2014年8月26日
機械学習の用語集:データ、学習とモデリング
(2013-12-20)by Jason Brownlee
本記事は、原著者の許諾のもとに翻訳・掲載しております。
機械学習には、この分野を理解するための基礎となるいくつかの重要な概念があります。
この記事では、データとデータセットを記述する際に用いられる用語体系 (標準的な言葉) を学びます。また、データを基にした学習やモデルを記述する際に使われる概念や用語も学びますが、これにより皆さんは機械学習の分野への旅にでかける際に役に立つ直観力を育むことができます。
データ
機械学習のメソッドでは多くの実例を通して学習します。データを記述する際には入力されるデータおよび使われているさまざまな専門用語をよく理解することが大切です。この章では、機械学習の分野でデータについて述べる際に使われる専門用語を学びます。
ここでデータとは、例えて言えばデータベースのテーブルやExcelのスプレッドシートのような行と列の配置のことを言っています。これはデータの伝統的な構造のひとつで、機械学習の分野ではなじみが深いものです。これ以外にも、例えば画像、動画、テキストなどのいわゆる非構造的データと呼ばれるデータがありますが、今回はそれらについては取り上げません。

インスタンスと特徴、そしてデータセットを示すデータ表
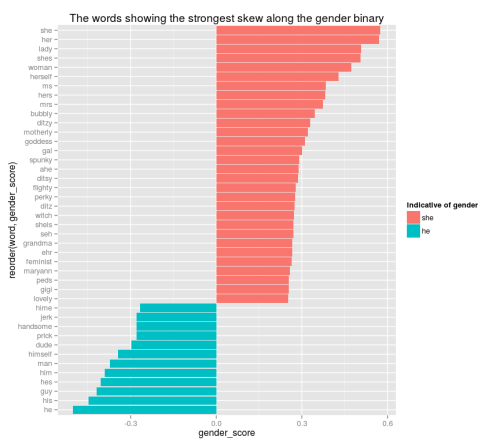
インスタンス : 横一列に並んだデータはインスタンスと呼ばれます。ある特定のドメインからの観測結果です。
特徴 : 縦一列に並んだデータは特徴(フィーチャー)と呼ばれます。観測の一つの要素であり、データのインスタンスの属性 (アトリビュート) とも呼ばれています。特徴はあるモデルへの入力 (予測因子) となることもあれば、出力つまり予測されるべき結果が特徴と呼ばれることもあります。
データ型 : 特徴はデータ型を持ちます。実数、整数、それにカテゴリー値や序数の値などです。文字列、日付、時刻やもっと複雑な型もありますが、機械学習で用いられる場合には通常、実数またはカテゴリー値へとまとめられます。
データセット : インスタンスの集まりがデータセットです。機械学習を行う場合には、通常、それぞれ異なった目的を持ついくつかのデータセットが必要です。
トレーニング用データセット : 開発した機械学習アルゴリズムに与えて私たちのモデルのトレーニングに使うデータセットです。
テスト用データセット : 私たちのモデルの精度を確認するために用いるデータセットで、トレーニングには使いません。バリデーション用データセットとも呼ばれます。
私たちのデータセットを作り上げるにはインスタンスを集める必要があるかもしれませんし、いくつかのデータセットはより小さなデータセットに分割しないといけないかもしれません。
学習
機械学習とはつまりアルゴリズムに従って自動化された学習です。この章では学習についてより高度なレベルの概念をいくつか考えてみます。
インダクション : ある一定の手続きに従って学習を進める機械学習のアルゴリズムを帰納的学習またはインダクションと呼びます。インダクションとは、個別の情報 (トレーニング用データ) から一般的化 (一つのモデル) を作り上げるという意味づけのプロセスです。
一般化 : 一般化が必要になる理由は、機械学習アルゴリズムを用いてモデルが得られると、そのモデルを用いてトレーニング中には現れなかったようなデータのインスタンスに基づいた予測や決定をする必要が出てくるからです。
過学習(Over-Learning) : あるモデルがトレーニング用データを度を越して綿密に学習しすぎたため一般化ができなくなった場合、これを過学習と呼びます。こうなった場合、トレーニング用データセットでない実際のデータを前にしても成績が上がりません。これは過度のフィッティングとも呼ばれます。
学習不足(Under-Learning) : 学習期間が短かすきてあるモデルが対象のデータベースから十分な構造を学習し終えていない場合、学習不足と呼ばれます。こうなった場合、一般化はされていても、トレーニング用データセットも含むすべてのデータを前にすると成績が上がりません。これはフィッティング不足とも呼ばれます。
オンライン学習 : ある機械学習のメソッドが、特定のドメインの中で新たにデータのインスタンスが得られる毎に更新されていく場合、これをオンライン学習と呼びます。オンライン学習にはノイズの多いデータに対しても堅牢なメソッドが必要となりますが、そのドメインの現在の状態により合致したモデルを得ることができます。
オフライン学習 : ある機械学習のメソッドがあらかじめ用意してあるデータに対して作り出され、それが観測されていないデータに実際に運用される場合、これをオフライン学習と言います。既知のトレーニング用データを利用するので、トレーニング過程は制御し調整することができます。でも使われるモデルは一旦できあがると更新されないので、対象のドメインが時につれて変わっていくと成績が下がりかねません。
教師あり学習 : これは、予測が必要となるような問題点を一般化するための学習手順の一つです。ある一つの 「指導プロセス」 が、すでに答えの分かっている事柄を対象のモデルがどのように予測するかを調べ上げて、それによりモデルに修正を加えます。
教師なし学習 : これは、データの中から一定の構造を見い出し一般化を進めるような学習手順の一つですが、予測が要らない場合です。見い出された自然な構造が、インスタンスを相互に関係づけるために利用されます。
教師あり学習と教師なし学習については以前の「 機械学習アルゴリズムへの招待(翻訳) でも言及しました。以上の用語はアルゴリズムをその作用によって分類する際に便利です。
モデリング
機械学習の過程でできてしまう不要な物があるとすれば、プログラム自体かも知れません。
モデルの選択 : ある特定のモデルを作り出しトレーニングする過程は、モデル選択の過程と考えることができます。新しいモデルが一つ出来上がるごとに、それをそのまま使って良いか修正を加えるべきかを選択します。機械学習のアルゴリズムを選ぶのだってこのモデル選択の過程の一部です。ある所定のアルゴリズムを選び抜かれたトレーニング用データセットで鍛え上げることで、ある問題を解くために存在するあらゆる可能なモデルの中から、最終的に一つのモデルを選び出すことができるのです。
帰納的バイアス : バイアスとは選択されたモデルに課される制限です。どのモデルも皆、モデルに誤差をもたらすようなバイアスを持っています。また定義から、あらゆるモデルは誤差を持っています (観測したものを一般化しているからです)。そのモデルが一般化される際にバイアスが発生します。たとえばそのモデルが作り出される際や、モデルを生成するためのアルゴリズムを選ぶ際です。ある機械学習のメソッドが作り出すモデルのバイアスは小さいこともあれば大きなこともあり、バイアスが大きい場合には何とか小さくするような方策が取られます。
モデルのバリアンス : バリアンスは、そのモデルがトレーニングに使われたデータに対してどれほど影響を受けやすいかを表します。あるデータセットについてあるモデルが作り出されたとき、機械学習のメソッドは大きなバリアンスを持つこともあれば小さなバリアンスを持つ事もあります。モデルのバリアンスを小さくするための方策は、そのモデルを初期条件を変えながら何度も同じデータセットで走らせてみることです。このときの精度の平均値をそのモデルの成績とします。
バイアスとバリアンスのトレードオフ : モデルの選定は、上記のバイアスとバリアンスのトレードオフの結果と言えるでしょう。バイアスの小さなモデルは通常大きなバリアンスを持つため、実用に耐えるモデルを得るためにより長い期間や多数回のトレーニングを繰り返す必要があります。バイアスの大きなモデルは通常小さなバリアンスを持つため、トレーニングはすぐにできますが、貧弱な成績しか得られません。
参考文献
より深く学びたい方のために以下の文献をご紹介します。
- Tom Mitchell, The need for biases in learning
generalizations (学習と一般化へのバイアスの必要性について) ,
1980 - Understanding the Bias-Variance
Tradeoff (バイアスとバリアンスのトレードオフを理解する)
この記事は役に立つ専門用語を集め、いつでも皆さんのご参考に見直していただけるよう、明白な定義を与えました。ここに掲げるべき用語がまだあるでしょうか。ここに掲げた用語はもっと明白に言い表せるでしょうか。お気づきの点があれば、ぜひコメントでお聞かせください。
次のステップへ進みましょう
機械学習の分野は実際紛らわしい世界です。非常に多くのアルゴリズム、非常に多くの問題があります。用語もたくさんありすぎます。皆さんが知っておくべき用語です。
飛び込むならまず地形をよく頭に入れておかなくてはなりません。
まずはこの28ページのPDFのガイドに是非目を通してください。
Machine Learning Foundations (機械学習の基礎)
このガイドを一読すれば、機械学習とは何かをはじめ、スタートに当たり皆さんが知っておく必要のあるハイレベルの概念を得ることができます。

株式会社リクルート プロダクト統括本部 プロダクト開発統括室 グループマネジャー 株式会社ニジボックス デベロップメント室 室長 Node.js 日本ユーザーグループ代表
- X: @yosuke_furukawa
- Github: yosuke-furukawa
関連記事