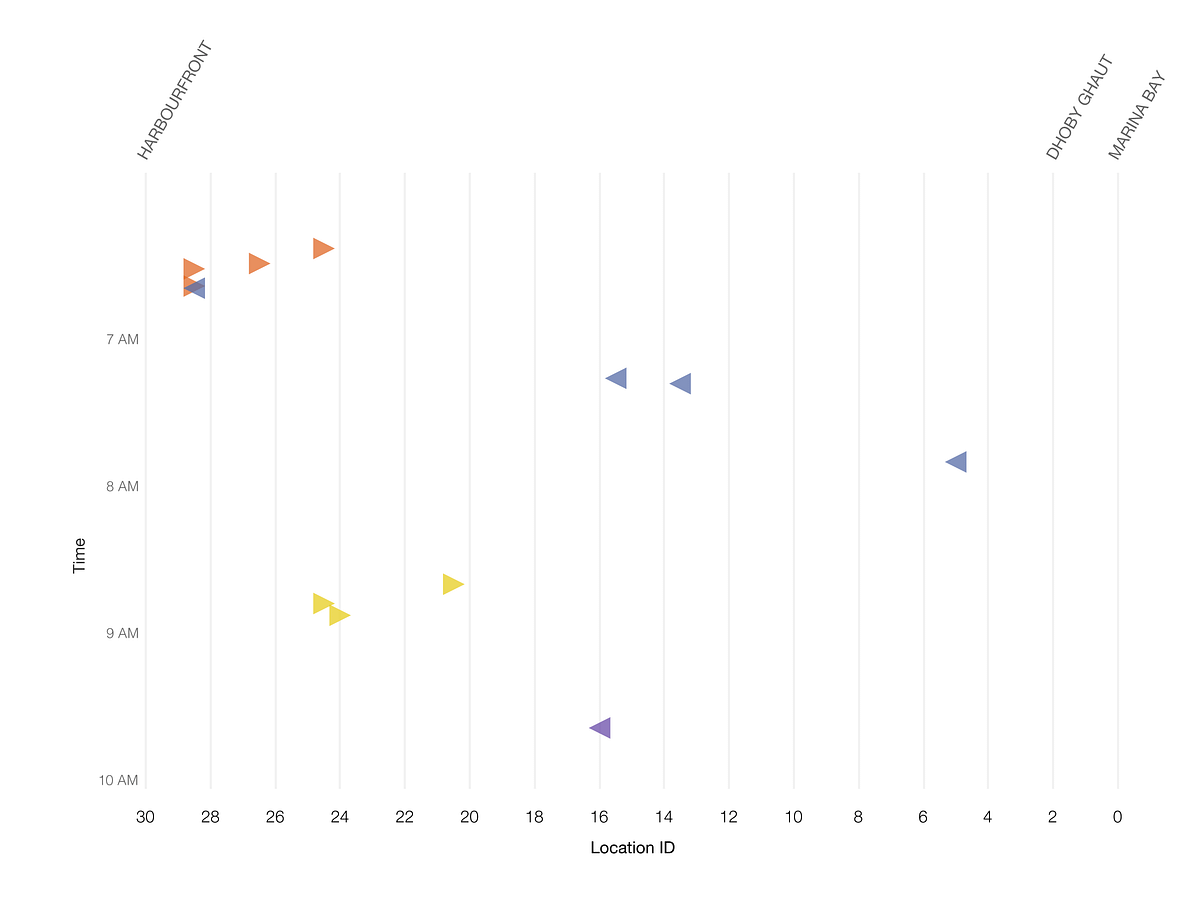
図10:私たちのアルゴリズムでクラスタリングしたインシデント
悪さをする列車は何台か?
図5 でお見せした通り、環状線を端から端まで走るのにかかる時間は、およそ1時間です。インシデントのプロットに合う線を描くと、図5に非常に近い線が引けます。これは”悪さをする列車”は1台だということを強く示唆しています。
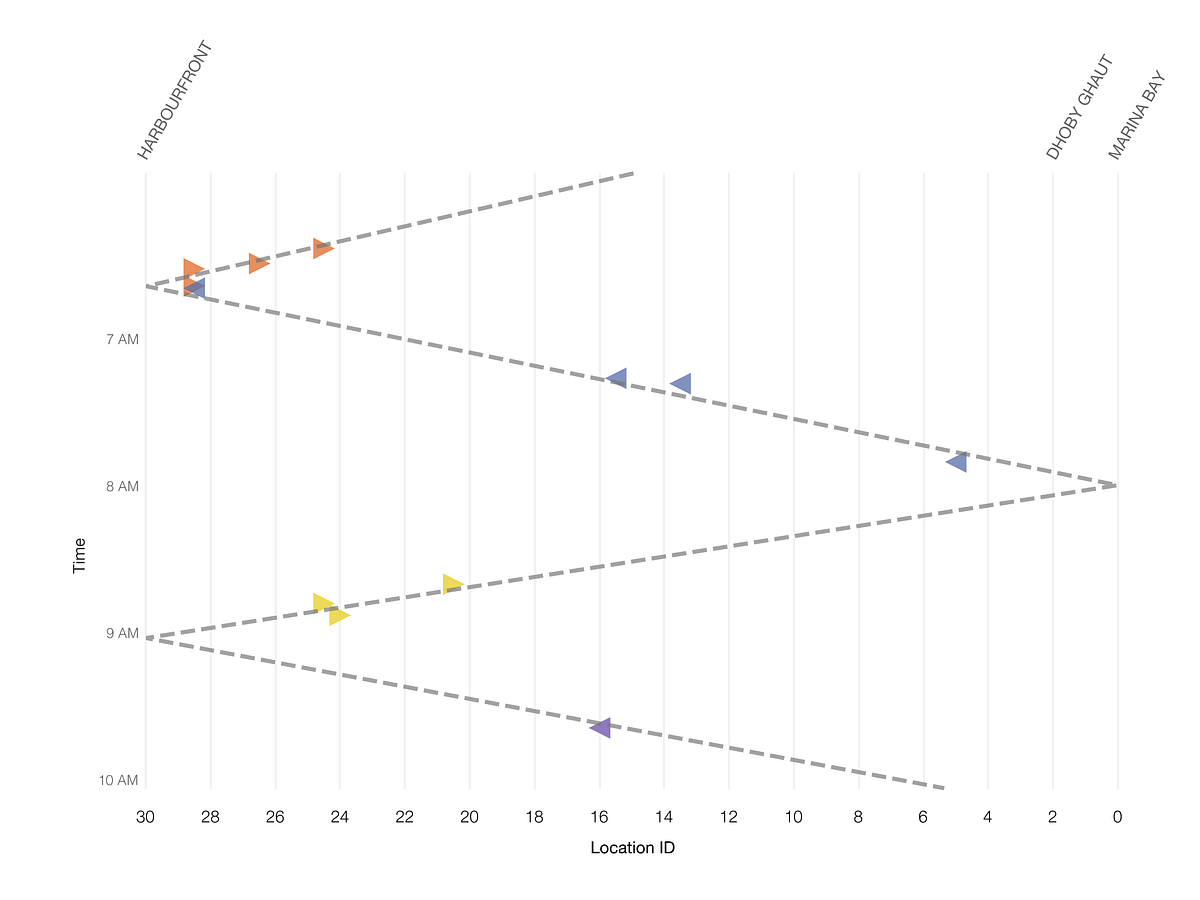
図11:クラスタリングしたインシデントの時間から、干渉に関係している列車は1台の可能性が高いことが分かる
また観察結果から、未確認の”悪さをする列車”自体は散布図に現れず、信号関連の問題を抱えていないようだと分かりました。
解明に向かっていると確信を持てたので、さらに調査を行うことにしました。
悪さをする列車を見つける
日没後、”悪さをする列車”を特定するために、キム・チュアン車両基地へ行きました。その日はSMRTがデータを抽出する時間を必要としたため、列車のログを詳しく調査できませんでした。そのため、昔ながらの方法で該当する列車を特定することにしました。インシデントが発生した時間に各駅を発着する列車の映像記録を見直したのです。
午前3時に、チームは第一容疑者を見つけました。それはPV46という、2015年から稼働している列車でした。
仮説の検証
11月6日(日曜日)にLTAとSMRTは、PV46が問題の原因かを検証するため、オフピークの時間帯にPV46を走らせました。私たちの仮説は当たりでした。PV46が、近くを走る列車同士の通信を遮断し、緊急ブレーキを作動させていたのです。検証を行った日のPV46が走るより前の時間に、同じようなインシデントは発生していませんでした。
11月7日(月曜日)、チームはPV46の過去の位置データを処理し、8月から11月に起こったインシデントの95パーセント以上が私たちの仮説で説明できると結論付けました。残りのインシデントは、通常の状態で時々発生する信号の消失が原因と思われます。
9月1日など、特定の日にパターンがはっきりと現れました。PV46が運行している時間帯およびその前後に障害が起こっていることが簡単に見て取れます。
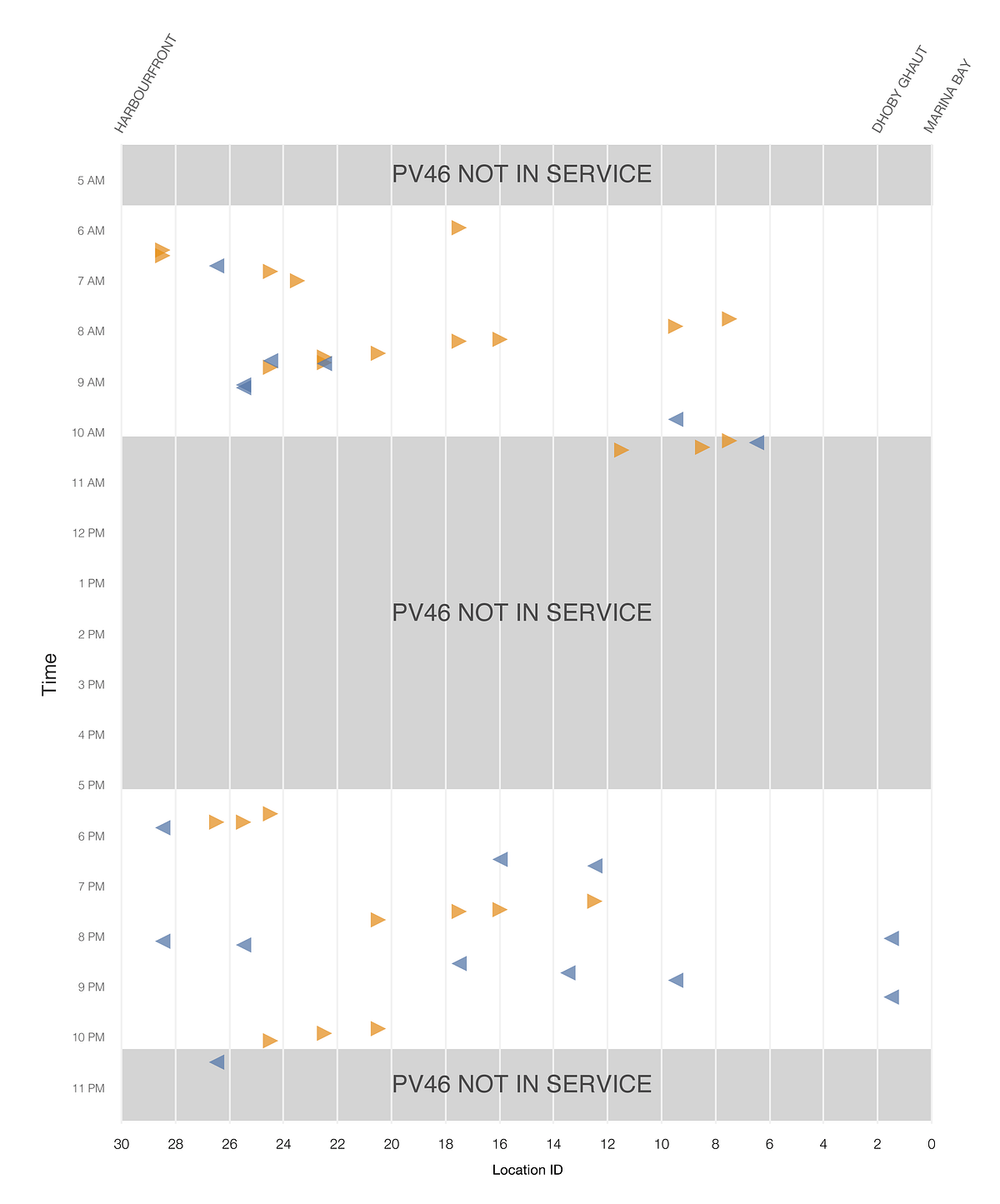
最終的にLTAとSMRTは、11月11日の 合同のプレスリリース で、調査結果を一般に公表しました。
最後に
私たちが調査を始めた頃、私と私の同僚は、LTA、SMRT、DSTAの職員が数多く参加する合同調査チームにとって興味深いパターンを見つけたいと思っていました。SMRTとLTAから提供されたインシデントログはきちんと整理されていたため、データをインポート、分析する前のクリーニングが最小限で済み、幸先のいいスタートを切ることができました。また、PV46のハードウェアの問題を確認したLTAやDSTAによる効果的な追跡調査も素晴らしかったです。
データサイエンスの観点から考えると、各インシデントがとても近い場所で発生したことは幸運でした。そのおかげで、かなり短い期間で問題と原因の両方を確認することができました。もっとインシデントが孤立していたらジグザグのパターンは分かりにくく、謎を解くための時間とデータがさらに必要となったでしょう
もちろん一番うれしいのは、通勤時に、また安心して環状線を使えるようになったことです。
注意:ここに書かれているコードは、環状線のインシデントを解明するために、実際にSMRTのデータで作業していた2016年11月5日に書かれました。非効率なコードもあると思われます。私たちが使用したJupyter Notebookのコピーは こちら からダウンロードできます。
Daniel Sim、Lee Shangqian、Clarence NgはGovTechのデータサイエンス部門で働くデータサイエンティストです。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事